Автор: Денис Аветисян
Новый алгоритм CoBA-RL позволяет динамически выделять вычислительные мощности для обучения больших языковых моделей, повышая их эффективность и производительность.
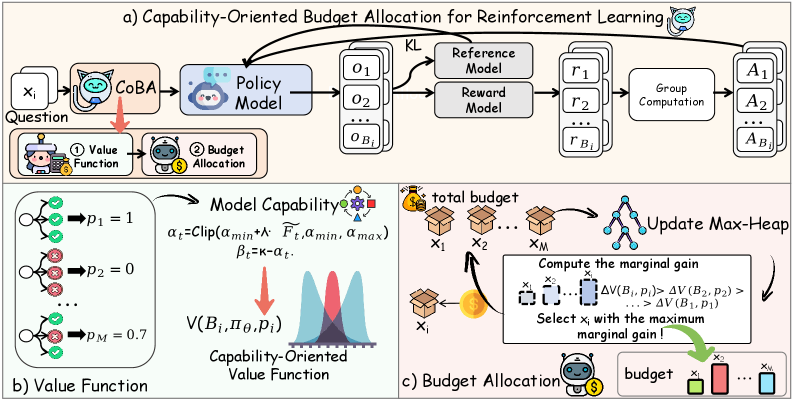
В статье представлена методика, основанная на обучении с подкреплением и ориентированной на оценку текущих возможностей модели для оптимизации распределения бюджета ресурсов.
Несмотря на успехи обучения с подкреплением в улучшении логических способностей больших языковых моделей, существующие подходы часто неэффективно используют вычислительные ресурсы. В данной работе, посвященной алгоритму ‘CoBA-RL: Capability-Oriented Budget Allocation for Reinforcement Learning in LLMs’, предлагается адаптивное распределение бюджета на основе оценки текущих возможностей модели. CoBA-RL использует ориентированную на возможности функцию ценности для определения потенциальной выгоды от обучения на различных задачах, что позволяет эффективно балансировать между исследованием и использованием ресурсов. Возможно ли, за счет более точной оценки ценности обучающих примеров, значительно повысить эффективность и обобщающую способность больших языковых моделей в процессе постобучения?
Преодолевая границы: Сложность обобщения в больших языковых моделях
Несмотря на впечатляющие масштабы и объемы данных, используемые для обучения, большие языковые модели (LLM) часто демонстрируют трудности при решении сложных математических задач. Это указывает на фундаментальное ограничение в их способности к обобщению, то есть к применению полученных знаний к новым, незнакомым ситуациям. Вместо реального понимания принципов математики, модели склонны к запоминанию и воспроизведению шаблонов, обнаруженных в обучающих данных. Когда задача выходит за рамки этих заученных примеров, даже небольшое изменение формулировки может привести к ошибке. Таким образом, хотя LLM способны выдавать впечатляющие результаты на знакомых задачах, их способность к абстрактному мышлению и решению проблем, требующих логического вывода и применения математических принципов, остается ограниченной, подчеркивая необходимость разработки новых подходов к обучению, способствующих более глубокому пониманию и реальному обобщению знаний.
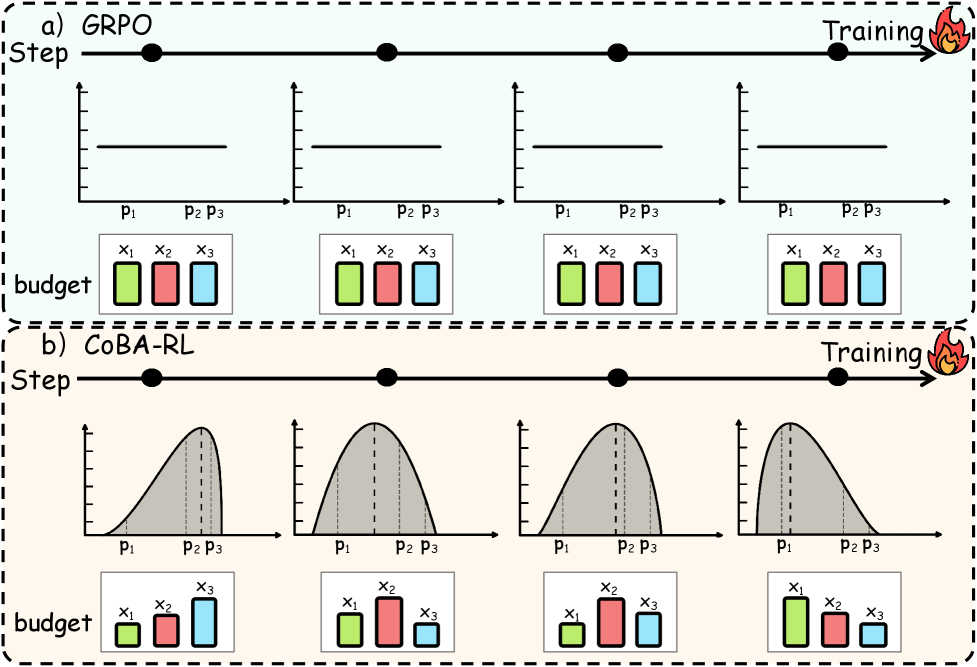
Традиционные методы обучения больших языковых моделей (LLM) зачастую рассматривают все примеры данных как равноценные, не учитывая их сложность или текущий уровень подготовки самой модели. Такой подход игнорирует потенциал целенаправленного обучения, при котором более сложные задачи или те, в которых модель проявляет слабость, получают повышенное внимание. Вместо адаптации процесса обучения к индивидуальным потребностям модели, стандартные алгоритмы распределяют усилия равномерно, что может приводить к неэффективному использованию ресурсов и замедлять прогресс в освоении сложных концепций. Исследования показывают, что фокусировка на “трудных” примерах, а также на тех, которые соответствуют текущим возможностям модели, позволяет значительно повысить ее производительность и обобщающую способность, особенно в областях, требующих глубокого логического мышления и решения задач.
CoBA-RL: Динамическое распределение ресурсов для эффективного обучения
CoBA-RL представляет собой алгоритм обучения с подкреплением, разработанный для динамического распределения бюджета прогонов (rollout budget) в процессе обучения модели. В отличие от традиционных подходов с фиксированным распределением, CoBA-RL адаптирует количество ресурсов, выделяемых для каждой обучающей выборки, исходя из её потенциала для улучшения модели. Алгоритм стремится максимизировать эффективность обучения, направляя ресурсы на наиболее информативные и сложные примеры, тем самым ускоряя сходимость и повышая общую производительность модели. Динамическое распределение бюджета позволяет избежать переобучения на простых примерах и сосредоточиться на тех, которые действительно способствуют улучшению обобщающей способности модели.
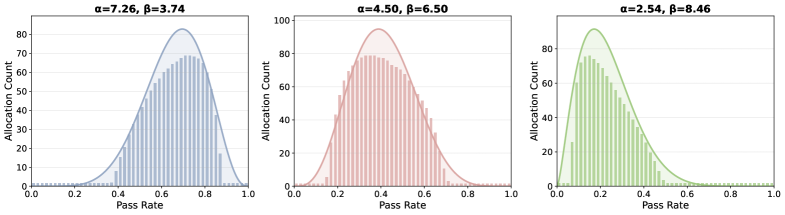
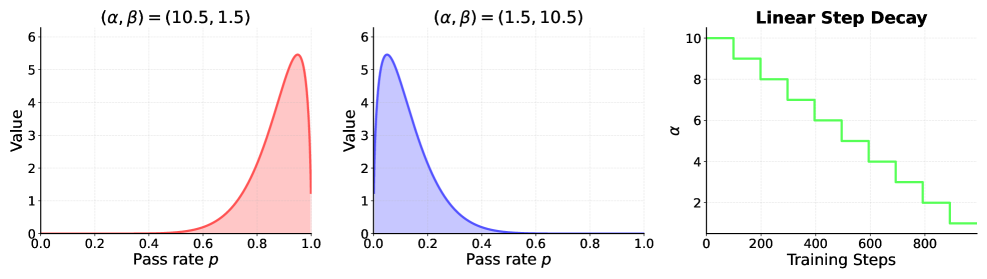
Алгоритм CoBA-RL использует ориентированную на возможности функцию оценки (Capability-Oriented Value Function) для определения ценности каждого экземпляра данных в процессе обучения. Эта функция моделируется с помощью бета-распределения \beta(\alpha, \beta), параметры которого (α и β) динамически адаптируются по мере развития модели. Бета-распределение позволяет учитывать как успех (высокое значение α), так и неудачи (высокое значение β) модели при работе с конкретным экземпляром, отражая её текущие сильные и слабые стороны. Изменение параметров распределения в процессе обучения позволяет системе фокусировать ресурсы на экземплярах, которые потенциально могут максимизировать прирост знаний, а также избегать повторного использования данных, которые модель уже хорошо освоила.
Для эффективного распределения бюджета обучения в алгоритме CoBA-RL используется жадный алгоритм, основанный на куче (heap). Данный подход позволяет динамически выбирать наиболее ценные экземпляры для обучения, основываясь на оценке их потенциала, полученной с помощью Capability-Oriented Value Function. Куча обеспечивает логарифмическую сложность при поиске экземпляра с максимальной ценностью, что значительно снижает вычислительные затраты по сравнению с полным перебором. При каждом шаге алгоритм извлекает наиболее ценный экземпляр из кучи, обучает модель на нем и пересчитывает ценность остальных экземпляров, обновляя структуру кучи. Это гарантирует, что ресурсы направляются на экземпляры, которые в данный момент наиболее способствуют улучшению модели, без излишних затрат на поддержание полной сортировки всех экземпляров.
Количественная оценка возможностей модели и руководство процессом обучения
Функция ценности, ориентированная на возможности (Capability-Oriented Value Function), использует метрики, такие как глобальная частота отказов (Global Failure Rate) и глобальная частота успехов (Global Success Rate), для количественной оценки сложности конкретного экземпляра задачи и уровня владения моделью необходимыми навыками. Определение этих показателей позволяет целенаправленно формировать процесс обучения, концентрируясь на экземплярах, представляющих наибольшую сложность для модели и требующих дополнительной проработки. Это обеспечивает более эффективное использование вычислительных ресурсов и позволяет ускорить процесс достижения желаемого уровня производительности модели.
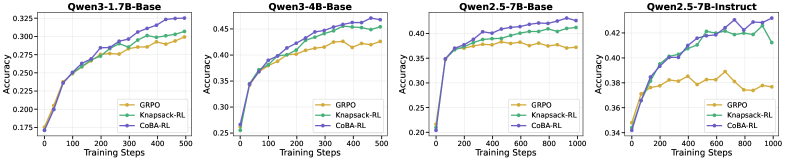
В ходе экспериментов на разнообразных бенчмарках, включающих AIME24, AMC23, OLYMPIAD Bench и MATH500, алгоритм CoBA-RL демонстрирует стабильное превосходство над базовыми методами. На модели Qwen2.5-7B-Instruct достигнута точность в 46.78%, что на 4.54% выше, чем у алгоритма GRPO. Данные результаты подтверждают эффективность CoBA-RL в решении задач, представленных в указанных бенчмарках, и его способность к улучшению показателей точности по сравнению с существующими подходами.
Эффективность CoBA-RL была подтверждена при использовании различных больших языковых моделей (LLM), включая Qwen2.5-7B-Base, Qwen2.5-7B-Instruct, Qwen3-1.7B и Qwen3-4B. На модели Qwen2.5-7B-Base достигнута точность в 47.43%. По результатам тестирования на бенчмарке OLYMPIAD, CoBA-RL показал улучшение производительности на 1.78% по сравнению с Knapsack-RL. На бенчмарках AIME25 и AMC23 зафиксировано повышение точности на 5.62% и неопределенное количество процентов соответственно, по сравнению с GRPO.
Расширяя горизонты: Адаптивные стратегии и будущие направления
Представленный подход CoBA-RL знаменует собой принципиальный сдвиг в обучении с подкреплением, отказавшись от унифицированного распределения ресурсов в пользу динамической стратегии, учитывающей текущие возможности агента. Вместо равномерного использования вычислительных мощностей, система непрерывно оценивает потенциал каждого компонента и адаптирует выделяемые ресурсы для достижения максимального эффекта. Это позволяет не только повысить общую эффективность обучения, но и более рационально использовать доступные ресурсы, направляя их на наиболее перспективные направления развития модели. Такой подход позволяет значительно ускорить процесс обучения и добиться лучших результатов по сравнению с традиционными методами, где ресурсы распределяются статично, не учитывая индивидуальные особенности и прогресс каждого компонента.
Исследования показали, что разработанный подход CoBA-RL демонстрирует значительное превосходство над существующими методами, такими как Knapsack-RL и Linear Step Decay, благодаря адаптивному распределению бюджета для обучения. В отличие от этих подходов, CoBA-RL динамически корректирует ресурсы в зависимости от текущих возможностей модели, что приводит к более эффективному использованию вычислительных ресурсов и улучшению результатов. Особенно примечательно, что время, затрачиваемое на распределение бюджета, составляет всего 0.124 секунды, что на несколько порядков меньше, чем у традиционного метода динамического программирования, требующего 115.05 секунд. Такая скорость позволяет использовать CoBA-RL в задачах, требующих быстрого принятия решений и оперативной адаптации к изменяющимся условиям.
Дальнейшие исследования направлены на расширение области применения данной системы, выходя за рамки текущих задач. Планируется внедрение более сложных метрик оценки возможностей агентов, позволяющих учитывать не только текущую производительность, но и потенциал к обучению и адаптации. Особое внимание будет уделено разработке усовершенствованных стратегий распределения ресурсов, в частности, алгоритмов, ориентированных на приоритетное исследование новых возможностей (Exploration-Prioritized Allocation) и эффективное использование уже известных (Exploitation-Prioritized Allocation). Это позволит не только повысить общую эффективность системы, но и адаптировать её к быстро меняющимся условиям и новым задачам, обеспечивая устойчивое развитие и долгосрочную перспективу применения.
Исследование, представленное в данной работе, фокусируется на оптимизации процесса обучения больших языковых моделей посредством динамического распределения вычислительных ресурсов. Подход CoBA-RL, предложенный авторами, стремится к достижению максимальной эффективности, учитывая развивающиеся возможности модели. Это напоминает слова Давида Гильберта: «В математике нет ничего определённого, только отношения». В данном контексте, CoBA-RL определяет отношения между доступными ресурсами и развитием способностей модели, постоянно корректируя распределение для достижения оптимального результата. Упрощение сложного процесса обучения за счет концентрации на ключевых возможностях — это и есть суть элегантного решения.
Куда же дальше?
Представленный подход, динамическое распределение вычислительных ресурсов для обучения больших языковых моделей, безусловно, указывает на необходимость переосмысления самой парадигмы оптимизации. Однако, за кажущейся эффективностью скрывается более глубокий вопрос: не является ли стремление к максимизации производительности лишь усложнением неизбежного? Акцент на «способностях» модели, как критерий распределения ресурсов, требует дальнейшего уточнения. Что есть «способность» в контексте языка? И как избежать ситуации, когда модель, оптимизированная для выполнения конкретных задач, теряет способность к обобщению и творчеству?
Очевидным направлением дальнейших исследований представляется исследование взаимодействия между различными «способностями». Недостаточно просто научить модель хорошо решать отдельные задачи; необходимо понять, как эти задачи связаны между собой, и как ресурсы можно распределять таким образом, чтобы обеспечить синергию. Крайне важно уйти от линейного взгляда на обучение и перейти к пониманию его как сложного, нелинейного процесса.
И в конечном итоге, необходимо помнить: совершенство — это не добавление новых функций, а избавление от избыточности. Каждый дополнительный параметр, каждая сложная метрика — это потенциальный источник шума. Задача исследователя — не усложнять, а упрощать, стремясь к ясности и элегантности. Иначе, за горой достижений рискует скрыться лишь очередная сложная и неповоротливая конструкция.
Оригинал статьи: https://arxiv.org/pdf/2602.03048.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Третья Разновидность ИИ: Как модели, думающие «про себя», оставят позади GPT и CoT
- BOOM: Визуальный перевод лекций: новый уровень доступности
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Охота на уязвимости: как большие языковые модели учатся на ошибках прошлого
- Диффузия против Квантов: Новый Взгляд на Факторизацию
- Многокритериальная оптимизация: взгляд на народные методы
- Ожившие скелеты: Редактируемая 4D-генерация объектов
2026-02-04 17:14