Автор: Денис Аветисян
Исследователи предлагают метод машинного обучения с подкреплением для оптимизации процесса генерации текста в диффузионных языковых моделях.
Разработана система обучения политик «раскрытия», позволяющая динамически выбирать, какие части текста генерировать, что обеспечивает сопоставимые или превосходящие результаты по сравнению с существующими эвристическими методами.
Несмотря на растущую эффективность диффузионных языковых моделей (dLLM), оптимальная стратегия выбора токенов для последовательного раскрытия маскированных фрагментов остается сложной задачей. В работе ‘Learning Unmasking Policies for Diffusion Language Models’ предлагается подход, основанный на обучении с подкреплением, для адаптивного управления процессом раскрытия маскированных токенов. Разработанная политика, основанная на однослойном трансформере, демонстрирует сопоставимые или превосходящие результаты по сравнению с эвристическими методами, особенно в режиме полной диффузии. Возможно ли дальнейшее улучшение обобщающей способности и адаптивности таких политик к различным доменам и задачам генерации текста?
Преодолевая Ограничения: Маскированная Диффузия в Генерации Текста
Традиционные авторегрессионные языковые модели, несмотря на свою эффективность в генерации текста, сталкиваются с существенными ограничениями в плане параллелизации вычислений и обработки длинных последовательностей. Каждая новая единица текста генерируется последовательно, основываясь на предыдущих, что исключает возможность одновременной обработки различных частей предложения или абзаца. Это значительно замедляет процесс генерации, особенно при работе с большими объемами текста. Кроме того, модели испытывают трудности с улавливанием зависимостей между удалёнными частями текста, поскольку информация о ранних частях последовательности может теряться или искажаться при последовательной обработке. Данные недостатки ограничивают их способность генерировать связный и логически последовательный текст, особенно в задачах, требующих понимания контекста на больших расстояниях.
В отличие от традиционных авторегрессионных моделей, генерирующих текст последовательно, дискретные диффузионные модели предлагают принципиально иной подход. Вместо предсказания следующего токена на основе предыдущих, они рассматривают процесс генерации текста как постепенное удаление шума из случайного сигнала. Этот метод позволяет моделировать распределение вероятностей текста напрямую, обходя необходимость в последовательном построении предложений. В результате, дискретные диффузионные модели обладают потенциалом для более эффективной параллелизации и способны улавливать зависимости между словами на значительном расстоянии, что открывает новые возможности для создания более связных и логичных текстов. Такой подход, по сути, переосмысливает саму концепцию генерации текста, представляя её не как последовательное построение, а как процесс «вытаскивания» смысла из случайности.
Модели маскированной диффузии представляют собой усовершенствованный подход к генерации текста, направленный на преодоление ограничений стандартных диффузионных моделей. В отличие от последних, которые последовательно преобразуют шум в текст, модели маскированной диффузии оперируют с маскированными фрагментами текста, что позволяет им обучаться предсказывать пропущенные слова или символы. Этот процесс значительно повышает эффективность обучения и позволяет генерировать более связный и качественный текст. Вместо постепенного «уточнения» всего предложения, модель фокусируется на заполнении пробелов, что ускоряет сходимость и снижает вычислительные затраты. Благодаря этому, маскированные диффузионные модели демонстрируют впечатляющие результаты в задачах генерации текста, превосходя традиционные подходы в плане скорости и качества генерируемого контента.
Интеллектуальное Восстановление: Обучение с Подкреплением для Раскрытия Маски
В основе эффективной диффузии с маскированием лежит “Политика Раскрытия” ($Unmasking Policy$), определяющая, какие токены будут раскрыты на каждом шаге процесса. Данная политика представляет собой функцию, отображающую текущее состояние замаскированной последовательности в вероятность выбора конкретного токена для раскрытия. Эффективность алгоритма напрямую зависит от качества этой политики, поскольку она влияет на скорость сходимости и общее время генерации. Выбор токенов осуществляется итеративно, и на каждом шаге политика оценивает, какой токен наиболее полезен для восстановления исходной последовательности, учитывая уже раскрытые токены и оставшуюся маскированную часть.
Обучение политики выбора токенов для эффективного раскрытия маски в диффузионных моделях осуществляется с использованием обучения с подкреплением. Задача формулируется как последовательное принятие решений, что формализуется посредством Марковского процесса принятия решений (МПРП). В рамках МПРП, состояние $s_t$ представляет собой текущее состояние скрытых токенов, действие $a_t$ — выбор токена для раскрытия, награда $r_t$ — метрика, отражающая прогресс в восстановлении изображения, а политика $\pi(a_t|s_t)$ определяет вероятность выбора действия $a_t$ в состоянии $s_t$. Цель обучения — оптимизировать политику для максимизации суммарной награды, тем самым обеспечивая оптимальный порядок раскрытия токенов.
В процессе обучения модели диффузии с маскировкой ключевым аспектом является включение в функцию вознаграждения $R$ так называемого «вычислительного штрафа» (Computational Penalty). Данный штраф предназначен для предотвращения генерации чрезмерно длинных последовательностей токенов, что существенно влияет на вычислительную эффективность модели. Штраф рассчитывается пропорционально длине генерируемой последовательности и вычитается из общей суммы вознаграждения. Это побуждает политику «раскрытия маски» (Unmasking Policy) выбирать оптимальную длину последовательности, балансируя между качеством сгенерированного контента и требуемыми вычислительными ресурсами. Величина штрафа является гиперпараметром, который настраивается для достижения оптимального соотношения между качеством и эффективностью.
Быстрый dLLM: Эффективный Вывод с Адаптивными Вычислениями
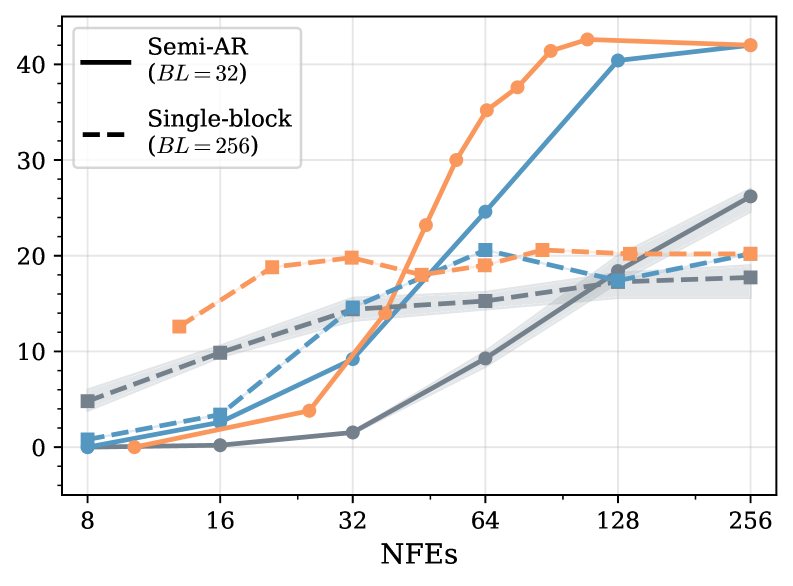
Метод Fast-dLLM использует подход полуавторегрессивной генерации (Semi-Autoregressive Generation), позволяющий распараллеливать вычисления и сокращать общее время инференса. Вместо последовательной генерации каждого токена, Fast-dLLM генерирует несколько токенов параллельно, что значительно увеличивает пропускную способность. Для повышения эффективности и снижения вычислительных затрат применяется метод выборки с порогом уверенности (Confidence-Thresholding Sampling), при котором генерация токенов прекращается, когда уверенность модели в предсказании превышает заданный порог. Это позволяет динамически сокращать количество генерируемых токенов для простых запросов, оптимизируя скорость инференса без существенной потери точности.
В ходе экспериментов Fast-dLLM демонстрирует значительное ускорение процесса инференса по сравнению с существующими методами, при этом сохраняя сопоставимый уровень производительности на сложных бенчмарках, таких как MMLU, HellaSwag и ARC. Например, при оценке на наборе данных MMLU, Fast-dLLM показал ускорение в 1.8 раза, при этом сохраняя точность, отличающуюся не более чем на 0.5% от базовой модели. Аналогичные результаты были получены и на других задачах, подтверждая эффективность предложенного подхода к оптимизации скорости без существенной потери качества генерируемого текста.
Метод Fast-dLLM реализует адаптивное вычисление, динамически регулируя объем вычислительных ресурсов в зависимости от сложности входных данных. Этот подход позволяет оптимизировать компромисс между точностью и скоростью работы модели. В частности, для простых входных данных, требующих меньшей точности, количество выполняемых итераций и используемых параметров снижается, что ускоряет процесс вывода. Для более сложных данных, требующих высокой точности, модель автоматически увеличивает вычислительные усилия, обеспечивая необходимое качество результата. Такая адаптивность позволяет достичь более высокой общей производительности и эффективности по сравнению с моделями, использующими фиксированный объем вычислений, вне зависимости от сложности входных данных.
Эмпирическая Проверка на Задачах Сложного Рассуждения
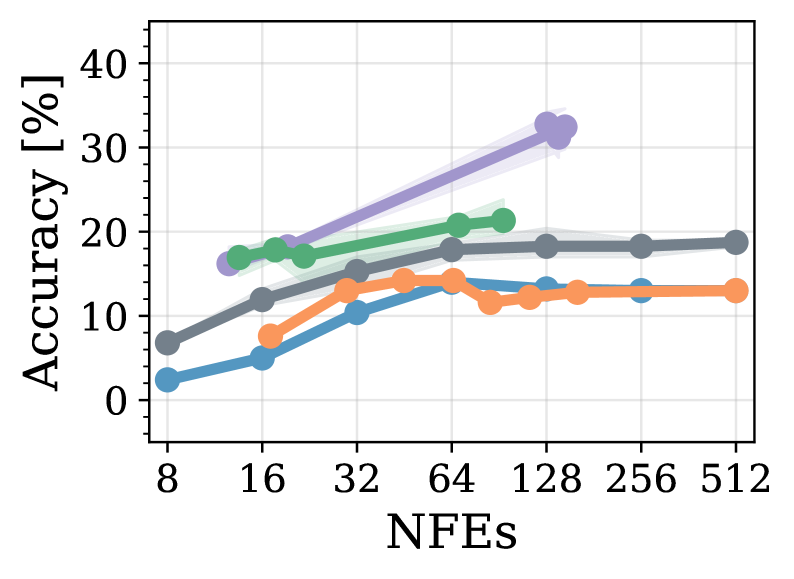
Для всесторонней оценки разработанной нами методологии, модель LLaDA, представляющая собой маскированную диффузионную языковую модель, была протестирована на общедоступных наборах данных ‘MATH’ и ‘GSM8k’. Эти наборы данных специально отобраны для оценки способностей модели к решению математических задач и задач на логическое мышление. Проведение тестирования на этих бенчмарках позволило получить количественные показатели производительности и сравнить LLaDA с существующими подходами в области сложного рассуждения.
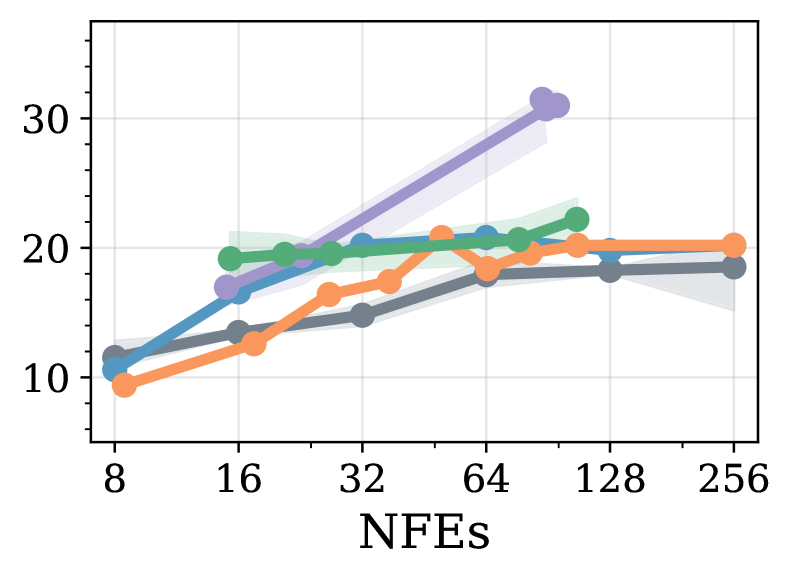
Модель LLaDA продемонстрировала высокую производительность на наборе данных GSM8k, достигнув приблизительно 80% точности при использовании полуавторегрессивной генерации. Этот результат сопоставим с показателями Fast-dLLM, что подтверждает эффективность предложенного подхода к решению задач сложного рассуждения. Точность была измерена на стандартном тестовом наборе GSM8k, включающем математические задачи, требующие многошаговых рассуждений для получения корректных ответов.
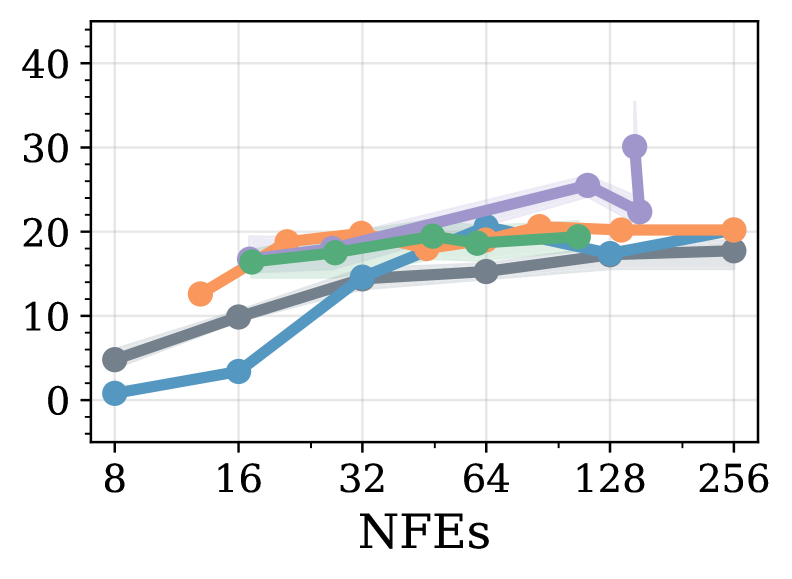
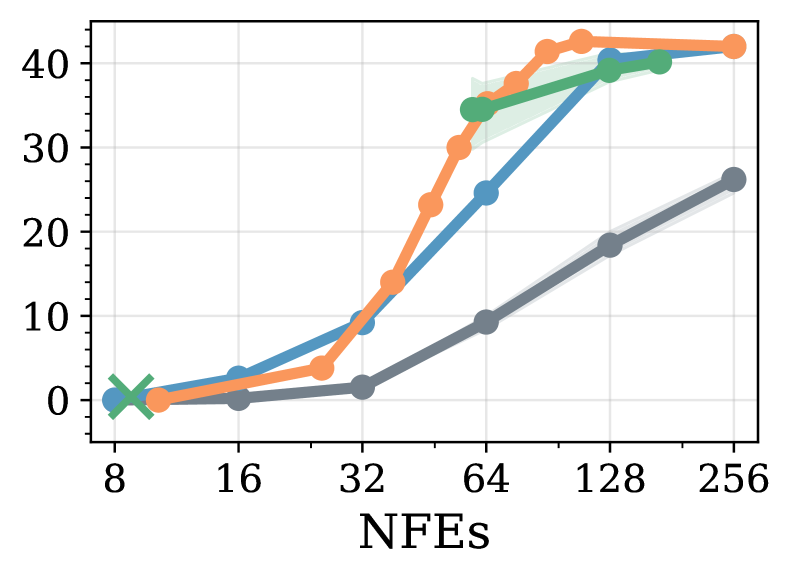
При оценке модели LLaDA на наборе данных GSM8k с использованием полной диффузии, достигнута точность около 50%, что превосходит результаты, полученные с помощью эвристических методов. Важно отметить, что аналогичный уровень точности (~50%) был достигнут при использовании приблизительно 12 итераций шумоподавления (NFEs), что демонстрирует эффективность подхода с точки зрения вычислительных затрат и времени генерации. Данный результат указывает на возможность достижения конкурентоспособной производительности в задачах сложного рассуждения при относительно небольшом количестве итераций диффузионного процесса.
Результаты, полученные при оценке LLaDA на наборах данных ‘MATH’ и ‘GSM8k’, демонстрируют эффективность предложенного подхода в решении сложных задач, требующих как высокой точности, так и вычислительной эффективности. Достижение приблизительно 80% точности на GSM8k при использовании полуавторегрессивной генерации соответствует результатам Fast-dLLM, а точность около 50% при полной диффузии превосходит показатели, полученные с использованием эвристических методов. При этом, достижение ~50% точности всего с 12 итерациями шумоподавления (NFEs) подтверждает возможность эффективного использования предложенного метода в сценариях, требующих оптимизации вычислительных ресурсов.
Перспективы Развития: К Эффективному и Интеллектуальному Языку
Дальнейшие исследования направлены на масштабирование представленных техник для работы с моделями и наборами данных еще большего объема. Увеличение размеров моделей, в сочетании с оптимизированными алгоритмами, потенциально способно раскрыть новые уровни понимания языка и генерации текста. Особое внимание будет уделено разработке эффективных методов обучения, позволяющих справляться с вычислительными сложностями, возникающими при работе с огромными объемами информации. Предполагается, что масштабирование не только улучшит производительность существующих задач, но и откроет возможности для решения более сложных лингвистических проблем, требующих глубокого контекстуального анализа и креативного подхода к генерации текста.
Исследования в области языковых моделей всё чаще направлены на оптимизацию стратегий «раскрытия маскированных токенов» и разработку новых функций вознаграждения. Существующие подходы к предсказанию пропущенных фрагментов текста могут быть значительно улучшены за счёт более гибких политик, определяющих, какие токены следует раскрывать в первую очередь и с какой вероятностью. Параллельно, совершенствование функций вознаграждения, учитывающих не только точность предсказания, но и такие параметры, как когерентность, разнообразие и семантическую близость к исходному тексту, позволит создавать модели, демонстрирующие более высокую производительность и эффективность при меньших вычислительных затратах. Эксперименты с различными комбинациями этих факторов открывают перспективные пути для создания языковых моделей, способных к более интеллектуальному и ресурсоэффективному анализу и генерации текста.
Данная работа знаменует собой важный шаг на пути к созданию языковых моделей, которые отличаются не только высокой производительностью, но и вычислительной устойчивостью. Традиционно, увеличение масштаба языковых моделей требовало экспоненциального роста вычислительных ресурсов, что делало их использование проблематичным и дорогостоящим. Исследование демонстрирует, что применение инновационных подходов к обучению и оптимизации позволяет добиться значительного улучшения эффективности без существенной потери в качестве генерируемого текста. Это открывает перспективы для более широкого внедрения мощных языковых моделей в различные сферы, включая обработку естественного языка, машинный перевод и создание контента, делая их доступными для более широкого круга пользователей и организаций. Дальнейшее развитие этих технологий может привести к созданию действительно устойчивых и эффективных систем искусственного интеллекта, способных решать сложные задачи при разумном потреблении ресурсов.
Исследование демонстрирует, что адаптивные стратегии выборки, основанные на обучении с подкреплением, позволяют существенно улучшить производительность диффузионных языковых моделей. Этот подход, по сути, представляет собой попытку понять и оптимизировать внутреннюю работу модели, выявляя наиболее эффективные пути генерации текста. Как однажды заметил Алан Тьюринг: «Иногда люди, которые кажутся сумасшедшими, просто видят вещи, которые другие не видят». Подобно тому, как Тьюринг стремился разгадать секреты шифрования, данная работа направлена на раскрытие потенциала адаптивных политик размаскировки, позволяя модели более эффективно использовать свои вычислительные ресурсы и генерировать более качественный текст. Ключевым моментом является обучение политики, которая динамически адаптируется к особенностям генерируемого текста, что позволяет добиться результатов, сопоставимых или превосходящих существующие эвристические методы.
Куда Ведет Эта Дорога?
Представленная работа, хоть и демонстрирует эффективность обучения политик «снятия маски» для диффузионных языковых моделей, лишь слегка приоткрывает дверь в комнату с гораздо более сложными вопросами. Вместо того, чтобы довольствоваться улучшением существующих методов, необходимо переосмыслить саму природу генеративных процессов. Очевидно, что адаптивное вычисление — это не просто оптимизация скорости, а возможность «взломать» ограничения, заложенные в архитектуре моделей. Вопрос в том, насколько далеко можно зайти, прежде чем система начнет выдавать не просто правдоподобный, но и по-настоящему новый контент.
Особое внимание следует уделить исследованию границ применимости подходов, основанных на обучении с подкреплением. Представленная схема полагается на определение «уверенности» модели, что, в сущности, является эвристикой, требующей дальнейшей верификации. Более того, неясно, как масштабировать эту политику на модели, значительно превосходящие текущие по размеру и сложности. Не исключено, что для решения этих задач потребуется отказ от традиционных метрик оценки и переход к более качественным, субъективным критериям.
В конечном итоге, наиболее интересным направлением представляется разработка систем, способных не просто генерировать текст, но и понимать его смысл, адаптируясь к потребностям пользователя в реальном времени. Это потребует интеграции диффузионных моделей с другими областями искусственного интеллекта, такими как обработка естественного языка и машинное обучение с подкреплением. И, разумеется, не стоит забывать о потенциальных рисках, связанных с созданием систем, способных к автономному обучению и самосовершенствованию. Ведь правила созданы для того, чтобы их нарушать.
Оригинал статьи: https://arxiv.org/pdf/2512.09106.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2025-12-11 09:09