Автор: Денис Аветисян
В статье представлен всесторонний обзор подхода COAML, объединяющего методы комбинаторной оптимизации и машинного обучения для повышения эффективности принятия решений в условиях неопределенности.
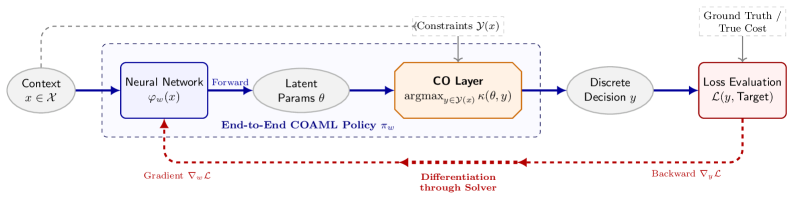
Обзор теоретических основ, методологических достижений и областей применения комбинаторной оптимизации, дополненной машинным обучением (COAML).
Традиционные подходы к машинному обучению часто испытывают трудности при решении комбинаторных задач, требующих учета ограничений и дискретных решений. Настоящий обзор посвящен перспективному направлению ‘Combinatorial Optimization Augmented Machine Learning’, объединяющему возможности предсказательного моделирования с методами комбинаторной оптимизации. Предлагаемый подход позволяет создавать стратегии, основанные на данных и гарантирующие выполнимость решений, стирая границы между машинным обучением, исследованием операций и стохастической оптимизацией. Какие новые горизонты открываются для применения COAML в задачах планирования, маршрутизации и обучения с подкреплением?
Трудность Комбинаторного Хаоса
Многие задачи, с которыми сталкивается современный мир, характеризуются огромным количеством возможных комбинаций и вариантов, что делает их недоступными для решения традиционными методами машинного обучения. Представьте себе задачу планирования логистики с тысячами пунктов доставки или оптимизацию сложной финансовой модели — пространство всех возможных решений быстро становится астрономическим. Традиционные алгоритмы, требующие перебора всех комбинаций или анализа огромных объемов данных, оказываются неэффективными и непрактичными. Это связано с тем, что вычислительные ресурсы, необходимые для обработки такого количества вариантов, растут экспоненциально с увеличением сложности задачи. В результате возникает потребность в принципиально новых подходах, способных эффективно ориентироваться в этих сложных комбинаторных пространствах и находить оптимальные или хотя бы приемлемые решения в разумные сроки.
Проблемы, требующие принятия сложных решений (CSOProblems), часто связаны с необходимостью учитывать неопределенность и случайность, что существенно ограничивает возможности подходов, основанных исключительно на анализе данных. В таких ситуациях, где исход событий не детерминирован, а подвержен вероятностным влияниям, недостаточно просто выявить закономерности в исторических данных. Вместо этого, требуется способность оценивать риски, прогнозировать вероятности различных исходов и адаптироваться к изменяющимся обстоятельствам. Традиционные методы машинного обучения, полагающиеся на большие объемы размеченных данных, оказываются неэффективными, поскольку не способны адекватно моделировать и учитывать случайные факторы, что делает необходимым разработку новых подходов, сочетающих в себе элементы вероятностного моделирования и логического вывода.
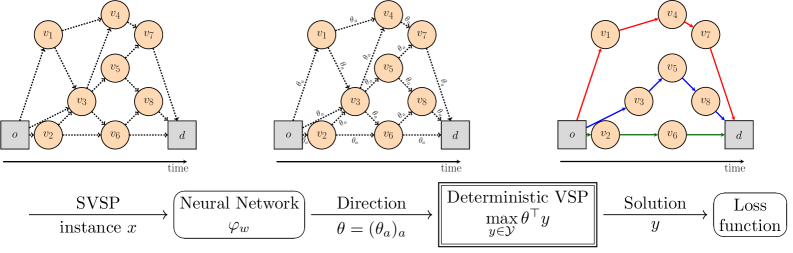
COAML: Сплетение Машинного Обучения и Оптимизации
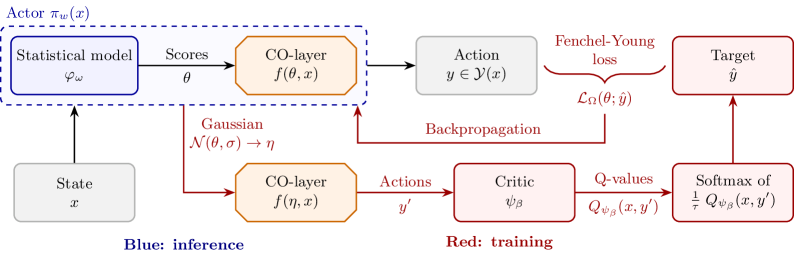
COAML представляет собой новую структуру, объединяющую модели машинного обучения с мощными решателями ‘COOracle’. Данный подход заключается в синергетическом взаимодействии: модели машинного обучения используются для прогнозирования и аппроксимации решений, а решатели ‘COOracle’ — для обеспечения гарантий оптимальности и структурной целостности процесса принятия решений. В основе лежит итеративный процесс, в котором машинное обучение направляет поиск решателя, а решатель предоставляет обратную связь для улучшения модели машинного обучения. Архитектура COAML позволяет решать сложные задачи, требующие как прогностической точности, так и строгих гарантий качества решения.
Интеграция машинного обучения и оптимизации в рамках COAML позволяет осуществлять сквозное обучение политик принятия решений. Этот подход использует предсказательную силу моделей машинного обучения для формирования начальных решений, которые затем уточняются и гарантированно улучшаются с помощью оптимизационных решателей ‘COOracle’, обеспечивающих структурные гарантии качества. Эффективность данного метода подтверждена на стандартных задачах в областях маршрутизации транспорта, планирования и распределения ресурсов, где наблюдалось улучшение результатов по сравнению с существующими подходами.
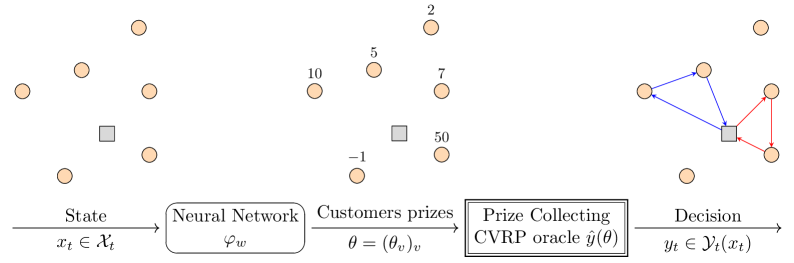
Пропуск Градиента Через Комбинаторные Слои
Обучение моделей COAML требует вычисления градиентов через недифференцируемые комбинаторные операции. Для решения этой проблемы используется функция потерь Fenchel-Young (FYLoss). FYLoss позволяет аппроксимировать недифференцируемые функции с помощью дифференцируемых, что обеспечивает возможность обратного распространения ошибки (backpropagation) через комбинаторные слои. По сути, FYLoss заменяет дискретные операции на их выпуклые релаксации, обеспечивая дифференцируемый путь для градиентов и позволяя оптимизировать всю модель COAML посредством стандартных алгоритмов градиентного спуска. \mathcal{L}_{FY} = \max_{u} \langle x, u \rangle - f^<i>(u) , где f^</i> — бифункция, а u — вспомогательная переменная.
Использование функции потерь Fenchel-Young (FYLoss) позволяет эффективно распространять градиенты через недифференцируемые комбинаторные операции, что обеспечивает сквозную оптимизацию всего конвейера COAML. Это достигается за счет аппроксимации недифференцируемых операций дифференцируемыми аналогами в рамках FYLoss. В результате, становится возможным вычисление градиентов и их использование для обучения всех компонентов модели COAML. Кроме того, применение FYLoss позволяет установить теоретические границы избыточного риска ε, демонстрируя статистическую обобщающую способность и коэффициенты аппроксимации, что подтверждает эффективность подхода в задачах машинного обучения.
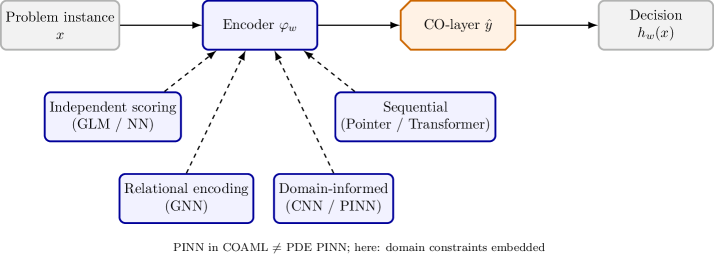
Универсальность Благодаря Различным Парадигмам Обучения
Платформа COAML отличается исключительной адаптивностью, обеспечивая бесшовную интеграцию с различными подходами машинного обучения, включая обучение с подкреплением (RL), имитационное обучение (IL) и эволюционные стратегии управления (ECM). Такая универсальность позволяет эффективно решать широкий спектр задач, адаптируясь к специфике каждой конкретной проблемы. Возможность выбора и комбинирования различных алгоритмов обучения значительно расширяет область применения COAML, делая её подходящей для оптимизации сложных комбинаторных задач в различных областях, от робототехники до разработки новых материалов. Гибкость платформы заключается в том, что она не ограничивается одним методом, а позволяет исследователям и инженерам использовать наиболее подходящий инструмент для достижения желаемого результата.
В рамках данной системы активно используются модели машинного обучения MLModel и графовые нейронные сети GNN для анализа и моделирования сложных взаимосвязей в комбинаторном пространстве. Этот подход позволяет не только повысить эффективность решения задач, но и значительно улучшить способность системы к обобщению — то есть, к успешной работе с новыми, ранее не встречавшимися ситуациями. Использование GNN, в частности, позволяет эффективно представлять и обрабатывать данные, имеющие структуру графа, что особенно важно для задач, связанных с оптимизацией и поиском в больших пространствах решений.
В рамках COAML предусмотрена возможность интеграции нейронных сетей, решающих дифференциальные уравнения (PINN), что позволяет существенно повысить точность и надежность оптимизационных процессов. PINN, встраиваясь в существующую архитектуру, обеспечивают соответствие полученных решений фундаментальным физическим законам и ограничениям. Такой подход особенно важен при решении сложных комбинаторных задач, где соблюдение физической правдоподобности критически важно. Использование PINN не только уточняет полученные результаты, но и улучшает обобщающую способность модели, позволяя эффективно решать задачи, где данные ограничены или зашумлены. По сути, PINN выступают в роли регуляризатора, направляющего процесс оптимизации в область физически допустимых решений, что значительно расширяет сферу применения COAML.
Преодолевая Масштабируемость и Обобщающую Способность
Проблема масштабируемости остаётся существенным ограничением в контексте комбиниаторных задач большого объёма. Для эффективной обработки подобных вычислений применяются инновационные подходы, в частности, гибридные алгоритмы, объединяющие преимущества различных методов, и суррогатные модели, заменяющие сложные вычисления более простыми аппроксимациями. Такой симбиоз позволяет существенно сократить вычислительные затраты и время обработки, сохраняя при этом приемлемую точность результатов. Дальнейшие исследования направлены на оптимизацию этих методов и разработку новых алгоритмов, способных справляться с постоянно растущими объёмами данных и сложностью задач.
Для решения проблемы обобщения, заключающейся в способности модели корректно работать с новыми, ранее не встречавшимися данными, необходимы надежные стратегии регуляризации и методы увеличения объема данных. Регуляризация, посредством добавления штрафов к сложным моделям, препятствует переобучению и способствует выявлению наиболее значимых закономерностей. В свою очередь, увеличение объема данных, достигаемое за счет применения техник аугментации, позволяет модели изучать более широкий спектр вариаций и повышает ее устойчивость к шуму и отклонениям. Сочетание этих подходов обеспечивает более надежную и универсальную производительность модели COAML в различных условиях и задачах, расширяя область ее практического применения.
Будущие исследования в области COAML сосредоточены на разработке более эффективных алгоритмов и изучении новых архитектур, призванных преодолеть существующие ограничения масштабируемости и обобщающей способности. Особое внимание уделяется поиску инновационных подходов, способных обрабатывать сложные комбинаторные задачи с высокой производительностью и адаптироваться к разнообразным условиям. Предполагается, что дальнейшее развитие алгоритмической базы и архитектурных решений позволит раскрыть весь потенциал COAML, открывая новые возможности для применения в различных областях, от оптимизации сложных систем до разработки интеллектуальных агентов.
Данное исследование, претендующее на всеобъемлющий обзор COAML, закономерно вызывает скепсис. Авторы усердно описывают теоретические основы и методологические новшества, но, как показывает опыт, любая «элегантная» система оптимизации рано или поздно столкнется с реальностью продакшена. Клод Шеннон метко подметил: «Информация — это не то, что мы передаём, а то, что принимается». Иными словами, не важно, насколько сложна модель, если она не способна адаптироваться к непредсказуемым данным и ошибкам в реальном времени. В контексте COAML, эта фраза особенно актуальна, поскольку интеграция комбинаторной оптимизации в машинное обучение призвана улучшить принятие решений в условиях неопределенности, но, как известно, даже самая совершенная оптимизация не застрахована от внезапного сбоя.
Что дальше?
Обзор, представленный в данной работе, аккуратно упаковывает COAML — симбиоз комбинаторной оптимизации и машинного обучения. Однако, как показывает опыт, любая элегантная теория неизбежно сталкивается с суровой реальностью продакшена. Оптимизация, при всей её математической красоте, всегда найдёт способ споткнуться о неожиданное ограничение, а «обучение с подкреплением», столь многообещающее на бумаге, запросто превратится в бесконечный цикл случайных действий. Очевидно, что дальнейшее развитие потребует не только улучшения алгоритмов, но и признания их принципиальной ограниченности.
Вместо того, чтобы стремиться к идеальной модели, следует сосредоточиться на создании систем, способных адаптироваться к неточностям и ошибкам. Важнее не «найти оптимальное решение», а «выжить в условиях неопределённости». Тесты, конечно, важны, но, как известно, это всего лишь форма надежды, а не гарантия. Особый интерес представляет вопрос о масштабируемости. Алгоритмы, работающие на небольших задачах, часто оказываются бесполезными в реальных условиях. И, разумеется, не стоит забывать о простоте. Сложность — это враг надёжности.
В конечном итоге, будущее COAML, как и любой другой «революционной» технологии, предрешено: станет техдолгом. Но это не повод отказываться от исследований. Ведь даже зная, что всё рухнет, можно попытаться построить что-то красивое и устойчивое… хотя бы на время.
Оригинал статьи: https://arxiv.org/pdf/2601.10583.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2026-01-16 13:54