Автор: Денис Аветисян
Исследователи представили TwinFlow — метод, позволяющий создавать высококачественные изображения всего за один или два шага, значительно ускоряя процесс генерации.
TwinFlow использует концепцию ‘двойной траектории’ для обучения крупномасштабных генеративных моделей, объединяя преимущества моделей диффузии, потокового сопоставления и consistency models.
Несмотря на впечатляющие успехи современных генеративных моделей, особенно в области создания изображений и видео, их эффективность часто ограничивается необходимостью многоступенчатой процедуры вывода. В данной работе, ‘TwinFlow: Realizing One-step Generation on Large Models with Self-adversarial Flows’, предложен новый фреймворк, позволяющий обучать генеративные модели, способные создавать высококачественные изображения всего за один шаг. Ключевым элементом подхода TwinFlow является концепция “двойной траектории”, обходящая необходимость в фиксированных предобученных учителях и стандартных состязательных сетях. Сможет ли TwinFlow стать основой для создания действительно эффективных и масштабируемых генеративных моделей нового поколения?
Преодолевая Ограничения Многошагового Генеративного Моделирования
Современные генеративные модели, такие как диффузионные модели и Flow Matching, часто требуют значительного количества шагов для синтеза изображений высокого качества. Этот многоступенчатый процесс является вычислительно затратным, что существенно ограничивает их применение в задачах, требующих мгновенного отклика, например, в интерактивных приложениях или системах реального времени. Несмотря на впечатляющие результаты в генерации детализированных изображений, необходимость выполнения сотен или даже тысяч шагов для каждого сгенерированного изображения становится узким местом, препятствующим широкому распространению этих технологий. Таким образом, возникает потребность в разработке новых подходов, способных обеспечить сравнимое качество при значительно меньшем количестве шагов, что откроет возможности для более эффективных и быстрых генеративных систем.
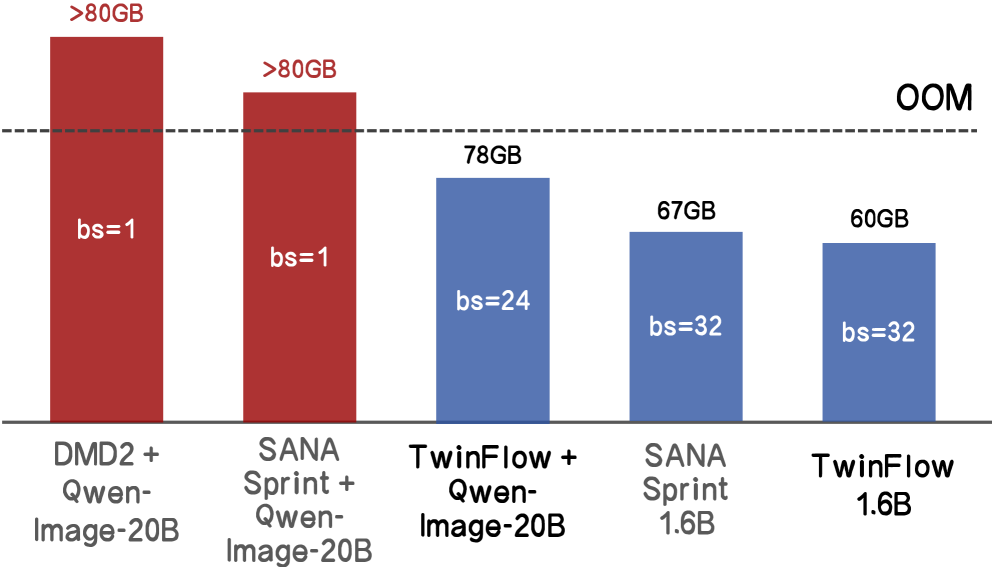
Многоступенчатые подходы к генеративному моделированию, такие как диффузионные модели и методы сопоставления потоков, требуют значительных вычислительных ресурсов. Каждая итерация, необходимая для получения изображения высокого качества, вносит вклад в общую стоимость вычислений, что ограничивает возможность быстрого и эффективного создания контента. Потребность в больших объемах памяти и вычислительной мощности делает эти модели менее доступными для устройств с ограниченными ресурсами и препятствует их применению в приложениях реального времени, например, в интерактивных системах или мобильных устройствах. Таким образом, вычислительная сложность становится критическим фактором, сдерживающим широкое распространение передовых генеративных моделей и стимулирующим поиск более экономичных альтернатив.
Становится все более очевидной необходимость кардинального пересмотра подходов к генеративному моделированию. Современные методы, такие как диффузионные модели и Flow Matching, демонстрируют впечатляющие результаты в синтезе изображений, однако требуют значительного количества шагов для достижения высокого качества. Эта многоступенчатость приводит к высоким вычислительным затратам и ограничивает возможности применения в задачах, требующих генерации в реальном времени. В связи с этим, поиск новых парадигм, позволяющих существенно сократить число шагов без потери качества генерируемых данных, является ключевой задачей для развития области. Такой прорыв позволит не только ускорить процесс генерации, но и снизить энергопотребление, открывая новые перспективы для широкого спектра приложений — от интерактивного дизайна до мгновенного создания контента.

Any-Step Framework и RCGM: Унификация Генеративных Моделей
Фреймворк Any-Step представляет собой унифицирующий принцип для генеративных моделей, позволяющий реализовать как многошаговую, так и малошаговую генерацию в рамках единой архитектуры. В традиционных подходах, модели часто разрабатывались для конкретного числа шагов генерации, что ограничивало их адаптивность. Any-Step позволяет модели динамически определять количество необходимых шагов для создания выходных данных, основываясь на входных данных и внутренних параметрах. Это достигается за счет использования промежуточных состояний и механизмов, позволяющих модели завершить генерацию на любом шаге, обеспечивая гибкость и потенциал для оптимизации производительности в различных задачах генерации данных. Таким образом, единая архитектура может эффективно выполнять широкий спектр задач, требующих разного количества шагов генерации.
RCGM (Recursive Conditional Generative Model) представляет собой расширение концепции Any-Step Framework, обеспечивающее обобщение существующих методов генеративного моделирования. В отличие от традиционных подходов, RCGM позволяет использовать как многошаговую, так и одношаговую генерацию в рамках единой архитектуры. Это достигается за счет рекурсивного применения условных генеративных блоков, что позволяет модели адаптироваться к различным задачам и данным. Фактически, RCGM включает в себя такие методы, как autoregressive модели, diffusion модели и Variational Autoencoders (VAE) как частные случаи, предлагая более универсальный и эффективный подход к генеративному моделированию, позволяющий оптимизировать процесс генерации для конкретных требований.
Единый подход, реализованный в рамках Any-Step Framework и RCGM, обеспечивает повышенную гибкость и возможности для оптимизации при решении различных задач генерации. Вместо необходимости разработки отдельных моделей для многошаговой и малошаговой генерации, RCGM позволяет использовать единую архитектуру для обоих типов задач, что упрощает процесс разработки и развертывания. Такая унификация открывает возможности для совместной оптимизации параметров модели, что может привести к улучшению производительности и эффективности использования вычислительных ресурсов. Кроме того, единая структура облегчает адаптацию модели к новым задачам генерации, требующим различного количества шагов, и позволяет использовать общие методы обучения и настройки.

TwinFlow: Новая Одношаговая Генеративная Архитектура
В основе архитектуры TwinFlow лежит концепция “двойных траекторий” — двух путей, начинающихся из случайного шума и направленных во времени в противоположные стороны. Эти траектории генерируются одновременно, что позволяет модели напрямую синтезировать изображения, избегая итеративных процессов уточнения. Каждая траектория представляет собой процесс диффузии, но одна идет от шума к изображению (прямое время), а другая — от изображения к шуму (обратное время). Синхронизация этих траекторий является ключевым элементом, позволяющим эффективно использовать информацию, полученную в обоих направлениях, и значительно ускорить процесс генерации. Фактически, TwinFlow использует обратную траекторию для улучшения качества прямой траектории, создавая единый, эффективный путь к конечному изображению.
В основе эффективной одношаговой генерации в TwinFlow лежит выравнивание траекторий, начинающихся из случайного шума и развивающихся в противоположных направлениях времени. Этот процесс достигается посредством использования метода Velocity Matching, который сопоставляет скорости движения вдоль этих траекторий. Для минимизации расхождений и обеспечения сходимости, применяется Rectification Loss — функция потерь, оценивающая разницу между конечными состояниями траекторий и целевым изображением. Минимизация этой функции потерь позволяет получить высококачественный результат за один шаг, избегая необходимости в итеративной доработке с использованием методов, требующих многократных проходов для улучшения качества изображения.
В отличие от традиционных генеративных моделей, требующих многократных итераций для достижения удовлетворительного результата, TwinFlow позволяет синтезировать изображения за один шаг. Это достигается за счет использования концепции “двойных траекторий” и механизмов выравнивания, что устраняет необходимость в последовательной доработке генерируемого контента. Как следствие, время синтеза значительно сокращается, а вычислительная эффективность процесса возрастает, что делает TwinFlow особенно полезным для приложений, требующих генерации изображений в реальном времени или с ограниченными вычислительными ресурсами.

Результаты и Валидация с Qwen-Image-20B
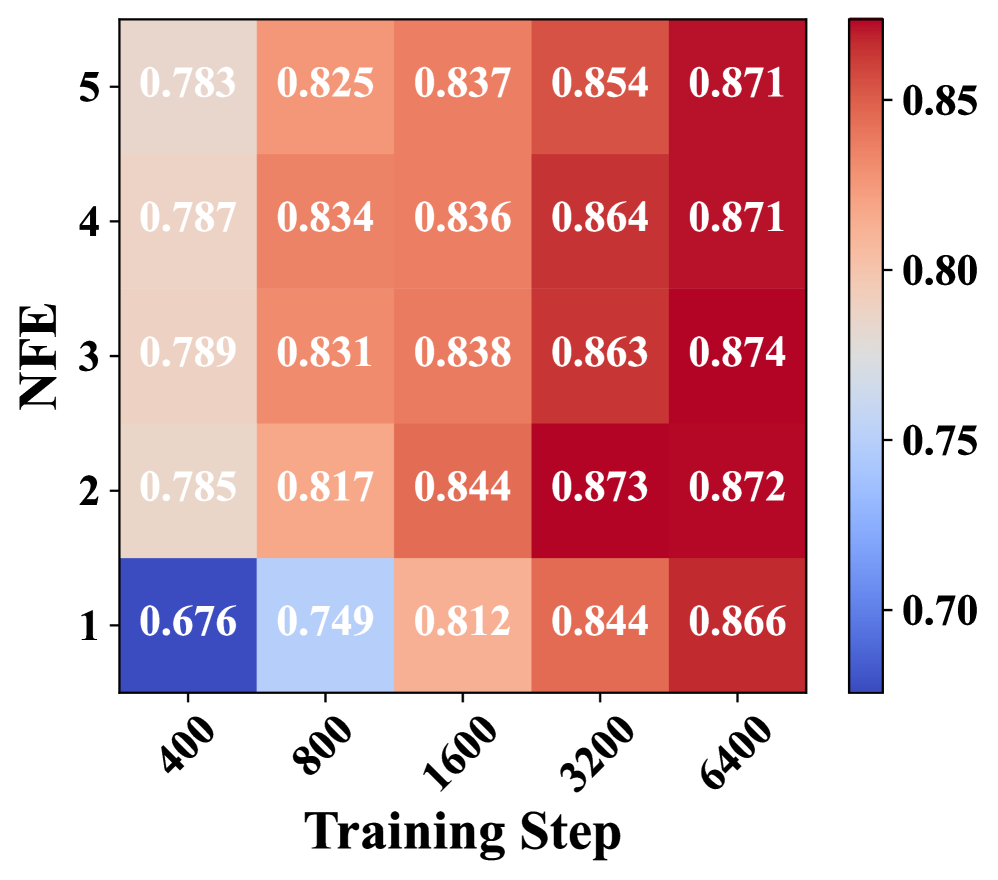
В сочетании с масштабной моделью Qwen-Image-20B и эффективной LoRA тонкой настройкой, TwinFlow демонстрирует впечатляющие результаты на бенчмарке DPG-Bench. Данный подход позволяет добиться высокой производительности в задачах генерации изображений, эффективно используя вычислительные ресурсы. Благодаря оптимизированному процессу обучения, TwinFlow не только достигает сопоставимых показателей с оригинальной моделью, но и превосходит существующие методы генерации при ограниченном числе шагов оценки (NFE), что подчеркивает его практическую значимость и потенциал для дальнейшего развития в области генеративного моделирования.
В ходе оценки с использованием метрик, таких как GenEval, система TwinFlow продемонстрировала превосходство над существующими моделями генерации с небольшим числом шагов. Она достигла показателя GenEval в 0.86 при 1-NFE (number of function evaluations), что сравнимо с результатами оригинальной модели, полученными при 100-NFE. Этот результат указывает на значительное повышение эффективности и скорости работы системы TwinFlow, позволяя достигать сопоставимого качества генерации с гораздо меньшими вычислительными затратами. Подобная производительность открывает новые возможности для применения генеративных моделей в условиях ограниченных ресурсов и в реальном времени.
В ходе оценки на бенчмарке DPG-Bench, разработанная методика TwinFlow продемонстрировала впечатляющий результат в 86.52% при использовании всего лишь 1-NFE (number of function evaluations), что сопоставимо с производительностью оригинальной модели, требующей 100-NFE. Более того, при применении к моделям SANA, TwinFlow превзошел существующие передовые методы few-step генерации, достигнув показателей GenEval в 0.83 для SANA-0.6B и 0.81 для SANA-1.6B. Эти результаты свидетельствуют о значительном улучшении эффективности и скорости генерации изображений, что открывает новые возможности для развития области генеративного моделирования.
Полученные результаты валидации подтверждают значительный потенциал TwinFlow для существенного прогресса в области генеративного моделирования. Сочетание TwinFlow с масштабной моделью Qwen-Image-20B и эффективной LoRA-настройкой демонстрирует впечатляющие показатели на бенчмарке DPG-Bench, достигая сравнимой производительности с оригинальной моделью, но при значительно меньших вычислительных затратах. Превосходство TwinFlow над существующими методами, особенно в задачах, требующих небольшого количества шагов генерации, указывает на его способность оптимизировать процесс создания изображений и повысить эффективность генеративных моделей. Эти достижения открывают перспективы для разработки более быстрых, доступных и качественных систем генерации изображений, что может привести к инновациям в различных областях, включая компьютерное зрение, дизайн и искусство.
Представленная работа демонстрирует стремление к математической чистоте в области генеративных моделей. TwinFlow, с его концепцией ‘двойной траектории’, представляет собой элегантное решение, позволяющее достичь высококачественной генерации изображений всего за один или два шага. Это подтверждает важность доказательства корректности алгоритма, а не просто его работоспособности на тестовых данных. Как однажды отметила Фэй-Фэй Ли: «Искусственный интеллект — это не только технология, но и отражение человеческих ценностей». В данном случае, ценностью является стремление к элегантности и эффективности, что TwinFlow и демонстрирует, предлагая простой, но эффективный подход к обучению масштабных генеративных моделей.
Что Дальше?
Представленный подход, хоть и демонстрирует впечатляющую эффективность в сокращении числа шагов генерации, всё же не решает фундаментальную проблему: необходимость в априорном определении траектории. Оптимизация без анализа — это самообман и ловушка для неосторожного разработчика. Хотя концепция «двойной траектории» и позволяет обойти некоторые ограничения существующих методов, вопрос о доказательной корректности такой аппроксимации остаётся открытым. Следующим шагом представляется не просто увеличение масштаба модели или усложнение архитектуры, а поиск принципиально новых методов, гарантирующих сходимость к желаемому результату даже при минимальном числе шагов.
Особый интерес представляет возможность интеграции TwinFlow с другими генеративными моделями, такими как вариационные автоэнкодеры или GAN, с целью создания гибридных систем, сочетающих в себе преимущества различных подходов. Однако, прежде чем приступать к подобным экспериментам, необходимо тщательно исследовать свойства пространства латентных переменных и обеспечить их согласованность. Попытки просто «склеить» различные модели без глубокого понимания их внутренней логики обречены на провал.
Наконец, стоит задуматься о вопросе интерпретируемости. Каким образом генерируемые изображения соотносятся с исходными данными? Какие факторы влияют на процесс генерации? Понимание этих вопросов позволит не только улучшить качество генерируемых изображений, но и использовать их для решения более сложных задач, таких как визуализация данных или создание виртуальных миров.
Оригинал статьи: https://arxiv.org/pdf/2512.05150.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
2025-12-08 10:13