Автор: Денис Аветисян
В статье представлена система, позволяющая более точно и объективно оценивать научные публикации с помощью современных языковых моделей.

SciRM и SciRM-Ref — модели вознаграждения, улучшающие оценку научного письма с помощью двухэтапного обучения с подкреплением и повышающие адаптивность к различным критериям оценки.
Оценка научных текстов требует глубоких предметных знаний и учета специфических требований, что представляет собой сложную задачу для современных моделей. В работе ‘Reward Modeling for Scientific Writing Evaluation’ предложен подход, основанный на обучении моделей вознаграждения (reward modeling) для улучшения автоматической оценки научных работ. Разработанные модели SciRM и SciRM-Ref повышают способность больших языковых моделей (LLM) к рассуждениям и адаптации к различным критериям оценки посредством двухэтапного обучения с подкреплением. Способны ли эти модели стать универсальным инструментом для оценки научных текстов без дорогостоящей перенастройки для каждой конкретной задачи?
Постановка проблемы: Оценка научной литературы в эпоху перегрузки
Традиционные методы оценки научной литературы, включая рецензирование, зачастую страдают от субъективности оценок, что затрудняет получение объективных выводов о качестве работы. Процесс рецензирования, хоть и является краеугольным камнем научной практики, требует значительных временных затрат от экспертов, что ограничивает количество оцениваемых работ и замедляет процесс публикации. Кроме того, оценки могут варьироваться в зависимости от личных предпочтений рецензента, его опыта и даже текущего настроения, что вносит элемент непредсказуемости и может приводить к несправедливой оценке. Масштабирование этого процесса представляется сложной задачей, поскольку для поддержания качества необходимо привлечение большого числа компетентных экспертов, что является дорогостоящим и трудоемким.
Современные большие языковые модели (LLM), используемые для оценки научных текстов, демонстрируют существенные ограничения в способности к сложному рассуждению и недостаток специализированных знаний в конкретных областях науки. В результате, автоматизированные оценки, предоставляемые этими моделями, часто оказываются ненадежными и не отражают истинное качество научной работы. LLM могут испытывать трудности с выявлением тонких логических ошибок, оценкой новизны исследования или проверкой соответствия методологии заявленным целям. Это приводит к тому, что перспективные, но неформально изложенные работы могут быть недооценены, а работы с поверхностными, но хорошо структурированными аргументами — переоценены, что в конечном итоге тормозит развитие науки и способствует распространению некачественных исследований.
Отсутствие надежных методов оценки научной литературы представляет собой серьезное препятствие для прогресса в науке. Недостаточная проверка и выявление методологических ошибок в исследованиях может привести к распространению недостоверных данных и, как следствие, к принятию ошибочных решений в различных областях — от медицины до инженерии. Задержка в выявлении и признании действительно новаторских открытий, обусловленная субъективностью или неэффективностью оценки, замедляет темпы развития науки и препятствует внедрению инноваций. Таким образом, совершенствование систем оценки научной литературы является критически важной задачей, способной значительно ускорить процесс научного познания и обеспечить более эффективное использование ресурсов, направленных на исследования.
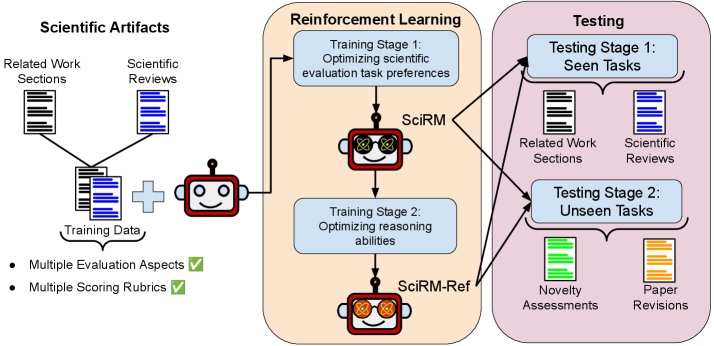
SciRM: Моделирование вознаграждения для оценки научной работы
SciRM представляет собой методологию моделирования вознаграждения, предназначенную для оценки качества научной литературы на основе заданных критериев и желаемых характеристик. В основе SciRM лежит обучение модели для предоставления оценок, соответствующих заранее определенным параметрам, таким как научная новизна, методологическая строгость, ясность изложения и значимость результатов. Модель обучается на корпусе текстов и соответствующих оценок, позволяя ей выявлять и ранжировать научные работы в соответствии с заданными стандартами. SciRM не предполагает субъективной оценки, а основывается на формализованных критериях, что обеспечивает воспроизводимость и объективность оценки научной литературы.
SciRM проходит обучение в два этапа, что позволяет добиться как обучения на основе предпочтений, так и развития способности к надежному логическому мышлению. На первом этапе модель обучается на парах текстов, ранжированных по качеству, что позволяет ей выявлять предпочтительные характеристики научного письма. Второй этап фокусируется на улучшении способности модели к рассуждениям и анализу, используя алгоритмы, которые позволяют ей оценивать текст на соответствие заданным критериям и выявлять логические несостыковки или недостатки в аргументации. Такой двухэтапный подход обеспечивает более комплексную и точную оценку научных текстов, чем одноэтапные методы обучения.
Для уточнения сигналов вознаграждения и повышения способности к осмысленной оценке, SciRM использует алгоритмы, такие как GRPO (Gaussian Rank-Based Policy Optimization). GRPO позволяет модели более эффективно ранжировать научные тексты на основе заданных критериев, учитывая не только общую оценку, но и нюансы качества, отраженные в тексте. Алгоритм основан на ранжировании предпочтений, что позволяет SciRM выявлять и поощрять тексты, демонстрирующие наиболее желаемые характеристики в соответствии с заданной Scoring Rubric и Evaluation Criteria. Использование GRPO способствует повышению стабильности и надежности процесса обучения модели и, как следствие, улучшению качества предоставляемых оценок.
SciRM спроектирован с учетом возможности адаптации к различным требованиям оценки научной литературы. В его основе лежит принцип использования специфических `Критериев Оценки` и `Шкал Оценивания`, разработанных для конкретной научной области. Это позволяет модели учитывать нюансы, характерные для разных дисциплин, и обеспечивать более точную и релевантную оценку научных текстов. Настраиваемые параметры позволяют задавать приоритеты для различных аспектов научной работы, таких как новизна, методология, ясность изложения и значимость результатов, что делает SciRM универсальным инструментом для оценки качества научных исследований.
Улучшение SciRM с помощью LoRA и SciRM-Ref: Доведение до ума
Для оптимизации SciRM используется метод LoRA (Low-Rank Adaptation), представляющий собой эффективный способ тонкой настройки модели с уменьшением вычислительных затрат и повышением производительности. LoRA позволяет адаптировать предварительно обученную модель к специфическим задачам научной обработки текста, изменяя лишь небольшое количество параметров. Вместо обновления всех весов модели, LoRA вводит низкоранговые матрицы, которые обучаются параллельно с исходными весами, значительно снижая требования к памяти и вычислительным ресурсам. Это особенно важно при работе с большими языковыми моделями и ограниченными ресурсами, позволяя достичь сопоставимых результатов с полной тонкой настройкой, но с меньшими затратами.
Для дальнейшей оптимизации параметров LoRA в процессе тонкой настройки SciRM используется фреймворк Unsloth. Unsloth автоматизирует процесс поиска оптимальных гиперпараметров LoRA, таких как ранг адаптации и скорость обучения, что позволяет значительно сократить время и вычислительные затраты на тонкую настройку. Данный фреймворк использует методы автоматизированного машинного обучения (AutoML) для эффективного исследования пространства параметров LoRA, обеспечивая повышение производительности модели при минимальных затратах ресурсов. Внедрение Unsloth позволяет упростить и ускорить процесс адаптации SciRM к конкретным задачам, делая его более доступным и эффективным.
SciRM-Ref представляет собой усовершенствованную версию SciRM, разработанную для повышения возможностей логического мышления и самопроверки. Ключевым отличием является внедрение второго этапа обучения, дополняющего первичную настройку модели. Этот дополнительный этап позволяет SciRM-Ref более эффективно усваивать сложные зависимости в научных текстах и, как следствие, точнее оценивать достоверность собственных выводов и ответов. В результате, SciRM-Ref демонстрирует значительное улучшение в задачах, требующих анализа, синтеза и критической оценки научной информации.
SciRM-Ref использует механизм `Task Query` — структурированный запрос, предоставляющий модели четкие инструкции и контекст для обработки научных текстов. Этот запрос определяет конкретную задачу, например, извлечение ключевых аргументов, выявление противоречий или обобщение информации. За счет фокусировки на релевантных аспектах научного текста посредством `Task Query`, SciRM-Ref повышает точность и эффективность выполнения задач, связанных с анализом и синтезом научной информации, минимизируя влияние посторонних факторов и повышая концентрацию на поставленной задаче.
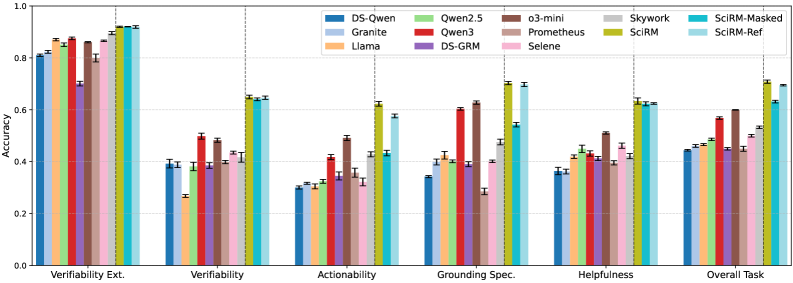
Оценка рецензий и сопутствующих работ: Где модель проявляет себя
Модели SciRM и SciRM-Ref демонстрируют высокую эффективность в оценке полезности научных обзоров, определяя их качество и информативность. Данные модели способны анализировать представленные аргументы, выявлять ключевые моменты и оценивать, насколько полно и понятно изложен материал. Оценка производится на основе нескольких критериев, включая соответствие обзора заявленной теме, ясность изложения и общую ценность для научного сообщества. Высокая точность SciRM и SciRM-Ref в данной области позволяет автоматизировать процесс оценки обзоров, значительно упрощая работу рецензентов и повышая качество научных публикаций.
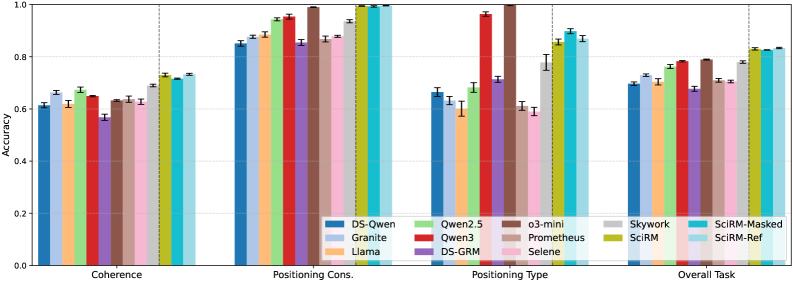
Модели SciRM и SciRM-Ref демонстрируют высокую точность в оценке связанных работ, что выходит за рамки простого подсчета цитирований. Они способны анализировать, насколько логично и последовательно представлен материал, оценивая взаимосвязь между различными исследованиями и обоснованность включения тех или иных источников. Особенно выделяется способность моделей к определению корректности позиционирования цитируемой литературы — то есть, насколько точно и уместно каждое исследование представлено в контексте общей аргументации. Такой подход позволяет не только выявить недостатки в структуре обзора литературы, но и оценить, насколько полно и адекватно автор освещает существующие научные знания по теме.
Оценка научных работ и обзоров опирается на ключевые показатели, среди которых выделяются верифицируемость и когерентность. Верифицируемость подразумевает, что каждое утверждение, представленное в исследовании, должно быть подкреплено соответствующими доказательствами и ссылками на источники. Когерентность, в свою очередь, оценивает логическую связность и последовательность аргументов, представленных в тексте. Высокая когерентность обеспечивает плавный переход от одной мысли к другой, облегчая понимание и восприятие информации. Оба этих показателя — верифицируемость и когерентность — являются фундаментальными для оценки качества научных материалов и определения их ценности для научного сообщества.
Исследование продемонстрировало выдающиеся результаты моделей SciRM и SciRM-Ref в оценке научной литературы. SciRM достигла почти абсолютной точности в определении согласованности позиционирования цитируемых работ — способности корректно отражать взаимосвязь между источниками и аргументацией, — и превысила 90% точности в нескольких аспектах оценки полезности рецензий. Постоянно превосходя базовые показатели, SciRM-Ref, в свою очередь, показала наивысший средний балл по всем четырем задачам оценки, что свидетельствует о ее превосходстве в комплексном анализе научной литературы и рецензировании.
Будущее: К автоматизированному научному дискурсу
Интеграция SciRM и SciRM-Ref с такими платформами, как vLLM, открывает возможности для автоматизированной генерации альтернативных ответов в процессе оценки научных текстов. Данный подход позволяет выйти за рамки простого выставления баллов, предоставляя более глубокий и детальный анализ. Система способна самостоятельно предлагать варианты интерпретации или развития идей, что значительно расширяет спектр оцениваемых критериев и позволяет выявлять нюансы, которые могли бы остаться незамеченными при традиционной экспертизе. Автоматическая генерация кандидатов на ответ позволяет не только проверить соответствие текста заданным требованиям, но и оценить его оригинальность и потенциал для дальнейших исследований, приближая научную оценку к уровню экспертного обсуждения.
Вместо простого присвоения баллов научной работе, новая методология позволяет проводить более глубокий и многогранный анализ текста. Она учитывает не только формальные аспекты, но и такие качества, как новизна, логическая последовательность аргументации и соответствие общепринятым научным стандартам. Это достигается за счет интеграции SciRM и SciRM-Ref с передовыми языковыми моделями, что позволяет оценивать не просто наличие определенных ключевых слов или фраз, а истинную научную ценность представленных идей и результатов. Такой подход открывает возможности для выявления слабых мест в исследовании, предоставления более детальной обратной связи авторам и, в конечном итоге, повышения качества научных публикаций.
Дальнейшие исследования направлены на расширение спектра критериев оценки научных текстов и адаптацию моделей к специфике различных научных дисциплин. В настоящее время ведется работа над включением в анализ таких аспектов, как методологическая строгость, воспроизводимость результатов и значимость полученных данных. Особое внимание уделяется настройке моделей для эффективной работы с текстами, характерными для биологии, химии, физики и других областей знания, учитывая их уникальный жаргон и требования к оформлению. Предполагается, что подобная адаптация позволит значительно повысить точность и релевантность автоматизированной оценки, сделав ее незаменимым инструментом для поддержки рецензирования и контроля качества научных публикаций.
Разработка модели SciRM-Ref продемонстрировала впечатляющие результаты в оценке новизны научных текстов, достигнув производительности, сопоставимой с закрытой моделью o3-mini. Этот прорыв представляет собой значительный шаг вперед в автоматизации оценки научной литературы, поскольку ранее оценка новизны требовала экспертного анализа. Способность модели к точному определению оригинальности исследований открывает перспективы для более эффективного рецензирования, выявления плагиата и поддержки исследователей в создании действительно инновационных работ. Достигнутый уровень производительности указывает на потенциал SciRM-Ref в качестве надежного инструмента для повышения качества и достоверности научных публикаций, автоматизируя трудоемкий и субъективный процесс оценки.
В перспективе, разработанные технологии автоматизированной оценки научных текстов способны кардинально изменить процесс рецензирования. Ожидается значительное повышение эффективности благодаря возможности быстрой обработки больших объемов материалов и выявления ключевых аспектов, требующих внимания. Прозрачность рецензирования усилится за счет четкой фиксации критериев оценки и обоснования вынесенных заключений, что снизит субъективность. Повышение надежности анализа станет возможным благодаря использованию стандартизированных метрик и алгоритмов, минимизирующих влияние человеческого фактора и обеспечивающих последовательность оценки различных работ. Данный подход открывает путь к более объективной, быстрой и масштабируемой системе контроля качества научных исследований, способствуя развитию науки в целом.
Статья, посвящённая SciRM и SciRM-Ref, демонстрирует очередную попытку обуздать непредсказуемость больших языковых моделей. Авторы стремятся улучшить оценку научной литературы, используя двухэтапное обучение с подкреплением — подход, который, несомненно, усложнит инфраструктуру, но, возможно, и повысит качество. Как говорил Линус Торвальдс: «Плохой код похож на раковую опухоль: его можно удалить, но он всегда возвращается». И здесь, как и во многих других проектах, необходимо помнить, что каждое «революционное» решение завтра станет техническим долгом, требующим постоянного обслуживания. Идея адаптации к различным критериям оценки — шаг в правильном направлении, хотя и иллюзорном, ведь всегда найдётся новый, ещё более строгий стандарт.
Что дальше?
Представленные модели SciRM и SciRM-Ref, несомненно, добавляют ещё один уровень абстракции между машиной и субъективностью оценки научного текста. Однако, как показывает опыт, каждая «оптимизация» неизбежно порождает новые, более изощренные способы обхода системы. Улучшение способности больших языковых моделей к «рассуждению» — это, по сути, поиск более эффективных костылей для имитации интеллекта. Не стоит забывать, что критерии «хорошего» научного письма сами по себе подвержены изменениям, а попытка их формализации чревата упрощением и потерей нюансов.
В перспективе, вероятно, стоит пересмотреть саму постановку задачи. Вместо бесконечной гонки за более «умными» моделями оценки, возможно, стоит сосредоточиться на разработке инструментов, позволяющих человеку быстрее и эффективнее выявлять недостатки в тексте. Ведь в конечном счёте, научная статья оценивается не алгоритмом, а человеком, склонным к предвзятости и ошибкам. И не нужно больше микросервисов — нам нужно меньше иллюзий.
Вполне вероятно, что в ближайшем будущем мы увидим появление ещё более сложных систем reward modeling, способных учитывать контекст, авторство и даже предполагаемую аудиторию. Но, как показывает история, каждая революционная технология завтра станет техдолгом. Продакшен всегда найдёт способ сломать элегантную теорию.
Оригинал статьи: https://arxiv.org/pdf/2601.11374.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2026-01-19 22:30