Автор: Денис Аветисян
Новое исследование показывает, что оценка производительности систем с агентами подвержена значительным случайным колебаниям, требующим более тщательного анализа.
Работа демонстрирует, что для надежной оценки прогресса необходимо проводить множество запусков и использовать надежные статистические методы, учитывая влияние случайности на траекторию развития агентов.
Несмотря на растущий интерес к агентным системам, оценка их производительности часто основывается на единственном прогоне, что может приводить к ошибочным выводам. В работе ‘On Randomness in Agentic Evals’ исследуется влияние случайности на оценку агентных систем, используемых для решения задач во взаимодействии со средой. Полученные результаты демонстрируют существенную вариативность метрики pass@1 — разница в оценках может достигать 2.2-6.0 процентных пунктов в зависимости от конкретного прогона, даже при низкой температуре. Можно ли разработать надежные методы оценки, позволяющие отделить реальный прогресс в алгоритмах от случайных колебаний и обеспечить воспроизводимость результатов?
Неустойчивость в Действиях: Вызовы Надёжности Агентурных Систем
Агентурные системы, несмотря на свой потенциал, часто демонстрируют непостоянство в работе, что связано с присущей большим языковым моделям (LLM) недетерминированностью. Этот фактор оказывает значительное влияние на предсказуемость результатов: даже при идентичных входных данных, LLM способны генерировать различные ответы из-за случайности, встроенной в процесс генерации. По сути, каждая «итерация» агента может приводить к различным путям выполнения и, следовательно, к отличающимся исходам, что затрудняет оценку реальной надежности и эффективности подобных систем. Поэтому, полагаться исключительно на единичные прогоны для оценки возможностей агентурных систем является ненадёжным подходом, поскольку результаты могут существенно варьироваться.
Традиционные методы оценки агентных систем, основанные на единичном прогоне и метрике Pass@1, зачастую дают завышенную и нестабильную картину их возможностей. Исследования показывают значительные колебания в показателях Pass@1, достигающие от 2,2 до 6,0 процентных пунктов, что указывает на существенную зависимость результатов от случайных факторов. Подобная вариативность ставит под сомнение надежность единичной оценки как репрезентативного показателя реальной производительности агента и подчеркивает необходимость более устойчивых и многократных методов тестирования для получения достоверной картины его способностей.
Встроенная случайность, обусловленная параметрами вроде температуры в больших языковых моделях, оказывает существенное влияние на траекторию выполнения задач агентными системами и, следовательно, на их надежность. Увеличение температуры, например, приводит к более разнообразным, но менее предсказуемым ответам, что может приводить к различным результатам даже при одинаковых входных данных. Этот фактор существенно усложняет оценку истинных возможностей агента, поскольку однократное выполнение задачи не отражает всей картины возможных исходов. В результате, кажущаяся успешность агента может быть обусловлена благоприятным стечением случайных факторов, а не фундаментальной способностью к решению задачи, что делает критически важным учет этой вариативности при разработке и тестировании подобных систем.
Многократная Оценка: Квантификация Надёжности Агентов
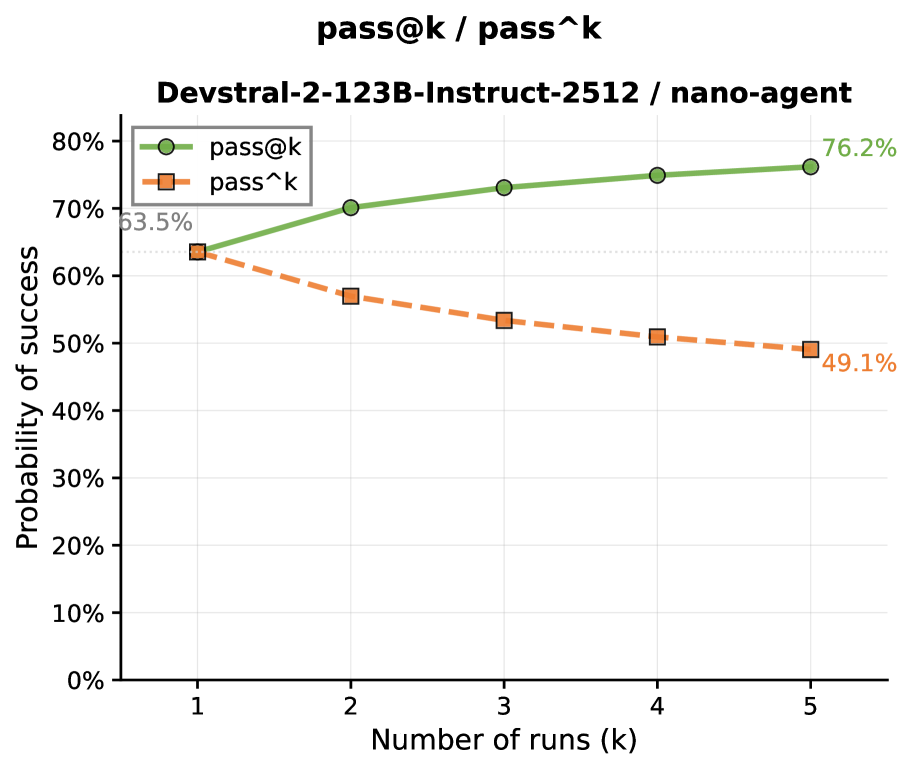
Множественный запуск оценки (Multiple-Run Evaluation) предоставляет статистически обоснованный подход к анализу производительности агентов, позволяя учесть разброс результатов и выявить устойчивые успехи. В отличие от оценки по единичному запуску, многократное тестирование позволяет не только определить средний уровень успешности, но и оценить вариативность результатов, что особенно важно при сравнении различных агентов или алгоритмов. Это позволяет более точно определить, насколько стабилен агент в достижении поставленной задачи и какие факторы могут влиять на его производительность. Такой подход обеспечивает более надежную и объективную оценку, снижая вероятность ошибочных выводов, основанных на случайных результатах единичного запуска.
Метрики Pass@k и Passˆk предоставляют более детальную оценку производительности агента, чем простое определение успешности/неуспешности. Pass@k измеряет вероятность успешного выполнения задачи хотя бы в одном из k запусков, а Passˆk — вероятность получения хотя бы одного успешного результата из k попыток, учитывая возможность частичного успеха. Разница между этими метриками и простым определением успешности/неуспешности может достигать 24,9 процентных пункта, что подчеркивает важность проведения оценки на основе множественных запусков для получения более точной и надежной картины производительности.
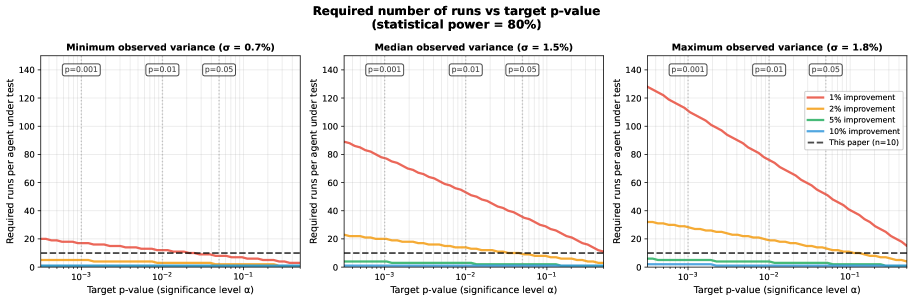
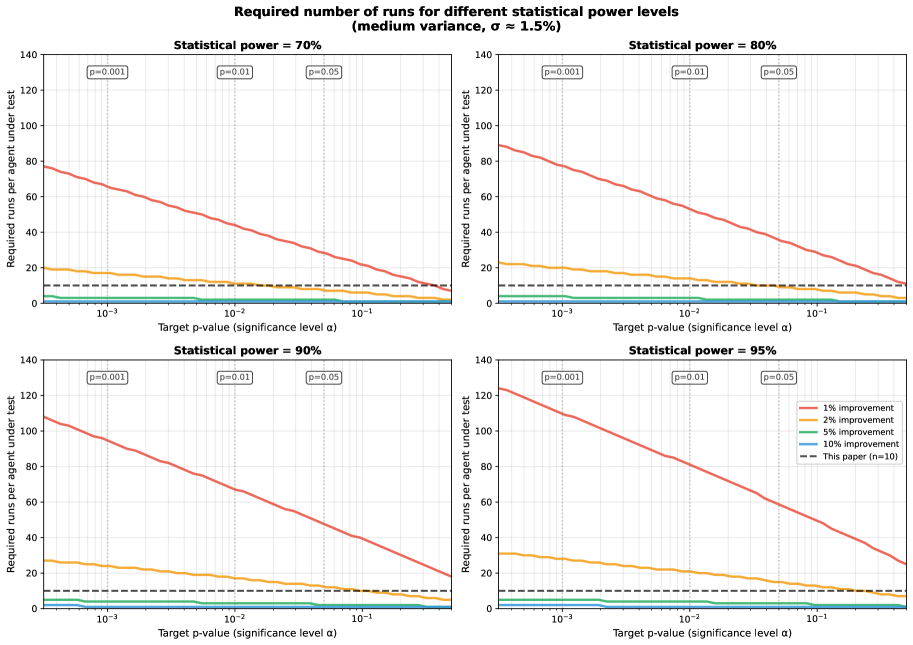
Для определения необходимого количества запусков, обеспечивающих достоверные результаты оценки агента, критически важен статистический анализ мощности (Statistical Power Analysis). Данный анализ позволяет установить минимальный размер выборки (количество запусков), при котором с заданной вероятностью (обычно 80% или выше) можно обнаружить статистически значимую разницу в производительности между различными агентами или конфигурациями. Недостаточное количество запусков может привести к ложноотрицательным результатам (неспособности выявить реальные улучшения), в то время как избыточное количество запусков увеличивает вычислительные затраты без существенного повышения достоверности. Анализ мощности учитывает желаемый уровень значимости α (обычно 0.05), ожидаемый размер эффекта и дисперсию данных для расчета необходимого количества запусков n.
Базовые Модели и Фреймворки для Надежного Выполнения Задач
Модели, такие как `Qwen/Qwen3-32B` и `mistralai/Devstral-2-123B-Instruct-2512`, выступают в качестве базовых строительных блоков для агентивных систем, определяя их исходные возможности. Размер модели, архитектура и данные, на которых она обучалась, напрямую влияют на способность агента к рассуждению, планированию и выполнению задач. В частности, модели с большим количеством параметров, такие как указанные, демонстрируют повышенную способность к обобщению и решению сложных проблем, однако требуют значительных вычислительных ресурсов для работы. Выбор базовой модели является критическим шагом при разработке агента, поскольку он устанавливает верхний предел его потенциальной производительности и определяет типы задач, которые он может эффективно выполнять.
Модели, подвергшиеся тонкой настройке, такие как agentica-org/DeepSWE-preview, демонстрируют повышение эффективности в задачах, связанных с кодированием в рамках агентов. Однако, для подтверждения их надежности и стабильности работы требуется проведение всесторонней оценки. Эта оценка должна включать тестирование в различных сценариях, анализ корректности генерируемого кода и проверку на наличие потенциальных уязвимостей. Необходимо учитывать, что улучшение производительности в отдельных задачах не гарантирует общей надежности и предсказуемости поведения модели в реальных условиях эксплуатации.
Фреймворки, такие как vLLM, и минимальные каркасы, например nano-agent, направлены на оптимизацию выполнения задач и эффективное использование ресурсов при работе с агентами. vLLM использует методы параллельной обработки для увеличения пропускной способности, а nano-agent минимизирует накладные расходы, упрощая архитектуру агента. Однако, стабильная производительность этих инструментов напрямую зависит от возможностей и поведения базовой модели, на которой они построены. Даже при оптимальной оптимизации инфраструктуры, ограничения, присущие модели, такие как склонность к галлюцинациям или неспособность к сложному рассуждению, будут влиять на конечный результат работы агента.
Анализ Поведения Агентов и Оценка Прогресса
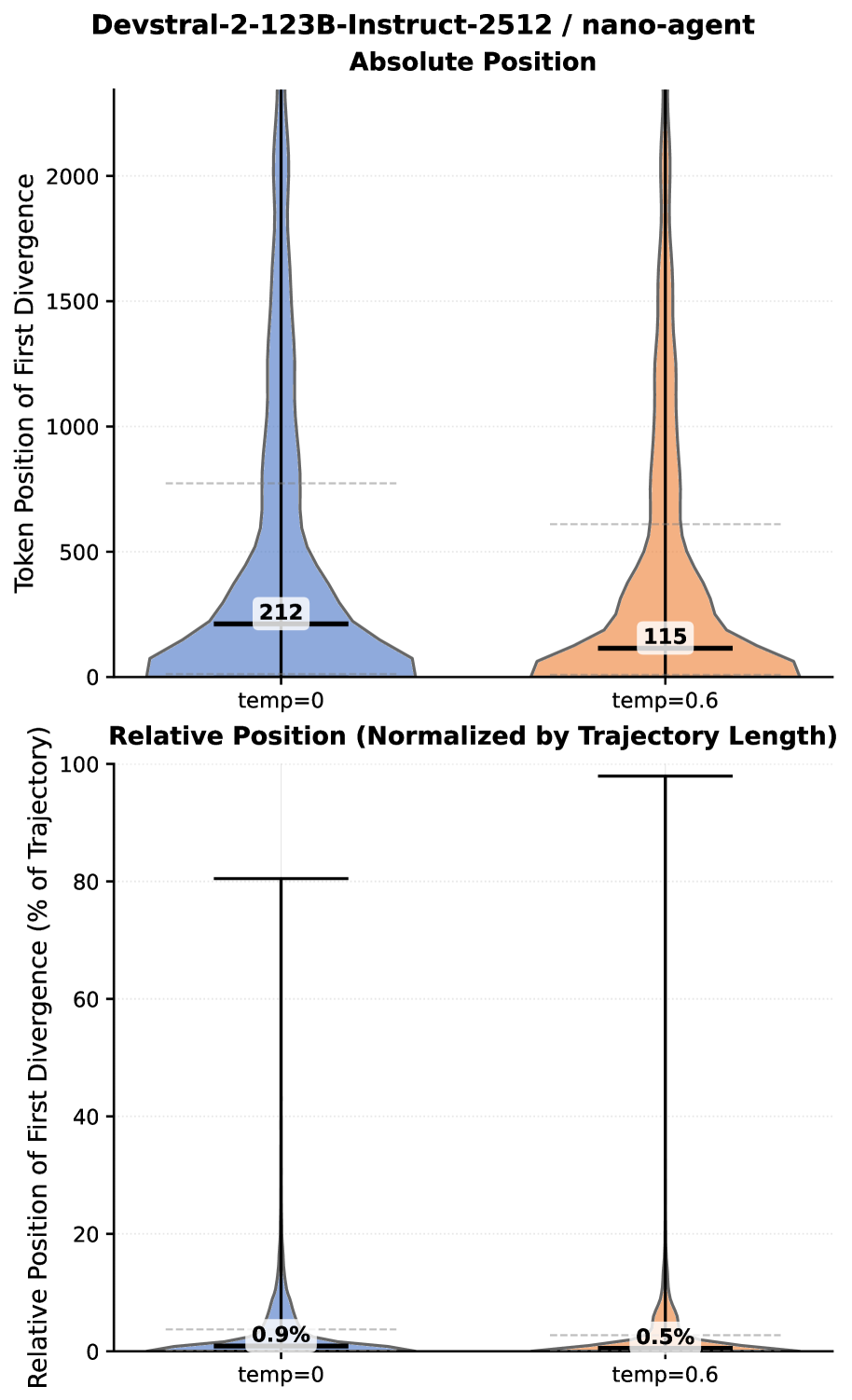
Наблюдения за расхождением траекторий в ходе множественных прогонов агентов выявили высокую чувствительность подобных систем к незначительным изменениям в выходных данных модели. Уже в первые 1% сгенерированных токенов наблюдается существенное расхождение в поведении агентов, что указывает на критическую важность начальных условий и непредсказуемость долгосрочных стратегий. Это подчеркивает потребность в тщательном анализе начальных условий и разработке методов контроля над ранними стадиями генерации, чтобы обеспечить более стабильное и предсказуемое поведение агентов в сложных задачах. Подобная высокая чувствительность требует новых подходов к оценке надежности и воспроизводимости результатов, полученных с использованием агентов.
Для объективной оценки и сопоставления возможностей агентов, специализирующихся на кодировании, используется эталонный набор задач SWE-Bench-Verified. Данный набор представляет собой стандартизированный инструмент, позволяющий количественно измерить способность агентов решать разнообразные задачи программирования. Применение SWE-Bench-Verified обеспечивает возможность последовательного отслеживания прогресса в разработке агентов, позволяя разработчикам точно оценивать улучшения в производительности и эффективности. Использование единой платформы для оценки гарантирует, что сравнения между различными агентами являются справедливыми и надежными, способствуя развитию более компетентных и универсальных систем искусственного интеллекта в области разработки программного обеспечения.
Анализ охватил внушительный объем данных — 60 000 траекторий работы агентов, в процессе которых было сгенерировано 25,58 миллиардов токенов. Это масштабное исследование позволило зафиксировать в общей сложности 1,88 миллиона обращений к инструментам, что дает уникальную возможность детально изучить поведение агентов в различных сценариях и оценить эффективность их взаимодействия с внешней средой. Такой объем данных обеспечивает статистическую значимость полученных результатов и способствует более глубокому пониманию принципов работы сложных агентных систем.
Исследование показывает, что оценка агентивных систем подвержена влиянию случайных факторов, что требует проведения множества итераций и тщательного статистического анализа для достоверной оценки улучшений. Подобная чувствительность к начальным условиям и траекториям развития напоминает о сложности предсказания поведения систем, где малейшие отклонения могут привести к значительным расхождениям. Как заметил Анри Пуанкаре: «Математия — это искусство открывать закономерности в хаосе». Эта фраза отражает суть работы: выявление влияния случайности и необходимости поиска устойчивых метрик для оценки эффективности агентивных систем, чтобы избежать ложных выводов и обеспечить надежность принимаемых решений.
Куда Далее?
Представленная работа демонстрирует, что оценка агентивных систем — процесс, удивительно чувствительный к случайности. Это напоминает градостроительство: недостаточно построить новый дом, необходимо учитывать, как он повлияет на всю инфраструктуру. Простое повышение метрики ‘pass@k’ без учета дисперсии и траектории расхождения результатов — всё равно что красить фасад, игнорируя трещины в фундаменте. Необходимо переосмыслить подход к статистической значимости, чтобы избежать ложных заключений о прогрессе.
Очевидным следующим шагом является разработка более устойчивых к шуму метрик и протоколов оценки. Необходимо стремиться к созданию системы, в которой небольшие улучшения действительно отражают фундаментальные изменения в поведении агента, а не случайные флуктуации. Иначе, прогресс рискует оказаться иллюзией, замаскированной под статистическую значимость.
В конечном счете, задача заключается не в том, чтобы просто измерять производительность, а в понимании структуры, определяющей ее. Элегантный дизайн системы, способной к надежной самооценке, требует ясности и простоты, а также признания того, что любое вмешательство в один ее компонент неизбежно влияет на все остальные. Будущие исследования должны быть направлены на выявление этих взаимосвязей и построение более целостной картины.
Оригинал статьи: https://arxiv.org/pdf/2602.07150.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Плоские зоны: от теории к новым материалам
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Искусственный интеллект на службе редких болезней
- Язык тела под присмотром ИИ: архитектура и гарантии
- Наука, управляемая интеллектом: новая эра открытий
- Квантовый дозор: Новая система обнаружения аномалий для умных сетей
- Генерация без рисков: как избежать нарушения авторских прав при работе с языковыми моделями
- Квантовый Переворот: От Теории к Реальности
- Искусственный интеллект: оценка по результату, а не по задаче
2026-02-10 17:56