Автор: Денис Аветисян
Новый подход к обучению вариационных автоэнкодеров позволяет создавать более интерпретируемые модели, учитывающие влияние действий на изучаемые системы.
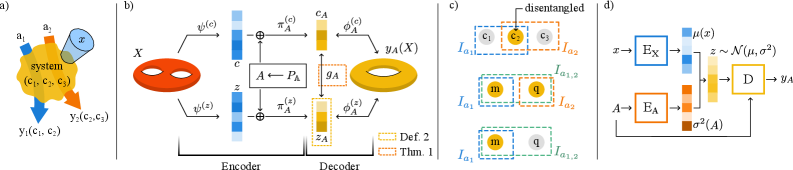
В статье представлена методика Action-Induced Representations (AIR) и архитектура вариационного автоэнкодера (VAIR), улучшающая выделение независимых признаков и позволяющая эффективно идентифицировать физические системы.
Обеспечение интерпретируемости скрытых представлений является ключевой задачей обучения с подкреплением и анализа данных, однако достижение действительно «разделимых» представлений, где каждый параметр соответствует независимому фактору генерации, остается сложной проблемой. В работе ‘Disentanglement by means of action-induced representations’ предложен новый подход, основанный на концепции представлений, индуцированных действиями (AIR), моделирующих системы применительно к выполняемым над ними экспериментам. Показано, что данный фреймворк позволяет гарантированно разделять степени свободы в зависимости от их чувствительности к действиям, а разработанная вариационная архитектура VAIR демонстрирует превосходство над стандартными вариационными автоэнкодерами в задачах интерпретируемости. Способны ли AIR и VAIR стать основой для создания более эффективных моделей понимания и управления физическими системами, учитывающих причинно-следственные связи?
Разгадывая Скрытые Факторы: Вызов Разделения
Во многих задачах машинного обучения ключевым является понимание скрытых факторов, определяющих вариативность данных, однако полученные латентные пространства часто оказываются запутанными и трудно интерпретируемыми. Это означает, что отдельные измерения в латентном пространстве не соответствуют конкретным, независимым признакам исходных данных, что затрудняет анализ и использование этих представлений для решения других задач. Например, при анализе изображений лиц, запутанное латентное пространство может смешивать такие факторы, как поза головы, выражение лица и освещение, делая невозможным изолированное изменение одного из них без влияния на остальные. Таким образом, способность разделять эти факторы вариативности является важной целью в области представления данных и машинного обучения.
Традиционные автокодировщики, несмотря на свою эффективность в сжатии и восстановлении данных, часто сталкиваются с проблемой неспособности выделить независимые факторы вариации. В процессе обучения они формируют латентное пространство, где различные аспекты входных данных переплетаются и взаимозависимы. Это приводит к тому, что отдельные измерения латентного пространства не соответствуют конкретным, интерпретируемым признакам, что существенно ограничивает возможности обобщения модели на новых данных. В результате, снижение производительности наблюдается при решении задач, требующих понимания и манипулирования отдельными факторами вариации, таких как генерация изображений с определенными характеристиками или классификация объектов по их свойствам. Иными словами, переплетенное латентное пространство снижает способность модели к эффективному представлению и использованию информации.
В основе современных исследований машинного обучения лежит стремление к созданию представлений данных, в которых каждая скрытая размерность (latent dimension) отражает отдельный, независимый фактор вариации. Это означает, что вместо сжатия информации в неразличимые компоненты, алгоритмы стремятся выделить и изолировать конкретные аспекты, определяющие данные — например, в изображении лица это может быть угол поворота головы, выражение лица или освещение. Достижение такой «разделимости» (disentanglement) позволяет не только лучше понимать структуру данных, но и значительно улучшает обобщающую способность моделей, позволяя им эффективно работать с новыми, ранее не встречавшимися данными, и успешно решать задачи, требующие манипулирования отдельными факторами вариации. Представьте, что модель может изменить только выражение лица на фотографии, не затрагивая другие характеристики — именно к этому и стремится disentanglement.
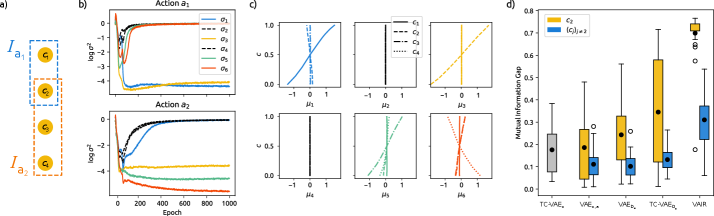
VAIR: Действия как Ключ к Разделению Представлений
VAIR (Variational Action-Induced Representations) представляет собой архитектуру вариационного автоэнкодера, разработанную специально для извлечения представлений, обусловленных действиями (Action-Induced Representations — AIR). В отличие от стандартных вариационных автоэнкодеров, VAIR нацелена на явное кодирование информации о действиях, влияющих на наблюдаемые данные. Это достигается путем интеграции данных о действиях в процесс кодирования и декодирования, что позволяет модели научиться представлять данные таким образом, чтобы отдельные латентные факторы соответствовали определенным действиям или аспектам действий. Архитектура предполагает использование латентного пространства, в котором векторы отражают вклад конкретных действий в формирование наблюдаемых данных.
В основе обучения VAIR лежит оптимизация нижней границы свидетельства (Evidence Lower Bound, ELBO). ELBO состоит из двух основных компонентов: потерь реконструкции и расхождения Кульбака-Лейблера (KL-дивергенции). Потеря реконструкции оценивает, насколько хорошо модель восстанавливает входные данные из латентного пространства. KL-дивергенция, в свою очередь, регуляризует латентное пространство, приближая его к заранее заданному распределению (обычно стандартному нормальному), что способствует обучению более устойчивых и интерпретируемых представлений. Формула ELBO выглядит следующим образом: ELBO = E_{q(z|x)}[log p(x|z)] - D_{KL}(q(z|x)||p(z))[ /latex], где [latex]q(z|x) - апроксимированное апостериорное распределение, p(x|z) - вероятность генерации входных данных при заданном латентном векторе, а p(z) - априорное распределение латентного пространства.
Архитектура VAIR способствует обучению разделенных и интерпретируемых представлений путем явной связи латентных факторов с действиями, выполняемыми в ходе эксперимента. В процессе обучения, каждый латентный фактор моделируется как зависимый от конкретного действия, что позволяет VAIR выучивать представления, где вариации в латентном пространстве соответствуют изменениям в выполняемых действиях. Это обеспечивает более контролируемое и понятное латентное пространство, где каждый фактор может быть связан с определенным аспектом поведения или характеристикой данных, что облегчает анализ и интерпретацию полученных представлений.
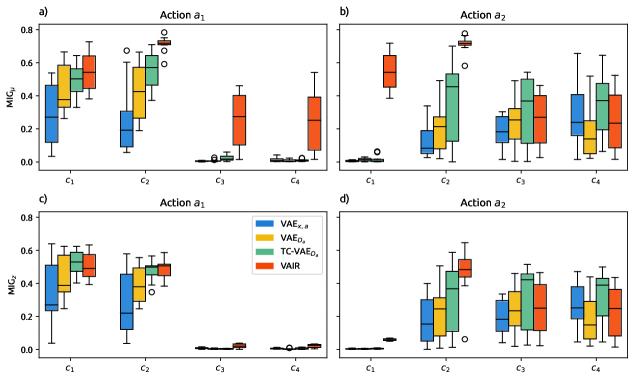
Оценка Разделения: Метрика Взаимной Информации (MIG)
Для оценки степени разделения латентных переменных используется метрика Mutual Information Gap (MIG). MIG количественно определяет степень независимости между этими переменными, основываясь на расчете разницы между взаимной информацией между каждой латентной переменной и входными данными, и взаимной информацией между всеми латентными переменными. MIG = \mathbb{E}_{z \sim p(z)} [I(x; z_i) - I(z_i; z_{\neg i})], где I(X;Y) обозначает взаимную информацию между переменными X и Y, z_i - i-я латентная переменная, а z_{\neg i} - все остальные латентные переменные. Более высокое значение MIG указывает на лучшую степень разделения, поскольку это означает, что каждая латентная переменная содержит информацию, уникальную для входных данных, и не коррелирует с другими латентными переменными.
Для оценки эффективности VAIR проводилось сравнение с базовыми вариационными автоэнкодерами (VAE) и TC-VAE, которые используют функцию потерь Total Correlation Loss (TCL) для стимулирования разделения латентных переменных. TCL направлена на минимизацию взаимной информации между латентными кодами, что теоретически должно приводить к более независимому представлению данных. В отличие от этого, VAIR использует иной подход к достижению разделения, который, как показывают результаты, позволяет добиться более высоких показателей по сравнению с моделями, основанными на TCL. Данное сравнение проводилось для выявления преимуществ VAIR в контексте обучения представлений с разделенными факторами.
Результаты экспериментов демонстрируют, что модель VAIR последовательно превосходит стандартные VAE и TC-VAE по показателям качества разложения представлений, измеряемым с помощью метрики Mutual Information Gap (MIG). Более высокие значения MIG, полученные для VAIR, свидетельствуют о большей независимости между латентными переменными, что указывает на улучшенное разделение факторов в абстрактных экспериментах. MIG количественно оценивает разницу между взаимной информацией между каждой латентной переменной и наблюдаемыми данными, и взаимной информацией между всеми парами латентных переменных. Постоянное превосходство VAIR подтверждает эффективность предложенного подхода к обучению представлений с целью достижения более полного разделения факторов.

Предсказание Будущего: Разделенные Представления для Реконструкции Траекторий
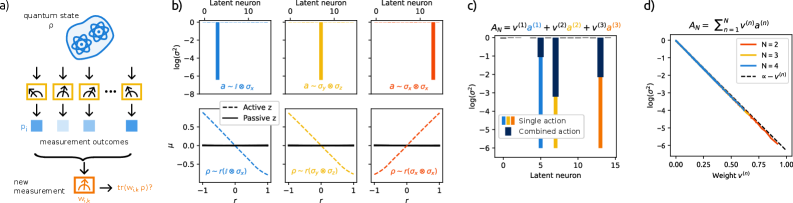
Основой точного восстановления траекторий является использование разделенных представлений, полученных с помощью VAIR. Данный подход позволяет выделить и независимо кодировать различные факторы, влияющие на динамику системы. Вместо обработки комплексных, взаимосвязанных данных, VAIR формирует представления, где каждый компонент соответствует отдельному аспекту - например, скорости, углу или массе. Такая декомпозиция значительно упрощает задачу предсказания будущего состояния системы, поскольку модель может сосредоточиться на каждом факторе в отдельности, повышая как точность, так и устойчивость к шумам и помехам. Благодаря этому, система способна эффективно реконструировать траектории даже в сложных и непредсказуемых сценариях, выделяя значимые переменные и игнорируя несущественные.
Разделение факторов, влияющих на динамику системы, является ключевым для повышения точности и устойчивости прогнозирования. Исследования показали, что при выделении независимых составляющих, определяющих поведение системы, модель приобретает способность более эффективно предсказывать её будущее состояние, даже в условиях неполной информации или шума. Этот подход позволяет отфильтровать незначительные колебания и сосредоточиться на определяющих факторах, что приводит к более надежным результатам. В частности, возможность отделения латентных переменных, соответствующих физическим характеристикам, таким как масса и заряд, значительно улучшает интерпретируемость модели и её способность к обобщению на новые данные. Таким образом, декомпозиция динамики системы на независимые компоненты представляет собой мощный инструмент для улучшения предсказательной силы и надежности моделей.
Исследования демонстрируют применимость VAIR в решении сложных задач, в частности, в реконструкции квантовых состояний посредством квантовой томографии. В ходе экспериментов VAIR успешно освоила представление Блоха для двухкубитного состояния, что позволило выделить интерпретируемые латентные переменные, соответствующие массе и заряду в классическом физическом эксперименте. Этот подход подчеркивает способность VAIR к извлечению значимой информации из сложных данных, открывая возможности для применения в различных областях, от квантовых вычислений до анализа физических систем.
Исследование, представленное в данной работе, демонстрирует, что включение действий в процесс обучения способствует более чёткому разделению представлений, что особенно важно для понимания физических систем. Это согласуется с идеей о том, что любые системы подвержены старению, и лишь адаптация к изменяющейся среде обеспечивает их устойчивость. Как однажды заметил Винтон Серф: «Интернет - это не просто технология, это способ мышления». В контексте данной работы, это можно интерпретировать как необходимость постоянного переосмысления подходов к обучению моделей, учитывая их взаимодействие с динамичной средой. Успех AIR и VAIR архитектур подтверждает, что медленные, постепенные изменения в процессе обучения позволяют создавать более устойчивые и интерпретируемые модели, способные эффективно идентифицировать ключевые аспекты сложных систем.
Что дальше?
Представленная работа, исследуя возможности включения действий в процесс обучения вариационных автоэнкодеров, лишь аккуратно приоткрывает завесу над более глубокой истиной: каждая система стареет, и качество её представления мира определяется не столько способностью к точному моделированию, сколько умением адаптироваться к изменяющимся условиям. Очевидно, что "распутывание" представлений - это не конечная цель, а лишь один из этапов долгого пути к созданию систем, способных не просто прогнозировать, но и понимать причинно-следственные связи, действующие в окружающем мире.
Неизбежно возникают вопросы о масштабируемости предложенного подхода к более сложным системам и о возможности интеграции с другими методами причинно-следственного вывода. Технический долг, накопленный в процессе разработки моделей, подобен закладке прошлого, которую предстоит оплатить настоящим, и будущие исследования должны быть направлены на минимизацию этого долга. Каждый обнаруженный баг - это момент истины на временной кривой развития системы, напоминание о её несовершенстве и стимул к дальнейшему совершенствованию.
Перспективы кажутся очевидными: переход от статических представлений к динамическим моделям, учитывающим историю взаимодействий системы с окружающей средой, и разработка методов, позволяющих извлекать из этих моделей не только информацию о текущем состоянии системы, но и прогнозы о её будущем. Время - не метрика, а среда, в которой существуют системы, и только учитывая эту среду, можно создать модели, способные выдержать испытание временем.
Оригинал статьи: https://arxiv.org/pdf/2602.06741.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Творческий процесс под микроскопом: от логов к искусственному интеллекту
- Квантовый Переворот: От Теории к Реальности
- Плоские зоны: от теории к новым материалам
- Искусственный интеллект на службе редких болезней
- Язык тела под присмотром ИИ: архитектура и гарантии
- Генерация без рисков: как избежать нарушения авторских прав при работе с языковыми моделями
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Видео-Мыслитель: гармония разума и визуального потока.
- Наука, управляемая интеллектом: новая эра открытий
2026-02-09 21:46