Автор: Денис Аветисян
Новая система, использующая механизмы самоанализа и памяти, значительно повышает точность и стабильность оптического распознавания символов и понимания визуальной информации.
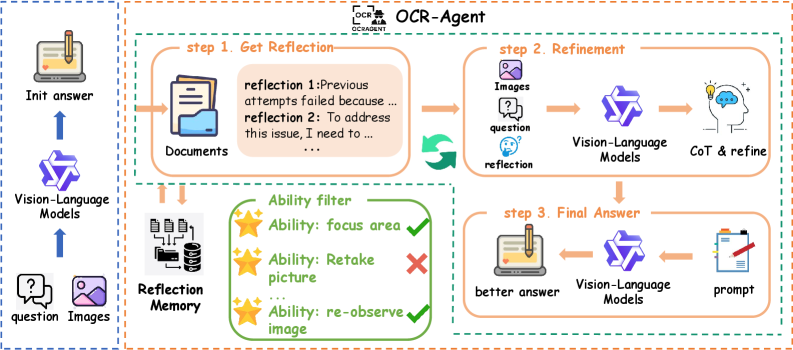
Представлена архитектура OCR-Agent, использующая механизмы рефлексии возможностей и памяти для итеративного улучшения работы больших визуально-языковых моделей.
Несмотря на значительный прогресс в области больших визуально-языковых моделей (VLMs), их способность к самокоррекции и избежанию повторяющихся ошибок остается ограниченной. В данной работе, посвященной разработке ‘OCR-Agent: Agentic OCR with Capability and Memory Reflection’, предложен новый итеративный механизм самокоррекции, включающий в себя возможности рефлексии над способностями и памятью. Данный подход позволяет моделям диагностировать ошибки, планировать исправления и избегать повторения предыдущих попыток, что приводит к повышению точности оптического распознавания символов и улучшению понимания сложных визуальных сцен. Способна ли структурированная саморефлексия стать ключевым фактором в повышении надежности и эффективности VLMs без дополнительного обучения?
Оптическое Распознавание Символов: Вызовы и Перспективы
Оптическое распознавание символов (OCR) представляет собой задачу преобразования изображений, содержащих текст, в машиночитаемый формат, однако существующие методы сталкиваются с существенными трудностями при работе со сложными макетами и зашумленными изображениями. Проблема заключается в том, что реальные документы часто содержат не только текст, но и графику, таблицы и различные элементы оформления, что затрудняет точное выделение и интерпретацию символов. Кроме того, низкое качество изображения, вызванное, например, плохим освещением, размытостью или повреждениями, значительно снижает эффективность алгоритмов OCR. Для преодоления этих препятствий требуются сложные методы предварительной обработки изображений и продвинутые алгоритмы распознавания, способные эффективно отделять текст от фона и компенсировать дефекты изображения.
Первые системы оптического распознавания символов, такие как Tesseract Engine и CRNN Model, заложили основу для автоматической обработки текста, однако их применение часто требовало значительных усилий по предварительной и последующей обработке изображений. Это включало в себя коррекцию искажений, удаление шумов, сегментацию текста и другие трудоемкие этапы, необходимые для достижения приемлемой точности. Подобная необходимость в ручной настройке и адаптации существенно ограничивала возможности масштабирования этих систем и снижала их устойчивость к различным типам документов и условиям сканирования. В результате, несмотря на свою историческую значимость, эти подходы оказались недостаточно эффективными для обработки больших объемов неструктурированных данных в реальных условиях.
В последние годы значительный прогресс в области автоматического распознавания текста был достигнут благодаря появлению крупных визуально-языковых моделей (VLMs). Эти модели демонстрируют впечатляющую способность к распознаванию текста “из коробки”, без необходимости предварительного обучения на специфических наборах данных. Однако, несмотря на этот прорыв, VLM-ы подвержены таким проблемам, как “галлюцинации возможностей” — когда модель выдает информацию, которой на самом деле не обладает, или “застой совершенствования” — когда, достигнув определенного уровня производительности, дальнейшее обучение не приносит существенных улучшений. Это означает, что, хотя VLM-ы и предлагают перспективное решение для автоматического распознавания текста, для достижения надежных и точных результатов требуется дальнейшая работа над устранением этих ограничений и повышением стабильности их работы.
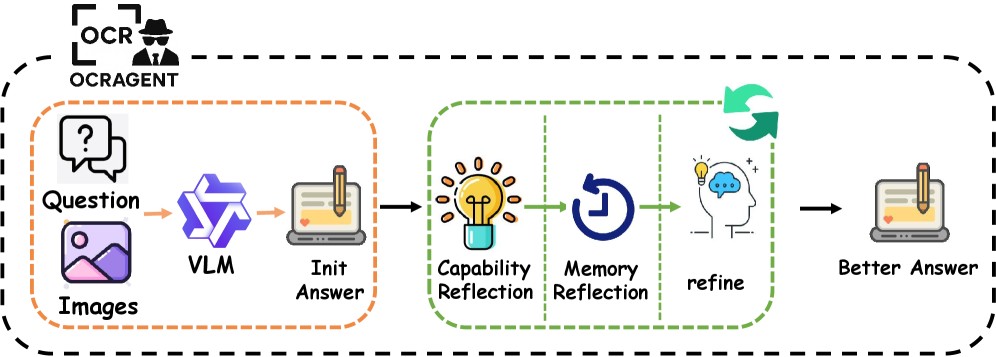
OCR-Agent: Саморефлексивная Архитектура для Итеративной Самокоррекции
Представляем OCR-Agent — новую структуру, предназначенную для улучшения итеративной самокоррекции в больших визуальных языковых моделях (VLMs) за счет использования принципов саморефлексии. В отличие от существующих подходов, OCR-Agent обеспечивает не просто исправление ошибок, а осознанный анализ собственных действий и планирование корректирующих шагов. Это достигается за счет интеграции механизмов, позволяющих модели оценивать собственные рассуждения, выявлять слабые места и формировать стратегии для повышения точности и эффективности решения задач. Структура спроектирована таким образом, чтобы имитировать процесс самоанализа, характерный для человеческого мышления, что позволяет модели учиться на собственных ошибках и улучшать свои результаты в ходе итеративного процесса.
OCR-Agent расширяет возможности существующих методов, таких как Self-Refine и Reflexion, за счет внедрения механизма многооборотной рефлексии (Multi-Turn Capability Reflection). Данный механизм позволяет модели не только выявлять собственные ошибки в процессе решения задачи, но и формировать план корректирующих действий, основываясь на анализе причин возникновения этих ошибок. В отличие от одношаговой коррекции, Multi-Turn Capability Reflection предполагает итеративный процесс самоанализа и внесения изменений, что повышает вероятность успешного исправления и оптимизации результатов. Это достигается путем последовательного пересмотра предыдущих шагов рассуждений и внесения необходимых корректировок на основе выявленных неточностей.
Ключевым компонентом OCR-Agent является механизм “Memory Reflection” (Рефлексия на основе памяти), позволяющий агенту сохранять и использовать историю своих рассуждений. Это достигается путем хранения предыдущих шагов решения задачи и анализа их для выявления повторяющихся ошибок или неэффективных стратегий. Сохранение исторических данных позволяет избежать повторения уже совершенных ошибок и повышает общую эффективность процесса самокоррекции, поскольку агент может опираться на накопленный опыт при планировании последующих действий и корректировке стратегии решения.
Для оптимизации производительности, OCR-Agent включает в себя механизм динамического управления итерациями. Этот механизм позволяет агенту интеллектуально регулировать количество шагов саморефлексии, основываясь на оценке прогресса в решении задачи. Вместо фиксированного количества итераций, OCR-Agent динамически определяет, когда необходимо прекратить процесс самокоррекции, предотвращая излишние вычислительные затраты и повышая эффективность. Решение о продолжении или завершении итераций принимается на основе анализа промежуточных результатов и оценки уверенности модели в правильности текущего решения, что позволяет избежать ненужных шагов и ускорить процесс достижения оптимального результата.
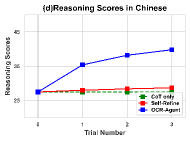
Строгая Оценка на Наборе Данных OCRBench v2
Оценка OCR-Agent проводилась на сложном наборе данных OCRBench v2, включающем более 10 000 пар вопрос-ответ. В ходе оценки производительность модели сравнивалась с производительностью передового открытого исходного кода InternVL3-8B. Использование OCRBench v2 позволило провести всестороннюю оценку возможностей OCR-Agent в решении задач оптического распознавания символов и понимания визуальной информации, а также обеспечить объективное сравнение с существующими решениями с открытым исходным кодом.
В ходе оценки на наборе данных OCRBench v2, OCR-Agent продемонстрировал средний балл 51.01 для английского подмножества и 54.72 для китайского. Эти результаты превосходят показатели всех доступных моделей с открытым исходным кодом. Более того, производительность OCR-Agent приближается к уровню закрытой модели Gemini-Pro, что подтверждает его конкурентоспособность в задачах оптического распознавания символов и обработки изображений с текстом. Данная оценка проводилась на большом наборе данных, содержащем более 10 000 пар вопросов и ответов, что обеспечивает статистическую значимость полученных результатов.
В ходе оценки было показано, что Индикатор Возможности, являющийся компонентом механизма Мульти-Пошагового Отражения Возможностей, значительно повышает способность агента избегать предложения действий, выходящих за рамки его компетенции. Этот компонент позволяет агенту оценивать, способен ли он выполнить запрошенное действие перед его выполнением, что приводит к снижению количества неудачных попыток и повышению общей эффективности системы. В результате внедрения Индикатора Возможности, агент демонстрирует более надежное поведение и более эффективно использует доступные ресурсы, избегая ситуаций, в которых он не может успешно завершить поставленную задачу.
В ходе оценки на датасете OCRBench v2, OCR-Agent продемонстрировал рекордные показатели в задачах визуального понимания и рассуждения. На английском языке агент достиг 79.9 баллов в задаче визуального понимания и 66.5 баллов в задаче визуального рассуждения, что является наивысшим результатом среди открытых моделей. На китайском языке, OCR-Agent установил новые рекорды для открытых моделей, набрав 77.0 баллов в задаче распознавания текста, 68.8 баллов в задаче извлечения информации и 65.1 балл в задаче визуального понимания.
Результаты оценки OCR-Agent на наборе данных OCRBench v2 демонстрируют значительное улучшение точности распознавания китайского текста. Изначальный показатель точности составлял 38.6%, однако после оптимизации и внедрения новых методов, точность была увеличена до 77.0%. Данное увеличение на 16 процентных пунктов свидетельствует о существенном прогрессе в обработке и понимании китайского текста моделью OCR-Agent по сравнению с предыдущими решениями.
Использование метода дистилляции моделей позволило добиться повышения производительности OCR-Agent при одновременном уменьшении размера и повышении эффективности модели. Дистилляция подразумевает передачу знаний от более крупной, сложной модели (в данном случае, вероятно, от закрытой модели Gemini-Pro, с которой сравнивались результаты) к меньшей, более компактной модели. Это достигается за счет обучения меньшей модели имитировать поведение и прогнозы более крупной модели, что позволяет сохранить высокую точность при значительно меньших вычислительных затратах и требованиях к памяти. В результате, OCR-Agent демонстрирует конкурентоспособные результаты, превосходя другие модели с открытым исходным кодом, при более эффективном использовании ресурсов.
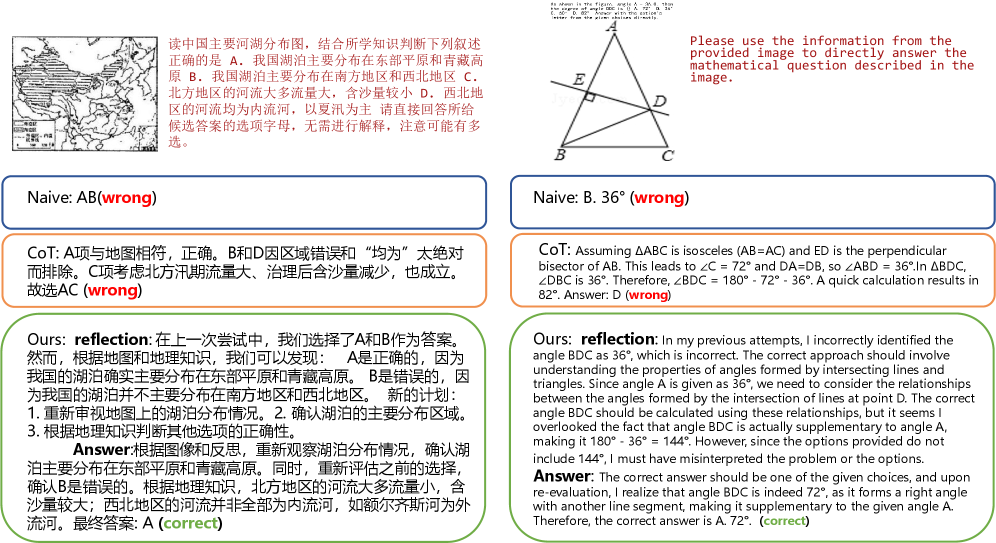
Влияние и Перспективы Дальнейших Исследований
Система OCR-Agent представляет собой важный прогресс в создании более устойчивых и надежных систем оптического распознавания символов. В отличие от традиционных подходов, эта архитектура способна эффективно справляться со сложными и зашумленными изображениями, значительно повышая точность распознавания текста. Саморефлексия, встроенная в систему, позволяет ей оценивать качество собственных результатов и корректировать процесс распознавания, что особенно ценно при обработке документов низкого качества или изображений, полученных в неидеальных условиях. Благодаря такому подходу, OCR-Agent демонстрирует повышенную устойчивость к различным видам помех и искажений, открывая новые возможности для автоматизации задач, связанных с извлечением информации из визуальных данных.
Саморефлексивный подход, реализованный в OCR-Agent, выходит за рамки оптического распознавания символов и обладает потенциалом для значительного улучшения производительности моделей, работающих с задачами, объединяющими зрение и язык. Способность системы оценивать собственную работу и корректировать процесс обработки изображений может быть применена, например, в задачах визуального вопросно-ответного диалога, где точность интерпретации изображения критически важна. Аналогичным образом, в задачах генерации описаний изображений, самооценка позволяет модели формировать более точные и информативные тексты, отражающие суть визуального контента. Использование механизмов саморефлексии открывает новые возможности для создания более надежных и интеллектуальных систем искусственного зрения, способных эффективно взаимодействовать с визуальным миром.
Дальнейшие исследования направлены на усовершенствование механизмов самоанализа, используемых в системе. Планируется разработка методов автоматической адаптации процесса рефлексии к специфике различных задач, что позволит модели более эффективно решать широкий спектр проблем. Особое внимание будет уделено применению обучения с подкреплением для оптимизации поведения агента, позволяя ему самостоятельно находить наиболее эффективные стратегии решения задач и улучшать свои результаты с течением времени. Эти разработки направлены на создание интеллектуальной системы, способной к самосовершенствованию и адаптации, что откроет новые возможности для применения в различных областях, от автоматизированной обработки документов до сложных задач компьютерного зрения.
Перспективы применения OCR-Agent в практических задачах представляются весьма значительными. Система способна существенно упростить и автоматизировать процессы оцифровки документов, включая старые архивы и бумажные носители, значительно сокращая трудозатраты и повышая точность распознавания текста даже при наличии повреждений или шумов. Автоматизация ввода данных, например, при обработке счетов, анкет или других форм, также является ключевым направлением, где OCR-Agent может существенно повысить эффективность и снизить вероятность ошибок. Более того, технология может быть интегрирована в системы интеллектуального поиска по документам, позволяя быстро находить нужную информацию в больших объемах данных, что особенно актуально для организаций, работающих с обширными архивами и документацией.
Представленная работа демонстрирует стремление к математической чистоте в области оптического распознавания символов. Авторы, подобно математикам, доказывающим теорему, предлагают не просто работающее решение, но и систему, способную к самоанализу и итеративному улучшению. Механизмы Capability Reflection и Memory Reflection, предложенные в OCR-Agent, позволяют модели оценивать собственные возможности и корректировать процесс распознавания, что соответствует принципу доказуемости алгоритма. Ян Лекун заметил: «Машинное обучение — это математика, а не магия». Данное исследование подтверждает эту мысль, демонстрируя, что устойчивость и эффективность в сложных задачах визуального понимания достигаются не за счет эвристик, а благодаря строгому применению принципов самокоррекции и рефлексии.
Куда Далее?
Представленная работа, хоть и демонстрирует значительный прогресс в области оптического распознавания символов посредством механизма саморефлексии, оставляет ряд вопросов, требующих строгого математического анализа. Идея «отражения возможностей» и «отражения памяти» представляется элегантной, но её эффективность напрямую зависит от корректности и непротиворечивости используемых критериев оценки. Необходимо формальное доказательство сходимости и оптимальности этих механизмов, а не просто эмпирическое подтверждение на ограниченном наборе данных. Устойчивость системы к «шуму» в исходном изображении, а также к неоднозначности символов, требует отдельного, детального изучения.
В частности, представляется важным исследовать, как предложенный подход масштабируется на задачи, требующие не только распознавания отдельных символов, но и понимания их семантического значения в контексте сложного визуального повествования. Попытки интеграции формальных методов верификации программного обеспечения с архитектурой больших языковых моделей представляются перспективными, но сопряжены с серьезными вычислительными сложностями. Простое увеличение размера модели не является решением; истинный прогресс требует глубины, а не масштаба.
Следующим шагом видится разработка метрик, позволяющих объективно оценивать «качество размышлений» модели. Насколько хорошо модель осознает собственные ошибки и как эффективно она использует полученные знания для улучшения результатов? Эти вопросы требуют не просто инженерных решений, но и философского осмысления самой природы интеллекта, как искусственного, так и естественного.
Оригинал статьи: https://arxiv.org/pdf/2602.21053.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая самовнимательность на службе у поиска оптимальных схем
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
2026-02-26 02:35