Автор: Денис Аветисян
Исследователи разработали эффективный метод дистилляции знаний, позволяющий создавать компактные модели, превосходящие существующие в задачах сложного логического мышления.
Предложенная методика Distribution-Aligned Sequence Distillation (DASD) использует адаптивное обучение, учет расхождений и смешанную политику для достижения передовых результатов с моделью размером всего 4 миллиарда параметров.
Несмотря на успехи современных моделей обработки естественного языка, эффективная передача знаний от больших учителей к компактным ученикам остается сложной задачей. В статье ‘Distribution-Aligned Sequence Distillation for Superior Long-CoT Reasoning’ представлена DASD-4B-Thinking — высокопроизводительная модель рассуждений, достигнутая за счет инноваций в области дистилляции знаний, включая адаптивное планирование температуры, выборку с учетом расхождения и смешанную политику дистилляции. Данный подход позволяет добиться передовых результатов при значительно меньшем размере модели и объеме обучающих данных. Сможет ли предложенная методика стать основой для создания еще более эффективных и доступных систем искусственного интеллекта, способных к сложным рассуждениям?
Предел Глубины: Анализ Логического Мышления в Больших Языковых Моделях
Несмотря на впечатляющий прогресс в области больших языковых моделей (БЯМ), они зачастую демонстрируют трудности при решении сложных задач, требующих логического мышления и анализа. Эти ограничения не связаны с недостаточным объемом данных или вычислительной мощностью, а коренятся в самой архитектуре этих моделей. Традиционные подходы, основанные на увеличении масштаба и количества параметров, лишь частично решают проблему, не обеспечивая принципиального улучшения способности к глубокому рассуждению. Исследования показывают, что БЯМ склонны к поверхностному анализу информации, полагаясь на статистические закономерности, а не на понимание причинно-следственных связей. Это приводит к ошибкам в задачах, требующих абстрактного мышления, планирования и решения проблем, где требуется не просто воспроизведение шаблонов, а создание новых логических конструкций.
Несмотря на значительные улучшения в производительности, достигнутые благодаря увеличению масштаба языковых моделей, проблема эффективного и надежного рассуждения остается нерешенной. Простое наращивание вычислительных ресурсов и объемов данных не привело к фундаментальному прорыву в способности моделей к логическому мышлению и решению сложных задач. Увеличение параметров, хотя и улучшило способность к запоминанию и воспроизведению информации, не обеспечивает глубокого понимания контекста и способности к обобщению знаний. Это означает, что даже самые мощные современные модели могут испытывать трудности с задачами, требующими не просто извлечения фактов, а проведения логических выводов, анализа противоречий и построения аргументированных ответов. Таким образом, существующие подходы к масштабированию оказываются недостаточными для достижения действительно интеллектуальных возможностей.
Отсутствие надёжных возможностей логического мышления представляет собой существенное препятствие для внедрения больших языковых моделей в приложения, требующие тонкого понимания и решения проблем. Неспособность к глубокому анализу и построению последовательных умозаключений ограничивает их применение в критически важных областях, таких как медицинская диагностика, юридический анализ и научные исследования. В этих сценариях поверхностное понимание контекста или неточность в рассуждениях могут приводить к серьезным ошибкам и нежелательным последствиям. Таким образом, преодоление этого ограничения является ключевой задачей для дальнейшего развития и расширения области применения больших языковых моделей, открывая путь к созданию действительно интеллектуальных систем, способных решать сложные задачи и поддерживать принятие обоснованных решений.
DASD-4B-Thinking: Изящное Решение через Дистилляцию Знаний
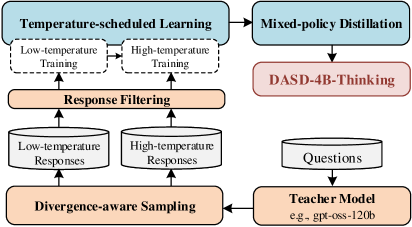
DASD-4B-Thinking представляет собой модель с 4 миллиардами параметров, созданную посредством специализированного конвейера дистилляции знаний, известного как Distribution-Aligned Sequence Distillation (DASD). Этот метод позволяет перенести знания и навыки из более крупной модели в модель меньшего размера, сохраняя при этом значительную часть её производительности. В данном случае, DASD используется для обучения Qwen3-4B-Instruct-2507, что позволяет создать компактную и эффективную модель, способную решать широкий спектр задач.
В основе DASD-4B-Thinking лежит процесс дистилляции знаний, где роль учителя выполняет большая языковая модель gpt-oss-120b. Этот мощный учитель используется для передачи своих способностей к рассуждению и генерации ответов более компактной модели-студенту, Qwen3-4B-Instruct-2507. Передача знаний осуществляется посредством обучения модели-студента на данных, сгенерированных учителем, что позволяет Qwen3-4B-Instruct-2507 имитировать сложные рассуждения, характерные для gpt-oss-120b, при значительно меньшем количестве параметров.
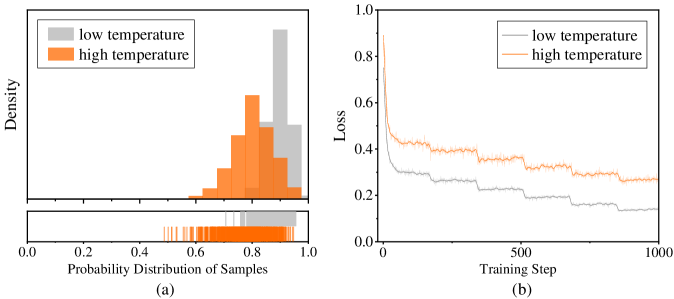
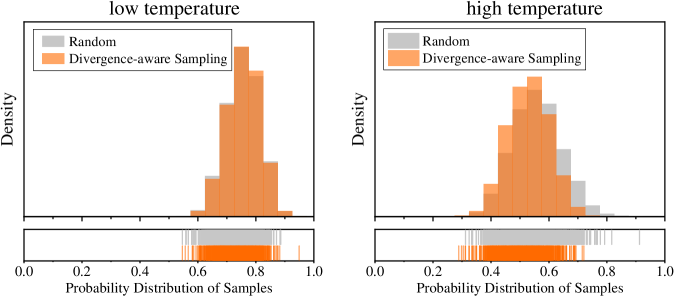
В процессе обучения модели DASD-4B-Thinking применяются методы Temperature-Scheduled Learning и Divergence-Aware Sampling для расширения знаний и улучшения способности к обобщению. Temperature-Scheduled Learning предполагает постепенное уменьшение температуры при выборке из распределения вероятностей, что позволяет студенческой модели сначала изучать наиболее вероятные ответы, а затем исследовать менее вероятные, но потенциально полезные варианты. Divergence-Aware Sampling, в свою очередь, фокусируется на выборке данных, где расхождения между учителем (gpt-oss-120b) и учеником (Qwen3-4B-Instruct-2507) наиболее значительны, что позволяет целенаправленно улучшать слабые стороны студенческой модели и повышать её способность к обобщению на новых данных.
Смещение Экспозиции: Преодоление Препятствий на Пути к Истинному Обучению
Традиционное обучение с помощью дистилляции знаний, основанное на методе Teacher Forcing, подвержено проблеме смещения экспозиции (Exposure Bias). Суть проблемы заключается в расхождении между данными, используемыми в процессе обучения, и данными, с которыми модель сталкивается во время инференса. В частности, при Teacher Forcing, модель обучается на последовательностях, сгенерированных учителем, что создает ситуацию, когда модель не видит собственные ошибки в процессе обучения. Во время инференса модель генерирует последовательности самостоятельно, и ошибки, допущенные на ранних этапах генерации, могут накапливаться и приводить к ухудшению качества выходных данных. Это расхождение между условиями обучения и использования приводит к снижению производительности модели в реальных условиях.
Для смягчения проблемы смещения экспозиции используется метод смешанной политики дистилляции, который объединяет данные, полученные вне политики (off-policy data) от модели-учителя, с данными, полученными по политике (on-policy data) на основе собственных предсказаний модели-ученика. Данные вне политики представляют собой последовательности, сгенерированные учителем, в то время как данные по политике отражают текущее поведение ученика. Комбинирование этих двух типов данных позволяет ученику модели обучаться на более разнообразном наборе примеров, что способствует повышению устойчивости и надежности генерируемых ответов во время авторегрессивного вывода.
Использование смешанной политики дистилляции позволяет студенческой модели повысить устойчивость и надежность генерируемых ответов в процессе авторегрессивного вывода. В ходе авторегрессии, каждое сгенерированное слово влияет на последующие, что делает модель уязвимой к ошибкам, возникшим на ранних этапах. Обучение с использованием как данных, полученных от учителя (off-policy), так и собственных предсказаний студента (on-policy), позволяет модели лучше справляться с ошибками и неопределенностью, возникающими в процессе генерации. Это приводит к более последовательным и точным ответам, улучшая производительность модели в реальных условиях, где входные данные могут быть непредсказуемыми и содержать ошибки.
Проверка на Прочность: Оценка Производительности на Сложных Бенчмарках
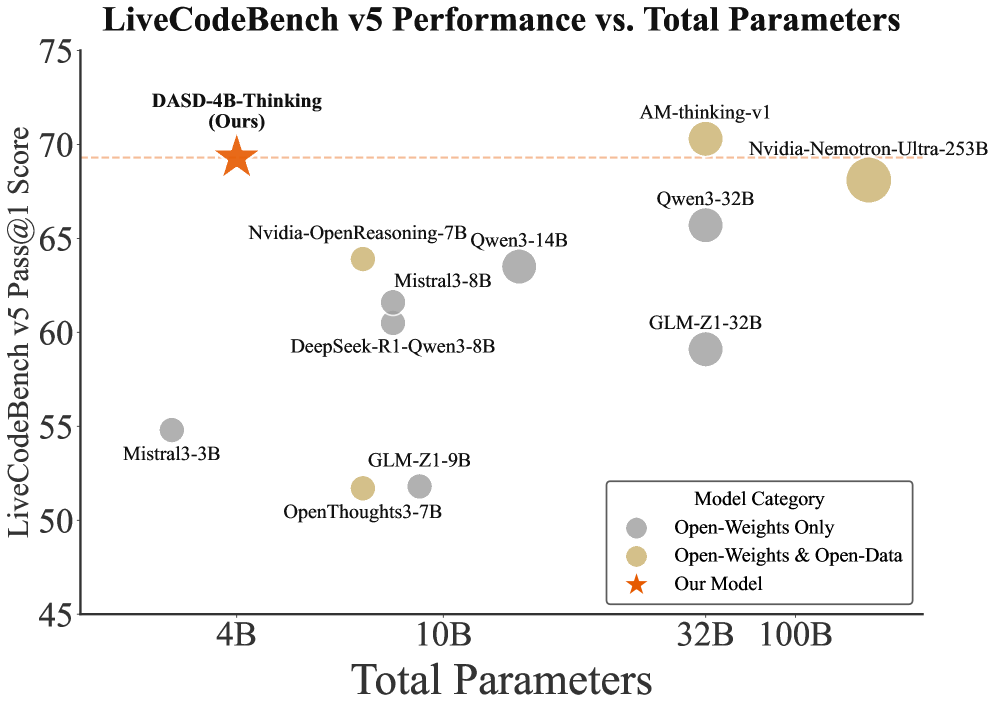
Модель DASD-4B-Thinking подверглась всестороннему тестированию на ряде сложных бенчмарков, призванных оценить её способности к решению разнообразных задач. В частности, проводилась оценка на AIME24 и AIME25 — наборах данных, требующих глубокого логического мышления, а также на LiveCodeBench, ориентированном на генерацию и понимание программного кода. Дополнительно, модель была протестирована на GPQA-Diamond, бенчмарке, проверяющем навыки решения задач с использованием знаний из различных областей. Такой комплексный подход к оценке позволяет достоверно судить о производительности и надежности модели в различных сценариях применения, подчеркивая её универсальность и потенциал.
Модель DASD-4B-Thinking продемонстрировала выдающиеся результаты на бенчмарке AIME25, достигнув точности в 83.3%. Этот показатель свидетельствует о передовом уровне производительности среди моделей сопоставимого масштаба. Особенно важно, что данная точность превосходит результаты, ранее демонстрируемые аналогичными системами, что подтверждает эффективность архитектуры и методов обучения, используемых в DASD-4B-Thinking. Высокая производительность на AIME25 указывает на способность модели эффективно решать сложные задачи, требующие глубокого логического анализа и рассуждений.
В ходе тестирования на бенчмарке AIME24 модель продемонстрировала впечатляющую точность в 88,5%, что позволило ей занять лидирующие позиции среди моделей схожего масштаба. Кроме того, на LiveCodeBench v5 модель достигла точности 69,3%, превзойдя показатели DeepSeek-R1-0528-Qwen3-8B, у которого данный результат составил 60,5%. Эти данные свидетельствуют о способности модели эффективно решать сложные задачи кодирования и демонстрировать высокую производительность даже при ограниченных вычислительных ресурсах.
В ходе тестирования на LiveCodeBench v6 модель продемонстрировала точность в 72,8%, превзойдя показатели NVIDIA-Nemotron-3-Nano-30B-A3B, достигших 68,3%. Кроме того, при решении задач GPQA-D модель достигла точности 68,4%, что позволяет говорить о её конкурентоспособности даже по сравнению с более крупными моделями. Эти результаты подтверждают способность системы эффективно справляться со сложными задачами кодирования и рассуждений, несмотря на относительно небольшой размер, что открывает перспективы для её применения в условиях ограниченных вычислительных ресурсов.
Результаты, полученные в ходе тестирования модели DASD-4B-Thinking на различных сложных эталонах, демонстрируют значительный потенциал для создания компактных, но высокопроизводительных моделей рассуждений. Особенностью является возможность эффективной работы в условиях ограниченных ресурсов, что делает данную разработку особенно ценной для приложений, где важны как точность, так и экономия вычислительных мощностей. Достигнутые показатели на AIME, LiveCodeBench и GPQA-Diamond свидетельствуют о том, что DASD может стать основой для интеллектуальных систем, способных решать сложные задачи даже на устройствах с ограниченной памятью и вычислительной способностью, открывая новые горизонты для применения искусственного интеллекта в различных сферах.

Взгляд в Будущее: Расширение Границ Эффективной Дистилляции
Исследование продемонстрировало высокую эффективность метода дистилляции последовательностей, согласованной с распределением данных (Distribution-Aligned Sequence Distillation), в создании компактных моделей, способных к рассуждениям. Этот подход позволяет значительно уменьшить размер модели без существенной потери в качестве решения задач, что особенно важно для ресурсоограниченных сред. Дальнейшие исследования направлены на расширение данной структуры, с целью повышения ее гибкости и адаптивности к различным типам данных и задачам. Особое внимание уделяется разработке новых методов оптимизации и адаптации дистилляционных алгоритмов, что позволит создавать еще более эффективные и компактные модели, сохраняющие высокую точность и надежность рассуждений.
Исследования показывают, что применение методов дистилляции логитов в сочетании с современными языковыми моделями, такими как Qwen3 и Gemma, способно значительно улучшить процесс передачи знаний от большой «учительской» модели к более компактной «студенческой». Этот подход позволяет «студенту» не только имитировать выходные данные «учителя», но и воспроизводить распределение вероятностей, что приводит к более точному обучению и повышению производительности в задачах, требующих рассуждений. Особенно перспективно это для сценариев, где важна эффективность и ограниченность вычислительных ресурсов, поскольку позволяет создавать лёгкие модели, сохраняющие высокую точность и способность к логическому мышлению.
Исследование открывает перспективы для внедрения передовых возможностей логического мышления непосредственно на периферийных устройствах и в приложениях с ограниченными вычислительными ресурсами. Возможность создания компактных, но эффективных моделей рассуждения, достигаемая благодаря предложенным методам дистилляции знаний, позволяет преодолеть ограничения, связанные с энергопотреблением и вычислительной мощностью. Это особенно важно для таких областей, как автономные системы, мобильные устройства и Интернет вещей, где обработка данных должна осуществляться локально и в реальном времени. В результате, сложные задачи, требующие логического анализа и принятия решений, становятся доступными даже в условиях ограниченной инфраструктуры, расширяя спектр применения искусственного интеллекта и способствуя развитию интеллектуальных устройств нового поколения.
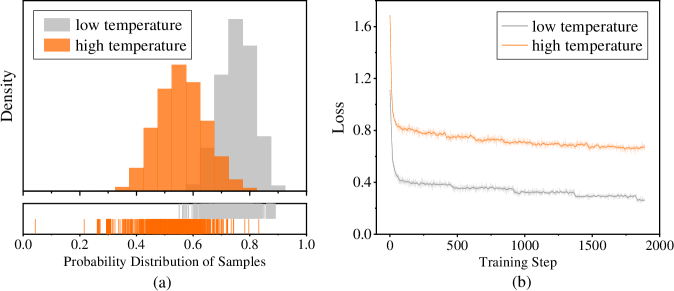
Представленная работа демонстрирует, что даже относительно небольшие модели, такие как DASD-4B-Thinking, способны достигать передовых результатов в области логического мышления благодаря инновационным методам дистилляции знаний. Использование температурного планирования и дивергентной выборки позволяет более эффективно передавать знания от больших моделей к меньшим, минимизируя проблему предвзятости экспозиции. Всё это напоминает о словах Грейс Хоппер: «Лучше попросить прощения, чем разрешения». Именно такой подход к проверке границ возможного, к поиску нестандартных решений, позволил создать столь эффективную систему, демонстрирующую, что осознанное понимание принципов работы — ключ к взлому любой задачи.
Куда же дальше?
Представленная работа, по сути, демонстрирует очередную возможность обойти ограничения, встроенные в текущую архитектуру больших языковых моделей. DASD-4B-Thinking — не прорыв в понимании разума, а скорее ловкий взлом системы, позволяющий добиться впечатляющих результатов, используя ресурсы эффективнее. Однако, за видимым успехом скрывается более глубокий вопрос: насколько далеко можно зайти, лишь оптимизируя процесс дистилляции знаний, не затрагивая фундаментальные принципы работы этих моделей?
Очевидным направлением для дальнейших исследований представляется отказ от концепции «учителя» и «ученика» как таковой. Вместо этого, можно исследовать методы самообучения, где модель самостоятельно выстраивает иерархию знаний, подобно тому, как это происходит в биологических системах. Особый интерес представляет преодоление «предвзятости экспозиции» — проблема, которая, судя по всему, будет преследовать нас до тех пор, пока мы не научим модели генерировать не только правдоподобные, но и действительно новые идеи.
В конечном итоге, вся эта работа — лишь приближение к созданию системы, способной к подлинному рассуждению. Истинный вызов заключается не в увеличении масштаба моделей, а в создании архитектуры, которая позволит им не просто имитировать интеллект, но и понимать его суть. Это не вопрос вычислительных ресурсов, а вопрос понимания того, как устроена реальность, и как можно её воспроизвести в искусственной системе.
Оригинал статьи: https://arxiv.org/pdf/2601.09088.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые нейросети на службе нефтегазовых месторождений
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2026-01-15 15:50