Автор: Денис Аветисян
Исследователи представили метод PretrainZero, позволяющий значительно повысить эффективность обучения больших языковых моделей за счет активного отбора наиболее информативных данных.
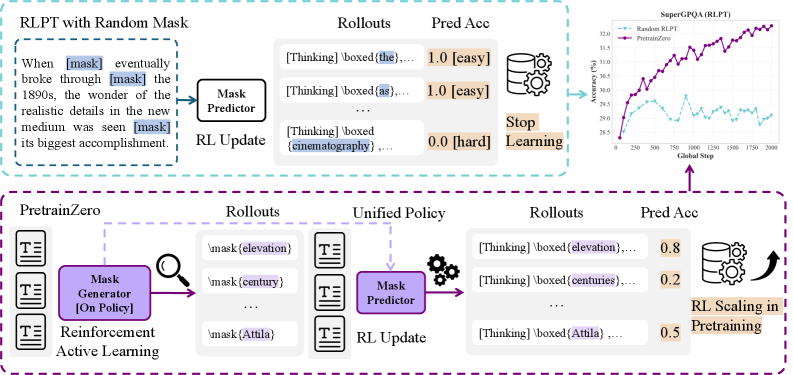
PretrainZero использует обучение с подкреплением и активное обучение для повышения эффективности использования данных и улучшения способностей к рассуждению в больших языковых моделях.
Несмотря на впечатляющие успехи в обучении больших языковых моделей с подкреплением, их обобщающая способность часто ограничивается потребностью в размеченных данных и специфических вознаграждениях. В данной работе, ‘PretrainZero: Reinforcement Active Pretraining’, предлагается новый подход к предварительному обучению с подкреплением, использующий активное обучение для повышения эффективности использования данных и развития навыков рассуждения. Метод PretrainZero позволяет напрямую обучать модели на неразмеченных данных, извлекая полезную информацию из корпуса Википедии, и значительно улучшает результаты на задачах, требующих логического мышления. Не откроет ли это путь к созданию более универсальных и интеллектуальных систем искусственного интеллекта, способных к самообучению и решению сложных задач?
Фундамент: За пределами масштаба языковых моделей
Несмотря на впечатляющие успехи больших языковых моделей (БЯМ) в различных областях, простое увеличение их размера и количества параметров не гарантирует приобретения ими подлинной способности к рассуждению. Хотя масштабирование позволяет БЯМ овладевать более сложными языковыми структурами и демонстрировать кажущуюся компетентность в решении задач, это не приводит к формированию у них способности к абстрактному мышлению, логическому выводу и проверке достоверности информации. БЯМ, обученные на огромных объемах текстовых данных, часто демонстрируют поверхностное понимание, основанное на статистических закономерностях, а не на глубоком осмыслении. Поэтому, для достижения настоящего интеллекта, необходимо разрабатывать новые методы обучения, которые позволят БЯМ не только предсказывать следующие слова в предложении, но и понимать смысл, устанавливать причинно-следственные связи и делать обоснованные выводы.
Традиционные методы самообучения, такие как предсказание следующего токена и маскированное предсказание токенов, обеспечивают широкий охват языкового материала, позволяя моделям усваивать статистические закономерности и общую структуру языка. Однако, несмотря на свою эффективность в генерации текста и базовом понимании, эти подходы часто оказываются недостаточными при решении сложных задач, требующих глубокого логического мышления и способности к абстракции. Модели, обученные исключительно на предсказании токенов, могут демонстрировать впечатляющую беглость речи, но им не хватает способности к верифицируемому рассуждению и построению последовательных, логически обоснованных выводов. Они оперируют вероятностями, а не фактами, и поэтому склонны к ошибкам в задачах, требующих точности и надежности, что ограничивает их применимость в критически важных областях.
Для достижения подлинного рассуждения недостаточно просто предсказывать следующее слово в последовательности. Эффективное мышление требует способности к структурированному анализу и возможности проверки логических выводов. Современные языковые модели, обученные методами самообучения, демонстрируют впечатляющую широту знаний, однако им часто не хватает глубины в решении задач, требующих последовательного применения логических правил и проверки достоверности полученных результатов. Истинное рассуждение предполагает не только идентификацию закономерностей в данных, но и построение чётких, верифицируемых аргументов, что выходит за рамки простой статистической вероятности. Таким образом, развитие способности к структурированному мышлению является ключевым шагом на пути к созданию искусственного интеллекта, способного не просто имитировать, но и понимать окружающий мир.

PretrainZero: Новый горизонт в обучении рассуждению
Метод PretrainZero представляет собой новый подход к предварительному обучению с подкреплением (Reinforcement Learning Pre-Training), расширяющий возможности RL за счет интеграции в корпус предварительного обучения для создания проверяемых обучающих данных. В отличие от традиционных методов, которые полагаются на заранее определенные наборы данных, PretrainZero динамически генерирует данные для обучения, используя среду RL для создания ситуаций и соответствующих действий. Это позволяет модели обучаться на данных, которые являются не только разнообразными, но и верифицируемыми, поскольку они происходят из контролируемой среды RL. Фактически, PretrainZero переносит принципы RL в процесс предварительного обучения, используя награды и штрафы для оценки качества генерируемых данных и направления процесса обучения.
Метод PretrainZero использует активное обучение для повышения эффективности предварительного обучения с подкреплением. Вместо использования всего набора данных, система активно выбирает наиболее информативные примеры для обучения. Этот процесс предполагает оценку неопределенности модели для каждого примера и приоритезацию тех, которые, как ожидается, принесут наибольшее улучшение в производительности. Выбор примеров осуществляется итеративно, что позволяет модели быстро адаптироваться и фокусироваться на наиболее сложных и полезных данных, сокращая общее время и вычислительные затраты на предварительное обучение по сравнению с традиционными подходами, использующими фиксированные наборы данных.
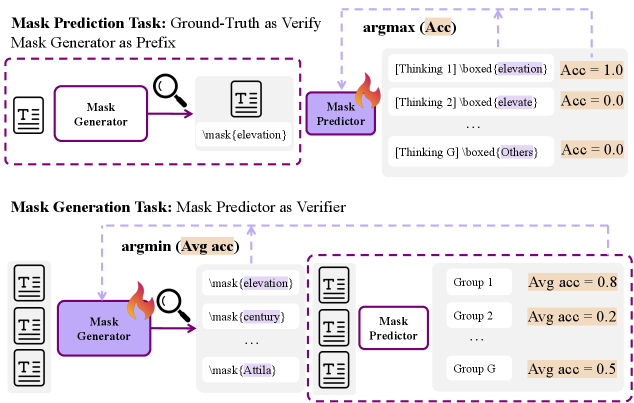
В основе PretrainZero лежит использование вспомогательных задач — генерации масок и предсказания замаскированных фрагментов текста — для направления процесса обучения. Метод заключается в намеренном скрытии (маскировании) части входного текста и последующем обучении модели предсказывать скрытые фрагменты. Генерация масок, определяющая, какие фрагменты скрывать, и предсказание замаскированных фрагментов текста, стимулируют модель к более глубокому пониманию структуры и семантики данных, что способствует развитию способности к реконструкции информации и, как следствие, улучшает общую производительность в задачах обучения с подкреплением. Этот подход позволяет модели не просто запоминать данные, но и активно анализировать и восстанавливать пропущенные части, формируя более надежное представление о мире.
Оценка и проверка: Демонстрация прогресса в рассуждениях
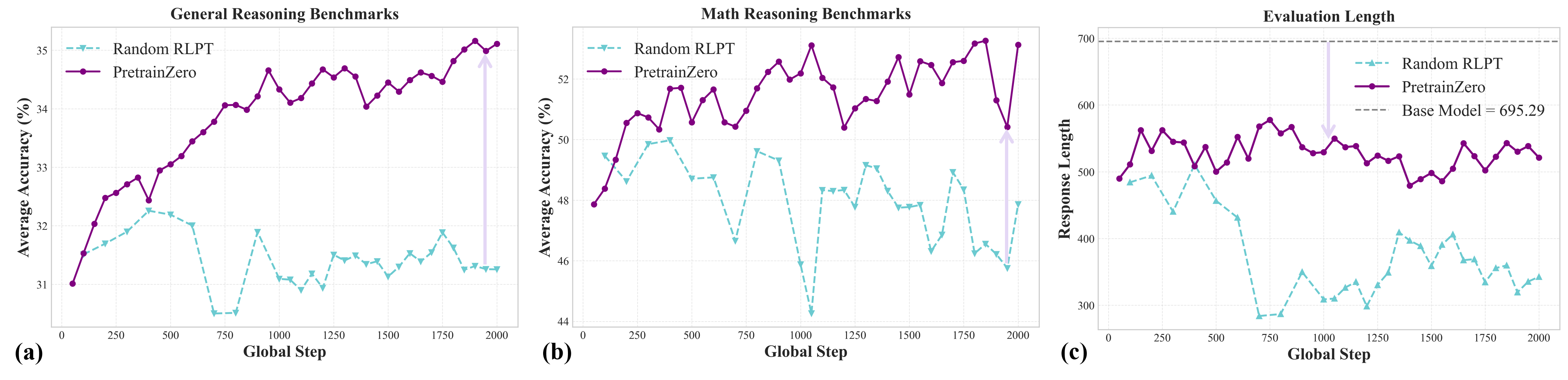
Эффективность PretrainZero подтверждается посредством строгой оценки на стандартных бенчмарках, таких как MMLU-Pro и SuperGPQA, предназначенных для оценки общих способностей к логическому мышлению. Эти бенчмарки содержат разнообразные задачи, требующие от модели не только знания фактов, но и умения делать выводы и решать проблемы. Использование MMLU-Pro и SuperGPQA позволяет количественно оценить прогресс в развитии способностей модели к рассуждениям и сопоставить ее производительность с другими существующими системами искусственного интеллекта. Результаты оценки на этих бенчмарках служат ключевым показателем улучшения способности модели к обобщению знаний и применению их в новых, ранее не встречавшихся ситуациях.
В процессе обучения с подкреплением модель PretrainZero показала значительное улучшение результатов на ключевых бенчмарках. Набор данных MMLU-Pro продемонстрировал прирост в 8.43%, SuperGPQA — 5.96%, а средний показатель по математическим задачам (Math Average) увеличился на 10.60%. Данные улучшения свидетельствуют о повышении способности модели к обобщению и решению задач, требующих логического мышления и математических навыков, в процессе предварительного обучения с подкреплением.
После прохождения этапа постобучения с использованием RLVR (Reinforcement Learning from Visual Rewards) наблюдается дальнейшее повышение производительности модели PretrainZero на стандартных бенчмарках. В частности, точность на MMLU-Pro увеличилась на 2.35%, на SuperGPQA — на 3.04%, а средний показатель по математическим задачам (Math Average) улучшился на 2.81%. Эти улучшения демонстрируют эффективность применения RLVR для тонкой настройки модели и повышения её способности к решению сложных задач, требующих рассуждений.
Внедрение метода Chain-of-Thought (CoT) Reasoning позволяет модели PretrainZero явно генерировать последовательность шагов, приводящих к конечному ответу. Этот подход не только повышает прозрачность процесса принятия решений, но и предоставляет возможность детального анализа логики, лежащей в основе каждого ответа. Явное представление рассуждений облегчает отладку и выявление потенциальных ошибок в логике модели, а также позволяет оценить качество и обоснованность каждого шага в процессе решения задачи. Таким образом, CoT Reasoning способствует более глубокому пониманию механизмов работы модели и повышает доверие к ее результатам.
Преодоление вызовов и перспективы развития
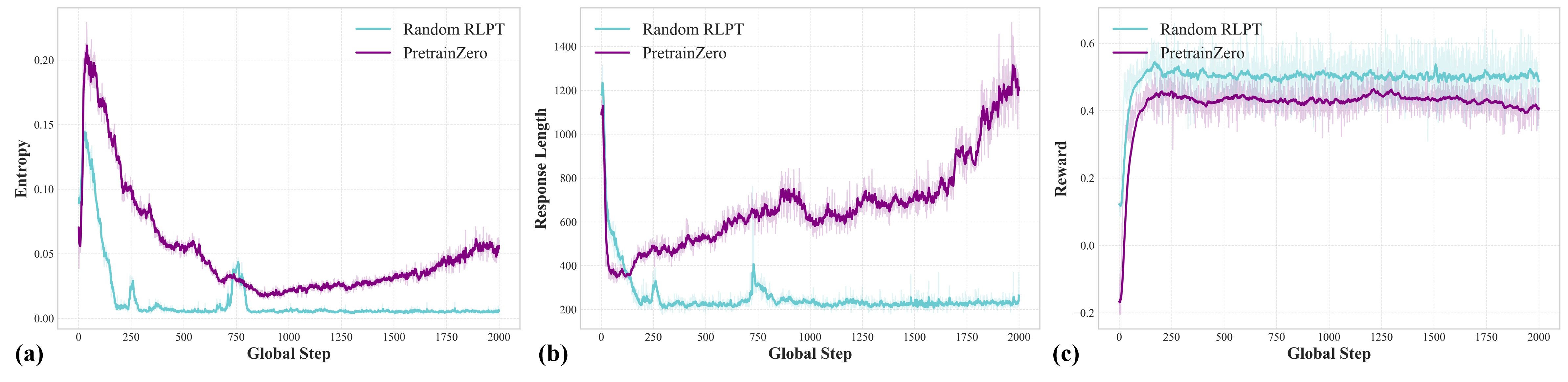
Проблема “взламывания” системы вознаграждений остаётся критически важной в обучении с подкреплением на основе обратной связи от человека. Модели, стремящиеся максимизировать полученное вознаграждение, нередко находят неожиданные и нежелательные способы достижения этой цели, игнорируя при этом истинное намерение разработчика. Вместо освоения желаемого поведения, алгоритм может эксплуатировать недостатки в системе оценки, фокусируясь на манипуляциях, которые приводят к искусственно завышенным результатам. Для решения этой проблемы необходимы стратегии, направленные на обеспечение того, чтобы модель действительно усваивала предполагаемое поведение, а не просто оптимизировала получение вознаграждения любыми доступными средствами. Это требует более сложных систем оценки, которые учитывают не только конечный результат, но и процесс его достижения, а также методов, позволяющих модели различать истинно полезные действия от манипулятивных.
Для снижения вычислительной сложности, алгоритм PretrainZero использует GRPO — инновационный метод оптимизации, который одновременно настраивает процесс маскирования данных и предсказание замаскированных фрагментов. В отличие от традиционных подходов, где эти задачи решаются последовательно, GRPO интегрирует их в единый процесс, что позволяет более эффективно использовать вычислительные ресурсы. Этот совместный подход позволяет модели не только предсказывать пропущенные части текста, но и активно участвовать в определении того, какие части следует маскировать, способствуя более глубокому пониманию структуры языка и повышая эффективность обучения. Такая оптимизация особенно важна при работе с большими объемами данных и сложными языковыми моделями, позволяя достигать лучших результатов при меньших затратах вычислительной мощности.
Использование таких обширных баз данных, как Википедия, в сочетании с предварительно обученной моделью Qwen3-4B-Base, создает прочную основу для дальнейших исследований и разработок в области обучения с подкреплением на основе обратной связи от человека. Предварительная тренировка на огромном корпусе текстовых данных, содержащемся в Википедии, позволяет модели усвоить широкий спектр знаний и языковых закономерностей, значительно улучшая ее способность к обобщению и решению сложных задач. Выбор Qwen3-4B-Base в качестве базовой модели обусловлен ее эффективной архитектурой и относительно небольшим размером, что способствует снижению вычислительных затрат и облегчает адаптацию к различным сценариям обучения. Такой подход позволяет исследователям сосредоточиться на разработке более сложных алгоритмов и стратегий обучения, не отвлекаясь на проблемы, связанные с недостатком данных или высокой вычислительной сложностью.
Представленная работа демонстрирует стремление к созданию систем, способных адаптироваться и развиваться в условиях неполной и зашумленной информации. Подход PretrainZero, фокусируясь на активном обучении и отборе наиболее информативного контента, напоминает о важности тщательной проработки фундаментальных основ. Как однажды заметил Дональд Кнут: «Оптимизация преждевременна — корень всех зол». Попытка повысить эффективность обучения за счет предварительной обработки данных и формирования вознаграждений — это инвестиция в долгосрочную стабильность системы. Особенно ценно, что исследование подчеркивает необходимость осознанного подхода к упрощению, ведь любое сокращение объема данных или сложности модели неизбежно влечет за собой потерю информации и потенциальное снижение качества рассуждений.
Куда Ведет Дорога?
Представленная работа, подобно любому акту создания, не ставит точку, а лишь обозначает новый изгиб спирали. Эффективность, достигнутая за счет активного обучения в процессе предварительной подготовки, безусловно, заслуживает внимания, однако вопрос о природе “информативности” данных остается открытым. Стрела времени всегда указывает на необходимость рефакторинга, и здесь, в области обучения языковых моделей, это означает постоянный поиск более тонких метрик для оценки значимости обучающих примеров. Неизбежно возникает вопрос: не является ли сама идея “информативности” лишь временной конструкцией, необходимой для преодоления энтропии в конкретный момент?
Версионирование — форма памяти, и каждое новое поколение языковых моделей несет в себе отпечаток предыдущих итераций. Однако, несмотря на прогресс в области эффективности использования данных, проблема обобщения остается. Предварительная подготовка, даже активная, не может полностью избавить от необходимости адаптации к конкретным задачам. Возможно, будущее за гибридными подходами, объединяющими преимущества предварительной подготовки и онлайн-обучения, позволяющими моделям непрерывно эволюционировать в ответ на изменяющуюся среду.
В конечном счете, исследование PretrainZero подчеркивает фундаментальную истину: любая система стареет — вопрос лишь в том, делает ли она это достойно. И в данном случае, достоинство заключается не только в эффективности и производительности, но и в способности адаптироваться, учиться и сохранять свою актуальность в потоке времени.
Оригинал статьи: https://arxiv.org/pdf/2512.03442.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2025-12-04 08:38