Автор: Денис Аветисян
Обзор посвящен статистическим методам обучения с подкреплением, позволяющим эффективно применять алгоритмы в условиях постоянно меняющейся среды и ограниченных данных.
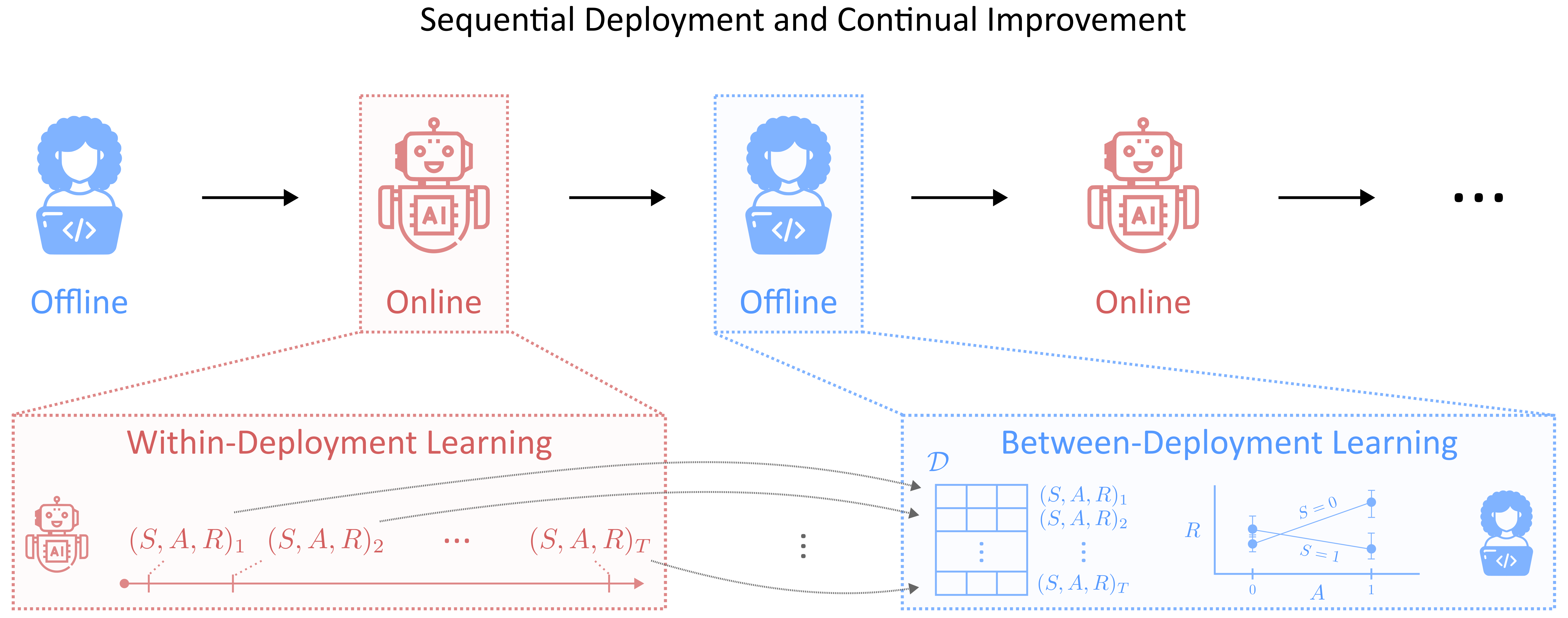
Статистический подход к обучению с подкреплением, охватывающий онлайн-обучение, оффлайн-анализ и последовательное развертывание для адаптивных интервенций.
Несмотря на впечатляющие успехи обучения с подкреплением (RL) в различных областях, значительный разрыв остается между теоретическими разработками и практическим применением в реальных условиях. Данная работа, ‘Statistical Reinforcement Learning in the Real World: A Survey of Challenges and Future Directions’, рассматривает ключевые препятствия — ограниченность данных и изменчивость окружения — при внедрении RL-систем. Предлагается концептуализировать процесс адаптации RL как трехкомпонентный цикл, включающий онлайн-оптимизацию, оффлайн-анализ и последовательное переобучение для непрерывного улучшения. Какие статистические методы и алгоритмы позволят преодолеть эти вызовы и обеспечить надежное, эффективное развертывание RL в динамично меняющемся мире?
Неуловимость Стационарности: Вызов для Интеллектуальных Агентов
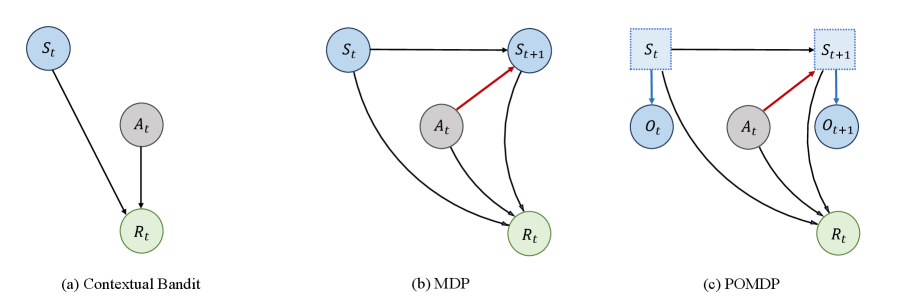
Традиционное обучение с подкреплением, как правило, исходит из упрощающего предположения о стационарности окружающей среды — то есть, о ее неизменности во времени. Однако, реальные задачи, с которыми сталкиваются интеллектуальные агенты, редко соответствуют этой модели. Вместо этого, агенты зачастую функционируют в динамичных условиях, где правила игры, доступные ресурсы и даже сама цель могут меняться. Представьте, например, робота, обучающегося на конвейере: изменение скорости ленты, появление новых объектов или даже изменение конфигурации производственной линии — всё это нарушает предположение о стационарности и требует от агента постоянной адаптации. Игнорирование этой не стационарности приводит к снижению эффективности алгоритмов обучения и, как следствие, к неустойчивой работе агента в реальном мире.
Многие алгоритмы обучения с подкреплением (RL) построены на неявном предположении о стационарности среды, то есть о ее неизменности во времени. Однако, в реальных условиях, динамика окружающей среды часто претерпевает изменения — будь то изменение правил игры, появление новых объектов или непредсказуемое поведение других агентов. Это несоответствие между предположениями алгоритма и реальной динамикой существенно снижает их эффективность. Когда среда перестает быть стационарной, ранее усвоенные оптимальные стратегии могут устаревать, требуя постоянной переоценки и адаптации. В результате, агент, обученный в стационарной среде, испытывает трудности при поддержании стабильной производительности и достижении оптимальных результатов в условиях меняющейся динамики, что подчеркивает необходимость разработки более устойчивых и адаптивных алгоритмов RL.
Нестационарность среды представляет собой серьезную проблему для агентов, стремящихся к выработке оптимальных стратегий и поддержанию стабильной производительности. В динамично меняющихся условиях, где закономерности и правила со временем претерпевают изменения, традиционные алгоритмы обучения с подкреплением оказываются неэффективными. Агент, обученный на определенном наборе данных или в конкретной ситуации, может столкнуться с резким снижением эффективности, когда среда изменится. Это требует от агента постоянной адаптации и переобучения, что увеличивает вычислительные затраты и замедляет процесс обучения. Более того, нестационарность может приводить к ситуации, когда агент не может сойтись к оптимальной стратегии, постоянно «гоняясь» за меняющимися условиями и не находя стабильного решения. Поэтому разработка алгоритмов, способных эффективно работать в нестационарных средах, является ключевой задачей современного обучения с подкреплением.
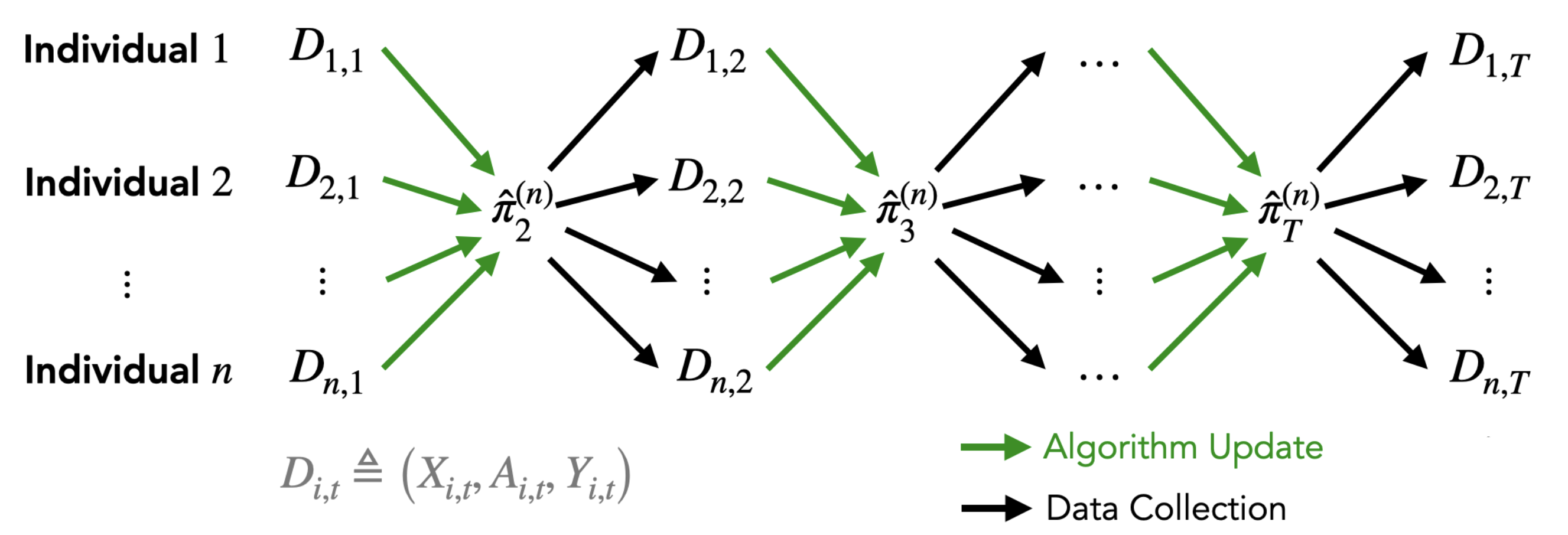
Непрерывное Обучение: Эволюция в Динамичном Мире
Непрерывное обучение расширяет возможности обучения с подкреплением, позволяя агентам приобретать новые знания без катастрофического забывания ранее изученных навыков. Традиционное обучение с подкреплением часто страдает от “катастрофического забывания” — потери эффективности в старых задачах при обучении новым. Методы непрерывного обучения направлены на смягчение этого эффекта посредством различных стратегий, включая регуляризацию, replay-буферизацию и динамическое выделение ресурсов. Эти подходы позволяют агентам сохранять и эффективно использовать накопленный опыт при адаптации к новым условиям, обеспечивая более устойчивую и эффективную работу в динамичных средах.
Методы непрерывного обучения критически важны для работы в нестационарных средах, характеризующихся изменяющимися условиями и распределениями данных. В таких средах традиционные алгоритмы обучения с подкреплением могут демонстрировать существенное снижение производительности при изменении параметров окружения. Непрерывное обучение позволяет агентам адаптироваться к новым условиям, сохраняя при этом знания, полученные ранее, и избегая катастрофического забывания. Это обеспечивает поддержание стабильной и эффективной работы агента в долгосрочной перспективе, а также улучшает общую производительность и надежность системы в динамически меняющейся обстановке.
Интеграция принципов непрерывного обучения позволяет агентам поддерживать устойчивые политики даже при значительных изменениях в окружающей среде. Это достигается за счет механизмов, предотвращающих катастрофическое забывание ранее приобретенных навыков при обучении новым. Агенты, использующие такие методы, способны адаптироваться к не стационарным условиям, сохраняя эффективность и производительность, несмотря на постоянные изменения в динамике среды и требованиях к задачам. В результате, они демонстрируют повышенную надежность и долгосрочную работоспособность в условиях, требующих постоянной адаптации.
Сила Данных: Онлайн и Оффлайн Подходы
Адаптивные эксперименты, основанные на обучении с подкреплением в режиме реального времени, позволяют оптимизировать стратегии взаимодействия с пользователем и предоставлять персонализированные вмешательства. В отличие от статических A/B-тестов, эти системы динамически корректируют политику (набор правил принятия решений) на основе получаемой обратной связи от пользователей. Алгоритмы обучения с подкреплением непрерывно оценивают эффективность различных действий, максимизируя заданную целевую функцию, например, уровень вовлеченности или коэффициент конверсии. Это достигается за счет использования методов, таких как Q-learning или policy gradients, позволяющих системе «учиться на собственном опыте» и адаптироваться к индивидуальным предпочтениям каждого пользователя в процессе взаимодействия.
Статистический вывод имеет решающее значение для оценки эффективности адаптивных методов лечения, обеспечивая надежность и достоверность полученных результатов. Оценка должна включать в себя расчет доверительных интервалов для оценки эффекта вмешательства, а также проверку статистической значимости наблюдаемых различий. Важно учитывать потенциальные источники смещения, такие как отбор пациентов и систематические ошибки измерения. Для обеспечения воспроизводимости и валидности результатов необходимо использовать соответствующие статистические методы, такие как t-критерий, дисперсионный анализ (ANOVA) или непараметрические тесты, в зависимости от типа данных и дизайна исследования. Надежность выводов напрямую зависит от размера выборки и мощности статистического анализа, поэтому необходимо заранее планировать исследование, чтобы обеспечить достаточную статистическую мощность для обнаружения значимых эффектов.
Обучение с подкреплением в автономном режиме (offline reinforcement learning) представляет собой альтернативный подход, позволяющий строить и оптимизировать стратегии на основе исторических данных, собранных ранее, без необходимости проведения дополнительных онлайн-экспериментов. Этот метод особенно ценен в ситуациях, когда активное взаимодействие с системой нежелательно, дорогостояще или невозможно, например, при работе с медицинскими данными или в системах, где ошибка может иметь серьезные последствия.
Эффективное использование оффлайн-данных критически важно в ситуациях, когда проведение онлайн-экспериментов является дорогостоящим, сопряжено с риском или непрактично. В таких сценариях необходимо балансировать между ограничением кумулятивных потерь (regret bounds) и статистической мощностью анализа. Оффлайн-обучение с подкреплением позволяет извлекать знания из исторических данных, избегая необходимости в реальном времени взаимодействовать с системой, что особенно ценно в приложениях, где каждое взаимодействие имеет значимые последствия или ограничено по времени. Оценка эффективности оффлайн-обучения требует учета смещений, возникающих из-за различий между данными, используемыми для обучения, и данными, получаемыми в процессе эксплуатации.
Дилемма Исследования и Использования: Путь к Адаптации
Агенты, обучающиеся с подкреплением, постоянно сталкиваются с дилеммой исследования и использования: следует ли им исследовать новые действия, чтобы потенциально найти более выгодные, или использовать уже известные, обеспечивающие гарантированное вознаграждение? Эта фундаментальная проблема является ключевой для успешного обучения в любой среде, поскольку слишком сильный уклон в сторону использования может привести к застреванию в локальном оптимуме, в то время как чрезмерное исследование может снизить эффективность и замедлить процесс обучения. Баланс между этими двумя стратегиями требует от агента оценки неопределенности, связанной с каждым действием, и принятия решений на основе оценки потенциальной выгоды и риска, что является сложной задачей, особенно в динамично меняющихся условиях.
В условиях нестационарной среды, где оптимальные стратегии поведения могут меняться со временем, дилемма исследования и эксплуатации становится особенно острой. Агенты, обучающиеся с подкреплением, сталкиваются с необходимостью постоянно адаптироваться к новым условиям, поскольку ранее эффективные действия могут утратить свою ценность. Постоянное изменение среды требует от агента не только эффективной эксплуатации текущих знаний, но и активного исследования новых возможностей, чтобы избежать застревания в субоптимальных решениях. Эта проблема усугубляется, когда изменения в среде происходят непредсказуемо или скрыто, требуя от агента способности к быстрому обучению и адаптации к новым обстоятельствам, а также к прогнозированию будущих изменений для поддержания оптимальной производительности.
Интеграция причинно-следственного вывода и использование цифровых двойников позволяют агентам формировать более глубокое и устойчивое понимание окружающей среды. Такой подход способствует осознанному выбору между исследованием новых возможностей и использованием уже известных, эффективно разрешая дилемму «исследование — использование». Это, в свою очередь, открывает путь к непрерывному совершенствованию, включающему обучение непосредственно в процессе эксплуатации, вне-эксплуатационный анализ полученных данных и последовательное развертывание и переразвертывание агента. В результате, система способна адаптироваться к изменениям в окружающей среде и оптимизировать свою стратегию поведения, обеспечивая стабильно высокие результаты даже в нестационарных условиях.
Взгляд в Будущее: Пути Развития и Широкие Возможности
Сочетание непрерывного обучения, обучения с подкреплением на основе исторических данных и надежных статистических методов формирует мощную основу для решения сложных задач реального мира. Непрерывное обучение позволяет системам адаптироваться к постоянно меняющимся условиям, избегая необходимости полной переподготовки при появлении новой информации. Обучение с подкреплением на основе исторических данных, в свою очередь, дает возможность извлекать ценные знания из уже накопленных данных, минуя дорогостоящие и рискованные эксперименты в реальной среде. Наконец, применение строгих статистических методов обеспечивает надежность полученных результатов и позволяет оценивать степень уверенности в принимаемых решениях. Такой комплексный подход, объединяющий адаптивность, опыт и точность, открывает новые горизонты для создания интеллектуальных систем, способных эффективно функционировать в динамичных и непредсказуемых условиях, например, в робототехнике, автономном транспорте и управлении сложными процессами.
Современные системы, использующие непрерывное обучение и обучение с подкреплением в оффлайн-режиме, могут значительно выиграть от интеграции больших языковых моделей. Эти модели способны предоставлять предварительные знания, существенно расширяя возможности систем в процессе принятия решений. Они позволяют учитывать контекст и общие закономерности, которые сложно обнаружить при анализе только текущих данных. В частности, языковые модели способны формировать более обоснованные гипотезы о возможных исходах действий, оценивать риски и выбирать оптимальные стратегии, что особенно важно в динамически меняющихся условиях. Такое сочетание технологий открывает перспективы создания интеллектуальных систем, способных эффективно адаптироваться к новым задачам и демонстрировать высокую устойчивость к неопределенности.
Для широкого внедрения систем, основанных на непрерывном обучении и обучении с подкреплением, необходимо решить ряд критических задач. Особое внимание следует уделить проблеме переноса знаний между различными доменами — так называемому «сдвигу домена», когда модель, обученная в одной среде, теряет эффективность в другой. Не менее важным является обеспечение статистической мощности исследований, то есть способности системы достоверно обнаруживать значимые закономерности даже при наличии шума или ограниченного объема данных. Надежность статистических оценок напрямую влияет на принятие обоснованных решений и предсказуемость поведения системы в реальных условиях. Успешное преодоление этих вызовов позволит создавать более устойчивые и адаптивные системы, способные эффективно функционировать в динамично меняющейся среде, и откроет путь к их применению в самых разных областях — от робототехники до медицины.
В конечном итоге, совокупность достижений в области непрерывного обучения, обучения с подкреплением в оффлайн-режиме и надежных статистических методов открывает путь к созданию систем, обладающих беспрецедентной адаптивностью и устойчивостью. Эти системы смогут эффективно функционировать в постоянно меняющихся условиях, преодолевая трудности, связанные с непредсказуемостью реального мира. Они способны не просто реагировать на изменения, но и прогнозировать их, оптимизируя свою работу для достижения максимальной эффективности и надежности в динамичной среде. Такой подход обещает революцию в различных областях, от робототехники и автономных транспортных средств до управления сложными системами и принятия решений в условиях неопределенности, что позволит создавать интеллектуальные решения, способные к самообучению и самосовершенствованию.
Статья, исследующая статистическое обучение с подкреплением, словно пытается построить маяк в бушующем море непредсказуемости. Авторы справедливо отмечают, что реальный мир редко соответствует лабораторным условиям, и проблема не только в нехватке данных, но и в постоянном изменении окружающей среды. Эта погоня за адаптивностью, за способностью перестраивать модель поведения в ответ на новые вызовы, напоминает танец на краю пропасти. Как метко заметил Людвиг Витгенштейн: «Предел моего языка есть предел моего мира». И в данном случае, предел любой модели обучения с подкреплением — это горизонт событий, за которым скрывается непознанное, непредсказуемое, и, возможно, принципиально несмоделируемое.
Что Дальше?
Представленный анализ статистического обучения с подкреплением, несмотря на акцент на адаптивных вмешательствах и причинно-следственном анализе, лишь обнажает горизонт событий, за которым скрывается истинная сложность реальных систем. Когнитивное смирение исследователя пропорционально сложности нелинейных уравнений Эйнштейна, и в данном контексте — пропорционально непредсказуемости окружающей среды. Утверждение о трёхкомпонентном процессе — онлайн-обучение, оффлайн-анализ и последовательное повторное развертывание — звучит элегантно, но игнорирует фундаментальную проблему: невозможность полного моделирования нелинейной динамики, особенно при ограниченности данных.
Чёрные дыры демонстрируют границы применимости физических законов и нашей интуиции. Аналогично, успех алгоритмов обучения с подкреплением в реальном мире будет определяться не столько совершенством математических моделей, сколько способностью признавать их неполноту. Акцент на непрерывном обучении и адаптации — это не просто техническая необходимость, а признание принципиальной невозможности достижения стационарности. Будущие исследования должны быть направлены не на построение всеобъемлющей теории, а на разработку алгоритмов, способных эффективно функционировать в условиях фундаментальной неопределенности.
Вопрос не в том, как «победить» нелинейность, а в том, как научиться сосуществовать с ней, признавая, что любое «решение» — это лишь временная иллюзия, обреченная исчезнуть в горизонте событий. Предложенный статистический подход — это шаг в правильном направлении, но истинный прогресс потребует не только математической изобретательности, но и философского смирения.
Оригинал статьи: https://arxiv.org/pdf/2601.15353.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кванты в Финансах: Не Шутка!
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-23 10:38