Автор: Денис Аветисян
Новое исследование показывает, что для существенного улучшения способности больших языковых моделей к логическому мышлению достаточно всего одного, тщательно подобранного или сгенерированного примера.
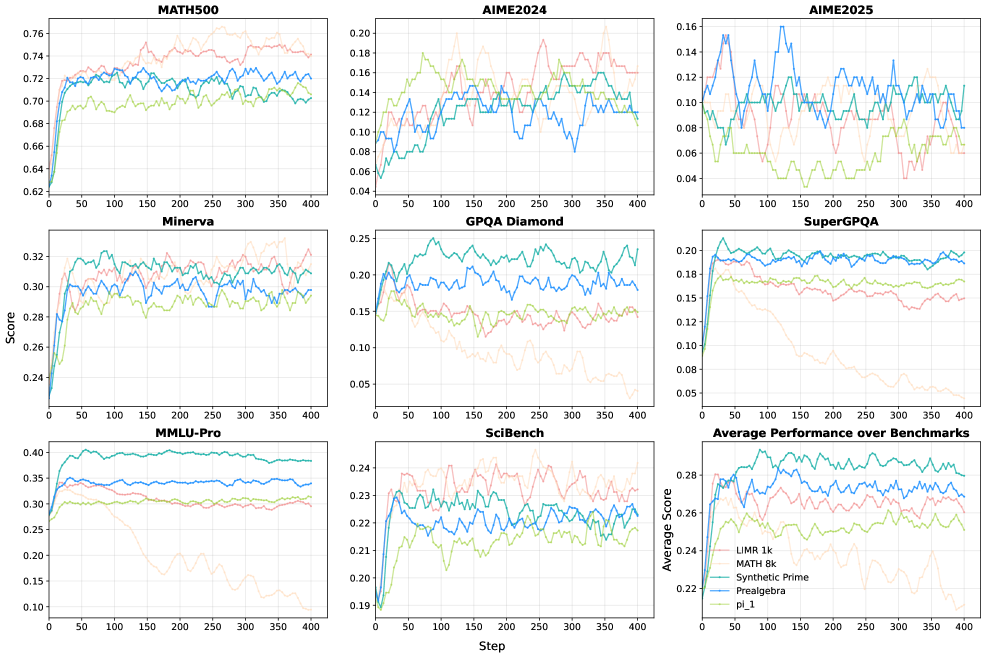
Работа демонстрирует, что акцент смещается от простого увеличения объема данных к ‘инженерии примеров’ для достижения высокой эффективности в обучении с подкреплением.
Несмотря на успехи обучения больших языковых моделей с подкреплением, обычно требуется огромное количество данных для достижения значительных улучшений в рассуждениях. В работе «One Sample to Rule Them All: Extreme Data Efficiency in RL Scaling» авторы демонстрируют, что одного тщательно подобранного или синтезированного примера математического рассуждения достаточно для существенного повышения способностей модели к решению задач в различных областях, включая физику, химию и биологию. Этот результат указывает на то, что качество и дизайн обучающих примеров, а не их количество, могут быть ключевыми для раскрытия потенциала языковых моделей. Не означает ли это, что будущее обучения больших моделей связано с переходом от простого увеличения объемов данных к точному конструированию обучающих выборок?
Пределы Масштабирования: Рассуждения в Больших Языковых Моделях
Несмотря на впечатляющие возможности, большие языковые модели (БЯМ) зачастую испытывают трудности при решении сложных задач, требующих логического мышления. Особенно заметны ограничения в многоступенчатом решении проблем, где требуется последовательное применение нескольких шагов для достижения результата. БЯМ могут успешно справляться с отдельными элементами задачи, однако возникают сложности с удержанием всей логической цепочки и интеграцией промежуточных выводов для получения окончательного ответа. Это проявляется в неспособности эффективно решать задачи, требующие планирования, дедукции или абстрактного мышления, демонстрируя, что простое увеличение объема данных для обучения не всегда приводит к улучшению способностей к сложному рассуждению.
По мере увеличения размеров языковых моделей наблюдается закономерное снижение эффективности традиционных методов масштабирования. Простое наращивание параметров и объемов данных перестает приносить соразмерный прирост в способности к сложному рассуждению. Исследования показывают, что дальнейшее увеличение масштаба дает все меньше преимуществ, что требует разработки инновационных подходов. Акцент смещается с количественного наращивания к качественным улучшениям в архитектуре моделей и стратегиях обучения, направленным на углубление понимания и повышение эффективности решения задач, требующих логических выводов и многоступенчатого анализа.
Современные эталонные тесты, такие как MMLU-Pro и SuperGPQA, демонстрируют существенные пробелы в способностях больших языковых моделей к логическому мышлению. Анализ результатов показывает, что целенаправленные улучшения в алгоритмах рассуждений позволяют достичь прироста в эффективности до 14.5% по сравнению с подходами, основанными на всестороннем обучении. Этот факт подчеркивает необходимость смещения фокуса с простого увеличения масштаба моделей в сторону разработки и внедрения специализированных методов, направленных на углубление и повышение точности логических операций, выполняемых искусственным интеллектом.
Полиматное Обучение: Новый Подход к Эффективным Рассуждениям
Метод Polymath Learning представляет собой новый подход к обучению больших языковых моделей (LLM) с использованием обучения с подкреплением (RL). В отличие от традиционных методов, требующих обширных наборов данных, Polymath Learning фокусируется на целевом обучении, используя тщательно отобранные примеры. Такой подход позволяет значительно повысить способность LLM к логическому мышлению и решению задач, оптимизируя процесс обучения и снижая потребность в больших вычислительных ресурсах и объеме данных. Основная цель — улучшение способности модели к рассуждениям за счет целенаправленного воздействия на конкретные когнитивные навыки.
Метод Polymath Learning использует принципы обучения в один пример (One-Shot Learning), что позволяет добиться высокой производительности модели при минимальном объеме обучающих данных. В отличие от традиционных подходов, требующих больших датасетов для эффективной тренировки, данная методика оптимизирует процесс обучения, используя лишь небольшое количество тщательно подобранных примеров. Это значительно повышает эффективность обучения и снижает вычислительные затраты, позволяя модели быстро адаптироваться и демонстрировать улучшенные результаты в задачах, требующих логического мышления и рассуждений, при ограниченных ресурсах.
Метод Polymath Learning использует как данные из естественных источников (Natural Sample), представляющие собой реальные примеры, так и синтетические данные (Synthetic Sample), сгенерированные для целенаправленной тренировки. Комбинация этих двух типов данных позволяет объединить преимущества обучения на основе реального мира с возможностью контролируемого экспериментирования и точной настройки модели. Использование синтетических данных позволяет создавать примеры, специфически направленные на улучшение определенных аспектов логического мышления, что невозможно в полной мере реализовать при использовании исключительно данных из естественных источников. Такой подход обеспечивает более эффективное и целенаправленное обучение, позволяя достичь высокого уровня производительности с использованием относительно небольшого объема данных.
Инженерия примеров играет ключевую роль в методологии Polymath Learning, обеспечивая целенаправленное улучшение способности LLM к рассуждениям. В отличие от традиционных подходов, использующих обширные датасеты, Polymath Learning фокусируется на создании небольшого, но тщательно отобранного набора обучающих примеров. Этот подход позволяет достигать сопоставимой или превосходящей производительности по сравнению с обучением на датасетах, содержащих тысячи примеров, благодаря целенаправленному воздействию на конкретные аспекты логического мышления и решения задач. Тщательная проработка каждого примера позволяет максимизировать эффективность обучения и снизить требования к вычислительным ресурсам.
Оптимизация Выбора Примеров с LIMR и Согласованием Вознаграждений
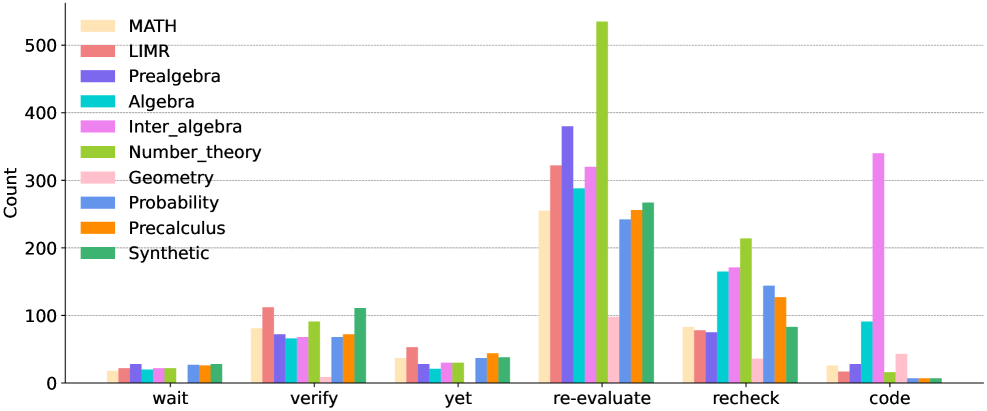
Метод LIMR (Learning-based Intelligent Sample Mining and Rewarding) используется для интеллектуального отбора примеров из набора данных MATH, с приоритетом на те, которые максимизируют соответствие награде во время обучения с подкреплением (RL). Этот процесс включает в себя оценку каждого примера из MATH на предмет его потенциала для усиления сигнала награды, выдаваемого алгоритмом GRPO. Выбранные примеры затем используются для обучения RL-агента, что позволяет оптимизировать процесс обучения и сосредоточиться на задачах, которые наиболее эффективно улучшают способность модели к рассуждениям. В результате, LIMR позволяет значительно повысить эффективность обучения, требуя меньше данных для достижения заданного уровня производительности.
Процесс отбора данных в Polymath Learning нацелен на выявление и использование примеров, усиливающих ключевые математические навыки (Salient Math Skills). Это достигается путем приоритезации задач, требующих демонстрации и применения фундаментальных принципов математического мышления, таких как алгебраические преобразования, логические рассуждения и решение уравнений. Укрепление этих базовых навыков позволяет повысить способность языковой модели (LLM) к обобщению и решению более сложных задач, требующих глубокого понимания математических концепций и умения применять их в новых контекстах. Использование подобного подхода обеспечивает улучшение производительности модели в задачах, требующих не просто запоминания фактов, а активного применения математических знаний.
В алгоритме GRPO функция вознаграждения играет ключевую роль в обучении агента с подкреплением, предоставляя количественную оценку качества выполненных действий. Эта функция, являясь основой процесса обучения, определяет, насколько действия агента приближают его к желаемому результату — решению математической задачи. Вознаграждение, рассчитываемое на основе корректности и эффективности решения, служит сигналом обратной связи, направляющим агента в процессе оптимизации стратегии. Конкретные значения вознаграждения формируют градиент, используемый для обновления параметров агента, что позволяет ему постепенно улучшать свою способность к рассуждениям и решению сложных задач. От точности и релевантности функции вознаграждения напрямую зависит скорость и эффективность обучения агента, а также конечная производительность системы.
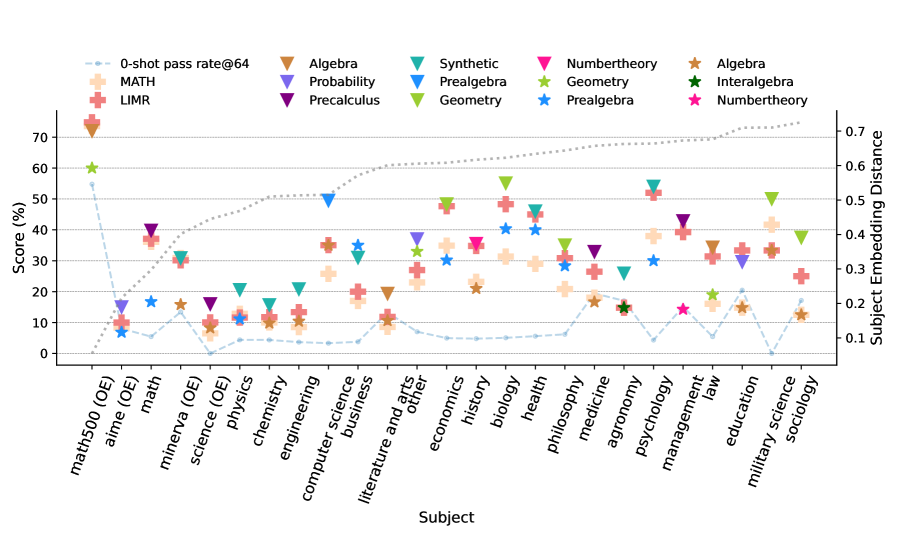
В процессе обучения Polymath Learning наблюдается значительное улучшение результатов на бенчмарках SuperGPQA и MMLU-Pro благодаря согласованию функции вознаграждения с целевыми результатами рассуждений. Данный подход демонстрирует превосходство над подходами, не требующими предварительного обучения (0-shot learning), а также над комплексными методами обучения, использующими тысячи примеров. Экспериментальные данные подтверждают, что оптимизация вознаграждения позволяет модели эффективно усваивать и применять математические навыки, что приводит к более высоким показателям точности и эффективности в задачах, требующих логического мышления и решения проблем.
Демонстрация Кросс-Доменной Обобщаемости и Надежности
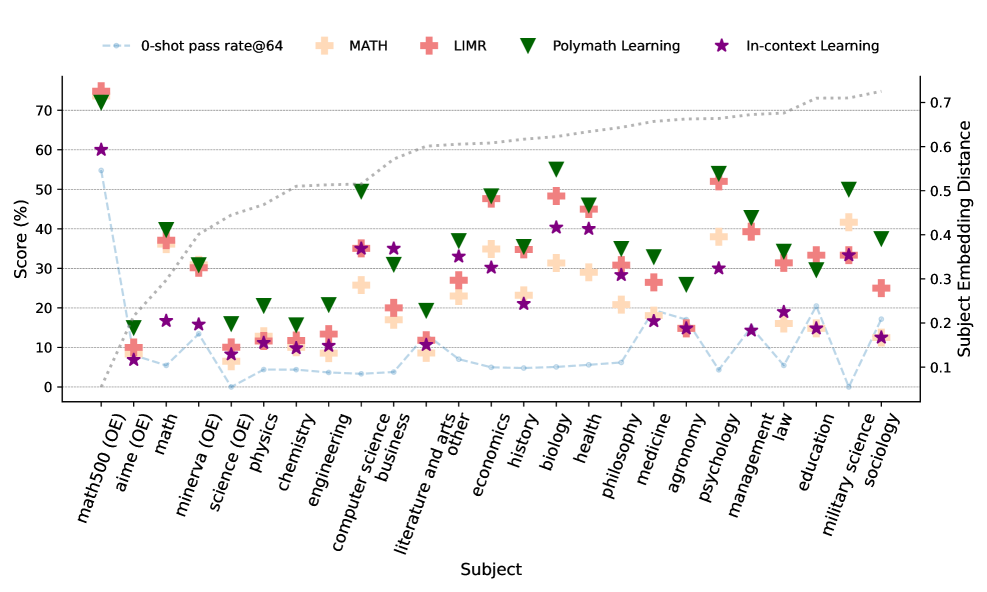
Эксперименты показали, что языковые модели, обученные с использованием подхода Polymath Learning, демонстрируют значительное улучшение в способности к обобщению знаний между различными областями. Модели успешно применяют навыки рассуждения к разнообразным задачам, показывая до 14.5%-ный прирост эффективности на бенчмарках, далеких от математических дисциплин. Этот результат свидетельствует о том, что Polymath Learning способствует формированию более гибкого и универсального интеллекта у моделей, позволяя им успешно справляться с проблемами, выходящими за рамки изначальной области обучения, и эффективно адаптироваться к новым условиям.
Интеграция механизма верификации, и в особенности, способности к самопроверке, значительно повышает надежность и устойчивость решений, генерируемых языковыми моделями. В процессе обучения модель не просто выдает ответ, но и оценивает его правдоподобность и логическую состоятельность, выявляя потенциальные ошибки и противоречия. Этот процесс самооценки позволяет ей корректировать свои выводы и предоставлять более точные и обоснованные результаты, даже в условиях неполной или противоречивой информации. Такой подход существенно снижает вероятность получения неверных или вводящих в заблуждение ответов, делая модель более предсказуемой и заслуживающей доверия в различных областях применения, где точность и надежность критически важны.
В ходе исследований, модель Qwen2.5-7b-base была использована в качестве базового примера для демонстрации эффективности предложенного подхода к улучшению способности к логическому мышлению у существующих больших языковых моделей. Эксперименты показали, что применение разработанных методов позволяет значительно повысить качество рассуждений, не требуя при этом переобучения модели с нуля. Этот результат подчеркивает потенциал подхода к адаптации и совершенствованию уже существующих LLM, делая их более универсальными и надежными в решении широкого спектра задач, требующих сложных логических выводов и анализа информации.
Исследования показали, что образец Synthetic Prime демонстрирует более сложные комбинации навыков по сравнению с образцом π1, что свидетельствует о более глубокой интеграции знаний. В отличие от π1, который фокусируется на относительно изолированных навыках решения задач, Synthetic Prime объединяет различные когнитивные способности, позволяя модели более эффективно применять знания в новых и сложных ситуациях. Этот подход к обучению способствует формированию не просто набора отдельных умений, а целостной системы знаний, что существенно повышает гибкость и адаптивность языковой модели к разнообразным задачам и доменам. Такая интеграция позволяет Synthetic Prime не только решать известные задачи, но и успешно адаптироваться к незнакомым проблемам, требующим комплексного подхода и творческого мышления.
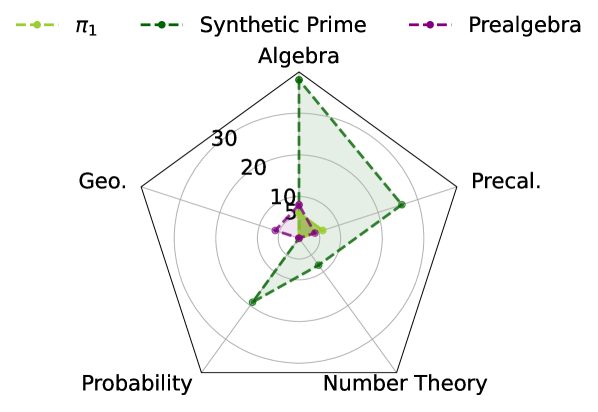
Исследование демонстрирует, что акцент смещается от простого увеличения объёма данных к тщательному проектированию выборочных данных. Это напоминает о словах Анри Пуанкаре: «Математика не открывает истину, а лишь предлагает способ убедиться в ней». В данном случае, единичный, но верно подобранный пример, служит не просто точкой данных, а ключом к раскрытию скрытых возможностей модели. Система, обученная на подобранном образце, демонстрирует способность к обобщению, что подтверждает идею о том, что эффективность обучения зависит не от количества, а от качества и репрезентативности данных. Эта работа, по сути, предлагает новый взгляд на взаимодействие между данными и разумом, где выбор образца является актом созидания, а не просто сбором информации.
Что дальше?
Представленная работа, как и любая попытка обуздать сложность, лишь аккуратно отодвинула завесу от истинной проблемы. Утверждение о возможности значительного улучшения способностей больших языковых моделей, используя единичный, тщательно отобранный пример, не говорит о решении, а скорее о переходе. Вместо бесконечного наращивания объемов данных, внимание смещается к «инженерии примеров» — к искусству выявления или создания тех самых «семян», из которых вырастает разумность. Но и здесь таится ловушка: каждый выбранный пример — это обещание, данное прошлому, и гарантия его адекватности в будущем весьма иллюзорна.
Очевидно, что истинная сила кроется не в самом примере, а в механизмах его отбора и адаптации. Системы не строятся, а вырастают, и каждый архитектурный выбор — это пророчество о будущей поломке. Вопрос не в том, как заставить модель выдать правильный ответ на конкретный пример, а в том, как создать систему, способную самостоятельно находить и интегрировать новые знания, постоянно адаптируясь к меняющимся условиям. Контроль — это иллюзия, требующая соглашения об уровне обслуживания, и все наши усилия по «управлению» интеллектом обречены на провал, если мы не признаем эту фундаментальную истину.
В конечном счете, всё, что построено, когда-нибудь начнёт само себя чинить. Задача исследователей — не в создании идеальной системы, а в создании системы, способной к самовосстановлению и эволюции. И, возможно, именно в этом поиске кроется ключ к подлинному искусственному интеллекту.
Оригинал статьи: https://arxiv.org/pdf/2601.03111.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2026-01-11 07:15