Автор: Денис Аветисян
Новый подход к обучению с подкреплением позволяет значительно повысить способность больших языковых моделей к логическому мышлению и расширить границы их возможностей.
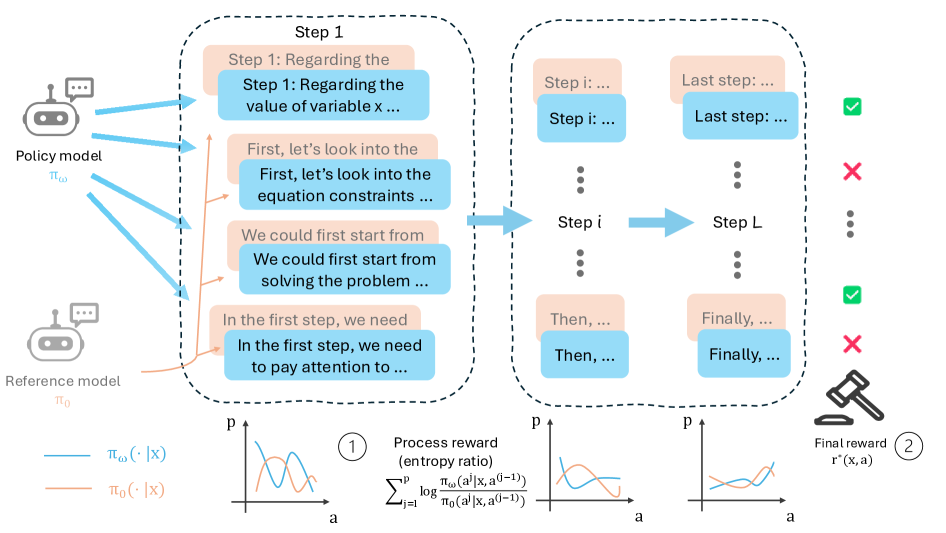
В статье представлен метод Process Reward Learning (PRL), использующий плотные сигналы вознаграждения, основанные на энтропийной регуляризации, для эффективного обучения больших языковых моделей.
Несмотря на значительный прогресс в обучении больших языковых моделей (LLM), эффективное повышение их способности к логическому мышлению остаётся сложной задачей. В данной работе, озаглавленной ‘PRL: Process Reward Learning Improves LLMs’ Reasoning Ability and Broadens the Reasoning Boundary’, предложен новый подход — Process Reward Learning (PRL), который декомпозирует задачу обучения с подкреплением на промежуточные шаги, используя теоретически обоснованные сигналы вознаграждения за процесс рассуждения. Полученные результаты демонстрируют, что PRL не только улучшает среднюю производительность LLM в задачах логического вывода, но и расширяет границы решаемых задач. Возможно ли дальнейшее развитие PRL для создания LLM, способных к более сложному и гибкому мышлению, приближая их к человеческому интеллекту?
Логическое Мышление: Узкое Место Больших Языковых Моделей
Несмотря на впечатляющий масштаб и количество параметров, современные большие языковые модели (LLM) демонстрируют трудности при решении задач, требующих многоступенчатого логического мышления. Часто, вместо глубокого понимания проблемы, модели ограничиваются распознаванием поверхностных закономерностей в данных, что препятствует успешной генерализации и применению знаний в новых, незнакомых ситуациях. Данное ограничение проявляется в неспособности корректно решать логические головоломки, выполнять сложные вычисления или строить последовательные аргументы, требующие анализа и синтеза информации на нескольких этапах. Вместо этого, модели склонны к воспроизведению статистических связей, обнаруженных в обучающем корпусе, что приводит к ошибкам в случаях, когда требуется истинное понимание и применение принципов логики и рассуждений.
Традиционные методы обучения с подкреплением, основанные на редких сигналах вознаграждения, оказываются неэффективными при обучении больших языковых моделей сложным, многоступенчатым рассуждениям. Суть проблемы заключается в том, что модель получает информацию о правильности решения только в конце всего процесса, что затрудняет определение того, какие конкретно шаги были успешными, а какие — нет. Это приводит к крайне медленному обучению, поскольку модель вынуждена перебирать множество вариантов, прежде чем случайно наткнуться на правильную последовательность действий. По сути, модель лишена возможности оперативно корректировать свои действия на основе промежуточных результатов, что существенно ограничивает её способность к эффективному решению задач, требующих последовательного логического мышления и планирования.
Оценка эффективной награды на каждом этапе рассуждений представляет собой значительную проблему для больших языковых моделей, что приводит к замедленному обучению и неоптимальным результатам. В частности, методы, подобные Монте-Карло поиску по дереву (MCTS), демонстрируют ограничения в этой области. Суть проблемы заключается в сложности точной оценки промежуточных шагов к правильному ответу; модель часто не может определить, насколько близко текущее состояние к желаемому результату, что приводит к неэффективному исследованию пространства решений. Даже если модель и находит правильный ответ, путь к нему может быть извилистым и неоптимальным, поскольку недостаточная оценка промежуточных шагов не позволяет ей быстро сходиться к наиболее эффективной стратегии рассуждений. Это ограничивает способность модели обобщать знания и успешно применять рассуждения в новых, сложных ситуациях.
Обучение с Вознаграждением за Процесс: Шаг за Шагом к Решению
Обучение с вознаграждением за процесс (Process Reward Learning, PRL) решает проблему разреженных вознаграждений, часто встречающуюся в сложных задачах, путем предоставления плотных сигналов вознаграждения на каждом промежуточном шаге процесса рассуждений. В традиционном обучении с подкреплением, вознаграждение выдается только при достижении конечной цели, что затрудняет обучение в задачах с длинными последовательностями действий. PRL, напротив, разбивает задачу на последовательность управляемых подцелей и назначает вознаграждение за каждый успешный шаг к их достижению. Это позволяет агенту быстрее обучаться и исследовать более эффективные стратегии, даже если конечная цель достижима только после множества промежуточных действий. Такой подход особенно полезен в задачах, где получение конечного вознаграждения происходит редко или с большой задержкой.
Метод обучения с вознаграждением за процесс (PRL) использует концепцию “промежуточных шагов” для декомпозиции сложных задач на последовательность выполнимых подцелей. Вместо ожидания редкого сигнала вознаграждения при достижении конечной цели, PRL назначает вознаграждения за каждый успешно выполненный промежуточный шаг. Это позволяет агенту быстрее обучаться, поскольку он получает более частые и информативные сигналы обратной связи, что способствует более эффективному исследованию пространства состояний и формированию оптимальной стратегии. Разбиение сложной задачи на подцели также упрощает процесс обучения, позволяя агенту осваивать отдельные компоненты решения перед интеграцией их в единую стратегию.
В основе Process Reward Learning (PRL) лежит использование логарифмического отношения \log \frac{\pi(a_t | s_t)}{\pi_{ref}(a_t | s_t)} , которое позволяет оценить разницу между текущей политикой π и эталонной (reference) политикой \pi_{ref} на каждом шаге процесса. Это отношение, вычисляемое для каждого действия a_t в состоянии s_t , предоставляет более детализированный и нюансированный сигнал вознаграждения, чем традиционные подходы с разреженными наградами. Положительное значение указывает на то, что текущая политика предпочтительнее эталонной, а отрицательное — наоборот. Величина логарифмического отношения пропорциональна величине вознаграждения, что позволяет эффективно направлять процесс обучения и ускорять сходимость к оптимальной стратегии.
Стабилизация Обучения с Регуляризацией Энтропии
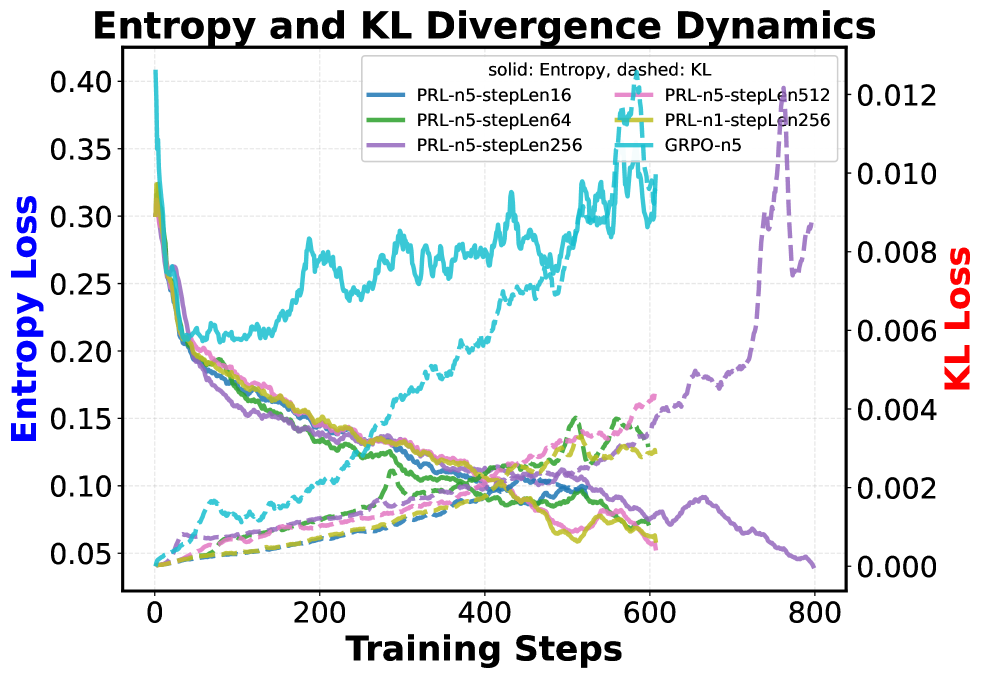
Метод обучения с подкреплением, используемый в PRL (Policy Reinforcement Learning), применяет регуляризацию энтропией для стимулирования исследования пространства действий и предотвращения преждевременной сходимости политики к единственному, возможно, неоптимальному решению. Регуляризация энтропией добавляет к функции награды штраф, пропорциональный энтропии распределения действий, что поощряет агента выбирать более разнообразные действия и избегать чрезмерной уверенности в конкретной стратегии. Это особенно важно в сложных задачах, где локальные оптимумы могут препятствовать достижению глобально оптимального решения, и позволяет агенту более эффективно исследовать пространство состояний и находить более надежные и устойчивые стратегии.
Штраф за расхождение КЛ (KL-Divergence Penalty) играет ключевую роль в стабилизации обучения, ограничивая отклонение текущей политики от эталонной (Reference Policy). Этот штраф измеряет разницу между двумя распределениями вероятностей — текущей и эталонной политики — используя D_{KL}(P||Q), где P — текущая политика, а Q — эталонная. Внедрение этого штрафа в функцию потерь предотвращает чрезмерные изменения в политике на каждом шаге обучения, что особенно важно при обучении больших языковых моделей (LLM). Ограничивая отклонение от исходной политики, KL-Divergence Penalty способствует более плавному и стабильному обучению, снижая вероятность коллапса политики и обеспечивая более надежное исследование пространства действий.
Обучение языковой модели (LLM) в рамках данного подхода осуществляется посредством оптимизации на основе градиентных методов, известных как Policy Gradient. Этот метод направлен на максимизацию суммарной награды, получаемой в процессе взаимодействия с окружающей средой. В частности, Policy Gradient позволяет напрямую оптимизировать политику (стратегию поведения) LLM, корректируя ее параметры в направлении увеличения ожидаемой кумулятивной награды. Вычисляемый градиент используется для обновления параметров политики, что приводит к постепенному улучшению ее способности генерировать действия, приводящие к более высоким наградам в долгосрочной перспективе. \nabla J(\theta) \approx \frac{1}{N} \sum_{i=1}^{N} \sum_{t=1}^{T} \nabla_{\theta} \log \pi_{\theta}(a_t|s_t) R_t , где θ — параметры политики, \pi_{\theta} — вероятность действия a_t в состоянии s_t , а R_t — суммарная награда, полученная после действия a_t .
Эмпирическая Валидация и Приращение Производительности
Исследование успешно применило алгоритм PRL к крупным языковым моделям Qwen и Llama, что привело к заметному улучшению результатов в решении математических задач. В ходе экспериментов, модели, дополненные PRL, продемонстрировали повышенную точность на таких сложных бенчмарках, как MATH500, Minerva Math и Olympiad Bench, охватывающих широкий спектр математических дисциплин и уровней сложности. Данные результаты подтверждают эффективность PRL в усилении способностей LLM к логическому мышлению и решению математических проблем, открывая перспективы для дальнейшего развития и применения в областях, требующих высокой точности вычислений и анализа.
Для строгой оценки эффективности предложенного метода PRL использовалась метрика Pass@N, которая определяет долю успешно решенных задач из заданного набора при N попытках. Результаты экспериментов демонстрируют, что PRL последовательно превосходит существующие подходы, такие как RAFT и GRPO, по среднему показателю Pass@N на различных математических бенчмарках. Такое устойчивое улучшение свидетельствует о том, что PRL эффективно расширяет возможности больших языковых моделей в решении сложных математических задач и повышает их надежность в процессе рассуждений.
Исследования показали, что применение метода PRL значительно повышает вероятность успешного решения сложных математических задач, особенно при оценке по метрике Pass@N, где N равно 8. Это означает, что модели, использующие PRL, демонстрируют повышенную способность находить верные ответы среди нескольких предложенных вариантов, расширяя границы их логического мышления по сравнению с базовыми методами, такими как RAFT и GRPO. Увеличение пропускной способности при N=8 свидетельствует о том, что PRL не просто улучшает существующие возможности больших языковых моделей, но и позволяет им решать более сложные и требовательные задачи, требующие глубокого анализа и логических выводов.
Исследование демонстрирует, как стремление к элегантным теоретическим решениям в области обучения больших языковых моделей неизбежно сталкивается с суровой реальностью практической реализации. Авторы предлагают Process Reward Learning (PRL) — подход, основанный на плотных сигналах вознаграждения, полученных из энтропийной регуляризации. Звучит прекрасно, пока не начнётся этап интеграции с существующими системами, где каждая оптимизация порождает новую головную боль. Как говорил Алан Тьюринг: «Мы можем только надеяться, что машины не станут слишком умными». Это не предостережение о восстании машин, а констатация факта: чем сложнее система, тем больше вероятность, что она сломается самым неожиданным образом. И тогда все эти энтропийные регуляризации и плотные сигналы вознаграждения превратятся в пыль, а команда проджекта будет решать, почему модель решила, что дважды два — пять.
Что дальше?
Предложенный подход к обучению языковых моделей через плотные сигналы вознаграждения, безусловно, элегантен. Однако, стоит помнить, что каждая «революция» в машинном обучении неизбежно превращается в технический долг. Оптимальная политика, вычисленная в контролируемой среде, рано или поздно столкнется с суровой реальностью продакшена, где данные не столь учтивы, а энтропия — не всегда благом. Вопрос не в том, улучшит ли этот метод рассуждения, а в том, сколько ресурсов потребуется для поддержания иллюзии разумности, когда модель начнет сталкиваться с непредсказуемыми запросами.
Очевидным направлением для дальнейших исследований представляется адаптация этого фреймворка к мультимодальным моделям. Но, как показывает опыт, добавление новых каналов информации лишь усложняет процесс обучения и порождает новые классы ошибок. Не исключено, что мы просто заменим один набор багов другим, более изощренным. Важнее, пожалуй, разработка более устойчивых к шуму методов оценки вознаграждения — ведь в реальном мире «истина» редко бывает четкой и однозначной.
В конечном итоге, успех этого подхода будет зависеть не столько от теоретической обоснованности, сколько от практической применимости. И если эта работа поможет продлить «страдания» еще одной языковой модели в продакшене — это уже будет достижением. Мы не чиним продакшен — мы просто продлеваем его страдания.
Оригинал статьи: https://arxiv.org/pdf/2601.10201.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2026-01-17 07:58