Автор: Денис Аветисян
Новый подход к обучению моделей «зрение-язык-действие» позволяет значительно повысить эффективность манипуляций роботов в реальном мире.
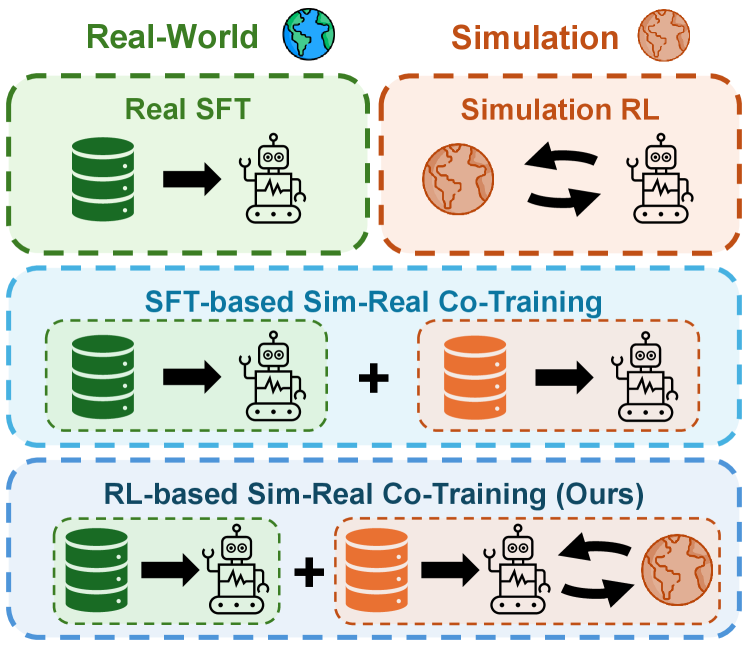
Предложена методика совместного обучения в симуляции и реальности на основе обучения с подкреплением для моделей, управляющих роботами.
Несмотря на перспективность использования симуляций для обучения моделей «зрение-язык-действие» (VLA), существующие подходы часто не позволяют в полной мере использовать потенциал интерактивного взаимодействия. В данной работе, посвященной разработке фреймворка ‘RLinf-Co: Reinforcement Learning-Based Sim-Real Co-Training for VLA Models’, предложен метод совместного обучения в симуляции и на реальных данных, основанный на обучении с подкреплением, который позволяет значительно повысить эффективность и обобщающую способность роботов-манипуляторов. Эксперименты на четырех задачах показали увеличение успешности реальных манипуляций до 24% при использовании архитектуры OpenVLA и 20% для \pi_{0.5}, демонстрируя превосходство над традиционными подходами. Можно ли масштабировать данный фреймворк для решения более сложных задач и расширить его применение на другие типы робототехнических систем?
Преодоление Разрыва Между Симуляцией и Реальностью: Вызовы Робототехники
Роботизированные системы часто сталкиваются с трудностями при переносе навыков, приобретенных в контролируемой среде симуляции, в реальный мир. Эта проблема обусловлена значительными расхождениями между идеализированными условиями моделирования и непредсказуемостью окружающей среды. В симуляциях объекты и освещение обычно стандартизированы, а физические взаимодействия предсказуемы. Однако в реальных условиях освещение может меняться, текстуры объектов различаться, а непредвиденные обстоятельства возникать постоянно. В результате, робот, прекрасно функционирующий в симуляции, может столкнуться с серьезными трудностями при выполнении тех же задач в реальном мире, демонстрируя низкую степень обобщения и требуя значительных корректировок для адаптации к новым условиям.
Традиционные методы робототехники, как правило, демонстрируют ограниченную эффективность при столкновении с вариациями освещения, текстур объектов и непредвиденными обстоятельствами реального мира. Алгоритмы, успешно работающие в контролируемых лабораторных условиях, часто терпят неудачу при изменении интенсивности света, появлении бликов или незначительных отклонениях в структуре поверхности объектов. Неспособность адаптироваться к этим, казалось бы, незначительным изменениям приводит к ошибкам в распознавании объектов, неверной оценке расстояния и, как следствие, к сбоям в выполнении задач. Проблема усугубляется непредсказуемостью реальной среды, где робот может столкнуться с новыми, ранее не встречавшимися ситуациями, требующими немедленной адаптации и принятия решений.
Для успешного внедрения робототехнических систем необходимо преодолеть разрыв между смоделированной и реальной средой, обеспечивая надежную работу в динамичных условиях. Этот “разрыв реальности” возникает из-за несоответствия между упрощенными представлениями, используемыми в симуляциях, и непредсказуемостью окружающего мира. Разработка алгоритмов, способных адаптироваться к изменениям освещения, текстур объектов и неожиданным препятствиям, является ключевой задачей. Современные исследования направлены на создание роботов, которые могут обучаться непосредственно в реальном времени, используя данные, полученные от сенсоров, и корректировать свои действия в соответствии с изменяющейся обстановкой. Только преодолев этот вызов, можно добиться широкого распространения роботов в различных сферах, от промышленности до повседневной жизни.

Использование Симуляций для Надежного Обучения
Использование симуляционных сред, таких как ManiSkill, предоставляет экономически эффективное решение для обучения робототехнических агентов благодаря возможности генерации масштабных наборов данных. Традиционные методы обучения роботов часто требуют значительных затрат времени и ресурсов, связанных с физическим взаимодействием робота с окружающей средой и сбором данных. Симуляция позволяет создавать неограниченное количество сценариев и данных, варьируя параметры среды и действия агента без необходимости в дорогостоящем оборудовании или риска повреждения робота. Это особенно важно для обучения сложных задач манипулирования, где требуется большое количество разнообразных примеров для достижения высокой производительности и обобщающей способности агента. Объем генерируемых данных может быть значительно увеличен по сравнению с реальными экспериментами, что позволяет использовать алгоритмы машинного обучения, требующие больших объемов данных для эффективной работы.
Методики, такие как MimicGen, позволяют создавать разнообразные траектории в симулированной среде, основываясь на демонстрациях экспертов. Этот подход предполагает использование алгоритмов для генерации множества реалистичных движений робота, имитирующих действия, выполненные человеком или другим опытным оператором. Созданные траектории служат основой для обучения агентов, значительно расширяя объем обучающих данных и обеспечивая более широкое покрытие возможных сценариев. Важно отметить, что MimicGen позволяет не только копировать существующие демонстрации, но и генерировать вариации, учитывая шум и неопределенность, что повышает устойчивость и обобщающую способность обученных моделей.
Несмотря на эффективность обучения в симулированных средах, перенос обученных моделей в реальный мир часто сталкивается с проблемами, обусловленными неизбежными расхождениями между симуляцией и реальностью. Эти расхождения могут быть вызваны упрощениями в физической модели симуляции, неточностями в сенсорных данных, а также непредсказуемыми факторами окружающей среды, отсутствующими в симуляции. Для преодоления этих трудностей необходимы методы адаптации моделей к реальным условиям, такие как дообучение в реальном мире (real-world fine-tuning), использование доменной адаптации (domain adaptation) или разработка робастных моделей, устойчивых к вариациям параметров симуляции и реальных данных.
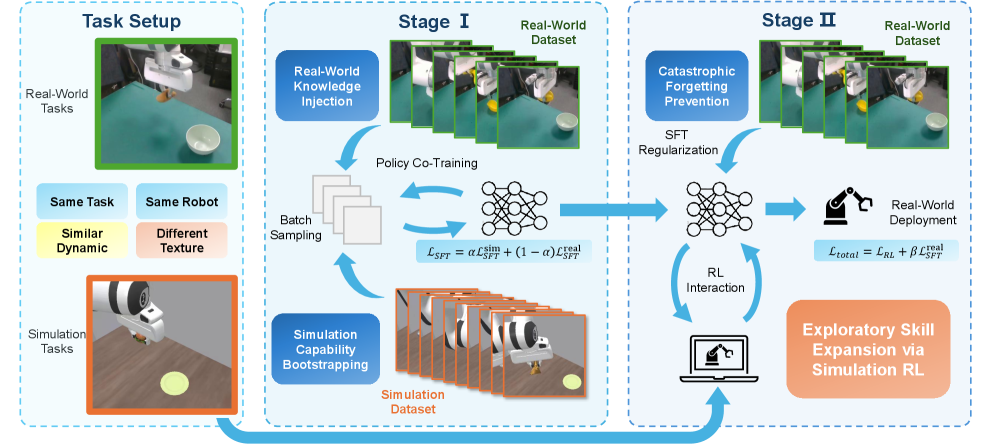
Модели «Зрение-Язык-Действие»: Основа для Адаптивности
Модели «Зрение-Язык-Действие», такие как OpenVLA и π0.5, представляют собой перспективную основу для управления роботами, объединяя в единую систему обработку визуальной информации, лингвистическое понимание и планирование действий. В отличие от традиционных подходов, требующих ручного программирования каждого шага, эти модели позволяют роботу воспринимать окружающую среду через камеры, интерпретировать инструкции на естественном языке и самостоятельно генерировать последовательность действий для достижения поставленной цели. Интеграция этих трех компонентов обеспечивает повышенную гибкость и адаптивность робота к изменяющимся условиям и новым задачам, существенно расширяя область его применения.
Модели, такие как OpenVLA и π0.5, используют различные подходы для генерации связных и контекстно-зависимых действий. OpenVLA применяет метод предсказания следующего токена (Next-Token Prediction), где модель обучается прогнозировать следующее действие или команду в последовательности, основываясь на визуальном вводе и предыдущих действиях. π0.5 использует подход Flow Matching, который моделирует процесс генерации действий как диффузионный процесс, где модель обучается «рассеивать» шум и постепенно формировать оптимальную траекторию действия на основе визуальной информации и поставленной задачи. Оба метода позволяют моделям адаптироваться к изменяющейся обстановке и выполнять действия, соответствующие текущему контексту и целям.
Для дальнейшей адаптации моделей Vision-Language-Action (VLA) к конкретным задачам применяется контролируемое обучение с использованием демонстраций экспертов. Этот процесс предполагает предоставление модели набора данных, состоящего из пар «входные данные (визуальная информация, языковые инструкции) — желаемое действие». Модель обучается предсказывать действия, соответствующие предоставленным демонстрациям, минимизируя разницу между предсказанными и фактическими действиями. Такой подход позволяет уточнить параметры модели и добиться более точного и эффективного выполнения целевых задач, особенно в сложных и неоднозначных сценариях, где заранее запрограммированные правила могут оказаться недостаточными. Эффективность контролируемого обучения зависит от качества и разнообразия демонстраций экспертов, а также от выбора подходящей функции потерь для оценки расхождения между предсказанными и фактическими действиями.
Закрытие Разрыва Реальности: Продвинутые Методы Переноса
Перенос обучения из симуляции в реальный мир является ключевым этапом для практического применения разработанных моделей. Однако, непосредственное использование моделей, обученных в виртуальной среде, часто сталкивается с проблемами из-за расхождений между симуляцией и реальными условиями. Для преодоления этого разрыва применяются такие методы, как доменная рандомизация, которая заключается в намеренном варьировании параметров симуляции — освещения, текстур, физических свойств объектов и прочего. Цель данной техники — научить модель быть устойчивой к различным вариациям окружающей среды и обобщать знания, полученные в симуляции, на реальные условия. В результате, модель становится менее чувствительной к незначительным различиям между виртуальным и реальным миром, что существенно повышает её эффективность при работе с реальными данными и задачами.
Совместное обучение, или ко-тренировка, представляет собой перспективный подход к повышению надежности и обобщающей способности моделей машинного обучения. Данная методика предполагает одновременное использование как синтетических, так и реальных данных в процессе обучения. Вместо последовательной адаптации модели к одному типу данных, ко-тренировка позволяет ей извлекать выгоду из сильных сторон обоих источников. Синтетические данные обеспечивают широкий охват различных сценариев и возможность контролируемой генерации сложных ситуаций, в то время как реальные данные гарантируют соответствие модели реальным условиям эксплуатации. Такой симбиоз позволяет модели не только эффективно решать поставленную задачу, но и демонстрировать повышенную устойчивость к изменениям в окружающей среде и новым, ранее не встречавшимся ситуациям, что особенно важно для роботизированных систем, работающих в непредсказуемых условиях.
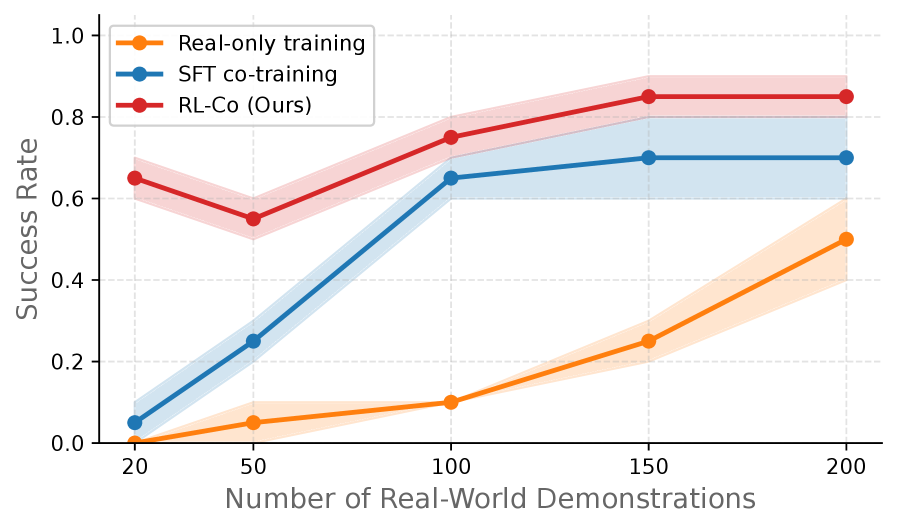
Предложенная схема RL-Co демонстрирует стабильное превосходство над методами, основанными исключительно на обучении в реальном мире, а также над подходами, использующими совместное обучение в симуляции и реальности с применением SFT. В ходе экспериментов зафиксировано значительное увеличение успешности выполнения задач — в некоторых случаях более чем на 35%. Данный подход позволяет добиться существенного улучшения результатов, эффективно используя данные, полученные как в виртуальной среде, так и в реальном мире, и обеспечивает более надежную работу системы в различных условиях.
Предложенная структура демонстрирует значительное повышение устойчивости к изменениям в распределении данных, что особенно важно при переходе от смоделированной среды к реальным условиям. Исследования показывают, что система способна поддерживать сопоставимую эффективность, требуя при этом существенно меньший объем данных, собранных в реальном мире. Это достигается благодаря эффективному использованию симуляций и алгоритмов обучения с подкреплением, позволяющих модели адаптироваться к новым, ранее не встречавшимся условиям с высокой точностью и надежностью. Такая адаптивность открывает возможности для применения в динамичных и непредсказуемых средах, где сбор большого объема реальных данных является сложной или дорогостоящей задачей.

Исследование, представленное в данной работе, демонстрирует стремление к созданию систем, способных адаптироваться к неизбежным изменениям окружающей среды. Подобно тому, как время испытывает любую структуру, предложенный метод RL-Co стремится к устойчивости моделей Vision-Language-Action к разрыву между симуляцией и реальностью. Алан Тьюринг однажды заметил: «Самое важное — это не то, что машина может думать, а то, что она может делать». Это высказывание перекликается с основной идеей работы — успешное применение моделей в реальном мире, а не только в симуляции, является истинным мерилом их эффективности. Предложенный подход к совместному обучению в симуляции и реальности, использующий обучение с подкреплением, направлен на создание систем, способных достойно стареть, сохраняя свою функциональность даже в условиях неопределенности и меняющейся среды.
Что дальше?
Предложенный подход, безусловно, вписывается в летопись усилий по преодолению разрыва между симуляцией и реальностью. Каждый коммит в этой области — это запись о попытке обуздать неумолимый хаос, а каждая версия — глава, повествующая о частичном успехе. Однако, следует признать, что идеальной симуляции, полностью отражающей сложность реального мира, достичь, вероятно, не удастся. Задержка в исправлении ошибок, возникающих из-за несоответствия симуляции и реальности, — это неизбежный налог на амбиции.
Будущие исследования, вероятно, сосредоточатся на более изощренных методах регуляризации и адаптации, позволяющих моделям учиться не столько «правильным» действиям, сколько принципам, позволяющим справляться с неожиданными обстоятельствами. Ключевым представляется развитие методов, позволяющих моделям самостоятельно выявлять и корректировать ошибки, возникающие из-за несоответствия симуляции и реальности, а не полагаться исключительно на предварительно определенные стратегии.
В конечном счете, каждая система стареет — вопрос лишь в том, делает ли она это достойно. Время — не метрика, а среда, в которой существуют системы. Задача состоит не в создании вечно работающих моделей, а в разработке механизмов, позволяющих им адаптироваться, учиться и, возможно, даже эволюционировать, чтобы оставаться полезными в постоянно меняющемся мире.
Оригинал статьи: https://arxiv.org/pdf/2602.12628.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Физика под контролем: Как «научить» модели понимать мир
- Квантовый скачок в обучении с учителем: новая архитектура для искусственного интеллекта
- Грань между Творчеством и Риском: Искусственный Интеллект и Эротический Контент
- Favia: Искусственный интеллект на страже безопасности кода
- Рассуждения на графах: как большие языковые модели учатся видеть мир
2026-02-16 13:38