Автор: Денис Аветисян
Новый алгоритм позволяет повысить эффективность больших языковых моделей при решении разнообразных задач, фокусируясь на слабых сторонах и обеспечивая более сбалансированные навыки.
В статье представлен Multi-Task GRPO (MT-GRPO) — алгоритм постобработки, улучшающий способность языковых моделей к рассуждениям за счет адаптивной перевзвески задач и выравнивания вклада градиентов.
Несмотря на успехи обучения с подкреплением для улучшения рассуждений больших языковых моделей (LLM) в отдельных задачах, обеспечение надежной производительности в реальных условиях, требующих работы с разнообразными задачами, остается сложной проблемой. В работе ‘Multi-Task GRPO: Reliable LLM Reasoning Across Tasks’ предложен новый алгоритм Multi-Task GRPO (MT-GRPO), который динамически корректирует веса задач и обеспечивает согласованность градиентов, уделяя особое внимание слабым сторонам модели и продвигая сбалансированный прогресс. Эксперименты показывают, что MT-GRPO значительно превосходит существующие подходы в задачах, требующих максимальной надежности, и требует меньше шагов обучения для достижения заданного уровня производительности. Каковы перспективы применения MT-GRPO для создания LLM, способных к универсальным и надежным рассуждениям в широком спектре предметных областей?
Вызов надёжного рассуждения в больших языковых моделях
Несмотря на впечатляющие успехи больших языковых моделей (LLM) в решении разнообразных задач обработки естественного языка, последовательное и надежное рассуждение остается серьезной проблемой. LLM демонстрируют высокую производительность в генерации текста, переводе и ответах на вопросы, однако часто допускают ошибки в логических умозаключениях, требующих более глубокого понимания контекста и применения здравого смысла. Это проявляется в неспособности решать задачи, требующие многоступенчатых рассуждений, или в чувствительности к незначительным изменениям в формулировке вопроса. Таким образом, хотя LLM способны имитировать интеллектуальное поведение, их способность к истинному рассуждению остается ограниченной и требует дальнейших исследований и разработок.
Традиционное увеличение масштаба языковых моделей, выраженное в наращивании параметров и объемов обучающих данных, часто не решает глубинных проблем, связанных со способами обработки информации. Исследования показывают, что, несмотря на впечатляющую способность генерировать текст, модели демонстрируют хрупкость при столкновении с незнакомыми или сложными задачами. Это связано с тем, что увеличение масштаба не всегда приводит к улучшению способности к абстрактному мышлению, логическому выводу или пониманию причинно-следственных связей. В результате, даже самые крупные модели могут допускать ошибки в простых рассуждениях или демонстрировать неустойчивость при небольших изменениях во входных данных, что ограничивает их надежность и применимость в критически важных областях.
Существующие методы постобработки, направленные на улучшение языковых моделей, зачастую сталкиваются с трудностями при поддержании стабильной производительности на различных типах задач. Оптимизация, ориентированная на достижение высоких показателей в одной области, нередко приводит к ухудшению результатов в других, что указывает на необходимость более тонких и сбалансированных стратегий. Вместо универсальных подходов требуется разработка методов, способных адаптироваться к специфике каждой задачи и учитывать взаимосвязи между ними, обеспечивая тем самым надежную и последовательную работу модели в широком спектре сценариев применения. Такой подход позволит преодолеть ограничения существующих решений и создать действительно универсальные языковые модели, способные к комплексному и гибкому мышлению.
Многозадачный GRPO: Новый подход к надежному рассуждению
Представляем Multi-Task GRPO (MT-GRPO) — алгоритм постобработки, расширяющий Group Relative Policy Optimization (GRPO) для улучшения многозадачного рассуждения. MT-GRPO не требует модификации процесса обучения базовой модели и применяется к уже обученной нейронной сети. Алгоритм предназначен для повышения способности модели к обобщению и эффективному решению разнообразных задач, используя преимущества GRPO в адаптации к различным распределениям данных. В отличие от методов, требующих совместного обучения, MT-GRPO позволяет улучшить производительность модели на новых задачах после завершения первоначального обучения, что делает его гибким инструментом для адаптации моделей к меняющимся требованиям.
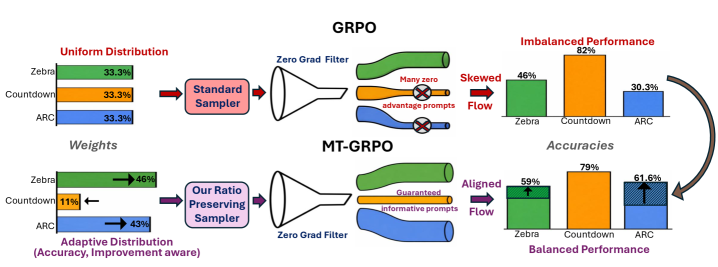
Многозадачный алгоритм GRPO (MT-GRPO) использует сложные стратегии взвешивания задач, включая взвешивание с учетом улучшения (Improvement-Aware Reweighting). Данный подход позволяет динамически расставлять приоритеты в процессе обучения, основываясь на текущей производительности модели на каждой задаче. В частности, задачи, в которых наблюдается недостаточный прогресс, получают больший вес в градиенте, что способствует более эффективному обучению и улучшению результатов на сложных задачах. Взвешивание осуществляется на основе оценки изменения потерь на каждой задаче между итерациями, обеспечивая адаптивное распределение ресурсов обучения.
Ключевым компонентом MT-GRPO является Ratio-Preserving Sampler (RPS), предназначенный для обеспечения репрезентативности обучающей выборки в соответствии с заданными весами задач. RPS динамически корректирует состав обучающей партии, гарантируя, что доля данных, относящихся к каждой задаче, точно соответствует её весу. Это достигается путем отбора примеров из каждого домена с вероятностью, пропорциональной заданному весу, что предотвращает смещение в процессе обучения, вызванное неравномерным представлением задач в мини-пакете. Использование RPS позволяет алгоритму эффективно обучаться на разнородных задачах, избегая доминирования наиболее представленных задач и обеспечивая сбалансированное улучшение производительности по всем задачам.
Алгоритм MT-GRPO разработан для преодоления ограничений существующих методов, таких как DAPO, при решении задач, требующих разностороннего логического мышления. DAPO и аналогичные подходы часто демонстрируют снижение производительности при переносе на новые, незнакомые задачи или при работе с задачами, требующими различных типов рассуждений. MT-GRPO повышает устойчивость за счет динамической адаптации стратегии обучения, позволяя модели эффективно обобщать знания и сохранять высокую производительность на широком спектре задач, отличающихся по сложности и типу требуемых рассуждений. Это достигается за счет улучшения способности модели к переносу знаний и снижению риска переобучения на конкретном подмножестве задач.
Валидация и метрики производительности
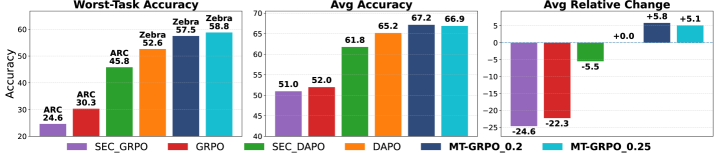
Для всесторонней оценки MT-GRPO использовались ключевые метрики, такие как средняя точность (Average Accuracy) и точность на худшем сценарии (Worst-Task Accuracy). Средняя точность отражает общую производительность модели на всем наборе задач, в то время как точность на худшем сценарии позволяет оценить устойчивость алгоритма и его способность эффективно работать в наиболее сложных ситуациях. Комбинированное использование этих метрик обеспечивает полное представление о производительности MT-GRPO и позволяет выявить потенциальные области для улучшения, а также сравнить его с другими существующими методами.
Анализ результатов экспериментов демонстрирует, что MT-GRPO систематически превосходит базовые методы обучения с подкреплением. В частности, наблюдается значительное улучшение метрики «наихудшая точность» (Worst-Task Accuracy) примерно на 6%. Данный показатель отражает способность модели поддерживать высокую производительность даже на наиболее сложных задачах, что свидетельствует о ее устойчивости и обобщающей способности по сравнению с альтернативными подходами.
Наблюдения показали, что использование MT-GRPO положительно влияет на частоту нулевых градиентов, являющихся критическим фактором эффективного обучения. Адаптивная схема взвешивания, реализованная в MT-GRPO, позволяет снизить количество случаев, когда градиенты стремятся к нулю во время оптимизации. Это, в свою очередь, способствует более стабильному и быстрому обучению модели, поскольку алгоритм реже сталкивается с проблемой «застревания» в локальных минимумах или на плато функции потерь. Увеличение частоты ненулевых градиентов напрямую связано с улучшением скорости сходимости и общей производительностью алгоритма.
В основе MT-GRPO лежит алгоритм GRPO, эффективность которого повышается за счет применения KL-регуляризации. KL-регуляризация, представляющая собой добавление к функции потерь члена, измеряющего расхождение между текущей и предыдущей политиками, способствует стабилизации процесса оптимизации политики. Это достигается за счет ограничения изменений в политике на каждом шаге обучения, предотвращая резкие колебания и обеспечивая более плавную сходимость к оптимальному решению. В результате, KL-регуляризация позволяет GRPO более эффективно исследовать пространство политик и избегать локальных оптимумов, что, в свою очередь, положительно сказывается на общей производительности MT-GRPO.
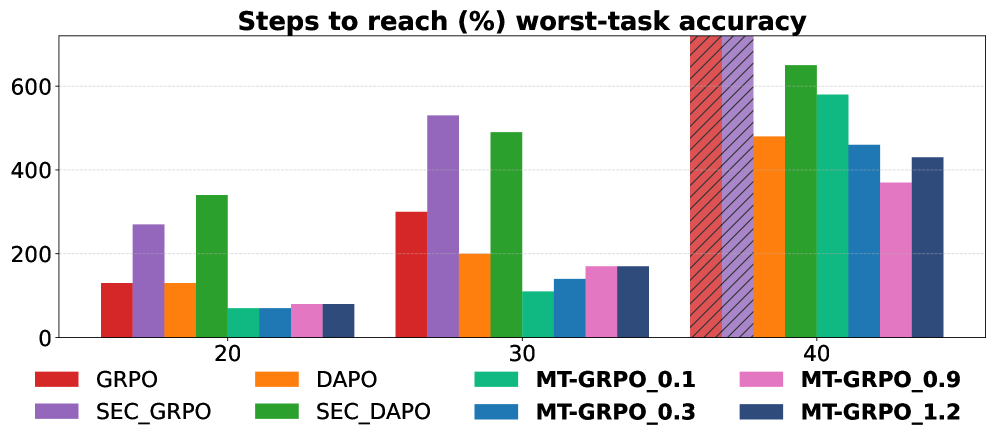
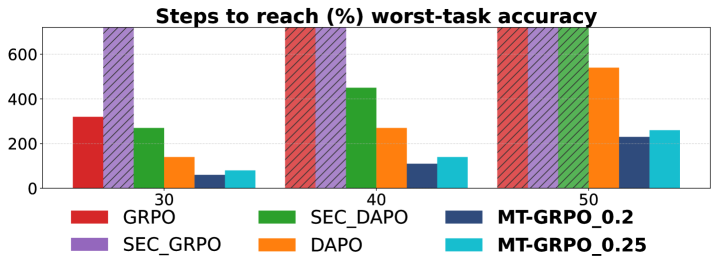
В ходе экспериментов было установлено, что модель MT-GRPO стабильно достигала заданных пороговых значений точности за меньшее количество шагов обучения по сравнению с базовыми методами. Данный факт свидетельствует о повышенной эффективности обучения MT-GRPO, что позволяет сократить время, необходимое для достижения требуемого уровня производительности. Наблюдаемое сокращение числа шагов обучения указывает на более быструю сходимость алгоритма и более эффективное использование вычислительных ресурсов.
К надёжным и адаптируемым системам рассуждений
Алгоритм MT-GRPO обеспечивает поддержку оптимизации с учетом распределения, что существенно повышает устойчивость модели к вариациям во входных данных и улучшает её способность к обобщению. Вместо того, чтобы полагаться на фиксированный набор данных для обучения, MT-GRPO учитывает возможные отклонения в распределении данных, что позволяет модели более эффективно справляться с новыми, ранее не встречавшимися ситуациями. Этот подход особенно важен в реальных приложениях, где входные данные часто бывают шумными или неполными. Посредством учета неопределенности в данных, MT-GRPO позволяет создавать более надежные и адаптивные системы рассуждений, способные сохранять высокую производительность даже в сложных и изменчивых условиях. Такая устойчивость к вариациям данных является ключевым фактором для построения доверительных и эффективных систем искусственного интеллекта.
Алгоритм MT-GRPO эффективно взаимодействует со стратегиями обучения по учебному плану, позволяя постепенно усложнять задачи, предлагаемые модели. Такой подход способствует более быстрому освоению материала и значительно ускоряет процесс обучения. Вместо одновременного освоения всех сложных задач, модель последовательно знакомится с ними, начиная с простых примеров и постепенно переходя к более сложным. Это не только повышает эффективность обучения, но и улучшает обобщающую способность системы, позволяя ей лучше справляться с новыми, ранее не встречавшимися задачами. В результате, применение MT-GRPO в сочетании с обучением по учебному плану позволяет создавать более интеллектуальные и адаптивные системы рассуждений.
Алгоритм MT-GRPO направлен на решение проблемы интерференции задач, которая часто возникает при обучении единой модели решению множества разнородных задач. Вместо того чтобы каждая новая задача ухудшала результаты по ранее изученным, MT-GRPO позволяет модели сохранять и улучшать свои навыки по всем задачам, эффективно интегрируя новые знания. Это приводит к созданию более универсальных и адаптивных систем рассуждений, способных решать широкий спектр задач без существенной потери производительности. Это особенно важно для создания искусственного интеллекта, который может эффективно функционировать в динамично меняющихся условиях и справляться с непредвиденными ситуациями, требующими комплексного анализа и принятия решений.
Внедрение алгоритма MT-GRPO выходит за рамки улучшения результатов выполнения отдельных задач, оказывая существенное влияние на создание более надежных и заслуживающих доверия искусственных агентов. Повышая устойчивость системы к изменениям в данных и снижая вероятность ошибок, MT-GRPO способствует формированию предсказуемого поведения, критически важного для применения ИИ в ответственных областях, таких как здравоохранение или автономное управление. Это позволяет не только повысить эффективность работы агента, но и обеспечить прозрачность его действий, что, в свою очередь, укрепляет доверие пользователей и заинтересованных сторон. В конечном итоге, MT-GRPO способствует переходу от просто «умных» систем к действительно надежным и заслуживающим доверия помощникам, способным решать сложные задачи в реальном мире.
Исследования показали, что алгоритм MT-GRPO демонстрирует наиболее значительные улучшения в решении задач, которые изначально представляли наибольшую сложность для системы. Вместо равномерного повышения эффективности по всем направлениям, MT-GRPO особенно эффективно справляется с «слабыми» задачами, показывая более высокую относительную динамику изменений по сравнению с другими подходами. Это указывает на то, что алгоритм не просто улучшает общую производительность, но и способствует более сбалансированному развитию навыков рассуждения, позволяя системе успешно справляться с широким спектром сложных задач и преодолевать трудности, ранее казавшиеся непреодолимыми. Такая избирательная оптимизация способствует созданию более надежной и универсальной системы искусственного интеллекта.
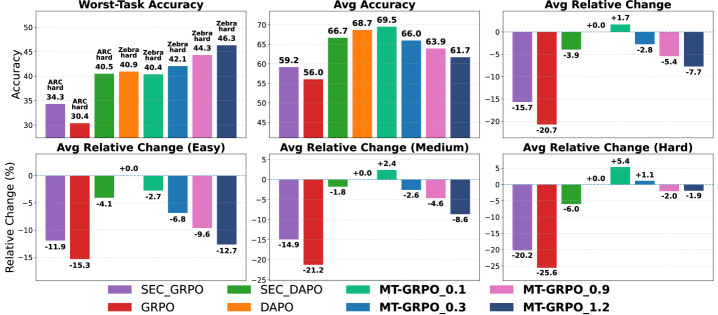
Исследование представляет собой стремление к элегантности в обучении больших языковых моделей. Алгоритм MT-GRPO, посредством адаптивной перевзвески задач и выравнивания градиентов, демонстрирует подход к созданию более сбалансированных и устойчивых систем. Этот метод, фокусируясь на усилении слабых сторон модели, напоминает о важности непротиворечивости и доказательства корректности решения. Как отмечал Эдсгер Дейкстра: «Программирование — это не столько техника, сколько искусство — искусство организации и воплощения мыслей». В данном случае, искусство заключается в создании алгоритма, способного к последовательному и надёжному решению широкого спектра задач, что является залогом истинной интеллектуальной силы.
Куда двигаться дальше?
Представленный алгоритм MT-GRPO, безусловно, демонстрирует улучшение в адаптации больших языковых моделей к разнообразным задачам. Однако, не стоит обольщаться иллюзией полного решения. Проблема «слабых мест» в компетенциях модели, как показывает опыт, не решается простым перевешиванием задач. Скорее, это лишь временное облегчение симптомов, а не лечение первопричины. Истинная устойчивость требует более глубокого понимания механизмов, лежащих в основе приобретения знаний, и разработки методов, позволяющих модели самостоятельно выявлять и устранять пробелы в своей компетенции.
Перспективным направлением представляется исследование методов, позволяющих модели не просто «выполнять» задачи, но и «понимать» их структуру, выявлять общие закономерности и применять полученные знания для решения новых, ранее не встречавшихся проблем. Алгоритмы, основанные на принципах математической индукции и дедукции, представляются более элегантными и надежными, чем эмпирические подходы, основанные на статистическом анализе больших объемов данных.
В хаосе данных спасает только математическая дисциплина. Будущие исследования должны быть сосредоточены на разработке методов, позволяющих формализовать процесс обучения модели, доказать корректность ее работы и обеспечить ее устойчивость к непредсказуемым изменениям в окружающей среде. Иначе, рискуем создать лишь еще одну сложную, но хрупкую систему, подверженную случайным ошибкам и непредсказуемым сбоям.
Оригинал статьи: https://arxiv.org/pdf/2602.05547.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Графы и действия: новый подход к планированию для роботов
- Bibby AI: Новый помощник для исследователей в LaTeX
- Искусственный интеллект, который знает, когда ему нужна подсказка
- Федеративное обучение: баланс между конфиденциальностью и скоростью
- Искусственный разум: Нет доказательств самосознания в современных языковых моделях
- Наука определений: Автоматическое извлечение знаний из научных текстов
- Квантовый скачок венчурного капитала: между надеждой и реальностью
2026-02-07 10:39