Автор: Денис Аветисян
В статье представлен фреймворк Terminal-Task-Gen, позволяющий создавать высококачественные данные для обучения больших языковых моделей, ориентированных на эффективное выполнение задач в командной строке.

Исследование описывает систему адаптации данных и синтетической генерации задач, демонстрирующую значительное повышение производительности и превосходящую более крупные модели.
Несмотря на быстрый прогресс в возможностях больших языковых моделей (LLM), стратегии подготовки данных для создания эффективных терминальных агентов остаются малоизученными. В работе ‘On Data Engineering for Scaling LLM Terminal Capabilities’ представлен систематический анализ практик разработки данных для терминальных агентов, включающий создание конвейера синтетической генерации задач Terminal-Task-Gen и всесторонний анализ стратегий адаптации и обучения данных. Разработанный подход позволил создать масштабный открытый датасет Terminal-Corpus и обучить семейство моделей Nemotron-Terminal, демонстрирующих значительное превосходство над более крупными аналогами на бенчмарке Terminal-Bench 2.0. Какие перспективы открывает дальнейшее совершенствование методов разработки данных для создания более интеллектуальных и автономных терминальных агентов?
Преодоление Разрыва Между Моделью и Реальностью: Необходимость Качественных Данных
Для эффективной работы языковых моделей в реальных условиях, требующих выполнения сложных задач, необходимы обширные и разнообразные наборы данных для обучения. Однако, создание таких данных является существенным препятствием. Современные наборы данных зачастую не обладают достаточным масштабом и вариативностью, что ограничивает способность моделей обобщать полученные знания и успешно функционировать в новых, ранее не встречавшихся ситуациях. Ограниченность данных особенно остро ощущается при обучении моделей для «терминального» взаимодействия — то есть, для выполнения задач, требующих последовательного принятия решений и действий в динамической среде. Недостаток реалистичных и сложных примеров приводит к тому, что модели часто демонстрируют неустойчивость и неспособность адаптироваться к реальным вызовам.
Существующие наборы данных для обучения больших языковых моделей (LLM) зачастую оказываются недостаточными для эффективной обобщающей способности в новых, ранее не встречавшихся ситуациях. Несмотря на объём, они нередко демонстрируют ограниченное разнообразие задач и сценариев, что приводит к снижению производительности при столкновении с реальными, сложными запросами. Модели, обученные на узкоспециализированных данных, могут демонстрировать высокую точность в рамках знакомых условий, но быстро теряют эффективность при незначительных отклонениях от привычного контекста. Эта проблема особенно актуальна для LLM, предназначенных для взаимодействия с реальным миром, где разнообразие возможных ситуаций практически бесконечно, и простое увеличение объёма данных не решает проблему недостатка репрезентативности и сложности.
Простое увеличение объемов собираемых данных для обучения больших языковых моделей представляется неэффективным и экономически невыгодным решением. Несмотря на кажущуюся простоту, наращивание датасетов не устраняет ключевую проблему — сложность задач, с которыми предстоит справлять моделям в реальном мире. Увеличение масштаба сбора данных неизбежно приводит к экспоненциальному росту затрат и требует значительных ресурсов, в то время как модели продолжают испытывать трудности с обобщением знаний и адаптацией к новым, непредсказуемым сценариям. Подобный подход лишь усугубляет проблему, не решая фундаментальную задачу — предоставление моделям данных, отражающих разнообразие и сложность реальных взаимодействий.
Для преодоления ограничений, связанных с недостаточным объемом и сложностью существующих наборов данных для обучения больших языковых моделей, необходим принципиальный переход к генерации целенаправленных обучающих данных. Вместо пассивного сбора информации, все большее внимание уделяется алгоритмам и методам, способным самостоятельно создавать реалистичные и разнообразные сценарии взаимодействия. Такой подход позволяет не просто увеличить объем данных, но и контролировать их качество и сложность, обеспечивая модели возможность эффективного обобщения и адаптации к новым, ранее не встречавшимся ситуациям. Этот сдвиг парадигмы предполагает разработку систем, способных генерировать данные, имитирующие сложные задачи и требующие от модели проявления логического мышления, планирования и решения проблем — ключевых элементов для успешного взаимодействия с реальным миром.
Terminal-Task-Gen: Проактивное Создание Данных для Обучения
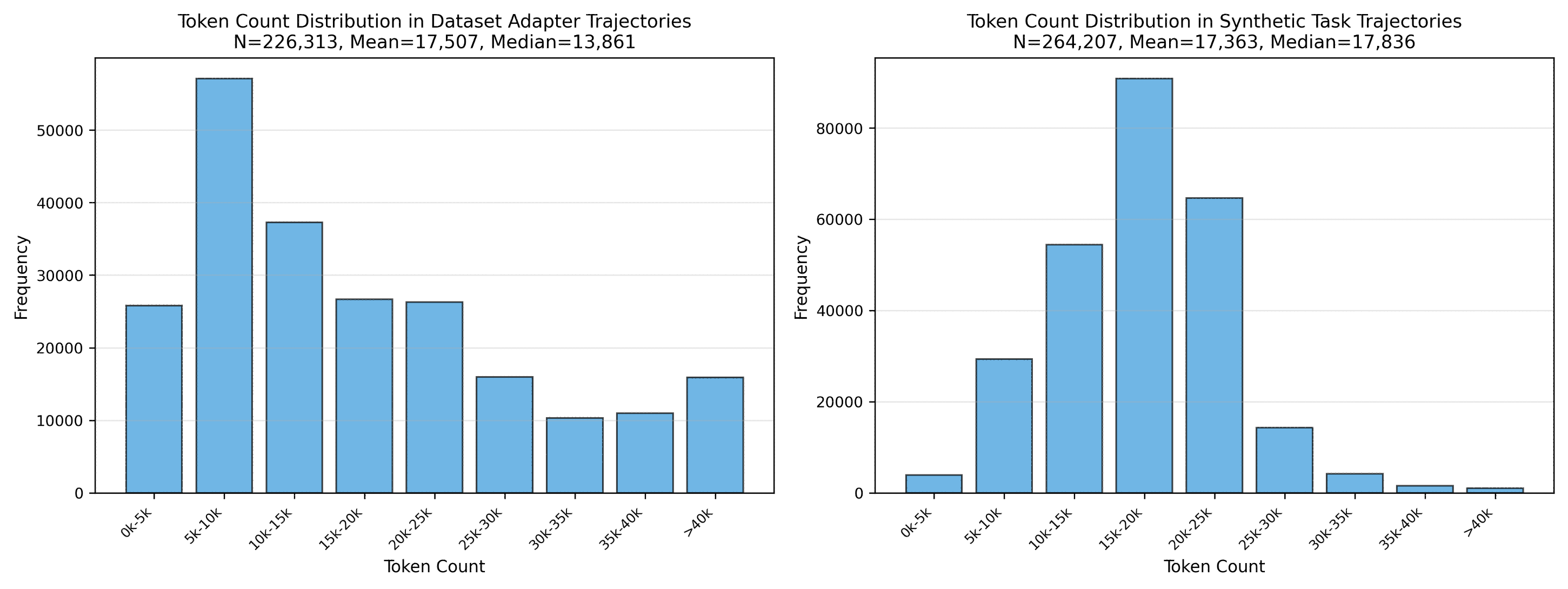
Система Terminal-Task-Gen представляет собой комплексный подход к генерации обучающих данных для агентов, взаимодействующих с терминальными средами. В основе лежит комбинирование методов адаптации существующих наборов данных и синтетической генерации новых. Адаптация данных позволяет использовать и улучшать уже имеющуюся информацию, в то время как синтетическая генерация создает новые сценарии и ситуации, расширяя возможности обучения агента. Данный подход обеспечивает систематическое создание данных, необходимых для эффективной работы агента в различных условиях, и позволяет избежать ограничений, связанных с ручным сбором или ограниченностью существующих наборов данных.
В основе системы Terminal-Task-Gen лежит структурированная таксономия навыков, определяющая пространство возможных действий и задач для агента. Данная таксономия представляет собой иерархическую классификацию навыков, позволяющую декомпозировать сложные задачи на более простые, атомарные действия. Каждый узел таксономии соответствует конкретному навыку или подзадаче, а связи между узлами отражают зависимости между ними. Это позволяет систематически генерировать разнообразные сценарии обучения, охватывающие широкий спектр возможных действий агента и обеспечивающие его эффективное обучение в различных условиях. Использование структурированной таксономии гарантирует полноту и последовательность генерируемых данных, что критически важно для обучения надежных и обобщающих агентов.
В системе Terminal-Task-Gen для генерации сложных и разнообразных траекторий используется большая языковая модель DeepSeek-V3.2, функционирующая как ‘обучающая’ модель. DeepSeek-V3.2 генерирует последовательности действий агента, формируя обширный набор примеров для обучения. Данные, сгенерированные моделью, отличаются высокой сложностью и разнообразием, что позволяет обучать агентов решать широкий спектр задач и адаптироваться к различным ситуациям. Объем генерируемых траекторий достаточен для эффективного обучения, обеспечивая надежную основу для развития навыков целевого агента.
Для обеспечения генерации достаточного объема траекторий, необходимого для обучения агентов, используется инфраструктура Harbor. Данная платформа предоставляет возможности для масштабируемого и параллельного выполнения задач генерации данных, что критически важно при работе со сложными моделями и большими пространствами действий. Harbor позволяет эффективно распределять вычислительные ресурсы и управлять процессом создания траекторий, обеспечивая тем самым необходимый объем данных для обучения моделей, превосходящий возможности ручного создания или ограниченных вычислительных мощностей. Это позволяет значительно ускорить процесс обучения и повысить качество получаемых моделей.
Nemotron-Terminal: Тонкая Настройка для Превосходной Производительности
Семейство моделей Nemotron-Terminal построено на архитектуре Qwen3 и подверглось специализированной тонкой настройке (fine-tuning) для достижения высоких результатов в задачах взаимодействия с терминалом. В отличие от базовой модели Qwen3, Nemotron-Terminal оптимизировано для обработки и генерации команд и ответов, характерных для среды командной строки. Это достигается путем обучения модели на специализированном наборе данных, содержащем примеры сеансов терминала и связанных с ними задач, что позволяет ей эффективно понимать и выполнять инструкции, вводимые пользователем через терминал.
Применение контролируемого обучения (SFT) с использованием данных, сгенерированных Terminal-Task-Gen, демонстрирует существенное улучшение производительности моделей семейства Nemotron-Terminal на сложных эталонных тестах. Данный подход позволяет повысить точность и эффективность выполнения задач, связанных с взаимодействием с терминалом, за счет обучения на специально сгенерированном наборе данных, отражающем реальные сценарии использования. Результаты показывают, что SFT является ключевым фактором в достижении высоких показателей на бенчмарке Terminal-Bench 2.0, что подтверждается превосходством Nemotron-Terminal-32B над Qwen3-Coder-480B и успешной работой более компактных моделей 8B и 14B.
Использование открытых фреймворков, таких как veRL, значительно упрощает процесс Supervised Fine-Tuning (SFT) и повышает эффективность обучения моделей. veRL предоставляет инструменты и инфраструктуру для автоматизации ключевых этапов SFT, включая сбор данных, обучение и оценку. Это позволяет сократить время и ресурсы, необходимые для дообучения моделей, и обеспечивает возможность масштабирования процесса обучения для больших наборов данных и сложных задач. В частности, veRL оптимизирует использование вычислительных ресурсов и предоставляет гибкие возможности настройки параметров обучения, что способствует повышению производительности и стабильности модели Nemotron-Terminal.
Оценка возможностей моделей семейства Nemotron-Terminal проводилась с использованием Daytona — платформы, обеспечивающей надежную и параллельную оценку на бенчмарке Terminal-Bench 2.0. В ходе тестирования, модель Nemotron-Terminal-32B продемонстрировала результат 27.4±2.4, превзойдя показатель Qwen3-Coder-480B, составивший 23.9±2.8. Данные результаты подтверждают эффективность подхода к тонкой настройке, применяемого в Nemotron-Terminal, в задачах взаимодействия с терминалом.
Меньшие модели семейства Nemotron-Terminal продемонстрировали значительную эффективность в задачах взаимодействия с терминалом. Согласно результатам оценки на наборе данных Terminal-Bench 2.0, модель Nemotron-Terminal-8B достигла показателя 13.0±2.2, а модель Nemotron-Terminal-14B — 20.2±2.7. Эти результаты свидетельствуют о том, что даже модели с меньшим количеством параметров способны достигать высокой производительности в специфических задачах, связанных с работой в терминале.
Расширяя Горизонты: Длинный Контекст и Будущие Направления
Обучение с увеличенной максимальной длиной последовательности, или так называемое “Long Context Training”, является ключевым фактором для развития способности агентов к рассуждениям на основе расширенных траекторий. Способность обрабатывать и анализировать длинные цепочки событий позволяет агенту не просто реагировать на текущую ситуацию, но и учитывать предшествующий контекст, предвидеть последствия действий и строить более эффективные стратегии. В результате, агенты, прошедшие такое обучение, демонстрируют значительно улучшенные показатели в задачах, требующих долгосрочного планирования и принятия решений, например, в сложных играх или при управлении ресурсами в динамической среде. Увеличение длины контекста позволяет агенту учитывать более широкий спектр факторов и, следовательно, принимать более обоснованные и эффективные решения, что является важным шагом на пути к созданию действительно интеллектуальных систем.
Методики, такие как YaRN2, значительно повышают стабильность и эффективность обучения моделей работе с длинными последовательностями данных. В отличие от традиционных подходов, которые часто сталкиваются с проблемой «забывания» информации в начале длинных контекстов, YaRN2 позволяет модели сохранять когерентность и последовательность на протяжении всей последовательности. Это достигается за счет усовершенствованных техник регуляризации и оптимизации, которые предотвращают потерю градиентов и обеспечивают более эффективное распространение информации по всей нейронной сети. В результате, модель способна более точно обрабатывать и понимать длинные контексты, что критически важно для решения сложных задач, требующих учета большого объема информации и долгосрочного планирования.
Возможность обработки длинных последовательностей открывает принципиально новые перспективы для решения сложных задач, требующих развернутого планирования и логических выводов. Теперь агенты способны учитывать более широкий контекст, что критически важно для таких областей, как стратегическое моделирование, анализ больших объемов данных и разработка сложных планов действий. Ранее недоступные задачи, требующие удержания в памяти и сопоставления информации на протяжении длительных временных интервалов, становятся реализуемыми. Это особенно важно для приложений, где успех зависит от понимания долгосрочных последствий действий и способности адаптироваться к меняющимся обстоятельствам, что значительно расширяет область применения искусственного интеллекта.
Дальнейшие исследования направлены на усовершенствование процесса генерации данных, необходимого для обучения интеллектуальных агентов. Особое внимание уделяется разработке новых методов, позволяющих создавать более разнообразные и реалистичные сценарии, способствующие развитию навыков долгосрочного планирования и принятия решений. Параллельно ведётся активный поиск инновационных архитектур нейронных сетей, которые могли бы эффективно обрабатывать большие объемы информации и извлекать из неё полезные знания. Эти усилия призваны значительно расширить возможности агентов, позволяя им решать задачи, требующие глубокого понимания контекста и способности к сложным рассуждениям, и в конечном итоге приблизить создание действительно интеллектуальных систем.
Исследование, представленное в статье, демонстрирует, что эффективная работа с большими языковыми моделями невозможна без тщательной проработки данных. Авторы подчеркивают важность адаптации существующих наборов данных и генерации синтетических задач для повышения качества обучения. Это особенно актуально для улучшения взаимодействия с терминалом, где точность и надежность критически важны. Как однажды заметил Дональд Кнут: «Преждевременная оптимизация — корень всех зол». Данное наблюдение применимо и здесь: попытки сразу построить сложную систему, не имея четкого понимания структуры данных и взаимосвязей, обречены на неудачу. Если система держится на костылях, значит, мы переусложнили её, не уделив должного внимания базовым принципам организации и адаптации данных.
Куда Дальше?
Представленная работа демонстрирует, что кажущееся усложнение в виде адаптации данных и генерации синтетических задач может привести к неожиданной простоте — превосходству над более крупными моделями. Однако, следует помнить, что эта победа достигнута не за счёт абсолютного совершенства, а за счёт более эффективного использования доступных ресурсов. Иллюзия «интеллекта» часто рождается из умения обойти ограничения, а не преодолеть их. Поэтому, задача не в создании бесконечно больших моделей, а в разработке методов, позволяющих извлекать максимум информации из ограниченных данных.
Очевидным направлением дальнейших исследований является изучение границ применимости предложенного подхода. Насколько хорошо масштабируется Terminal-Task-Gen для более сложных задач, требующих более глубокого понимания контекста? Не окажется ли, что кажущаяся эффективность — лишь локальный оптимум, ограниченный спецификой рассматриваемых терминальных взаимодействий? Оптимизация ради оптимизации — опасный путь, если не понимать, что именно оптимизируется. Зависимости от специфических данных и архитектуры — настоящая цена любой «свободы», и игнорировать их нельзя.
В конечном итоге, успех в области создания интеллектуальных агентов для терминального взаимодействия зависит не от технологических ухищрений, а от способности увидеть лес за деревьями. Хорошая архитектура незаметна, пока не ломается, и её ценность заключается не в сложности, а в устойчивости и предсказуемости. Простота масштабируется, изощрённость — нет. И в этом заключается главный урок, который следует из данной работы.
Оригинал статьи: https://arxiv.org/pdf/2602.21193.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая самовнимательность на службе у поиска оптимальных схем
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
2026-02-26 06:00