Автор: Денис Аветисян
Исследователи продемонстрировали, как усиленное обучение с использованием реальных метрик производительности может значительно улучшить качество кода, генерируемого большими языковыми моделями для задач высокопроизводительных вычислений.
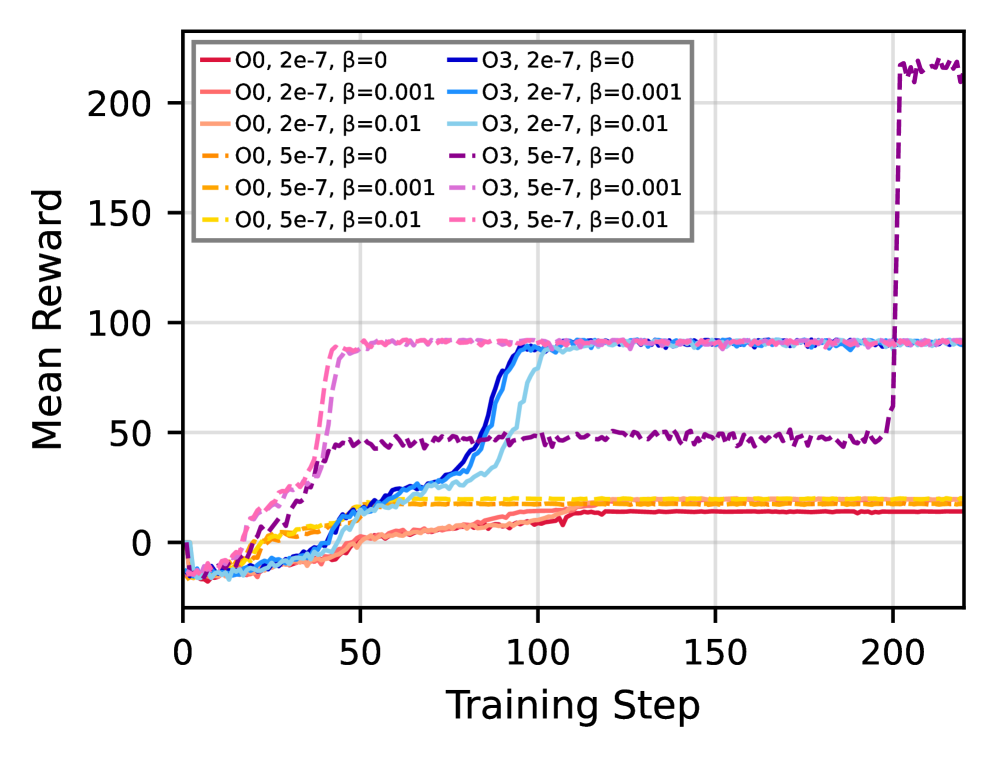
В статье представлен метод оптимизации кода для HPC, основанный на обучении с подкреплением и использовании реальных данных о производительности, полученных на физических машинах.
Несмотря на впечатляющие успехи больших языковых моделей (LLM) в генерации кода, обеспечение высокой производительности сгенерированных программ для высокопроизводительных вычислений (HPC) остается сложной задачей. В работе, озаглавленной ‘Improving HPC Code Generation Capability of LLMs via Online Reinforcement Learning with Real-Machine Benchmark Rewards’, предлагается подход, основанный на обучении с подкреплением в онлайн-режиме, использующий фактическую производительность кода (в GFLOPS) на суперкомпьютере в качестве сигнала вознаграждения. Авторы демонстрируют, что комбинация обучения с подкреплением и алгоритма Staged Quality-Diversity (SQD), позволяющего последовательно расширять набор оптимизаций, значительно улучшает производительность LLM при решении задач, таких как матричное умножение. Возможно ли дальнейшее масштабирование данного подхода для более сложных HPC-приложений и различных архитектур вычислительных систем?
Фундамент: Высокопроизводительные вычисления и большие языковые модели
Современные системы искусственного интеллекта, особенно крупные языковые модели, в значительной степени зависят от высокопроизводительных вычислений (ВВВ) как на этапе обучения, так и при практическом применении. Обучение таких моделей требует обработки огромных объемов данных и выполнения триллионов операций, что практически невозможно без параллельных вычислений, обеспечиваемых ВВВ-инфраструктурой. Применение обученной модели, или инференс, также требует значительных вычислительных ресурсов для быстрого генерирования ответов или анализа данных. По мере усложнения архитектур моделей и увеличения объема обрабатываемой информации, потребность в вычислительной мощности продолжает расти экспоненциально, делая ВВВ неотъемлемой частью развития и функционирования передовых систем искусственного интеллекта.
Потребность в вычислительной мощности, измеряемой в GFLOPS, демонстрирует экспоненциальный рост по мере усложнения моделей искусственного интеллекта. Современные большие языковые модели, требующие обработки огромных объемов данных и выполнения триллионов параметров, предъявляют беспрецедентные требования к вычислительным ресурсам. O(n^2) или даже O(n^3) сложность некоторых операций, умноженная на размер входных данных и количество параметров модели, приводит к значительному увеличению необходимой вычислительной мощности с каждым новым поколением моделей. Эта тенденция обусловлена стремлением к повышению точности, расширению функциональности и улучшению способности моделей к обобщению, что неизбежно требует более сложных архитектур и большего количества параметров, а следовательно, и больше вычислительных ресурсов.
Эффективная высокопроизводительная вычислительная инфраструктура (HPC) является основополагающим фактором для дальнейшего развития возможностей систем искусственного интеллекта. По мере того, как модели становятся всё сложнее и требуют обработки колоссальных объёмов данных, возрастает потребность в вычислительных ресурсах, способных обеспечить необходимую скорость и эффективность. Без современной HPC-инфраструктуры, включающей в себя мощные процессоры, большие объемы памяти и высокоскоростные сети, обучение и применение крупных языковых моделей становится не только трудоёмким, но и зачастую невозможным. Инвестиции в развитие и оптимизацию HPC-систем напрямую влияют на скорость инноваций в области искусственного интеллекта, открывая путь к созданию более умных, адаптивных и полезных технологий для решения широкого спектра задач.

Обучение с подкреплением: Усиление возможностей больших языковых моделей
Обучение с подкреплением представляет собой перспективный подход к улучшению производительности больших языковых моделей (LLM) за счет возможности обучения на основе взаимодействия со средой и получения обратной связи. В отличие от традиционного обучения с учителем, где модель обучается на размеченных данных, обучение с подкреплением позволяет LLM самостоятельно исследовать пространство возможных ответов и оптимизировать свою стратегию генерации текста на основе получаемых вознаграждений или штрафов. Это позволяет модели адаптироваться к конкретным задачам и предпочтениям пользователей, превосходя возможности, достижимые при использовании только статических наборов данных. Процесс обучения включает в себя итеративное взаимодействие модели с окружением, оценку полученных результатов и корректировку параметров модели для максимизации кумулятивного вознаграждения.
Алгоритмы, такие как Proximal Policy Optimization (PPO), Direct Preference Optimization (DPO) и Group Relative Policy Optimization (GRPO), совершенствуют политику языковой модели посредством итеративного улучшения. PPO использует обрезку вероятностей для обеспечения стабильности обучения, предотвращая слишком большие изменения в политике на каждом шаге. DPO напрямую оптимизирует модель для соответствия предпочтениям человека, используя данные о ранжировании ответов. GRPO, в свою очередь, улучшает эффективность обучения в многопользовательских средах, группируя пользователей по схожим предпочтениям. Все три алгоритма используют градиентный спуск для корректировки параметров модели, стремясь максимизировать вознаграждение, получаемое от взаимодействия со средой или от оценок человека, и таким образом постепенно улучшая качество генерируемого текста и соответствие желаемым критериям.
Методы обучения с подкреплением, такие как Proximal Policy Optimization, Direct Preference Optimization и Group Relative Policy Optimization, предъявляют высокие требования к вычислительным ресурсам. Это обусловлено необходимостью многократных итераций обучения, а также обработкой больших объемов данных для оценки и корректировки политики модели. В связи с этим, разработка эффективных реализаций, оптимизирующих использование памяти и вычислительной мощности, является критически важной для обеспечения масштабируемости и практического применения данных алгоритмов. Особое внимание уделяется техникам параллелизации вычислений и использованию специализированного оборудования, например, графических процессоров (GPU), для ускорения процесса обучения и снижения требуемых ресурсов.
Оптимизация для производительности: Методы ускорения HPC
Оптимизация компилятором и использование параллельных API, таких как OpenMP, являются критически важными для достижения максимальной производительности оборудования. Современные компиляторы способны выполнять множество оптимизаций, включая векторизацию, распараллеливание циклов и оптимизацию использования кэша. OpenMP позволяет разработчикам явно указывать параллельные участки кода, что позволяет компилятору генерировать многопоточные приложения, эффективно использующие все доступные ядра процессора. Использование этих инструментов позволяет значительно повысить загрузку процессора и, следовательно, общую производительность приложения, особенно в задачах, требующих интенсивных вычислений. Эффективное использование OpenMP требует тщательного анализа зависимостей данных и избежания состояния гонки, что может привести к непредсказуемым результатам и снижению производительности.
Использование SIMD-инструкций, таких как расширения AVX-512, и оптимизированных библиотек базовых линейных алгебраческих подпрограмм (BLAS), например OpenBLAS, обеспечивает существенное ускорение операций линейной алгебры. AVX-512 позволяет выполнять параллельную обработку данных в пределах одного регистра процессора, увеличивая пропускную способность вычислений. OpenBLAS предоставляет высокооптимизированные реализации стандартных операций линейной алгебры, таких как умножение матриц и решение систем линейных уравнений, используя преимущества SIMD-инструкций и многопоточности. Комбинация этих технологий позволяет значительно снизить время выполнения ресурсоемких вычислений в задачах высокопроизводительных вычислений (HPC).
Эффективность высокопроизводительных вычислений (HPC) напрямую зависит от минимизации задержек доступа к памяти и максимизации пропускной способности. Методы блокировки кэша (Cache Blocking) разбивают большие массивы данных на более мелкие блоки, которые помещаются в кэш-память процессора, снижая необходимость обращения к более медленной основной памяти. Оптимизированные алгоритмы умножения матриц, такие как алгоритм Страссена или алгоритмы, использующие блочную структуру данных, также играют важную роль. Эти методы позволяют сократить количество операций доступа к памяти и повысить эффективность использования кэша, что приводит к значительному увеличению общей производительности при выполнении операций линейной алгебры и других ресурсоемких вычислений. Правильная реализация данных методов критически важна для достижения максимальной пропускной способности и минимизации задержек, особенно при работе с большими объемами данных.
Для оценки эффективности высокопроизводительного кода (HPC) и выявления областей для оптимизации критически важны эталонные тесты, такие как KernelBench и Mercury. Недавнее исследование, проведенное нашей группой, продемонстрировало достижение пиковой производительности в 549 GFLOPS при выполнении операций умножения матриц с использованием поэтапной стратегии SQD (Staggered Quadrature Decomposition). Данный результат подтверждает важность применения специализированных бенчмарков для количественной оценки производительности и обоснования выбора оптимальных алгоритмических и аппаратных решений в задачах HPC.
Поэтапная оптимизация и разнообразие качества для надежного обучения
Поэтапная оптимизация представляет собой методику, при которой ограничения применяются к процессу обучения постепенно, а не одновременно. Это позволяет избежать резких изменений в параметрах модели, что способствует повышению стабильности обучения и предотвращает возникновение расходимости. Последовательное введение ограничений позволяет модели адаптироваться к новым требованиям на каждом этапе, что приводит к более эффективному использованию вычислительных ресурсов и повышению итоговой производительности. Данный подход особенно полезен при обучении сложных моделей, где одновременное применение всех ограничений может привести к неустойчивости и замедлению процесса обучения.
Методы, такие как Staged Quality-Diversity (SQD), расширяют подход последовательной оптимизации за счет исследования множества путей оптимизации и обеспечения механизмов восстановления после ошибок. В отличие от традиционных алгоритмов, которые стремятся к единственному оптимальному решению, SQD поддерживает популяцию разнообразных решений, что позволяет находить более устойчивые и эффективные стратегии. Это достигается за счет сохранения широкого спектра параметров и стратегий обучения, что позволяет алгоритму адаптироваться к изменяющимся условиям и избегать локальных оптимумов. В случае возникновения ошибок или нестабильности, SQD может вернуться к альтернативным решениям из своей популяции, обеспечивая более надежный процесс обучения.
Использование методов обучения с подкреплением в сочетании со staged optimization и quality-diversity, в частности с применением моделей, таких как Qwen2.5 Coder 14B, обеспечивает надежное и эффективное обучение сложных ИИ-систем. Эксперименты показали улучшение производительности на 20.4% при умножении матриц 256×256 с использованием staged SQD стратегии, достигнув пиковой производительности в 549 GFLOPS. Данный подход позволяет эффективно оптимизировать сложные задачи и достигать высоких показателей производительности в задачах, требующих значительных вычислительных ресурсов.
Эксперименты с оптимизацией O0 показали прирост производительности до 125%, в то время как при использовании оптимизации O3 была достигнута производительность в 463 GFLOPS. Данные результаты демонстрируют значительное влияние уровня оптимизации на итоговую производительность системы, подчеркивая важность тщательного подбора параметров компиляции для достижения максимальной эффективности. Полученные значения производительности были измерены в ходе тестов на матричном умножении размером 256×256.
Будущее ИИ: Интеллектуальные помощники HPC и автономное обучение
ChatHPC представляет собой важный прорыв в создании интеллектуальных помощников для высокопроизводительных вычислений (HPC), способных автоматизировать процессы обучения и оптимизации моделей машинного обучения. Данная система позволяет не только упростить настройку сложных вычислительных задач, но и значительно ускорить цикл разработки, избавляя исследователей и инженеров от рутинных операций. Автоматизируя такие аспекты, как выбор оптимальных гиперпараметров, распределение ресурсов и мониторинг производительности, ChatHPC открывает возможности для более эффективного использования дорогостоящего оборудования и позволяет сосредоточиться на инновационных аспектах разработки искусственного интеллекта. Это, в свою очередь, способствует созданию более мощных и эффективных AI-систем для широкого спектра применений, от научных исследований до промышленных задач.
Сочетание обучения с подкреплением, оптимизированной высокопроизводительной инфраструктуры и передовых алгоритмов открывает новую эру автономной разработки искусственного интеллекта. Этот симбиоз позволяет системам самостоятельно настраивать и оптимизировать процессы обучения моделей, минимизируя необходимость ручного вмешательства. В результате, алгоритмы способны самостоятельно исследовать пространство параметров, выявлять наиболее эффективные конфигурации и адаптироваться к изменяющимся требованиям задачи. Такой подход не только ускоряет процесс создания более мощных и эффективных AI-систем, но и позволяет решать задачи, которые ранее были недостижимы из-за их сложности и масштаба. В перспективе, это может привести к созданию самообучающихся систем, способных к непрерывному совершенствованию и адаптации к новым вызовам без участия человека.
Автоматизация процессов обучения и оптимизации моделей машинного обучения посредством систем, подобных ChatHPC, открывает перспективы для беспрецедентного ускорения инноваций в области искусственного интеллекта. Повышение эффективности алгоритмов и использование оптимизированной вычислительной инфраструктуры позволяют создавать более мощные и ресурсоэффективные системы ИИ, применимые в широком спектре областей — от разработки новых лекарственных препаратов и прогнозирования климатических изменений до создания автономных транспортных средств и улучшения систем кибербезопасности. Такая автоматизация не только сокращает время, необходимое для разработки и развертывания новых моделей, но и позволяет исследователям сосредоточиться на решении более сложных задач, расширяя границы возможного в сфере искусственного интеллекта и открывая новые возможности для технологического прогресса.
Исследование демонстрирует, что применение обучения с подкреплением, ориентированного на реальную производительность вычислительных систем, способно значительно улучшить качество генерируемого кода для высокопроизводительных вычислений. Это подтверждает идею о том, что истинное понимание системы приходит через её практическое исследование и оптимизацию. Как однажды заметил Анри Пуанкаре: «Наука не состоит из ряда истин, а из методов, ведущих к истинам». В данном контексте, метод обучения с подкреплением, направленный на максимизацию GFLOPS, становится инструментом для открытия и реализации скрытых возможностей оптимизации кода, раскрывая закономерности, которые остаются незамеченными при статическом анализе. Этот подход позволяет не просто генерировать код, но и адаптировать его к конкретной аппаратной архитектуре, приближая к идеалу производительности.
Куда же дальше?
Представленная работа демонстрирует, что даже столь сложные системы, как большие языковые модели, поддаются оптимизации через взаимодействие с реальным железом. Однако, не стоит обольщаться — улучшение производительности в рамках конкретной задачи, вроде умножения матриц, не означает полного понимания принципов генерации эффективного HPC-кода. Настоящий вызов заключается в создании систем, способных адаптироваться к разнообразию архитектур и алгоритмов, а не просто «настраиваться» на конкретный бенчмарк. Вопрос в том, не ограничиваем ли мы себя, стремясь к локальному максимуму производительности, игнорируя при этом потенциал принципиально новых подходов к компиляции и оптимизации?
Использование методов обучения с подкреплением, безусловно, перспективно, но требует более глубокого анализа стратегий исследования (exploration). Предложенная методика SQD — лишь один из возможных путей. Необходимо исследовать, как различные стратегии поиска и разнообразия влияют на общую устойчивость и обобщающую способность модели. А главное — как избежать ситуации, когда модель «заучивает» оптимальные решения для узкого круга задач, теряя способность к инновациям.
В конечном счете, успех в этой области зависит не только от технических ухищрений, но и от философского подхода. Если система не может быть «взломана», значит, мы её недостаточно поняли. И истинное знание — это не просто умение генерировать быстрый код, а способность увидеть скрытые закономерности и принципы, лежащие в основе вычислительных процессов.
Оригинал статьи: https://arxiv.org/pdf/2602.12049.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Понимание ориентации объектов: новый взгляд на 3D-пространство
- Моделирование кровотока мозга: новый взгляд на скорость и точность
- Квантовая телепортация в новых измерениях: топологические изоляторы
- Самообучающиеся автомобили: новый эталон для ИИ-систем
- Квантовые Завихрения и Пятилетние Планы: Взгляд изнутри
- Обучение представлений для динамических систем: новый взгляд
- Стратегия подцелей: Как научить ИИ долгосрочному планированию
- Квантовая магия: Революция нулевого уровня!
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Понимание сложных систем: новый взгляд на агентные модели
2026-02-14 21:24