Автор: Денис Аветисян
Исследователи разработали эффективный метод создания синтетических данных для обучения больших языковых моделей, позволяющий значительно повысить их производительность.
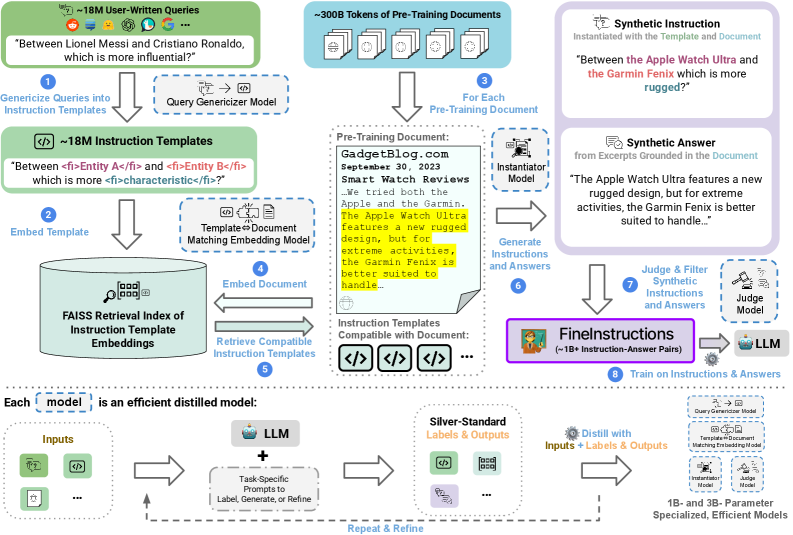
В статье представлен FineInstructions — конвейер для генерации разнообразных синтетических инструкций из предварительно обученных документов, демонстрирующий улучшенные результаты по сравнению со стандартным предварительным обучением и другими подходами к синтетическим данным.
Ограниченность размеченных данных для обучения больших языковых моделей (LLM) традиционно требует предварительного обучения на огромных объемах неструктурированного текста. В работе ‘FineInstructions: Scaling Synthetic Instructions to Pre-Training Scale’ предложен метод, позволяющий трансформировать знания, содержащиеся в текстах предварительного обучения, в миллиарды синтетических пар «инструкция-ответ». Этот подход, использующий около 18 миллионов шаблонов инструкций, позволяет обучать LLM с нуля, используя исключительно целевую функцию инструктивного обучения, что значительно приближает процесс к реальному использованию моделей. Может ли масштабирование синтетических данных стать ключевым фактором в создании более эффективных и удобных LLM для решения широкого круга задач?
Отточенный мост: от предварительного обучения к точному выполнению инструкций
Современные большие языковые модели демонстрируют впечатляющие результаты, осваивая огромные объемы текстовых данных в процессе предварительного обучения. Однако, несмотря на обширные знания, полученные в ходе этого этапа, модели зачастую испытывают трудности при выполнении сложных, многоступенчатых инструкций. Это связано с тем, что предварительное обучение фокусируется на предсказании следующего слова в последовательности, а не на понимании и точном следовании указаниям. В результате, даже модели, обладающие огромным объемом информации, могут генерировать нерелевантные или неполные ответы, если инструкции сформулированы неоднозначно или требуют глубокого понимания контекста и намерений пользователя. Для преодоления этой проблемы необходимы новые подходы к обучению, которые позволят эффективно перенести общие знания, накопленные в процессе предварительного обучения, на решение конкретных задач, требующих точного следования инструкциям.
Существующие подходы к обучению больших языковых моделей часто опираются на тщательно отобранные и размеченные наборы данных, что связано со значительными финансовыми затратами и трудоемкостью. Данные, полученные в результате ручной разметки, хоть и обеспечивают высокую точность на конкретных задачах, часто оказываются неспособными к обобщению и адаптации к новым, ранее не встречавшимся сценариям. Это ограничивает практическую применимость моделей в реальных условиях, где разнообразие задач и входных данных чрезвычайно велико. Ограниченность в доступе к обширным, качественно размеченным данным становится серьезным препятствием для дальнейшего развития и широкого внедрения технологий обработки естественного языка.
Основная сложность в обучении больших языковых моделей заключается в эффективной трансформации обширных знаний, накопленных в процессе предварительного обучения на огромных массивах данных, в способность точно выполнять конкретные инструкции. Модели, хотя и демонстрируют впечатляющие результаты в генерации текста и понимании языка, часто испытывают трудности при применении этих знаний к новым, специфическим задачам, требующим не просто воспроизведения информации, а её адаптации и применения в соответствии с заданными критериями. Решение этой проблемы требует разработки методов, которые позволят моделям не просто хранить факты, но и понимать взаимосвязи между ними, а также уметь извлекать релевантную информацию и применять её для решения конкретной проблемы, указанной в инструкции. Это подразумевает создание механизмов, способных эффективно «переводить» общие знания в контекст конкретной задачи, минимизируя необходимость в дорогостоящей ручной разметке данных и повышая обобщающую способность моделей.

Конвейер FineInstructions: Автоматизированное рождение синтетических данных
Конвейер FineInstructions представляет собой автоматизированное решение для преобразования данных предварительного обучения в синтетические пары «инструкция-ответ». Этот процесс позволяет генерировать обучающие данные без ручной разметки, используя существующий корпус текстов в качестве основы. Автоматизация достигается за счет последовательного применения языковых моделей для создания инструкций и соответствующих ответов, что обеспечивает масштабируемость и эффективность в процессе обучения больших языковых моделей. Полученные синтетические данные используются для тонкой настройки моделей, улучшая их способность выполнять сложные задачи и следовать инструкциям.
Конвейер FineInstructions использует большие языковые модели (LLM) для автоматической генерации разнообразного набора из более чем 18 миллионов уникальных шаблонов инструкций. Этот процесс позволяет существенно расширить объем обучающих данных, необходимых для тонкой настройки моделей. Сгенерированные шаблоны охватывают широкий спектр задач и форматов, что способствует повышению обобщающей способности модели и ее эффективности при решении новых, ранее не встречавшихся задач. Разнообразие шаблонов обеспечивает более полное покрытие пространства возможных инструкций, улучшая способность модели понимать и выполнять различные запросы пользователей.
Процесс автоматизированного создания обучающих данных осуществляется с использованием больших языковых моделей Llama-3 и DataDreamer. Llama-3 используется для генерации разнообразных инструкций и ответов, в то время как DataDreamer обеспечивает автоматизацию процесса и масштабируемость. Эта комбинация позволяет создавать высококачественные пары «инструкция-ответ» без необходимости ручной аннотации, что значительно снижает затраты и время, необходимые для подготовки данных для обучения моделей.
Автоматизированное создание обучающих данных посредством конвейера FineInstructions обеспечивает масштабируемость процесса обучения с подкреплением (instruction tuning) больших языковых моделей (LLM). Это позволяет значительно увеличить объем данных, используемых для обучения, без существенного увеличения ручного труда. В результате, LLM демонстрируют улучшенные результаты в решении более сложных задач, требующих понимания инструкций и генерации соответствующих ответов. Эффективное масштабирование обучения позволяет адаптировать модели к широкому спектру приложений и повышать их общую производительность.
Гарантия качества: Сопоставление и оценка инструкций
Для сопоставления предварительно обученных документов с подходящими шаблонами инструкций используется метод семантического сходства, основанный на векторных представлениях (embeddings), генерируемых моделью BGE-M3. Данный подход предполагает преобразование как документов, так и шаблонов инструкций в многомерные векторы, отражающие их семантическое значение. Затем вычисляется косинусное сходство между векторами документов и шаблонов, позволяющее определить наиболее релевантные пары. Использование BGE-M3 обеспечивает высокую точность представления семантического содержания, что критически важно для эффективного сопоставления и последующего формирования качественных пар «инструкция-ответ».
Для обеспечения эффективного поиска наиболее релевантных документов используется библиотека FAISS в сочетании с векторными представлениями документов, улучшенными за счет применения Gaussian Pooling. Gaussian Pooling позволяет агрегировать векторные представления отдельных частей документа, формируя единое, более компактное и информативное векторное представление всего документа. Это повышает скорость и точность поиска ближайших соседей в векторном пространстве, что критически важно для сопоставления документов с подходящими шаблонами инструкций. Использование FAISS, оптимизированной для работы с большими объемами векторных данных, позволяет значительно ускорить процесс поиска по сравнению с наивными подходами.
Для оценки качества генерируемых пар «инструкция-ответ» используется Flow Judge — дистиллированная модель, обученная для выявления высококачественных ответов. Flow Judge функционирует как автоматизированный оценщик, способный определять, насколько хорошо ответ соответствует предоставленной инструкции и соответствует ли он определенным критериям качества, таким как релевантность, точность и полнота. Обучение модели проводилось на размеченном наборе данных, что позволяет ей эффективно оценивать качество ответов и фильтровать нерелевантные или неточные результаты. Применение Flow Judge обеспечивает объективную и последовательную оценку генерируемых пар, что является важным шагом в процессе улучшения качества данных.
Высокая корреляция между количеством используемых документов и шаблонов инструкций, подтвержденная значением коэффициента детерминации R^2 = 0.96, свидетельствует о способности конвейера генерировать разнообразные и релевантные инструкции. Данный показатель указывает на то, что увеличение числа исходных документов линейно связано с увеличением числа сгенерированных шаблонов, обеспечивая пропорциональное расширение охвата и вариативности инструкций. Это подтверждает эффективность подхода в создании широкого спектра инструкций, адаптированных к различным входным данным и задачам.
Проверка и бенчмаркинг: Демонстрация улучшенной производительности
Для расширения обучающего набора данных была применена методика генерации синтетических данных, использующая разнообразные источники, такие как WildChat, LMSys Chat, вопросы и ответы с Reddit и GooAQ. Этот подход позволил значительно увеличить объем доступной информации для обучения модели, охватывая широкий спектр тем и стилей общения. Вместо трудоемкого и дорогостоящего ручного сбора данных, система автоматически генерирует примеры, имитирующие реальные пользовательские запросы и ответы. Такой способ не только увеличивает масштаб обучения, но и способствует повышению устойчивости модели к различным типам входных данных, а также её способности к обобщению знаний.
Тщательная оценка с использованием стандартных бенчмарков, таких как AlpacaEval, MT-Bench-101 и MixEval, продемонстрировала существенное повышение производительности модели в задачах, требующих сложного логического мышления. Результаты показывают прирост до 39% в общей оценке, что свидетельствует о значительном улучшении способности модели к решению комплексных задач. Данный показатель подтверждает эффективность предложенного подхода к расширению обучающей выборки и его потенциал для создания более интеллектуальных и способных систем искусственного интеллекта.
Исследования демонстрируют значительное повышение эффективности предложенного подхода к обучению языковых моделей. В частности, при оценке на комплексном бенчмарке MixEval, новая методика показала улучшение результата на 69% по сравнению со стандартным предварительным обучением на наборе данных IPT. Данный результат указывает на существенное преимущество в способности модели решать сложные задачи, требующие рассуждений и анализа информации. Улучшение на MixEval особенно важно, поскольку этот бенчмарк включает в себя разнообразные типы вопросов, оценивающие различные аспекты языковых способностей, что подтверждает универсальность и надежность представленного метода.
Предложенный подход демонстрирует значительное преимущество в создании обучающих данных, предлагая масштабируемую и экономически выгодную альтернативу трудоемкой ручной курации. Вместо дорогостоящего и длительного процесса сбора и аннотации данных вручную, система способна генерировать синтетические данные, расширяя существующий обучающий корпус. Это позволяет значительно снизить затраты на обучение моделей, сохраняя при этом, а в некоторых случаях и улучшая, их производительность в сложных задачах, требующих логического мышления и анализа информации. Таким образом, данный метод открывает возможности для более широкого доступа к передовым технологиям обработки естественного языка и стимулирует дальнейшие исследования в данной области.
Представленная работа демонстрирует стремление к созданию алгоритмов, чья корректность может быть доказана, а не просто эмпирически подтверждена. Авторы, подобно математикам, стремящимся к элегантности решения, создали конвейер генерации инструкций, позволяющий повысить производительность больших языковых моделей. Данный подход к синтезу данных, основанный на масштабируемости и разнообразии, напоминает построение строгого математического доказательства, где каждый шаг логически вытекает из предыдущего. Как заметил Г.Х. Гарди: «Математика — это наука о том, что логично». И в данном случае, логика построения данных напрямую влияет на эффективность получаемых моделей.
Куда Ведёт Этот Путь?
Представленный подход к генерации инструкций, безусловно, демонстрирует потенциал синтетических данных, превосходящий стандартное предварительное обучение. Однако, если повышение производительности представляется чудом, стоит задуматься, не упущено ли ключевое свойство — доказуемость. Генерация данных, основанная на шаблонах, пусть и сложных, всё же оставляет вопрос о полноте охвата семантического пространства инструкций открытым. Необходимо перейти от эвристического увеличения разнообразия к формальной верификации полноты и непротиворечивости набора инструкций.
Следующим этапом представляется разработка метрик оценки не просто производительности, а обоснованности ответов модели. Если модель выдаёт корректный ответ, но не может объяснить, почему он верен, это не прогресс, а лишь более изощрённая форма «чёрного ящика». Требуется формализация инвариантов, которые должна соблюдать модель, и проверка её поведения на соответствие этим инвариантам. Иначе, мы просто учим машину имитировать разум, не понимая его сути.
В конечном счёте, задача состоит не в том, чтобы создавать всё более крупные модели, а в том, чтобы создавать более понятные модели. Если решение кажется магией — значит, не раскрыт инвариант. Истинная элегантность алгоритма проявляется не в его способности решать задачи, а в его математической чистоте и доказуемости.
Оригинал статьи: https://arxiv.org/pdf/2601.22146.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Взлом языковых моделей: эволюция атак, а не подсказок
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Кванты в Финансах: Не Шутка!
- Квантовый оптимизатор: Новый подход к сложным задачам
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Искусственный интеллект: новый взгляд на когнитивные механизмы
- Квантовый скачок: Анализ последних новостей
2026-02-01 03:37