Автор: Денис Аветисян
Исследователи предлагают метод повышения эффективности моделей, генерирующих текст и изображения, за счет интеллектуального удаления нестабильных элементов внимания.
В статье представлен метод Sink-Aware Pruning, адаптированный к особенностям диффузионных языковых моделей и позволяющий повысить их производительность за счет отсечения нестабильных элементов внимания, зависящих от временного шага.
Несмотря на впечатляющие возможности диффузионных языковых моделей, их итеративный процесс шумоподавления обуславливает высокую вычислительную стоимость. В статье ‘Sink-Aware Pruning for Diffusion Language Models’ предложен новый подход к разрежению, основанный на анализе поведения «якорных» токенов внимания. Показано, что в отличие от авторегрессионных моделей, позиция этих «якорей» в диффузионных моделях нестабильна и не отражает структурную важность, что позволяет безопасно удалять неустойчивые связи без переобучения. Не приведет ли это к новым способам повышения эффективности и масштабируемости диффузионных языковых моделей?
Предел Внимания: Ограничения Плотных Трансформеров
Стандартные архитектуры Transformer, несмотря на свою мощь, в значительной степени зависят от механизма внимания, что создает существенные вычислительные ограничения при увеличении длины последовательности обрабатываемых данных. Этот механизм, требующий вычисления взаимодействия между каждой парой элементов последовательности, приводит к квадратичной зависимости вычислительных затрат и потребления памяти от длины входных данных O(n^2). По мере увеличения длины последовательности, например, при обработке длинных текстов или высокоразрешающих изображений, вычислительная нагрузка становится непомерно высокой, ограничивая возможности масштабирования и препятствуя эффективной обработке больших объемов информации. В результате, даже при наличии достаточных вычислительных ресурсов, обработка длинных последовательностей становится узким местом, снижающим производительность и ограничивающим применимость Transformer в задачах, требующих анализа обширного контекста.
Ограничения, связанные с вычислительной сложностью механизма внимания в трансформерах, особенно ярко проявляются в задачах, требующих глубокого понимания контекста. Чем длиннее последовательность данных, тем сложнее модели становится эффективно обрабатывать информацию, что приводит к снижению производительности и масштабируемости. Например, в задачах обработки естественного языка, таких как анализ длинных текстов или перевод сложных предложений, модель должна учитывать взаимосвязи между всеми элементами последовательности. Неспособность эффективно справляться с этой задачей приводит к потере важных нюансов и, как следствие, к ухудшению качества результатов. Таким образом, ограничение масштабируемости становится критическим фактором, препятствующим применению трансформеров в задачах, где контекст играет решающую роль.
Современные методы прореживания нейронных сетей, в частности, неструктурированное прореживание, зачастую оказываются неэффективными в решении ключевых проблем, связанных с вычислительной сложностью. Несмотря на стремление к увеличению разреженности модели, снижение производительности оказывается несоизмеримо малым. Вместо существенного ускорения вычислений и снижения потребления памяти, такие подходы приводят к незначительному уменьшению числа параметров при заметной потере точности. Это связано с тем, что неструктурированное удаление связей не учитывает структуру данных и зависимость между ними, что приводит к потере важной информации и ухудшению обобщающей способности модели. Таким образом, простые методы разреженности не позволяют в полной мере реализовать потенциал оптимизации, доступный в плотных трансформаторах.
Выявление Точек Притяжения Внимания: Новый Объект Прунинга
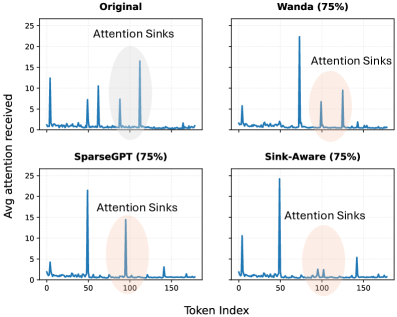
В механизмах внимания нейронных сетей наблюдается неравномерное распределение весов: определенные токены последовательно привлекают непропорционально большое количество внимания, формируя так называемые “Точки Притяжения Внимания” (Attention Sinks). Данное явление означает, что не все связи в графе внимания одинаково важны для процесса рассуждения модели. Анализ показывает, что некоторые токены, являясь “точками притяжения”, могут доминировать в распределении внимания, в то время как другие остаются практически незамеченными. Выявление этих доминирующих токенов является ключевым шагом для оптимизации архитектуры сети и повышения ее эффективности.
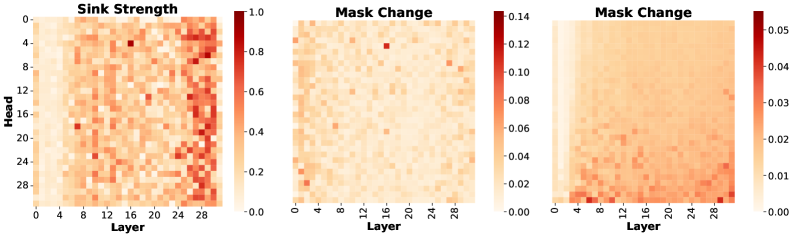
Стабильность так называемых «внимательных точек» (Attention Sinks), измеряемая посредством «Дисперсии точки» (Sink Variance), напрямую коррелирует с их значимостью для процесса логических рассуждений модели. Высокая дисперсия указывает на непостоянство внимания к конкретному токену в разных входных данных или слоях сети, что свидетельствует о его меньшей роли в формировании итогового результата. Напротив, низкая дисперсия говорит о стабильном привлечении внимания к данному токену, подтверждая его важность для принятия решений моделью. Таким образом, Sink Variance позволяет количественно оценить вклад каждой «внимательной точки» в общий процесс рассуждения и использовать эту информацию для более эффективной оптимизации и прунинга модели.
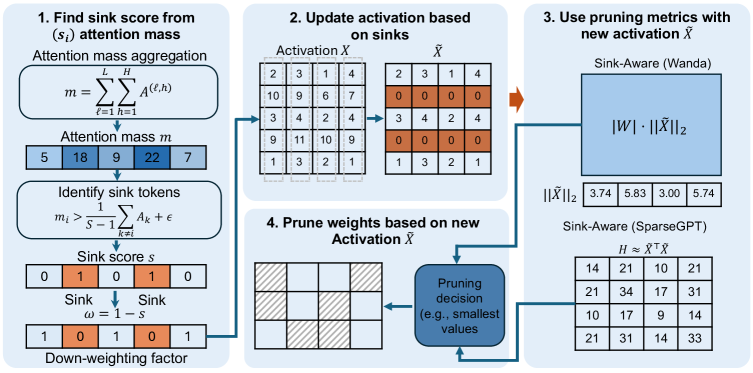
Метод Sink-Aware Pruning использует выявленные неустойчивые «Attention Sinks» для более целенаправленного сокращения числа параметров модели. Вместо случайного или равномерного удаления связей внимания, данный подход фокусируется на удалении путей внимания, связанных с токенами, демонстрирующими высокую изменчивость в привлечении внимания. Это позволяет снизить вычислительные затраты и размер модели, при этом минимизируя влияние на качество выходных данных, поскольку удаляются связи, которые, вероятно, вносят меньший вклад в процесс рассуждения модели, чем связи, связанные с устойчивыми «Attention Sinks». В отличие от традиционных методов обрезки, которые могут случайно удалить важные параметры, Sink-Aware Pruning обеспечивает более точное и эффективное сокращение модели.
Эмпирическая Валидация: Прунинг с Точностью
Метод Sink-Aware Pruning был успешно реализован и протестирован на различных языковых моделях, включая LLaDA, Dream и LLaDA-1.5. В ходе экспериментов подтверждена работоспособность алгоритма на архитектурах, различающихся по размеру и структуре. Реализация включала интеграцию метода в существующие пайплайны обучения и оценки моделей, что позволило провести всестороннее тестирование на стандартных наборах данных и оценить влияние pruning на производительность и точность. Результаты подтверждают применимость Sink-Aware Pruning к широкому спектру современных языковых моделей.
Метод Sink-Aware Pruning использует калибровочный набор данных (Calibration Dataset) для точной оценки стабильности «стоков» (sink) в нейронной сети перед проведением обрезки. Этот набор данных позволяет определить, какие веса и нейроны являются наименее критичными для сохранения производительности модели. Оценка стабильности «стоков» основана на анализе их вклада в выходные данные модели на примерах из калибровочного набора. Веса, соответствующие нестабильным «стокам», исключаются из процесса обрезки, что позволяет минимизировать потери точности и поддерживать высокую производительность модели после сокращения числа параметров. Использование калибровочного набора данных является ключевым фактором, обеспечивающим прецизионную обрезку и сохранение функциональности модели.
Оценка эффективности метода проводилась на стандартных бенчмарках, включающих MMLU, ARC-C и PIQA. Результаты демонстрируют стабильное увеличение разреженности модели без существенной потери производительности. На этих бенчмарках зафиксировано измеримое улучшение точности, подтверждающее эффективность предложенного подхода к прунингу. Наблюдаемые улучшения точности позволяют достигать более компактных моделей без ущерба для их способности решать задачи, оцениваемые данными бенчмарками.
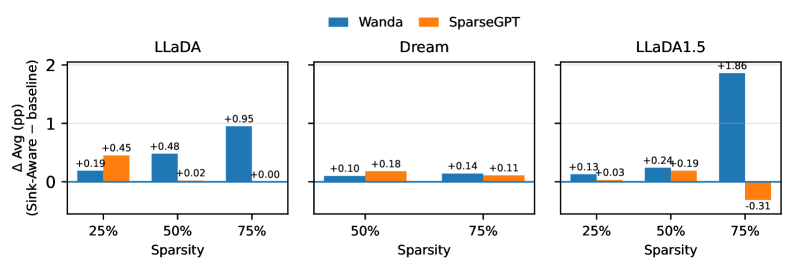
В ходе сравнительного анализа, метод Sink-Aware Pruning продемонстрировал превосходство над подходами Wanda и SparseGPT в поддержании точности модели при увеличении разреженности. Эксперименты, проведенные на моделях LLaDA, Dream и LLaDA-1.5 с использованием стандартных бенчмарков MMLU, ARC-C и PIQA, показали, что Sink-Aware Pruning последовательно достигает либо сопоставимых, либо более высоких результатов в сохранении точности по сравнению с указанными базовыми методами. Данные свидетельствуют о том, что предложенный подход обеспечивает более эффективное сжатие моделей без существенной потери в производительности, что подтверждается измеримыми улучшениями на различных тестовых наборах.
К Эффективным Языковым Моделям: Новая Парадигма
Метод Sink-Aware Pruning направлен на оптимизацию больших языковых моделей путем избирательного удаления так называемых “нестабильных точек внимания” — участков, склонных к флуктуациям и не несущих критически важной информации. В отличие от традиционных методов, которые удаляют параметры случайным образом, данный подход фокусируется на сохранении ключевых связей, ответственных за рассуждения и понимание контекста. Удаляя именно неустойчивые участки внимания, модель минимизирует потерю информации и сохраняет способность к логическим выводам, даже при значительном уменьшении размера и вычислительной сложности. Это позволяет достичь высокой эффективности модели без ущерба для её когнитивных способностей, открывая путь к более компактным и производительным языковым моделям.
Современные большие языковые модели, несмотря на свою впечатляющую производительность, требуют колоссальных вычислительных ресурсов и объемов памяти, что ограничивает их широкое применение. Разработанный подход позволяет существенно снизить эти затраты за счет оптимизации процесса обработки информации. Уменьшение вычислительной сложности и необходимого объема памяти достигается путем целенаправленного устранения избыточных параметров модели, что позволяет добиться значительной экономии ресурсов без существенной потери качества генерируемого текста. Это открывает перспективы для развертывания мощных языковых моделей на более доступном оборудовании, включая мобильные устройства и системы с ограниченными ресурсами, что делает передовые технологии обработки естественного языка более доступными для широкого круга пользователей и приложений.
Перспективы метода Sink-Aware Pruning выходят далеко за рамки текущих языковых моделей. Исследователи планируют адаптировать данный подход к другим архитектурам нейронных сетей, включая модели компьютерного зрения и обработки аудио, что позволит снизить вычислительные затраты и объём памяти, необходимые для их работы. Успешное применение Sink-Aware Pruning в различных модальностях откроет новые возможности для создания более эффективных и доступных искусственных интеллектов, способных решать широкий спектр задач. Ожидается, что дальнейшие исследования в этой области приведут к разработке универсальных методов оптимизации, применимых к различным типам моделей и данных, что существенно расширит область их применения и потенциальное влияние.
Исследование роли так называемых “точек притяжения внимания” в больших языковых моделях открывает перспективы для создания не только более эффективных, но и более понятных систем. Установлено, что целенаправленное устранение нестабильных “точек притяжения внимания” позволяет значительно снизить вычислительные затраты и объем памяти, сохраняя при этом ключевые возможности модели к рассуждению. Особенно заметные улучшения достигаются при умеренной и высокой степени разреженности (от 50% до 75%), что демонстрирует ценность данного подхода при агрессивном сжатии. Понимание механизмов работы этих “точек притяжения внимания” может привести к разработке более интерпретируемых моделей, способных не только генерировать текст, но и объяснять логику своих решений, а также к повышению их устойчивости к различным помехам и искажениям во входных данных.
Исследование демонстрирует, что поведение ‘внимательных поглотителей’ (attention sinks) существенно различается между диффузионными и авторегрессионными языковыми моделями. Предложенная стратегия обрезки, учитывающая эту особенность, направлена на повышение эффективности за счет исключения нестабильных участков внимания. Как однажды заметила Ада Лавлейс: «То, что может быть выражено в математической форме, живо; то, что не может быть выражено, мёртво». Этот принцип находит отражение в стремлении к точности и доказуемости алгоритмов, что особенно важно при разработке и оптимизации сложных моделей, таких как диффузионные языковые модели. Оптимизация без анализа, как справедливо отмечалось, является самообманом, и данная работа является ярким подтверждением этого.
Что Дальше?
Представленная работа, выявляя специфику поведения «поглотителей внимания» в диффузионных языковых моделях, вносит ценный вклад в понимание их внутренней архитектуры. Однако, математическая чистота решения не гарантирует универсальности. Устойчивость предложенного метода к различным архитектурам диффузионных моделей и наборам данных требует дальнейшей, строгой проверки. В частности, влияние различных стратегий отбора «поглотителей» и параметров адаптации к временным шагам нуждается в более глубоком исследовании.
В конечном счете, настоящая элегантность кроется не в простом снижении вычислительных затрат, а в доказательстве сохранения генеративного качества модели после прунинга. Многие подходы демонстрируют снижение параметров, но лишь немногие гарантируют, что эта экономия не обернется ухудшением результатов. В хаосе данных спасает только математическая дисциплина, и необходимо сосредоточиться на разработке формальных метрик для оценки стабильности прунинга, а не полагаться на эмпирические наблюдения.
Будущие исследования могли бы сосредоточиться на интеграции предложенного метода с другими техниками сжатия моделей, такими как квантизация и дистилляция знаний. Более того, исследование возможности адаптации стратегии прунинга в процессе обучения, а не только после него, представляется перспективным направлением. Иначе говоря, необходимо стремиться к созданию самооптимизирующихся моделей, способных самостоятельно находить оптимальный баланс между эффективностью и производительностью.
Оригинал статьи: https://arxiv.org/pdf/2602.17664.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Квантовый скачок: от лаборатории к рынку
2026-02-24 03:22