Автор: Денис Аветисян
Новая модель объединяет возможности обработки изображений и естественного языка для более точного и эффективного распознавания текста.
Представлен OCRVerse — целостный подход к оптическому распознаванию символов в больших моделях, объединяющий визуальные и текстовые представления для достижения конкурентоспособной производительности с меньшим количеством параметров.
Существующие методы оптического распознавания символов (OCR) часто разделяют обработку текстов и визуально насыщенных изображений, таких как графики и веб-страницы. В данной работе, представленной под названием ‘OCRVerse: Towards Holistic OCR in End-to-End Vision-Language Models’, предложен новый подход OCRVerse, объединяющий распознавание текстов и визуальных элементов в рамках единой сквозной модели. Данный метод, использующий двухэтапную стратегию обучения SFT-RL, демонстрирует сопоставимые, а в некоторых случаях и превосходящие результаты по сравнению с существующими моделями при значительно меньшем количестве параметров. Каковы перспективы применения OCRVerse для автоматизации анализа и извлечения информации из сложных мультимодальных данных?
Преодолевая границы традиционного OCR: Ограничения существующих подходов
Существующие методы оптического распознавания символов (OCR), вне зависимости от того, основаны ли они на последовательной обработке или используют визуальные языковые модели (VLM), часто демонстрируют неудовлетворительные результаты при работе со сложными макетами документов и разнообразным визуальным контентом. Причина кроется в том, что традиционные алгоритмы испытывают трудности при идентификации и корректной интерпретации элементов, расположенных нелинейно, или при наличии изображений, таблиц и других визуальных компонентов, перекрывающих текст. В результате, точность распознавания значительно снижается, особенно в документах, отличающихся от стандартных, хорошо структурированных образцов, что создает серьезные препятствия для автоматизации обработки документов и обеспечения их доступности.
Традиционные методы оптического распознавания символов (OCR) часто полагаются на специализированные модули для обработки различных аспектов документа, таких как обнаружение текста, распознавание символов и анализ макета. Однако такое разделение на модули приводит к вычислительным заторам, поскольку каждый модуль требует значительных ресурсов для своей задачи. Альтернативно, использование больших языковых моделей (LLM) для решения этой задачи также сталкивается с проблемами обобщения. LLM, обученные на ограниченном наборе данных документов, могут испытывать трудности при обработке документов с незнакомыми макетами, шрифтами или визуальным содержанием. Таким образом, зависимость от специализированных модулей или LLM ограничивает эффективность и адаптивность OCR-систем, особенно при работе со сложными и разнообразными документами.
Ограничения существующих методов оптического распознавания символов (OCR) особенно остро проявляются при обработке документов, насыщенных визуальным контентом и сложной компоновкой. Точность извлечения информации существенно снижается в случаях, когда текст перемежается с изображениями, таблицами или нестандартными элементами оформления. Это затрудняет не только автоматизированный анализ таких документов, но и делает их недоступными для людей с ограниченными возможностями, которым требуется программное обеспечение для чтения с экрана. В итоге, существующие недостатки препятствуют полноценной цифровизации и широкому распространению информации, содержащейся в визуально сложных документах, что требует разработки принципиально новых подходов к автоматическому извлечению и интерпретации данных.
OCRVerse: Унифицированный подход к распознаванию текста и изображений
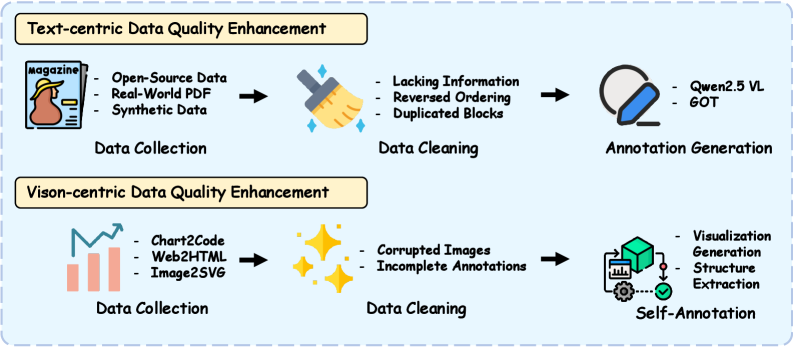
OCRVerse представляет собой новую методологию оптического распознавания символов (OCR), разработанную для объединения текстовых и визуальных возможностей в единую сквозную систему. В отличие от традиционных OCR-методов, которые обычно обрабатывают текст и изображения раздельно, OCRVerse интегрирует оба типа данных на всех этапах обработки. Это достигается за счет использования единой архитектуры, способной одновременно анализировать текстовую и визуальную информацию, что позволяет более эффективно извлекать и интерпретировать данные из документов различной сложности и форматов.
В основе OCRVerse лежит языковая модель Qwen3-VL 4B, обеспечивающая эффективную обработку как текстовой, так и визуальной информации. Qwen3-VL 4B, будучи мультимодальной моделью, позволяет системе понимать взаимосвязь между визуальными элементами документа (например, расположение текста, изображения, таблицы) и их текстовым содержанием. Это достигается за счет совместного кодирования визуальных признаков, извлеченных из изображения документа, и текстовых эмбеддингов, что позволяет модели учитывать контекст и семантику документа в целом. В результате, OCRVerse способна не просто распознавать символы, но и интерпретировать структуру и смысл документа, что повышает точность и надежность процесса оптического распознавания символов.
Унифицированный подход, реализованный в OCRVerse, обеспечивает повышенную точность и устойчивость при обработке документов, особенно сложных, содержащих смешанный контент — текст и изображения. Традиционные методы OCR часто испытывают трудности при распознавании документов, где текст тесно интегрирован с визуальными элементами или имеет нестандартное форматирование. OCRVerse, благодаря одновременной обработке как текстовой, так и визуальной информации, способен более эффективно извлекать и интерпретировать данные, минимизируя ошибки и обеспечивая целостность извлеченных данных даже в сложных сценариях, таких как сканированные документы с таблицами, диаграммами и рукописными вставками.

Совершенствование OCRVerse: Обучение SFT-RL для достижения оптимальной производительности
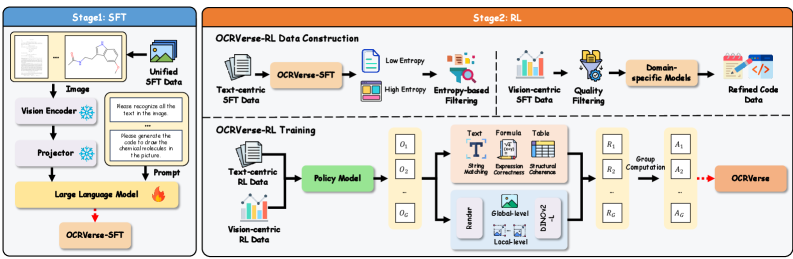
OCRVerse использует двухэтапную методологию обучения SFT-RL, объединяющую контролируемую тонкую настройку (Supervised Fine-Tuning, SFT) с обучением с подкреплением (Reinforcement Learning, RL). На первом этапе, SFT, модель обучается на размеченном наборе данных для освоения базовых навыков распознавания текста и структуры документов. Затем, на этапе RL, модель совершенствуется посредством взаимодействия с виртуальной средой и получения вознаграждения за корректные действия, что позволяет оптимизировать ее производительность и адаптироваться к различным типам документов и задачам. Такой подход позволяет сочетать преимущества обоих методов: SFT обеспечивает быстрое освоение начальных навыков, а RL — дальнейшую оптимизацию и адаптацию к сложным сценариям.
Для оптимизации производительности OCRVerse на различных типах документов и задачах реализованы специализированные механизмы вознаграждения. Эти механизмы определяют, как модель оценивает и корректирует свои действия в процессе обучения с подкреплением. Вознаграждение формируется на основе точности распознавания текста, корректного определения структуры документа (таблицы, списки и т.д.) и успешного извлечения необходимой информации. Настройка весов различных компонентов вознаграждения позволяет адаптировать OCRVerse к специфическим требованиям конкретных типов документов, например, юридических договоров или научных статей, и задач, таких как извлечение данных из счетов-фактур или автоматическое заполнение форм.
Процесс обучения позволяет OCRVerse выявлять тонкие закономерности в структуре документов и повышать его способность к обработке сложных макетов. В частности, модель анализирует взаимосвязи между элементами, такими как заголовки, абзацы, таблицы и изображения, что позволяет ей более точно интерпретировать и восстанавливать содержимое даже в случаях нетипичной или поврежденной разметки. Обучение фокусируется на распознавании неявных правил форматирования и вариаций в структуре документа, что улучшает точность извлечения данных и снижает количество ошибок, возникающих при обработке документов сложного дизайна.
Оценка и валидация: Демонстрация превосходной производительности
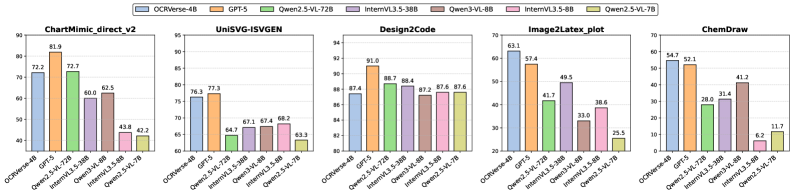
Система OCRVerse подверглась всестороннему тестированию на авторитетных эталонах, таких как OmniDocBench v1.5, ChartMimic и UniSVG, где продемонстрировала передовые результаты. В ходе оценки были использованы различные метрики, позволяющие комплексно оценить точность и качество распознавания, что подтверждает способность системы эффективно обрабатывать разнообразные типы документов и графических данных. Успешное прохождение этих тестов свидетельствует о высокой производительности OCRVerse и ее потенциале для широкого спектра практических применений, от автоматизации обработки документов до создания интеллектуальных систем анализа изображений.
Для подтверждения превосходства OCRVerse в распознавании документов и изображений, была проведена всесторонняя оценка с использованием ряда метрик. Такие показатели, как расстояние редактирования (Edit Distance), показатель ошибок TEDS, метрика согласованности диаграмм CDM, а также структурное подобие изображений SSIM и LPIPS, продемонстрировали высокую точность и качество визуального восприятия результатов, полученных с помощью данной модели. Эти метрики позволяют объективно оценить способность OCRVerse не только правильно распознавать текст и элементы диаграмм, но и сохранять их исходный вид и структуру, что особенно важно для сложных документов и научных изображений. Полученные результаты подтверждают, что OCRVerse обеспечивает значительно более высокое качество распознавания по сравнению с существующими аналогами.
Исследования показали выдающиеся результаты работы OCRVerse на нескольких ключевых бенчмарках. В частности, модель демонстрирует общую оценку в 89.23 балла на OmniDocBench v1.5, значительно превосходя результаты Qwen3-VL-8B (78.3%) и InternVL3-8B (63.3%) при анализе графиков на ChartMimic, где достигнута точность в 84.8%. Кроме того, OCRVerse успешно генерирует LaTeX-код для графиков в 88.7% случаев, обгоняя GPT-5 (78.7%). Особого внимания заслуживает высокая производительность в области химических формул: уровень успешного выполнения задач ChemDraw составляет 89.1%, что превосходит все доступные открытые аналоги. Эти результаты подтверждают, что OCRVerse является передовой моделью в области оптического распознавания и понимания документов.
Особенностью OCRVerse является его выдающаяся эффективность при относительно небольшом размере модели — всего 4 миллиарда параметров. Данный подход позволяет достигать конкурентоспособных, а в ряде случаев и превосходящих результатов по сравнению с гораздо более крупными моделями, достигающими 70 миллиардов параметров. Это означает, что OCRVerse может быть развернут и использован на оборудовании с ограниченными ресурсами, сохраняя при этом высокую точность и качество распознавания и обработки документов, диаграмм и химических формул, что делает его практичным решением для широкого спектра приложений и пользователей. Такая эффективность открывает новые возможности для интеграции OCR-технологий в устройства и системы с ограниченной вычислительной мощностью.
Перспективы развития: Расширение возможностей OCRVerse
Будущие исследования OCRVerse сосредоточены на значительном повышении его способности к обобщению и устойчивости к зашумленным или поврежденным документам. Это достигается путем внедрения новых методов обучения, которые позволяют модели эффективно адаптироваться к разнообразным стилям рукописи, различным типам сканирования и даже к намеренным искажениям, таким как пятна, размытость или частичная потеря информации. Разработчики стремятся создать систему, способную надежно распознавать текст даже в сложных условиях, приближая ее к человеческому уровню восприятия и минимизируя необходимость предварительной обработки документов. Улучшение обобщающей способности OCRVerse позволит расширить спектр обрабатываемых материалов и снизить затраты на адаптацию модели к новым задачам.
Исследования направлены на совершенствование системы вознаграждений и стратегий обучения для OCRVerse, что позволит значительно повысить его эффективность при обработке специализированных документов и выполнении конкретных задач. Разработка новых метрик, учитывающих не только точность распознавания символов, но и семантическую целостность текста, представляется перспективным направлением. Например, введение штрафов за логические ошибки или неверную интерпретацию структуры документа может стимулировать модель к более глубокому пониманию содержимого. Эксперименты с различными алгоритмами обучения с подкреплением и активного обучения, адаптированными к особенностям конкретных типов документов — исторических текстов, юридических соглашений или научных статей — способны привести к существенному улучшению результатов и расширению области применения OCRVerse.
Единый подход, реализованный в OCRVerse, открывает перспективные пути для интеграции оптического распознавания символов с другими возможностями искусственного интеллекта. Вместо традиционного разделения задач, OCRVerse позволяет создавать системы, способные не только извлекать текст из документов, но и анализировать его содержание, отвечать на вопросы, касающиеся этого текста, и даже формировать краткие резюме. Такое объединение позволяет значительно повысить эффективность обработки документов, автоматизируя сложные рабочие процессы и предоставляя пользователям более глубокое понимание содержащейся в них информации. Перспективы включают создание интеллектуальных систем управления документами, способных самостоятельно обрабатывать входящую корреспонденцию, извлекать ключевые данные и принимать решения на основе полученной информации, что значительно расширяет область применения OCR-технологий.
Исследование, представленное в статье, демонстрирует стремление к созданию элегантной и эффективной системы оптического распознавания символов. Авторы предлагают подход, объединяющий сильные стороны как текстоцентричного, так и визуального подходов, что позволяет достичь конкурентоспособных результатов с меньшим количеством параметров. Этот акцент на минимизации избыточности и повышении эффективности резонирует с принципами математической чистоты в коде. Как отмечал Ян Лекун: «Машинное обучение — это математика, а не магия». Данное утверждение подчеркивает необходимость строгого обоснования и доказательства корректности алгоритмов, что полностью соответствует предложенному в статье двухэтапному процессу обучения и стремлению к созданию доказуемо эффективной системы OCR.
Что Дальше?
Представленный подход, хоть и демонстрирует эффективность в унификации тексто- и визуально-ориентированного распознавания, лишь частично решает проблему истинной целостности OCR. Достижение математической чистоты в обработке рукописного текста и сложных макетов документов требует не просто увеличения объема обучающих данных, но и разработки алгоритмов, способных к формальной верификации. Нынешние модели, работающие на эмпирических результатах, подвержены непредсказуемым ошибкам, скрытым в граничных случаях.
Будущие исследования должны быть направлены на создание моделей, оперирующих не с пикселями и глифами, а с кодовыми представлениями, отражающими логическую структуру документа. Уход от чисто визуального восприятия к анализу семантики текста — вот путь к истинному OCR. Важно понимать, что красота алгоритма не зависит от языка реализации, важна только непротиворечивость. Успех не измеряется количеством параметров, а доказательством корректности.
Очевидным направлением является разработка формальных методов верификации OCR-систем, способных гарантировать отсутствие ошибок в определенных классах документов. Лишь тогда можно будет говорить о надежном и предсказуемом распознавании, свободном от случайных артефактов и неточностей. Иначе, все усилия по оптимизации будут лишь маскировать фундаментальные недостатки подхода.
Оригинал статьи: https://arxiv.org/pdf/2601.21639.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Взлом языковых моделей: эволюция атак, а не подсказок
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Кванты в Финансах: Не Шутка!
- Квантовый оптимизатор: Новый подход к сложным задачам
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Искусственный интеллект: новый взгляд на когнитивные механизмы
- Квантовый скачок: Анализ последних новостей
2026-01-31 08:45