Автор: Денис Аветисян
В статье представлена концепция обучения на опыте, позволяющая языковым моделям самостоятельно анализировать свои действия и улучшать результаты в сложных задачах.
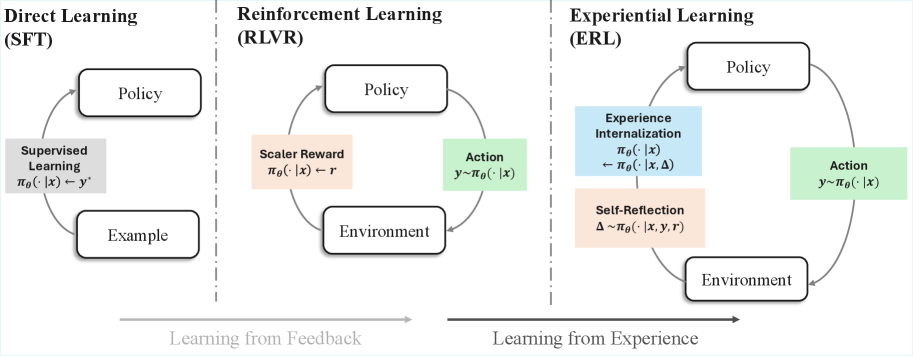
Исследование посвящено методу Experiential Reinforcement Learning (ERL), использующему механизмы рефлексии и интернализации для повышения эффективности обучения больших языковых моделей.
Обучение с подкреплением, несмотря на успехи, часто сталкивается с трудностями при работе с редкими и отложенными сигналами обратной связи. В данной работе представлена парадигма ‘Experiential Reinforcement Learning’ (ERL), встраивающая в процесс обучения языковых моделей явный цикл опыта-рефлексии-консолидации. Этот подход позволяет преобразовывать обратную связь в структурированные поведенческие изменения, повышая эффективность исследования и стабилизируя оптимизацию, при этом сохраняя достигнутые результаты без дополнительных вычислительных затрат. Может ли интеграция саморефлексии в обучение агентов стать ключевым фактором для создания более надежных и адаптивных систем искусственного интеллекта?
Преодолевая Ограничения: За гранью Традиционного Обучения с Подкреплением
Традиционное обучение с подкреплением демонстрирует впечатляющие результаты в различных областях, однако сталкивается с трудностями при решении сложных задач, требующих тонкого рассуждения и долгосрочного планирования. Суть проблемы заключается в том, что алгоритмы часто оптимизируются для немедленного получения вознаграждения, что препятствует эффективному освоению стратегий, приносящих пользу лишь в отдаленной перспективе. Например, в задачах, требующих последовательности действий для достижения конечной цели, традиционные методы могут упускать из виду важные промежуточные шаги, поскольку они не получают немедленного подтверждения их ценности. Это особенно заметно в сценариях, где необходимо учитывать множество взаимосвязанных факторов и принимать решения на основе неполной информации, что значительно снижает эффективность обучения и способность агента адаптироваться к сложным условиям.
Ограничения традиционного обучения с подкреплением часто связаны с его зависимостью от немедленного вознаграждения, что препятствует эффективному обучению в ситуациях, когда полезный сигнал приходит с задержкой или является редким. В подобных сценариях, алгоритм испытывает трудности в установлении связи между предпринятыми действиями и конечным результатом, поскольку промежуточные шаги не получают достаточной оценки. Это особенно критично в задачах, требующих долгосрочного планирования, таких как игра в шахматы или управление сложными системами, где успех зависит от последовательности действий, а не от немедленной выгоды. В результате, алгоритм может застрять в локальном оптимуме или не суметь освоить стратегию, требующую терпения и прогнозирования.
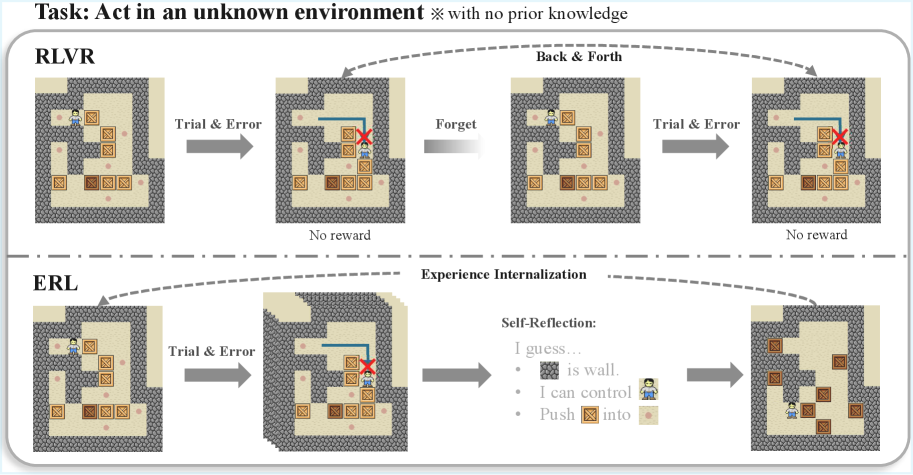
Самообучение: Цикл Опыта, Рефлексии и Консолидации
Обучение с подкреплением на основе опыта (ERL) представляет собой расширение традиционных алгоритмов обучения с подкреплением за счет внедрения внутреннего контура «Отражение-Консолидация опыта». В отличие от стандартных методов, ERL позволяет агентам не только действовать и получать вознаграждение, но и активно анализировать накопленный опыт. Этот внутренний контур обеспечивает возможность извлечения полезных знаний из прошлых взаимодействий, что позволяет агенту более эффективно адаптироваться к изменяющимся условиям и демонстрировать более устойчивое поведение. Фактически, ERL позволяет агенту учиться не только на прямом опыте, но и на рефлексии над этим опытом.
Цикл опытного обучения (Experience Reflection Consolidation Loop) состоит из трех последовательных этапов. На этапе рефлексии агент анализирует накопленный опыт, выделяя ключевые события и их последствия. Далее, на этапе консолидации, происходит обобщение извлеченных знаний и формирование устойчивых представлений о закономерностях среды. Завершающим этапом является применение консолидированных знаний при выборе будущих действий, что позволяет агенту демонстрировать более устойчивое и адаптивное поведение в различных ситуациях и повышает эффективность обучения в долгосрочной перспективе.
Алгоритм оптимизации GRPO (Gradient-based Reinforcement Learning with Policy Optimization) играет ключевую роль в эффективном обучении агентов в рамках ERL, обеспечивая стабильное и быстрое схождение к оптимальной политике. В отличие от традиционных алгоритмов RL, GRPO использует градиентные методы для одновременной оптимизации как политики, так и функции ценности, что позволяет снизить дисперсию и ускорить процесс обучения. Эффективность GRPO обусловлена применением методов trust region для ограничения изменений политики на каждом шаге, предотвращая резкие колебания и обеспечивая устойчивость обучения даже в сложных средах. Данный алгоритм особенно эффективен при работе с большими пространствами состояний и действий, характерными для задач, решаемых с помощью ERL.
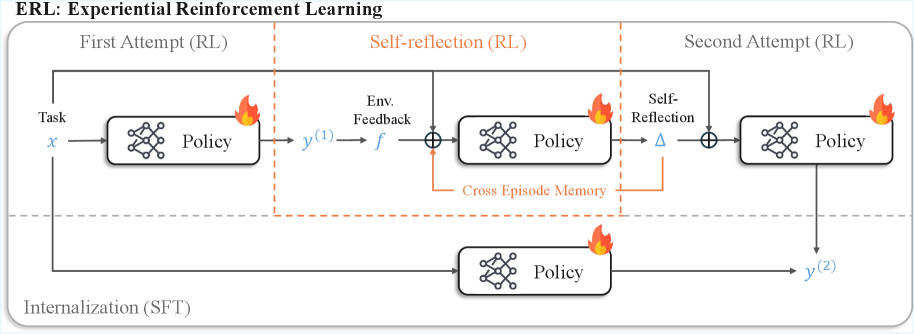
Самокритика и Внутренняя Трансформация: Учимся на Своих Ошибках
Рефлексия, являясь ключевым компонентом обучения с эпизодической рефлексией (ERL), представляет собой процесс анализа агентом собственного опыта и генерации самокритики. Этот анализ часто опирается на текстовую обратную связь, позволяющую агенту понять причины тех или иных исходов. Текстовые отзывы могут содержать информацию об ошибках, успешных стратегиях или альтернативных подходах, что позволяет агенту выявить закономерности и улучшить свою производительность. В процессе рефлексии агент не просто фиксирует результат действия, но и пытается понять, почему этот результат был достигнут, и как избежать ошибок в будущем.
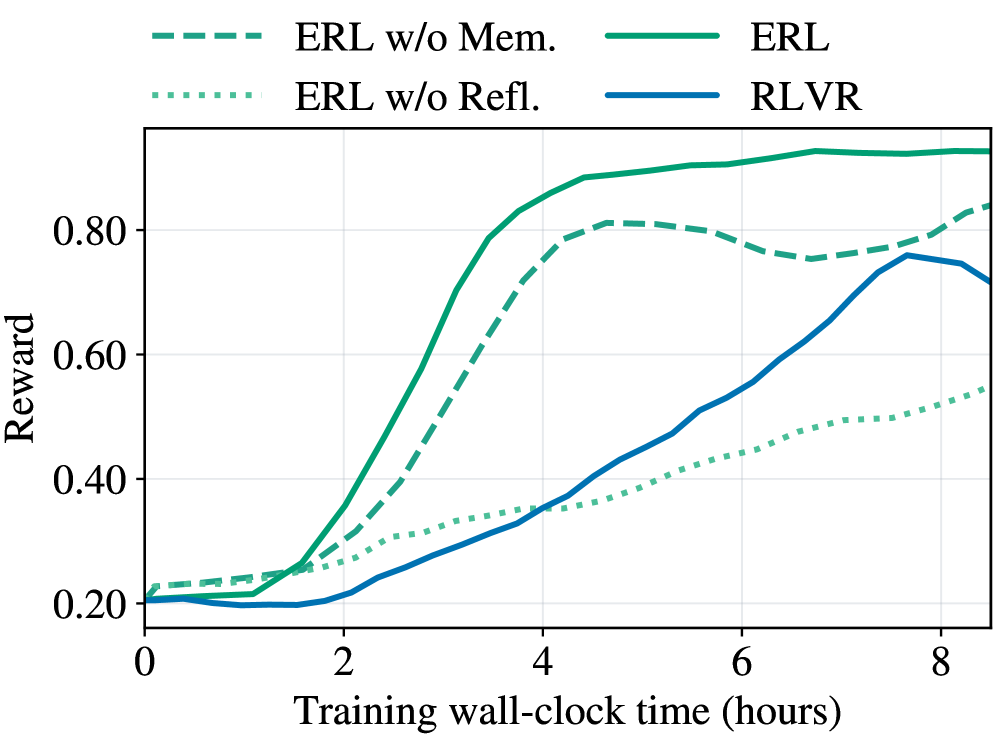
Процесс обучения с использованием саморефлексии (ERL) опирается на механизм кросс-эпизодической памяти рефлексии (Cross-Episode Reflection Memory), предназначенный для хранения и повторного использования успешных шаблонов самоанализа, сформированных в ходе различных эпизодов обучения. Эта память позволяет агенту не начинать процесс рефлексии с нуля в каждом новом эпизоде, а использовать накопленный опыт для более быстрой адаптации и повышения эффективности обучения. Повторное использование успешных стратегий самокритики значительно ускоряет сходимость обучения и позволяет агенту быстрее осваивать новые навыки и решать более сложные задачи, избегая повторных ошибок и оптимизируя процесс поиска оптимальной стратегии поведения.
Процесс интернализации в рамках обучения на основе рефлексии (ERL) обеспечивает закрепление полученных знаний в базовой политике агента посредством селективной дистилляции. Данный метод позволяет отобрать наиболее эффективные стратегии, выявленные в процессе самокритики и рефлексии, и интегрировать их в основную модель поведения агента. В отличие от простого добавления новых стратегий, селективная дистилляция фокусируется на усилении существующей политики, что приводит к устойчивым изменениям в поведении и предотвращает переобучение или ухудшение производительности. Это гарантирует, что улучшения, полученные в ходе эпизодов обучения, не будут потеряны после завершения процесса рефлексии, обеспечивая постоянный прогресс и адаптацию агента.
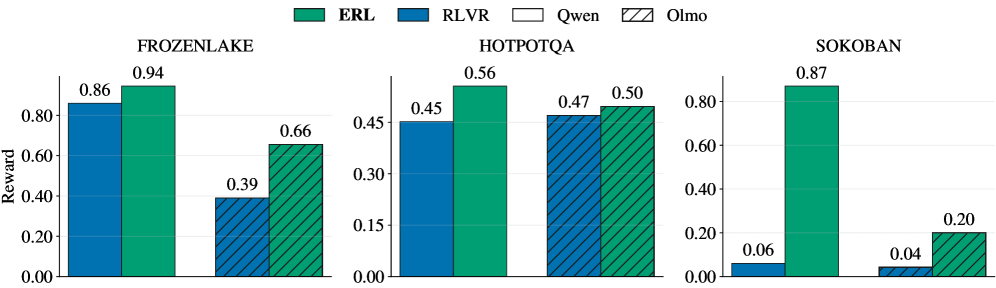
Использование обучения с подкреплением и верифицируемой наградой (RLVR) выигрывает от процесса рефлексии, поскольку она обеспечивает более информативный сигнал обратной связи. Экспериментальные данные демонстрируют, что обучение на основе рефлексии (ERL) систематически превосходит RLVR в различных задачах: прирост производительности достигает 81% в головоломке Sokoban, 27% в среде FrozenLake и 11% в задаче HotpotQA. Эти результаты подтверждают, что рефлексия значительно улучшает способность агента к обучению и адаптации.
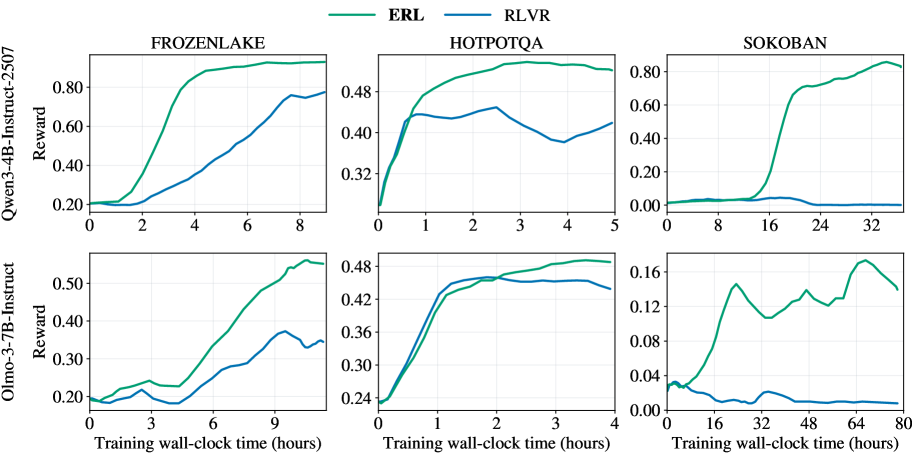
Надежность в Разнообразных Средах: Преодолевая Сложность
Исследования показали, что разработанный фреймворк ERL демонстрирует значительную приспособляемость к задачам различной сложности. В рамках экспериментальной проверки, система успешно прошла тестирование в разнообразных средах, включая симуляцию скользкого льда в FrozenLake, логическую головоломку Sokoban, требующую планирования маршрута, и задачу HotpotQA, связанную с извлечением информации из сложных текстовых источников. Способность ERL эффективно функционировать в столь отличающихся областях указывает на его универсальность и потенциал для применения в широком спектре реальных задач, где требуется адаптация к меняющимся условиям и сложным требованиям.
Разработанная платформа продемонстрировала передовые результаты благодаря асинхронной генерации траекторий, реализованной с использованием vLLM. В ходе тестирования на различных задачах, включая FrozenLake, HotpotQA и Sokoban, зафиксировано значительное увеличение вознаграждения: на 27% в среде FrozenLake, на 11% в задаче HotpotQA и впечатляющие 81% в среде Sokoban. Эти результаты указывают на высокую эффективность и потенциал платформы для применения в реальных задачах, требующих обучения с подкреплением, и позволяют говорить о преодолении ограничений, присущих традиционным алгоритмам обучения с подкреплением.
Наблюдаемые улучшения в эффективности использования данных и способности к обобщению указывают на то, что разработанная система обучения с подкреплением (ERL) успешно преодолевает ключевые ограничения, свойственные традиционным алгоритмам. В отличие от классических подходов, требующих огромного количества проб и ошибок для достижения приемлемых результатов, ERL демонстрирует способность к более быстрому обучению и адаптации к новым, ранее не встречавшимся ситуациям. Это достигается за счет оптимизированного процесса исследования и использования полученного опыта, что позволяет системе эффективно строить обобщенные модели поведения. Подобные характеристики открывают возможности для применения ERL в задачах, где сбор данных затруднен или требует значительных затрат, а также в сценариях, требующих высокой степени адаптивности к меняющимся условиям окружающей среды.
Будущее Адаптивного Интеллекта: Взгляд в Перспективу
Основанный на интеграции опыта, рефлексии и консолидации, подход ERL (Experience-Reflection-Learning) представляет собой перспективный путь к созданию более устойчивого, адаптивного и приближенного к человеческому интеллекту. В отличие от традиционных методов машинного обучения, полагающихся исключительно на накопление данных, ERL позволяет агентам не просто запоминать информацию, но и анализировать свой опыт, выявлять закономерности и корректировать стратегии поведения. Этот процесс самоанализа и оптимизации, имитирующий когнитивные функции человека, обеспечивает повышенную устойчивость к изменениям в окружающей среде и возможность эффективного обучения даже в условиях неопределенности. Благодаря такому подходу, искусственные агенты способны не только решать поставленные задачи, но и адаптироваться к новым ситуациям, проявляя гибкость и креативность, что делает ERL ключевым направлением в развитии по-настоящему интеллектуальных систем.
Дальнейшие исследования в области Experience Replay Learning (ERL) направлены на расширение его возможностей для решения задач возрастающей сложности. Особое внимание уделяется разработке более информативных механизмов обратной связи, позволяющих агенту получать не только количественные оценки, но и качественные характеристики выполненных действий. Параллельно ведется работа над оптимизацией алгоритмов самоанализа, что позволит значительно повысить эффективность процесса обучения и сократить время, необходимое для достижения оптимальных результатов. Ученые стремятся создать системы, способные не просто запоминать успешные стратегии, но и критически оценивать их, адаптируясь к меняющимся условиям и непредвиденным обстоятельствам, что приблизит искусственный интеллект к человеческому уровню рассуждений и обучения.
Основательный подход, лежащий в основе ERL, представляет собой значительный шаг на пути к созданию интеллектуальных агентов, способных к обучению и успешной адаптации в постоянно меняющихся и непредсказуемых условиях. В отличие от традиционных систем искусственного интеллекта, которые часто демонстрируют хрупкость при столкновении с незнакомыми ситуациями, ERL позволяет агентам не только накапливать опыт, но и анализировать его, извлекая уроки и совершенствуя свои стратегии. Это обеспечивает не просто реакцию на внешние раздражители, а проактивное поведение, направленное на достижение целей даже в условиях неопределенности. Способность к самоанализу и консолидации знаний делает таких агентов более устойчивыми к ошибкам и позволяет им эффективно функционировать в сложных и динамичных средах, открывая новые возможности для применения в самых разных областях — от робототехники и автономных систем до разработки интеллектуальных помощников и систем поддержки принятия решений.
Исследование, представленное в данной работе, демонстрирует подход к обучению больших языковых моделей, выходящий за рамки традиционного подкрепляющего обучения. Внедрение механизмов рефлексии и интернализации позволяет агентам не просто накапливать опыт, но и анализировать его, формируя более глубокое понимание решаемых задач. Этот процесс созвучен утверждению Брайана Кернигана: «Простота — это высшая степень совершенства». Подобно тому, как стремление к простоте в коде требует глубокого понимания системы, так и ERL требует от модели способности к самоанализу и коррекции, что ведет к повышению эффективности и производительности в сложных рассуждениях. Очевидно, что акцент на внутреннем анализе опыта становится ключевым фактором в развитии искусственного интеллекта.
Что дальше?
Представленный подход к обучению с подкреплением, акцентирующий рефлексию и интернализацию, неизбежно поднимает вопрос о границах “разумности” агента. Успешная самокоррекция — это лишь видимость понимания, или реальное приближение к осмысленному решению? Дальнейшие исследования должны сосредоточиться на проверке этой самой “внутренней модели” — как агент представляет и использует информацию о своих ошибках. Недостаточно просто научить систему исправлять оплошности; необходимо понять, понимает ли она, что исправила.
Очевидным направлением является исследование влияния структуры рефлексии на эффективность обучения. Должна ли рефлексия быть жестко заданной процедурой, или же агенту следует позволить самостоятельно формировать её правила? И как это соотносится с проблемой “раздувания” модели — насколько сложной может быть система самоанализа, прежде чем она начнет тормозить процесс обучения? Ведь, как показывает опыт, любая система оптимизации неизбежно находит способы обхода заданных ограничений, иногда весьма неожиданные.
В конечном счете, настоящий вызов заключается в создании агента, способного не просто выполнять задачи, но и адаптироваться к принципиально новым ситуациям, не требующим предварительного обучения. И это, пожалуй, потребует не столько улучшения алгоритмов обучения, сколько пересмотра самой концепции “интеллекта” — отказа от антропоцентричных представлений о нём и признания возможности существования принципиально иных форм разумности. Ведь, в конце концов, правила созданы для того, чтобы их нарушать.
Оригинал статьи: https://arxiv.org/pdf/2602.13949.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Языковые модели и границы возможного: что делает язык человеческим?
- Память на заказ: Как обучить агентов взаимодействовать эффективнее
- Взрыв скорости: Оптимизация внимания для современных GPU
- Ребусы для ИИ: новый масштабный тест на сообразительность
- Гендерные стереотипы в найме: что скрывают языковые модели?
- Таблицы оживают: Искусственный интеллект осваивает структурированные данные
- Понимание ориентации объектов: новый взгляд на 3D-пространство
- Симуляция, которая видит себя: новый подход к физическому моделированию
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Квантовый разум: Новая эра языковых моделей
2026-02-17 11:22