Автор: Денис Аветисян
Исследование предлагает инновационный подход к обучению больших языковых моделей с подкреплением, направленный на улучшение поиска оптимальных решений за счет стимулирования разнообразия стратегий.
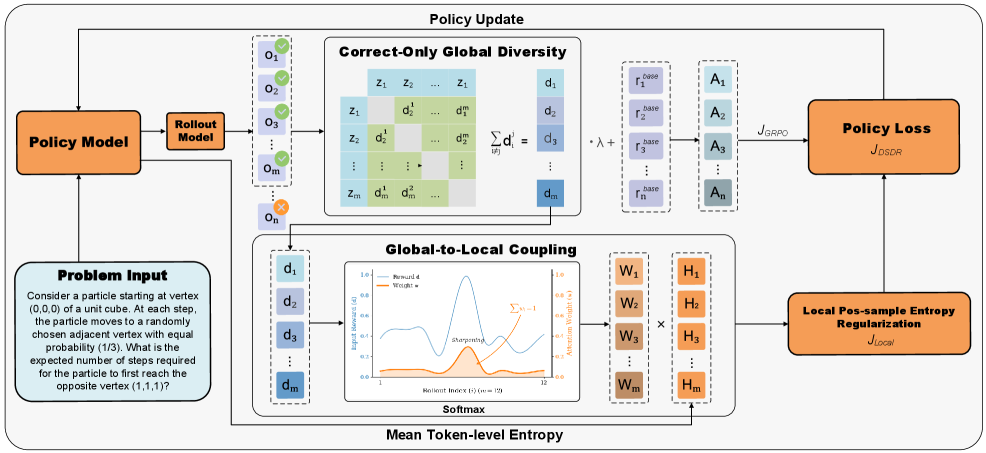
Представлен DSDR — фреймворк двойного масштаба для регуляризации разнообразия, повышающий эффективность обучения и улучшающий согласованность с локальными критериями корректности.
Несмотря на успехи обучения с подкреплением с верификаторами (RLVR) в улучшении рассуждений больших языковых моделей (LLM), существующие подходы часто страдают от недостаточной исследовательской способности. В данной работе, представленной под названием ‘DSDR: Dual-Scale Diversity Regularization for Exploration in LLM Reasoning’, предлагается новый фреймворк DSDR, основанный на регуляризации разнообразия в двух масштабах, который разделяет разнообразие в процессе рассуждений LLM на глобальные и локальные компоненты. Такой подход позволяет эффективно исследовать различные режимы решения задач, поддерживая при этом высокую точность и стабильность обучения. Каким образом дальнейшее развитие методов регуляризации разнообразия может способствовать созданию более надежных и интеллектуальных систем на основе LLM?
Вызовы логического мышления в больших языковых моделях
Несмотря на впечатляющие возможности больших языковых моделей, достижение надёжного и устойчивого рассуждения остаётся существенной проблемой. Эти модели демонстрируют способность генерировать связные и грамматически правильные тексты, однако их способность к логическому выводу и решению сложных задач часто оказывается ограниченной. Ошибки возникают не из-за неспособности понимать язык, а из-за трудностей с выстраиванием последовательности шагов, необходимых для получения верного ответа. Модели могут генерировать правдоподобные, но ошибочные заключения, особенно при работе с информацией, требующей глубокого анализа и критического осмысления. Таким образом, несмотря на значительный прогресс, надёжное рассуждение остается ключевым направлением для дальнейших исследований и усовершенствования больших языковых моделей.
Традиционные подходы к решению задач, требующих многоступенчатых логических выводов, часто оказываются недостаточно эффективными для современных больших языковых моделей. Эти модели, несмотря на впечатляющую способность генерировать связные тексты, склонны к ошибкам при решении сложных задач, требующих последовательного применения логики. В частности, они могут выдавать правдоподобные, но неверные ответы, поскольку их обучение часто фокусируется на статистических закономерностях в данных, а не на глубоком понимании причинно-следственных связей. Это проявляется в неспособности корректно решать задачи, требующие анализа нескольких условий, выявления противоречий или проведения дедуктивных умозаключений, что подчеркивает необходимость разработки новых методов, способных обеспечить более надежное и обоснованное рассуждение.
Одной из ключевых проблем, ограничивающих возможности больших языковых моделей в решении задач, требующих логического мышления, является склонность к быстрому сходимости к субоптимальным решениям. Модели часто недостаточно полно исследуют пространство возможных ответов, ограничиваясь первыми, кажущимися правдоподобными вариантами. Это приводит к тому, что даже при кажущейся убедительности ответов, они могут быть неверными или неполными. Недостаточное исследование альтернативных путей решения задачи обусловлено особенностями алгоритмов обучения и архитектуры моделей, что требует разработки новых подходов, стимулирующих более глубокий и всесторонний анализ информации перед выдачей окончательного результата.
Обучение с подкреплением для усиления рассуждений
Обучение с подкреплением (Reinforcement Learning, RL) представляет собой парадигму, в которой агент обучается принимать последовательность решений для максимизации суммарного вознаграждения за определенный период времени. В отличие от обучения с учителем, RL не требует предварительно размеченных данных; агент взаимодействует со средой, получая обратную связь в виде вознаграждений или штрафов за каждое действие. Этот подход особенно эффективен при решении задач, требующих планирования и принятия решений в сложных, динамических условиях, поскольку позволяет агенту адаптироваться к изменяющимся обстоятельствам и оптимизировать стратегию поведения для достижения долгосрочных целей. В контексте задач, требующих рассуждений, RL позволяет моделировать процесс принятия решений как последовательность шагов, где каждое действие приближает агента к желаемому результату, учитывая кумулятивный эффект от всех предыдущих действий.
Стандартные алгоритмы обучения с подкреплением (RL) часто демонстрируют низкую эффективность использования данных и нестабильность в сложных средах. Это связано с трудностями в исследовании пространства состояний и поддержании стабильности при обновлении политики. Для решения этих проблем разрабатываются алгоритмы, такие как Group Relative Policy Optimization (GRPO). GRPO обеспечивает более стабильный процесс обучения за счет группировки параметров политики и применения относительных обновлений, что снижает вариативность и ускоряет сходимость. Такой подход позволяет агенту более эффективно изучать оптимальные стратегии в сложных задачах, требующих последовательного принятия решений.
Эффективное исследование пространства состояний является критически важным для успешного обучения с подкреплением, особенно в сложных задачах, требующих рассуждений. Метод регуляризации разнообразия (Diversity Regularization) предоставляет механизм для стимулирования агента к обнаружению более широкого спектра потенциально полезных решений. Он достигается путем добавления к функции потерь компонента, который поощряет отклонение действий от текущей политики, тем самым увеличивая вероятность исследования новых, ранее неисследованных областей пространства действий. Это позволяет агенту избежать застревания в локальных оптимумах и находить более оптимальные стратегии в долгосрочной перспективе. Эффективность метода заключается в балансе между использованием уже известных выгодных действий и исследованием новых возможностей.
Двойная регуляризация разнообразия: новый подход
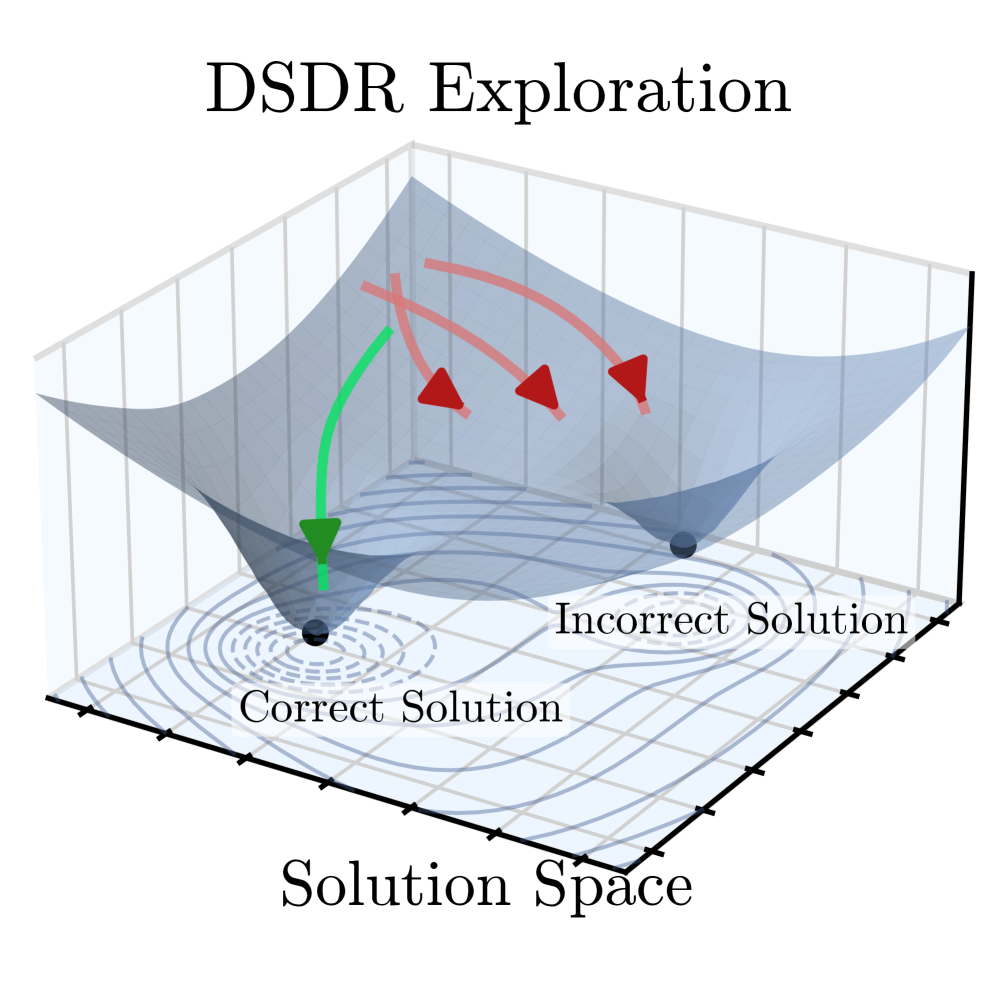
Двойная регуляризация разнообразия (DSDR) представляет собой структуру, объединяющую глобальную и локальную регуляризацию для стимулирования исследования на стратегическом и тактическом уровнях. Глобальная регуляризация направлена на поощрение исследования различных режимов рассуждений или стратегий, в то время как локальная регуляризация способствует вариативности внутри единого режима рассуждений. Данный подход позволяет модели одновременно исследовать различные высокоуровневые стратегии решения задачи и генерировать разнообразные решения в рамках каждой конкретной стратегии, что потенциально улучшает обобщающую способность и устойчивость модели к различным входным данным.
Глобальное разнообразие в рамках DSDR направлено на стимулирование исследования моделью различных режимов рассуждений или стратегий решения задачи. Это достигается путем поощрения генерации различных подходов к проблеме, что позволяет избежать застревания в локальном оптимуме. Локальное разнообразие, в свою очередь, способствует вариативности внутри каждого отдельного режима рассуждений, стимулируя изменение конкретных токенов или шагов в процессе генерации ответа. Таким образом, глобальное разнообразие определяет что модель исследует, а локальное разнообразие — как она это делает, обеспечивая комплексный подход к повышению эффективности и надежности генеративных моделей.
Глобальное-локальное связывание (Global-to-Local Coupling) в рамках Dual-Scale Diversity Regularization (DSDR) реализуется посредством координации сигналов регуляризации на двух уровнях. Этот механизм обеспечивает не просто суммирование, а взаимосвязанное воздействие глобальной и локальной регуляризации. Глобальная регуляризация определяет общую стратегию исследования пространства решений, в то время как локальная регуляризация варьирует параметры внутри выбранной стратегии. Координация этих сигналов позволяет избежать конфликтов и добиться синергетического эффекта, максимизируя преимущества диверсификации и обеспечивая более эффективное исследование пространства возможных решений по сравнению с независимым применением глобальной и локальной регуляризации.
Повышение локального разнообразия достигается за счет применения положительной энтропии, которая стимулирует случайность на уровне отдельных токенов. Этот подход предотвращает преждевременную сходимость модели к одному решению, заставляя её рассматривать большее количество вариантов даже в рамках выбранной стратегии рассуждений. Использование положительной энтропии эффективно увеличивает вероятность выбора менее вероятных, но потенциально полезных токенов, что способствует более полному исследованию пространства решений и повышает устойчивость модели к различным входным данным. Регулировка величины энтропии позволяет контролировать степень случайности и оптимизировать баланс между исследованием и эксплуатацией.
Корректность-согласованные награды для надёжного рассуждения
В основе подхода обучения с подкреплением и верифицированными наградами (RLVR) лежит использование внешних верификаторов для оценки корректности каждого шага рассуждений модели. Вместо традиционного определения награды на основе конечного результата, RLVR предоставляет промежуточную обратную связь, указывающую на правильность или ошибочность промежуточных выводов. Это позволяет модели не просто находить правильный ответ, но и усваивать логику и принципы корректного мышления. Внешний верификатор, функционируя как независимый эксперт, подтверждает или опровергает каждый шаг, формируя награду, направленную на стимулирование именно точных и обоснованных рассуждений, а не просто удачного угадывания. Такой механизм позволяет значительно повысить надежность и прозрачность процесса обучения, что особенно важно для сложных задач, требующих логического анализа и обоснования.
Метод формирования вознаграждения, или Reward Shaping, играет ключевую роль в обучении модели надежному рассуждению. В процессе обучения, внешние верификаторы оценивают каждый шаг логической цепочки, предоставляя обратную связь о корректности. Эта информация не просто регистрируется, а активно преобразуется в сигнал вознаграждения, который направляет модель к более точным и надежным решениям. Вместо простого подтверждения правильности конечного ответа, система поощряет каждый корректный шаг рассуждения, эффективно «обучая» модель не только достигать цели, но и следовать логически верному пути. Такой подход позволяет избежать ситуаций, когда модель случайно находит правильное решение, но не обладает пониманием принципов, лежащих в основе этого решения, и значительно повышает общую надежность и предсказуемость ее работы.
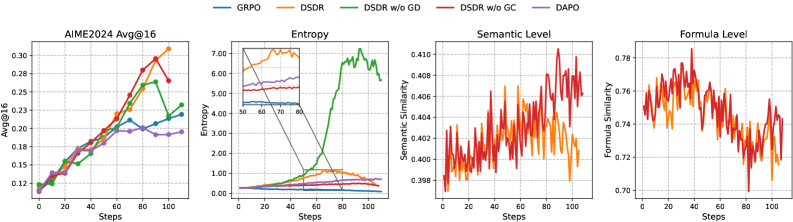
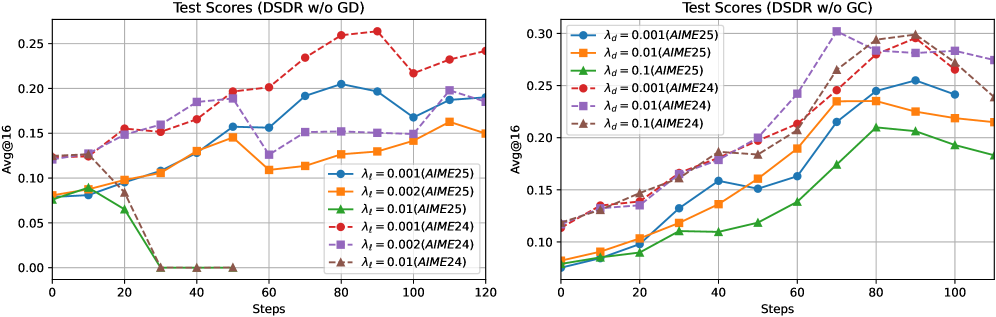
Регуляризация, согласованная с критерием корректности, дополняет подход обучения с подкреплением и верифицированными наградами (RLVR), усиливая акцент на точности и предотвращая отклонение модели от правильных путей решения. Этот механизм действует как дополнительный фильтр, штрафуя неверные шаги в рассуждениях и стимулируя модель к поиску логически обоснованных и достоверных ответов. Вместе с RLVR, регуляризация формирует систему, которая не только вознаграждает правильные решения, но и активно препятствует исследованию ошибочных направлений, что приводит к существенному повышению надежности и точности генерируемых цепочек рассуждений и, как следствие, к улучшению показателей прохождения тестов на различных бенчмарках, включая AIME2024 и MATH500.
Сочетание предложенных методов позволило значительно повысить способность модели генерировать корректные и логически обоснованные цепочки рассуждений. Это подтверждается улучшением показателя Pass@1 на пяти различных бенчмарках, включающих AIME2024, AIME2025, MATH500, Minerva и Olympiad. В частности, разработанная система DSDR демонстрирует стабильное превосходство над конкурирующими подходами GRPO и DAPO по метрике Avg@16. Более того, DSDR последовательно превосходит базовые модели и по показателю Pass@k (где k варьируется от 2 до 64), причем разрыв в производительности увеличивается с ростом значения k, что свидетельствует о повышенной надежности генерируемых решений.
Представленная работа демонстрирует подход к управлению сложностью систем, в которых случайность и разнообразие не рассматриваются как помехи, а используются для достижения более устойчивых результатов. В контексте обучения больших языковых моделей, DSDR подчёркивает важность исследования различных путей решения задач, избегая преждевременной оптимизации и зацикливания на локальных максимумах. Карл Фридрих Гаусс однажды сказал: «Я не знаю, как мир устроен, но я знаю, что он не устроен так, как мы думаем». Эта фраза отражает суть DSDR — признание ограниченности наших представлений о оптимальном решении и необходимость постоянного исследования новых возможностей, поддерживая баланс между глобальным разнообразием и локальной точностью, что позволяет системе эволюционировать, а не просто функционировать.
Что впереди?
Предложенный подход, акцентирующий регуляризацию разнообразия в двойном масштабе, представляет собой не столько конструкцию, сколько попытку взрастить сад исследования в пространстве языковых моделей. Однако, не стоит заблуждаться, полагая, что достигнуто полное понимание. Сама природа исследования, её стремление к неизведанному, предполагает постоянное возникновение новых, неожиданных троп, которые потребуют переосмысления существующих методов. Регуляризация — это лишь одна из граней, и вопрос о том, как сбалансировать глобальное разнообразие с локальной корректностью, остаётся открытым.
Более того, следует признать, что устойчивость системы не в изоляции её компонентов, а в их способности прощать ошибки друг друга. Поэтому, вместо стремления к идеальной корректности на каждом шаге, возможно, стоит обратить внимание на механизмы самовосстановления и адаптации, позволяющие модели учиться на собственных ошибках и извлекать из них пользу. Предложенный подход, безусловно, является шагом в правильном направлении, но он лишь указывает на сложность ландшафта, который предстоит исследовать.
В конечном счёте, система — это не машина, это сад; если её не поливать новыми идеями и не оберегать от сорняков упрощений, вырастет техдолг. Будущие исследования должны сосредоточиться на разработке более гибких и адаптивных механизмов регуляризации, способных учитывать динамику и непредсказуемость процесса обучения. Поиск баланса между исследованием и использованием остаётся ключевой задачей, требующей постоянного внимания и критического осмысления.
Оригинал статьи: https://arxiv.org/pdf/2602.19895.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Квантовый скачок: от лаборатории к рынку
2026-02-25 02:57