Автор: Денис Аветисян
Новый подход позволяет обучать мощные мультимодальные модели, сохраняя при этом конфиденциальность данных и преодолевая проблемы разнородности.

Представлена платформа FedUMM для федеративного обучения унифицированных мультимодальных моделей с использованием эффективной тонкой настройки и инновационной стратегии агрегации.
Единые мультимодальные модели (UMM) демонстрируют впечатляющие возможности, но их обучение традиционно требует централизованного доступа к данным, что ограничивает применение в условиях строгих требований к конфиденциальности. В данной работе представлена система ‘FedUMM: A General Framework for Federated Learning with Unified Multimodal Models’, предлагающая общий фреймворк для федеративного обучения UMM при использовании неоднородных мультимодальных данных с минимальными затратами на связь. Предложенный подход, основанный на платформе NVIDIA FLARE и использовании адаптеров LoRA, позволяет достичь производительности, близкой к централизованному обучению, за счет агрегации лишь обновлений адаптеров. Каковы перспективы дальнейшей оптимизации федеративного обучения UMM для повышения устойчивости к гетерогенности данных и снижения коммуникационных издержек?
Эволюция Унифицированных Мультимодальных Моделей: От Ограничений к Пониманию
Традиционные модели искусственного интеллекта зачастую разрабатываются для работы с данными одного типа, например, только с текстом или только с изображениями. Такой подход существенно ограничивает их возможности в понимании реального мира, где информация представлена в разнообразных формах и взаимосвязана. Изолированная обработка данных приводит к тому, что модели упускают важные контекстуальные детали и не способны к комплексному анализу. Представьте, что для понимания сцены человек видит изображение и одновременно слышит описание — объединенная информация позволяет сформировать более полное и точное представление. Аналогично, модели, работающие с изолированными данными, лишены возможности извлекать максимум пользы из окружающей среды и, следовательно, демонстрируют ограниченные возможности в решении сложных задач, требующих мультисенсорного анализа.
Единые мультимодальные модели представляют собой значительный шаг вперед в области искусственного интеллекта, стремясь преодолеть ограничения традиционных систем, которые обрабатывают данные изолированно. Вместо анализа текста или изображений по отдельности, эти модели способны одновременно воспринимать и интегрировать информацию из различных источников, таких как текстовые описания, визуальные образы и даже аудиосигналы. Такой подход позволяет им формировать более полное и глубокое понимание окружающей действительности, подобно тому, как человек воспринимает мир, используя все свои органы чувств. В результате, мультимодальные модели демонстрируют повышенную эффективность в решении сложных задач, требующих контекстуального понимания и способности к обобщению, открывая новые возможности в областях, начиная от автоматической обработки естественного языка и заканчивая компьютерным зрением и робототехникой.
Обучение унифицированных мультимодальных моделей сопряжено со значительными трудностями, в первую очередь связанными с доступом к обширным и размеченным наборам данных, охватывающим различные модальности — текст, изображения, аудио и другие. Создание таких датасетов требует колоссальных усилий и ресурсов, а их качество напрямую влияет на эффективность модели. Более того, обработка и интеграция данных из разных источников предъявляет высокие требования к вычислительной мощности, поскольку модели становятся все более сложными и параметрическими. Необходимость использования графических процессоров (GPU) или специализированных ускорителей для обучения увеличивает финансовые затраты и ограничивает доступность передовых мультимодальных систем для многих исследовательских групп и организаций. Преодоление этих трудностей является ключевым фактором для дальнейшего развития и широкого внедрения унифицированных мультимодальных моделей.

Федеративное Обучение: Когда Данные Остаются Дома
Федеративное обучение (FL) представляет собой подход к построению моделей машинного обучения, позволяющий обучать модель на децентрализованных устройствах или серверах, удерживая данные на самих устройствах. Это достигается путем обмена параметрами модели, а не самими данными, что существенно повышает конфиденциальность. Вместо централизованного сбора данных, каждый участник локально обучает модель на своих данных, а затем отправляет обновления модели (например, градиенты или веса) центральному серверу. Центральный сервер агрегирует эти обновления, создавая улучшенную глобальную модель, которая затем распространяется обратно участникам. Такой подход снижает необходимость передачи больших объемов данных, уменьшая коммуникационные издержки и повышая масштабируемость, особенно в сценариях с большим количеством устройств и ограниченной пропускной способностью сети.
Алгоритм Federated Averaging (FedAvg) является базовым подходом к агрегации обновлений моделей в федеративном обучении. В его основе лежит итеративный процесс, где каждая участвующая сторона (например, мобильное устройство) обучает локальную копию глобальной модели на своем локальном наборе данных. После завершения локального обучения, обновления моделей (разница между исходной и обученной моделью) отправляются на центральный сервер. Сервер усредняет эти обновления, вычисляя среднее значение весов моделей, и обновляет глобальную модель. Этот процесс повторяется несколько раз, пока глобальная модель не достигнет желаемой точности. \text{Global Model} = \frac{1}{N} \sum_{i=1}^{N} \text{Local Model}_i , где N — количество участвующих устройств. Простота FedAvg делает его отправной точкой для многих более сложных алгоритмов федеративного обучения.
В практических реализациях федеративного обучения (FL) часто возникают проблемы, связанные со статистической неоднородностью данных на различных устройствах и высокими затратами на передачу данных. Неоднородность, или “non-IID” данные, означает, что распределения данных на каждом устройстве могут значительно отличаться, что приводит к снижению скорости сходимости и ухудшению общей производительности модели. Высокие затраты на коммуникацию обусловлены необходимостью передачи параметров модели между устройствами и центральным сервером, что может быть особенно проблематично при ограниченной пропускной способности сети или большом количестве участников. Для решения этих проблем разрабатываются и применяются более сложные методы, такие как сжатие моделей, выборочное агрегирование, персонализированные федеративные алгоритмы и методы, снижающие частоту коммуникаций.
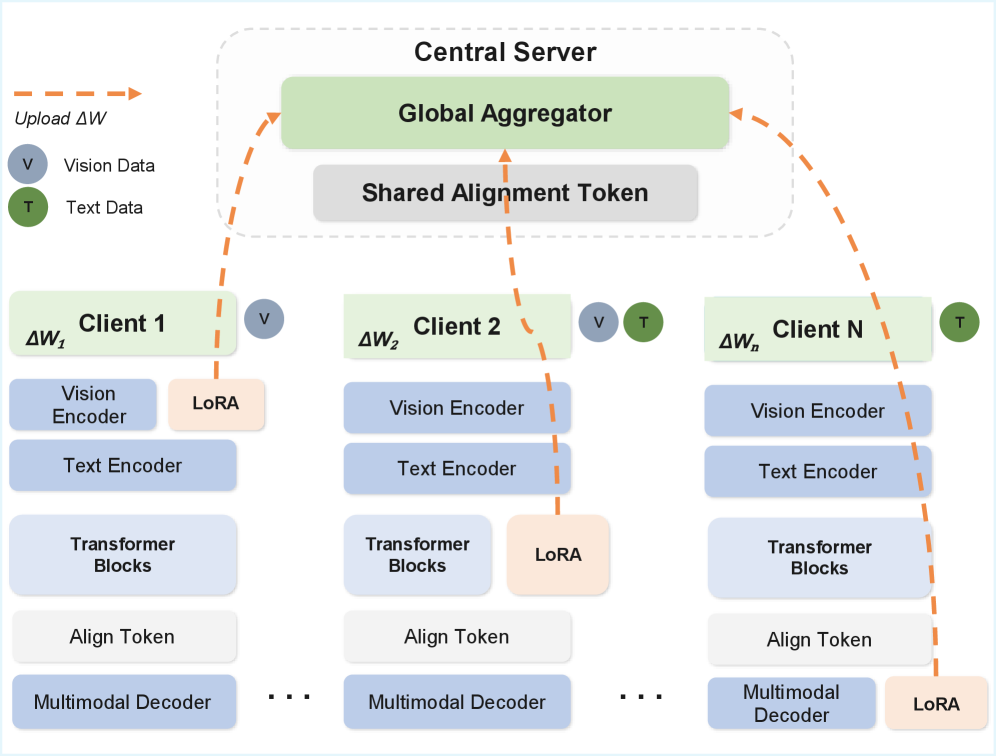
Оптимизация Федеративного Обучения для Мультимодальных Моделей: Эффективность и Точность
Для снижения затрат на передачу данных в федеративном обучении (FL) применяются методы адаптации с низким рангом (LoRA) и сжатия градиентов. LoRA позволяет обучать только небольшое количество дополнительных параметров, снижая объем передаваемых обновлений модели. Сжатие градиентов, в свою очередь, уменьшает размер передаваемых градиентов за счет квантования, разрежения или других методов. Комбинация этих техник значительно снижает требования к пропускной способности сети, что особенно важно при обучении на большом количестве гетерогенных устройств. Например, использование LoRA-based обучения позволяет снизить коммуникационные издержки на 90%.
Алгоритмы FedProx и SCAFFOLD предназначены для решения проблемы статистической неоднородности в федеративном обучении, которая возникает из-за различий в распределении данных между локальными устройствами. FedProx добавляет регуляризационный член к локальной функции потерь, чтобы ограничить отклонение локальных моделей от глобальной модели, тем самым стабилизируя процесс обучения. SCAFFOLD, в свою очередь, использует контроль коррекции для уменьшения влияния смещенных градиентов, вызванных неоднородностью данных, и обеспечивает более быструю сходимость. Оба подхода позволяют предотвратить смещение модели в процессе обучения и повысить общую производительность в условиях гетерогенных данных.
Для реализации и масштабирования федеративного обучения (FL) используются специализированные фреймворки, такие как NVFlare, предоставляющие необходимую инфраструктуру для управления процессами обучения, координации участников и обеспечения безопасности данных. Одновременно с этим, методы взвешивания качества обновлений (Quality Weighting) повышают эффективность агрегации моделей, присваивая больший вес обновлениям от клиентов, демонстрирующих более высокую производительность или качество данных. Это позволяет снизить влияние некачественных или предвзятых обновлений на глобальную модель, что особенно важно в гетерогенных средах, где производительность и качество данных могут существенно различаться между участниками.
Алгоритмы FedCLIP, FedVLM и FedLLM демонстрируют эффективность применения федеративного обучения (FL) к мультимодальным моделям. В частности, разработанный FedUMM фреймворк достигает 97.1% от производительности централизованного обучения на задачах визуального вопросно-ответного анализа (VQA). Это подтверждает возможность сохранения высокой точности модели при децентрализованном обучении на данных, распределенных между различными участниками, без существенной потери качества по сравнению с традиционным подходом.
В рамках Federated Learning (FL) системы FedUMM, использование метода LoRA (Low-Rank Adaptation) позволило добиться снижения объема передаваемых данных на 90%. LoRA предполагает адаптацию предварительно обученной модели посредством обучения лишь небольшого числа параметров, что значительно уменьшает размер обновлений, передаваемых между участниками FL сети. Это снижение коммуникационной нагрузки критически важно для масштабируемости и эффективности обучения больших мультимодальных моделей в условиях ограниченной пропускной способности сети и большого количества участников.
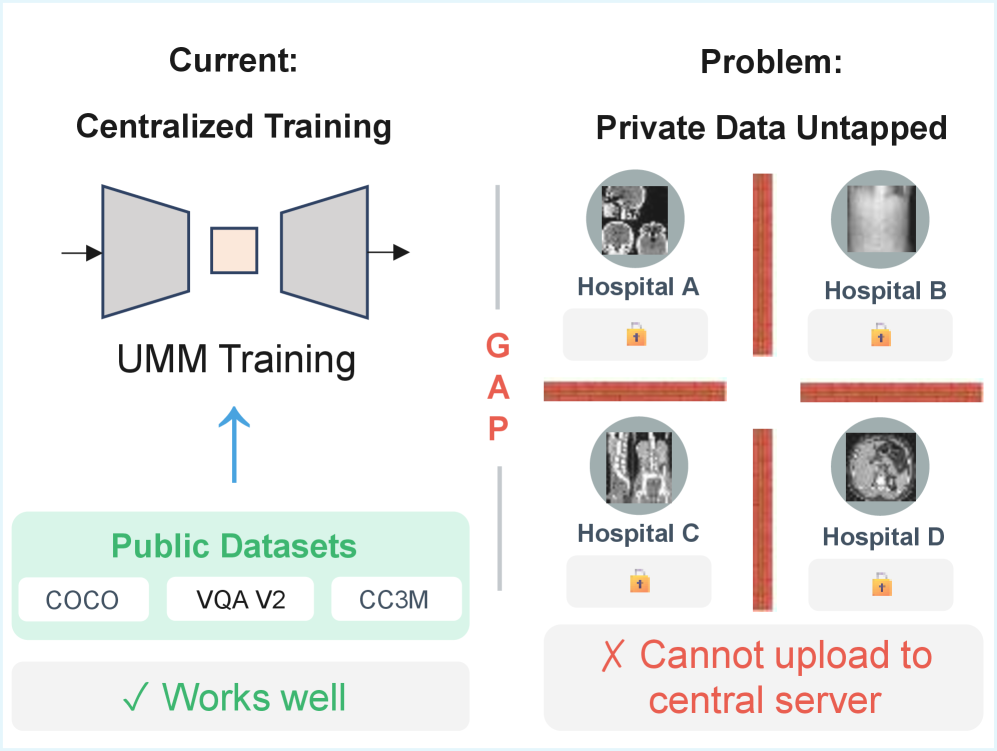
Расширяя Горизонты: Федеративная Инструктивная Настройка и За Гранью
Разработка таких платформ, как OpenFedLLM, демонстрирует значительный потенциал федеративного обучения с подкреплением для адаптации больших языковых моделей к конкретным задачам и наборам данных. Этот подход позволяет обучать модели непосредственно на децентрализованных данных, принадлежащих различным участникам, без необходимости централизации информации. Благодаря этому, обеспечивается повышенная конфиденциальность данных и снижается зависимость от централизованной инфраструктуры. Возможность тонкой настройки моделей на разнообразных, локальных данных позволяет достичь высокой степени специализации и улучшить производительность в конкретных областях применения, сохраняя при этом преимущества масштабируемости и эффективности, присущие федеративному обучению.
Методы, такие как FedMLLM, позволяют осуществлять обучение мультимодальных больших языковых моделей (LLM) в децентрализованной манере, что открывает новые перспективы в области понимания и обработки информации, поступающей из различных источников. Вместо централизованного подхода, требующего сбора и обработки данных на одном сервере, FedMLLM распределяет процесс обучения между множеством устройств или серверов, каждый из которых владеет лишь частью данных. Это не только повышает конфиденциальность данных, но и позволяет обучать модели на гораздо больших и разнообразных наборах данных, недоступных при централизованном обучении. В результате, модели, обученные с использованием FedMLLM, демонстрируют улучшенное понимание взаимосвязей между различными модальностями, такими как текст, изображения и звук, что критически важно для решения сложных задач, требующих интеграции информации из разных источников.
Для повышения конфиденциальности и эффективности при использовании федеративного обучения (FL) применяются такие методы, как разделение вычислений между устройствами и периферийными серверами, а также дифференциальная приватность. Разделение нагрузки позволяет обрабатывать часть данных непосредственно на устройствах, снижая необходимость передачи больших объемов информации на центральный сервер и, следовательно, уменьшая риски утечки данных. В свою очередь, дифференциальная приватность добавляет контролируемый шум к данным или результатам обучения, гарантируя, что вклад каждого отдельного пользователя остается анонимным. Комбинация этих техник не только защищает конфиденциальную информацию, но и существенно снижает вычислительные затраты и требования к пропускной способности сети, делая FL более масштабируемым и применимым в широком спектре сценариев, включая обработку медицинских данных и персонализированные сервисы.
Современные мультимодальные модели, такие как LLaVA, BLIP3o, CoDi и InstructBLIP, демонстрируют впечатляющие результаты в задачах, требующих обработки и понимания информации из разных источников, например, изображений и текста. Эти модели используют передовые методы федеративного обучения, позволяющие обучать их на децентрализованных данных, сохраняя при этом конфиденциальность пользователей. Благодаря этому, они способны достигать передового уровня производительности в задачах, связанных с визуальным вопросно-ответным взаимодействием, описанием изображений и другими мультимодальными приложениями, открывая новые возможности для взаимодействия человека и компьютера и расширяя горизонты искусственного интеллекта.
Оценка качества и надёжности моделей, особенно в контексте федеративного обучения, требует использования строгих бенчмарков. В этой связи, система GenEval играет ключевую роль в проверке производительности. Недавние исследования продемонстрировали, что FedUMM достигает впечатляющей точности в 97.0% на этом бенчмарке, что свидетельствует о сопоставимой эффективности с традиционными методами централизованного обучения. Этот результат подтверждает, что федеративное обучение не только обеспечивает конфиденциальность данных, но и позволяет создавать модели, не уступающие по качеству своим централизованным аналогам, открывая новые возможности для применения в различных областях, где защита данных имеет первостепенное значение.
Исследования показали, что применение FedUMM позволяет значительно оптимизировать процесс обучения больших языковых моделей. В частности, зафиксировано снижение времени работы графических процессоров на клиентских устройствах на 86.7% и уменьшение вычислительной нагрузки на сервер на 87.5% по сравнению с традиционным полным дообучением. Это достижение свидетельствует о высокой эффективности предложенного подхода к федеративному обучению, позволяя снизить потребность в вычислительных ресурсах и повысить доступность передовых моделей для более широкого круга пользователей и организаций. Оптимизация вычислительных затрат открывает новые перспективы для развертывания и применения сложных моделей в условиях ограниченных ресурсов.
Работа, представленная в статье, демонстрирует стремление к созданию гибких и адаптивных систем федеративного обучения. FedUMM, как предложенная архитектура, не стремится к абсолютному контролю над каждым параметром, но скорее создает условия для органического роста модели в распределенной среде. Это напоминает слова Алана Тьюринга: «Мы можем только надеяться, что машины в конечном итоге будут думать». Подобно тому, как Тьюринг предвидел возможности машин, авторы FedUMM признают неизбежность гетерогенности данных и стремятся не подавить её, а использовать во благо, позволяя моделям развиваться в условиях неопределенности и находить оптимальные решения, даже при отсутствии централизованного контроля. Этот подход особенно важен в контексте приватности данных, поскольку позволяет избежать необходимости агрегировать сырые данные, сохраняя при этом высокую производительность модели.
Что дальше?
Представленная работа, словно росток в тени больших деревьев, демонстрирует возможность федеративного обучения, не жертвующего качеством ради приватности. Однако, стоит помнить: система — это не машина, это сад. FedUMM — это лишь один из инструментов для ухода за этим садом, и его эффективность напрямую зависит от качества “почвы” — гетерогенности данных. Устойчивость не в изоляции компонентов, а в их способности прощать ошибки друг друга. Неизбежно возникнет вопрос: как FedUMM поведет себя в условиях радикальной неоднородности — когда модальности данных принципиально различны, а их распределение далеко от идеального?
В дальнейшем, усилия должны быть направлены не на создание более сложных алгоритмов агрегации, а на понимание фундаментальных ограничений федеративного обучения. Каждый архитектурный выбор — это пророчество о будущем сбое. Вместо погони за “централизованной производительностью” стоит сосредоточиться на разработке метрик, отражающих реальную полезность модели для каждого участника. Важно помнить, что приватность — это не просто техническая проблема, но и этический императив.
В конечном счете, успех FedUMM и подобных ему систем будет определяться не их техническими характеристиками, а способностью адаптироваться к непрерывно меняющемуся ландшафту данных и потребностям пользователей. Иначе, этот росток рискует завянуть, не успев дать плоды.
Оригинал статьи: https://arxiv.org/pdf/2601.15390.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-25 06:13