Автор: Денис Аветисян
Исследователи разработали метод, позволяющий стабилизировать и ускорить процесс обучения моделей искусственного интеллекта, используя формат данных FP8.
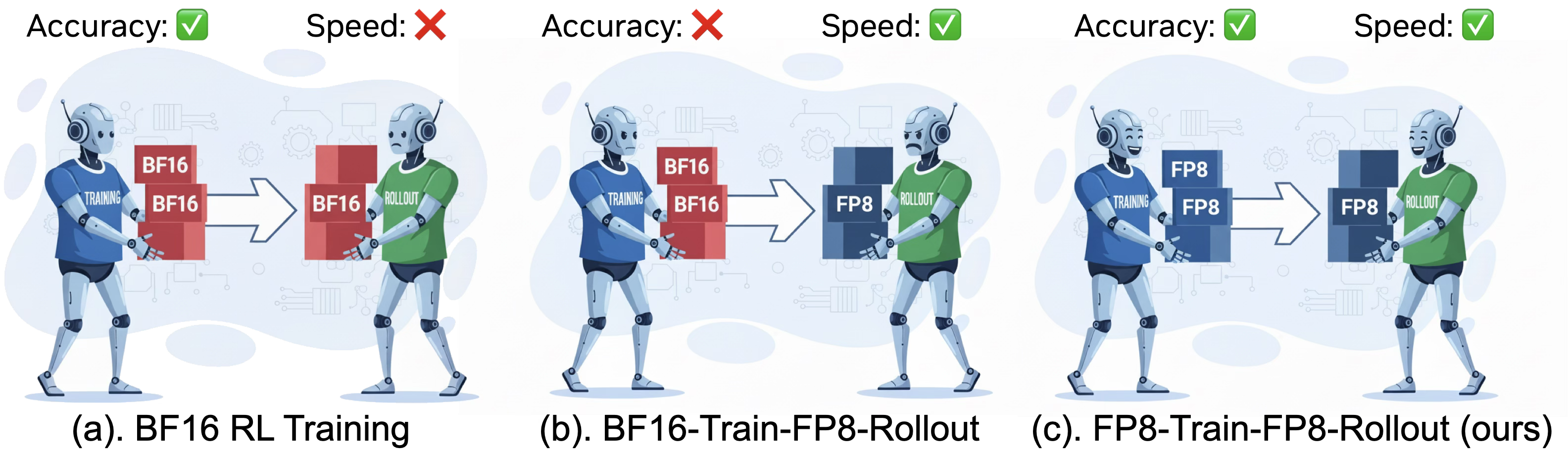
Jet-RL обеспечивает согласованный поток FP8-точности между фазами обучения и развертывания, решая проблему нестабильности при квантовании до FP8.
Обучение с подкреплением (RL) является ключевым для расширения возможностей сложных рассуждений больших языковых моделей, однако существующие конвейеры обучения зачастую неэффективны и ресурсоемки. В данной работе, посвященной ‘Jet-RL: Enabling On-Policy FP8 Reinforcement Learning with Unified Training and Rollout Precision Flow’, показано, что распространенная стратегия использования FP8 для фазы развертывания и BF16 для обучения приводит к нестабильности и снижению точности при решении сложных задач. Предложенный фреймворк Jet-RL обеспечивает стабильную оптимизацию RL за счет унификации точности FP8 как для обучения, так и для развертывания, минимизируя числовые расхождения. Возможно ли дальнейшее повышение эффективности и надежности обучения больших языковых моделей с использованием подобных подходов к квантованию и точности вычислений?
Разрушая Иллюзии: О Глубине Рассуждений в LLM
Современные большие языковые модели, такие как Qwen3-8B-Base, демонстрируют впечатляющую способность к распознаванию закономерностей и анализу данных. Однако, несмотря на успехи в обработке информации, сложные задачи, требующие последовательного, многоступенчатого рассуждения, представляют для них серьезную трудность. Модели часто демонстрируют неустойчивость при решении проблем, где необходимо не просто найти соответствие, но и логически выстроить цепочку действий для достижения результата. Это связано с тем, что обучение моделей преимущественно ориентировано на статистическое сопоставление данных, а не на развитие навыков абстрактного мышления и дедукции, необходимых для полноценного решения задач, требующих глубокого понимания и последовательного применения логических правил.
Традиционные методы, направленные на улучшение способности больших языковых моделей к построению цепочек рассуждений, зачастую сталкиваются с ограничениями масштабируемости. По мере увеличения сложности задач и объемов данных, стандартные подходы к обучению демонстрируют снижение эффективности и стабильности генерации последовательных, логически обоснованных выводов. Это связано с тем, что модели испытывают трудности в удержании контекста и поддержании когерентности на протяжении нескольких шагов рассуждений, что приводит к ошибкам и неточностям в итоговых ответах. В результате, способность модели к решению комплексных задач, требующих глубокого анализа и многоступенчатых вычислений, остается ограниченной, несмотря на значительные успехи в области обработки естественного языка.
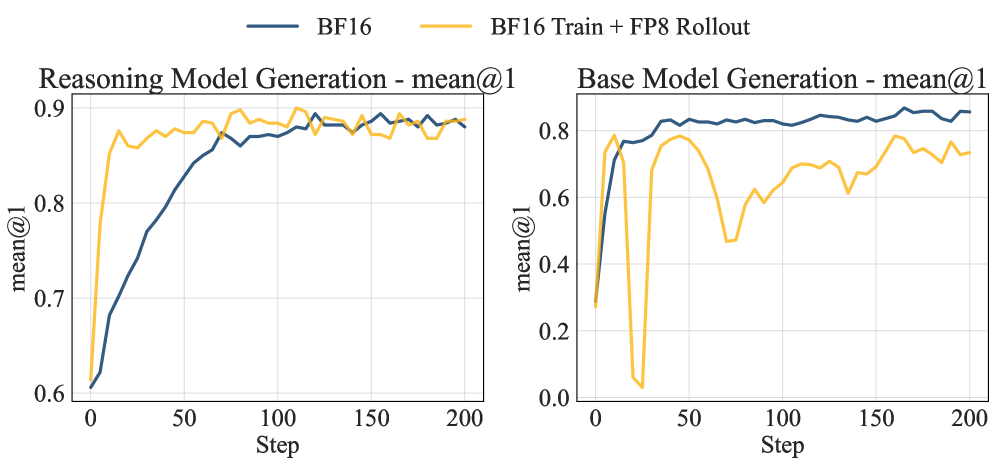
Обучение с подкреплением представляет собой перспективный подход к повышению способности больших языковых моделей генерировать логически выстроенные цепочки рассуждений, однако стабильность процесса обучения остается серьезной проблемой. Исследования показывают, что существующие методы, такие как BF16-Train-FP8-Rollout, могут приводить к ухудшению производительности моделей. В частности, при обучении на наборе данных DeepMATH, модели Qwen2.5-7B демонстрируют снижение точности до 5%, а Qwen3-8B-Base — до 10.3%. Это подчеркивает необходимость разработки более устойчивых алгоритмов обучения, способных эффективно использовать возможности обучения с подкреплением без ущерба для общей производительности языковой модели.
Jet-RL: Унифицированная Точность для Стабильного Обучения
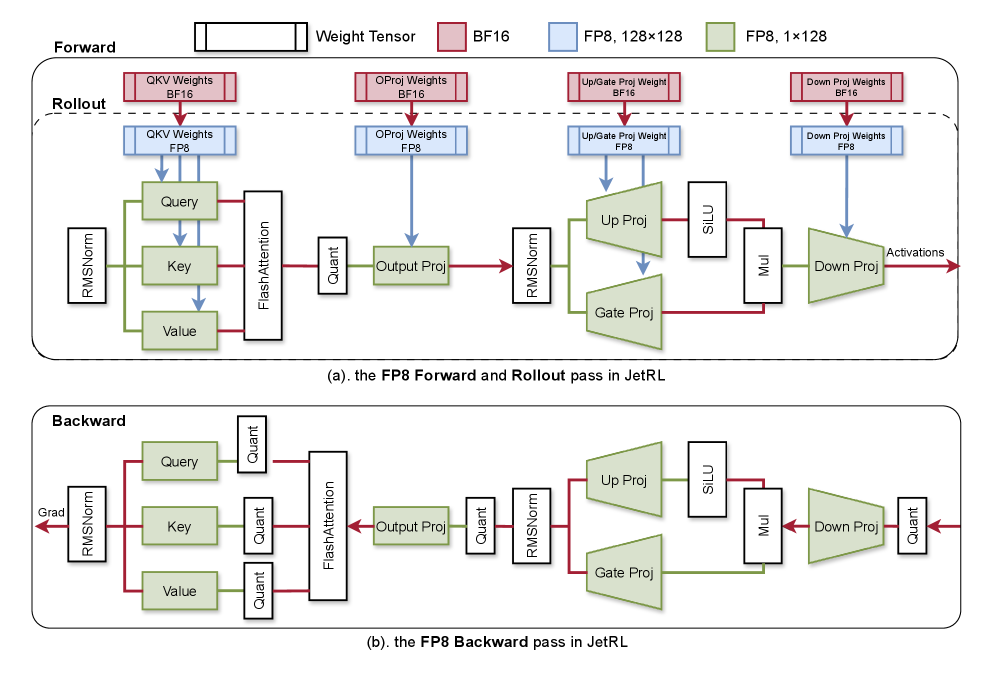
Jet-RL представляет собой фреймворк, разработанный для стабилизации обучения с подкреплением (Reinforcement Learning) для больших языковых моделей (LLM). Ключевой особенностью является обеспечение сквозного потока данных в формате FP8 на всех этапах — от обучения до развертывания (rollout). Такой подход направлен на устранение узких мест, связанных с точностью вычислений, и максимизацию вычислительной эффективности, что позволяет добиться стабильности обучения и предсказуемости поведения модели. Унификация точности на всех стадиях упрощает процесс обучения и развертывания, а также снижает вероятность ошибок, возникающих из-за несовместимости форматов данных.
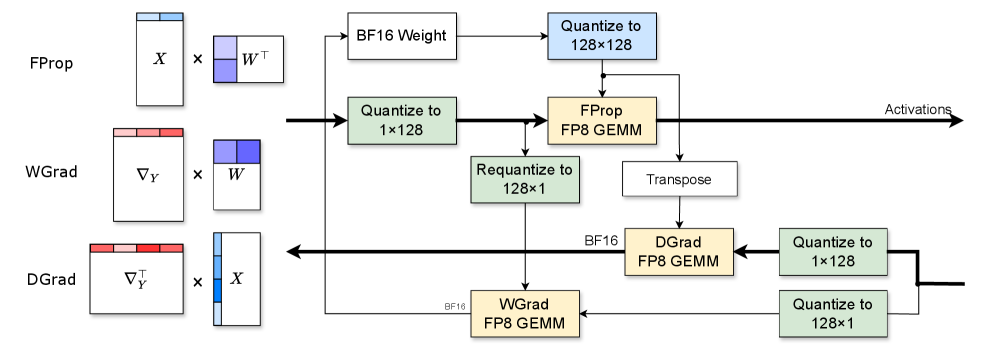
Подход Jet-RL объединяет обучение в формате BF16 с квантизацией до FP8 для минимизации узких мест, связанных с точностью вычислений, и максимизации вычислительной эффективности. Использование BF16 на этапе обучения позволяет сохранить градиенты и веса модели с высокой точностью, в то время как квантизация до FP8 применяется для промежуточных вычислений и хранения весов, что значительно снижает требования к памяти и увеличивает скорость обработки. Такая комбинация позволяет избежать потери точности, характерной для полной квантизации, и в то же время получить существенное увеличение производительности по сравнению с использованием только BF16.
Использование квантования FP8 в Jet-RL позволяет существенно снизить объем занимаемой памяти и ускорить процесс обучения без значительной потери производительности. В ходе экспериментов достигнуто ускорение в 1.16x на всех этапах обучения и вывода, при этом отклонение от результатов, полученных с использованием BF16, не превышает 1%. Ключевым фактором является тщательный выбор гранулярности квантования, обеспечивающий оптимальный баланс между степенью сжатия и сохранением точности вычислений. Данный подход позволяет эффективно обучать и развертывать большие языковые модели, снижая требования к вычислительным ресурсам.
Jet-RL поддерживает обучение с использованием политики (On-Policy Training), что обеспечивает стабильные обновления политики и согласованную генерацию цепочек мыслей (CoT). Экспериментальные данные показали ускорение обучения на 1.41x для моделей размером 8 миллиардов параметров и ускорение развертывания (rollout) на 1.33x для моделей в 32 миллиарда параметров. Использование On-Policy Training в Jet-RL способствует повышению стабильности процесса обучения и предсказуемости результатов, что критически важно для больших языковых моделей.
Проверка на Практике: Математическое Рассуждение
Для оценки Jet-RL использовалась модель DeepSeek-R1, применяющая алгоритм Group Relative Policy Optimization. Проверка проводилась на стандартных наборах данных для решения математических задач, включающих GSM8K, MATH и DeepMATH. На данных наборах оценивалась способность системы решать задачи различной сложности, начиная от базовой арифметики (GSM8K) до более сложных алгебраических и геометрических задач (MATH, DeepMATH). Использование этих наборов данных позволило провести объективное сравнение Jet-RL с другими подходами в области решения математических задач.
Результаты экспериментов демонстрируют устойчивое и значительное улучшение в решении сложных математических задач при использовании Jet-RL с DeepSeek-R1. Наблюдается повышение точности на ключевых бенчмарках, таких как GSM8K, MATH и DeepMATH, что подтверждает эффективность разработанного подхода к унифицированному потоку точности. Улучшение производительности связано с оптимизацией процесса вычислений и более эффективным использованием доступных ресурсов для решения задач, требующих высокой вычислительной мощности и точности, например, решение x^2 + 2x + 1 = 0. Данные результаты свидетельствуют о потенциале Jet-RL для применения в задачах, требующих сложных математических расчетов и высокой надежности.
Для существенного ускорения фазы Rollout используется комбинация DeepGEMM и тензорного параллелизма. DeepGEMM оптимизирует операции матричного умножения, критичные для вычислений в процессе Rollout, что позволяет повысить пропускную способность и снизить задержки. Тензорный параллелизм позволяет распределить нагрузку по нескольким устройствам, эффективно используя ресурсы и сокращая время вычислений. Данный подход обеспечивает эффективный вывод (inference) с использованием квантованных моделей, сохраняя при этом высокую точность и производительность.
Архитектура Jet-RL обеспечивает бесшовную интеграцию с популярными движками вывода, такими как vLLM и VeRL, что позволяет эффективно развертывать и масштабировать решения для решения математических задач. Использование этих движков позволяет оптимизировать процесс инференса, снизить задержки и повысить пропускную способность, обеспечивая возможность обработки большого объема запросов. Совместимость с vLLM и VeRL упрощает внедрение Jet-RL в существующие инфраструктуры и позволяет использовать преимущества аппаратного ускорения, предоставляемого этими движками.
Влияние и Перспективы: Развитие Интеллекта
Успешная реализация Jet-RL наглядно демонстрирует возможности смешанной точности квантования для раскрытия всего потенциала больших языковых моделей (LLM) при одновременном значительном снижении вычислительных затрат. Этот подход позволяет представлять параметры и активации модели с использованием различных уровней точности, сохраняя при этом высокую производительность. Вместо использования стандартной 32-битной точности, Jet-RL эффективно использует 8-битные и даже более низкие форматы для большей части вычислений, что приводит к уменьшению потребления памяти и ускорению работы модели. Подобная оптимизация открывает путь к более эффективному использованию LLM на различных платформах, включая устройства с ограниченными ресурсами, и делает передовые технологии искусственного интеллекта более доступными для широкого круга пользователей.
Разработанная схема открывает возможности для внедрения мощных моделей рассуждений на устройствах с ограниченными ресурсами, значительно расширяя доступ к передовым технологиям искусственного интеллекта. Это особенно важно для мобильных устройств, встроенных систем и других платформ, где вычислительная мощность и энергопотребление являются критическими факторами. Преодолевая ограничения, связанные с необходимостью в больших объемах памяти и высокой вычислительной мощности, данная технология позволяет развертывать сложные модели, способные решать задачи, требующие логического мышления и анализа, в местах, где ранее это было невозможно. В перспективе, это может привести к широкому распространению интеллектуальных систем в различных областях, от персональных помощников до автоматизированных систем управления, делая передовые технологии доступными для более широкой аудитории и способствуя инновациям в различных секторах.
Предстоящие исследования будут направлены на разработку адаптивных стратегий квантования, позволяющих динамически подстраивать точность представления данных в зависимости от сложности задачи и доступных ресурсов. Данный подход позволит еще больше снизить вычислительные затраты без потери качества решения. Параллельно планируется расширение применимости Jet-RL на другие сложные задачи, требующие рассуждений, выходящие за рамки математических вычислений, такие как логический анализ, обработка естественного языка и решение задач, требующих здравого смысла. Ожидается, что это откроет возможности для создания более универсальных и эффективных интеллектуальных систем, способных решать широкий спектр проблем в различных областях.
Сочетание алгоритмических инноваций и аппаратного ускорения открывает перспективу создания интеллектуальных систем, отличающихся как высокой производительностью, так и экологической устойчивостью. Разработка новых алгоритмов, оптимизированных для работы на специализированном оборудовании, позволяет значительно снизить энергопотребление и вычислительные затраты, необходимые для решения сложных задач. Такой подход не только расширяет возможности применения искусственного интеллекта, но и способствует созданию более эффективных и ресурсосберегающих технологий, что особенно важно в контексте растущей потребности в вычислительных мощностях и ограниченности ресурсов планеты. В результате, возможно построение интеллектуальных систем, способных к решению сложных задач при минимальном воздействии на окружающую среду, что является ключевым шагом к созданию устойчивого будущего.
Наблюдатель, повидавший немало оптимизаций, отмечает, что стремление к ускорению обучения больших языковых моделей через квантизацию — это всегда танец на грани. Авторы Jet-RL пытаются приручить эту нестабильность, обеспечивая согласованный поток FP8 между фазами обучения и развертывания. Звучит элегантно, но как показывает опыт, рано или поздно продакшен найдёт способ выдать неожиданный результат. Впрочем, попытки стабилизировать процесс достойны уважения. Как однажды сказал Винтон Серф: «Интернет — это как Швейцарский сыр: он полон дыр, но всё ещё работает». И Jet-RL, похоже, стремится залатать хотя бы некоторые из этих дыр в процессе обучения с подкреплением.
Что дальше?
Предложенная работа, как и большинство «прорывов», решает одну проблему, одновременно создавая, вероятно, две новых. Стабилизация обучения с подкреплением для больших языковых моделей посредством единообразного использования FP8 — это, безусловно, шаг вперед. Но давайте не будем забывать: каждая новая библиотека — это просто ещё одна обёртка над старыми багами, а каждое ускорение — это потенциальное увеличение количества краевых случаев, которые никто не отловит. Вполне вероятно, что через полгода появятся статьи о странных артефактах, возникающих при определённых конфигурациях, и о необходимости «тонкой настройки» этого самого «тонкого» представления чисел.
Вопрос, который остаётся открытым, касается масштабируемости. Работа демонстрирует улучшение производительности, но насколько хорошо этот подход будет работать с моделями, в несколько раз превосходящими текущие размеры? Учитывая тенденцию к постоянному увеличению размеров моделей, можно предположить, что проблемы со стабильностью и точностью неизбежно вернутся, требуя всё более сложных и ресурсоёмких решений. Вспомните, как «всё работало, пока не пришёл agile» — и вот, пожалуйста, очередная итерация «оптимизации», порождающая новые сложности.
В конечном итоге, всё новое — это просто старое с худшей документацией. Предложенный подход, вероятно, станет частью стандартного инструментария, но он не является панацеей. Скорее, это ещё один кирпичик в бесконечной стене, которую мы строим, пытаясь заставить машины делать то, что мы хотим. И эта стена, как известно, всегда будет нуждаться в ремонте.
Оригинал статьи: https://arxiv.org/pdf/2601.14243.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-26 22:39