Автор: Денис Аветисян
Исследователи разработали метод, позволяющий значительно ускорить и улучшить качество рассуждений больших языковых моделей за счет фильтрации несущественных шагов.
Метод FROST использует модифицированный механизм внимания (Softmax1) для выявления и удаления «шума» в процессе логических рассуждений, повышая скорость и точность работы моделей.
Несмотря на впечатляющие возможности больших языковых моделей в решении задач рассуждения, их эффективность часто страдает от избыточности и некритичных шагов. В данной работе, представленной под названием ‘FROST: Filtering Reasoning Outliers with Attention for Efficient Reasoning’, предлагается новый метод, основанный на механизмах внимания, для фильтрации «выбросов» в процессе рассуждений. FROST позволяет сократить количество используемых токенов и повысить точность моделей, таких как Phi-4-Reasoning и GPT-OSS-20B, за счет удаления нерелевантных шагов. Возможно ли дальнейшее повышение эффективности и надежности моделей рассуждения путем более тонкой настройки механизмов внимания и разработки новых стратегий фильтрации?
Устранение избыточности: путь к эффективным рассуждениям
Современные большие языковые модели, демонстрирующие впечатляющую способность к логическим рассуждениям, зачастую генерируют избыточные, ненужные шаги в процессе решения задач. Несмотря на кажущуюся эффективность, подобный подход снижает общую надежность и скорость работы моделей, увеличивая вычислительные затраты. Вместо прямого пути к решению, модели склонны исследовать множество нерелевантных направлений, что приводит к увеличению вероятности ошибок и замедлению процесса получения окончательного ответа. Данная особенность представляет собой значительную проблему для практического применения этих мощных инструментов в задачах, требующих высокой точности и оперативной обработки информации.
Неэффективность больших языковых моделей при решении задач часто обусловлена склонностью к исследованию множества нерелевантных путей. В процессе поиска решения, модель генерирует избыточные рассуждения, отклоняясь от оптимальной траектории. Это не только увеличивает вычислительные затраты и время обработки, но и повышает вероятность ошибок, поскольку каждая дополнительная ветвь рассуждений содержит потенциальные источники неточностей. По сути, модель «теряется» в пространстве возможностей, тратя ресурсы на анализ неперспективных вариантов вместо фокусировки на наиболее вероятном решении. Таким образом, преодоление этой тенденции к избыточности является ключевой задачей для повышения эффективности и надежности больших языковых моделей.
FROST: Обрезка для повышения эффективности
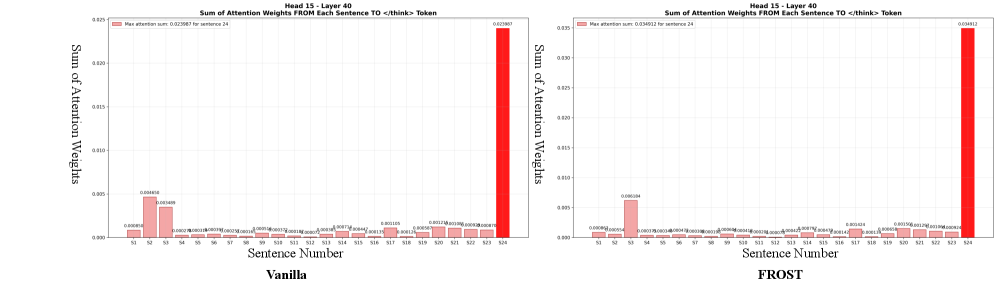
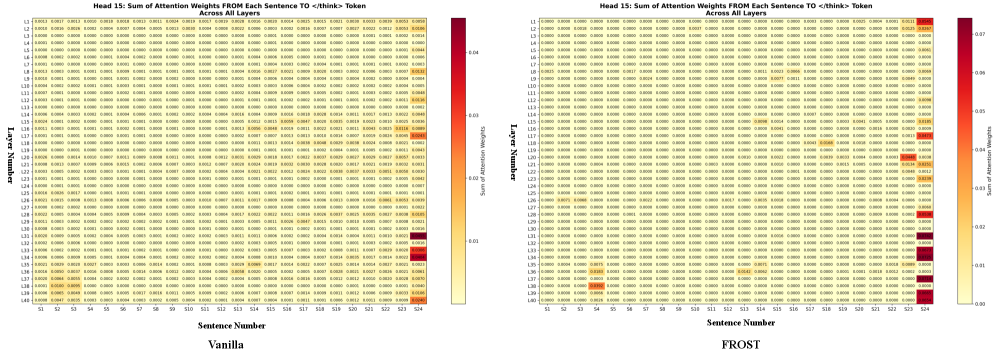
Механизм FROST оценивает важность каждого шага рассуждений, используя веса внимания (Attention Weights). Эти веса, являющиеся результатом работы модели, количественно отражают вклад каждого промежуточного шага в формирование конечного ответа. Шаги с минимальными весами внимания рассматриваются как наименее критичные, то есть оказывающие незначительное влияние на конечный результат. Анализ весов внимания позволяет идентифицировать избыточные или нерелевантные шаги в процессе рассуждений, предоставляя основу для их последующего удаления без ущерба для точности решения.
Метод FROST определяет “выбросы в рассуждениях” (Reasoning Outliers) путем комбинирования весов внимания (Attention Weights) и энтропии. Веса внимания оценивают значимость каждого шага рассуждений, а энтропия измеряет неопределенность, связанную с этим шагом. Шаги, характеризующиеся низкими значениями весов внимания и высокой энтропией, классифицируются как выбросы, поскольку они вносят незначительный вклад в конечный результат, но при этом содержат высокую степень неопределенности. Этот подход позволяет идентифицировать и исключить шаги, которые не улучшают качество решения, оптимизируя процесс рассуждений.
Удаление выявленных “выбросов” в процессе рассуждений позволяет значительно сократить длину траектории поиска решения. В ходе экспериментов было установлено, что применение данного метода привело к 69.68% уменьшению средней длины пути рассуждений без снижения точности конечного результата. Это достигается за счет удаления шагов, которые характеризуются низкой значимостью для получения ответа и высокой степенью неопределенности, что позволяет сконцентрироваться на наиболее релевантных этапах логического вывода.

Технические детали: Улучшение Softmax1
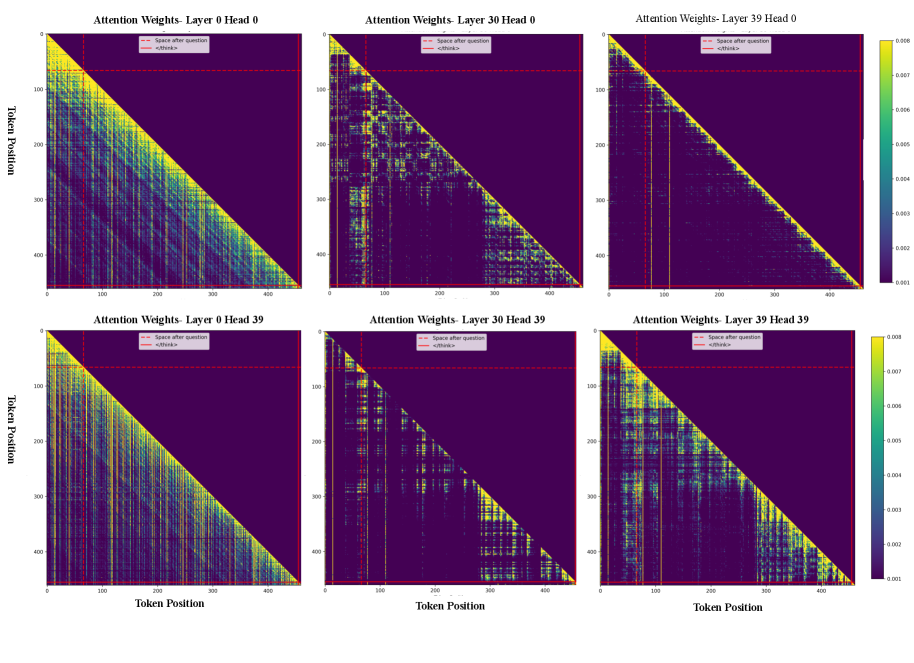
Функция Softmax1 является усовершенствованием стандартной функции Softmax и реализует динамическое масштабирование активаций. В отличие от традиционного Softmax, который может присваивать ненулевые веса даже элементам с низкой степенью внимания, Softmax1 подавляет активации с низкой степенью внимания до пренебрежимо малых значений. Это достигается путем адаптивной регулировки масштаба активаций, что позволяет эффективно отсеивать нерелевантные пути обработки информации. Математически, это можно представить как модификацию стандартной формулы Softmax: Softmax1(x_i) = \frac{e^{x_i / \tau}}{\sum_{j} e^{x_j / \tau}} , где τ — параметр, динамически регулирующий масштаб активаций в зависимости от их значений.
Подавление нерелевантных путей является ключевым фактором в способности FROST оптимизировать процесс рассуждений без потери целостности решения. В процессе поиска ответа на сложные вопросы, языковые модели часто генерируют множество промежуточных результатов, большинство из которых не имеют отношения к конечному ответу. FROST, посредством Softmax1, целенаправленно снижает вклад этих нерелевантных путей в финальное решение, эффективно концентрируя вычислительные ресурсы на наиболее перспективных направлениях. Это позволяет значительно ускорить процесс рассуждений и уменьшить вероятность ошибок, сохраняя при этом точность и надежность конечного ответа.
Реализация Softmax1 использует параметрически-эффективные методы, такие как LoRA (Low-Rank Adaptation), для обеспечения адаптации к различным языковым моделям без необходимости полной переподготовки. LoRA позволяет заморозить предварительно обученные веса модели и обучать лишь небольшое количество дополнительных параметров низкого ранга, что значительно снижает вычислительные затраты и требования к памяти. Этот подход позволяет эффективно интегрировать Softmax1 в существующие архитектуры, сохраняя при этом производительность и обобщающую способность исходной модели. Применение LoRA также упрощает процесс развертывания и масштабирования, поскольку требует значительно меньше ресурсов для обучения и хранения.

Проверка и результаты на основных эталонных задачах
В ходе тестирования на сложных математических наборах данных, таких как GSM8K, MATH500 и AIME24, методика FROST продемонстрировала значительное увеличение точности решения задач. В среднем, по сравнению с базовыми моделями, наблюдается прирост в 26.70%. Это свидетельствует о способности FROST эффективно улучшать навыки рассуждения языковых моделей при решении математических задач различной сложности, что делает её перспективным инструментом для повышения производительности в этой области. Полученные результаты подтверждают, что FROST способна существенно повысить качество ответов в задачах, требующих логического мышления и математических вычислений.
Исследования показали, что методика FROST демонстрирует значительную универсальность, успешно интегрируясь и повышая эффективность различных языковых моделей. Оценки, проведенные на таких моделях, как Phi-4-Reasoning, DeepSeek-R1, Minerva и GPT-OSS-20B, подтверждают способность FROST адаптироваться к разным архитектурам и размерам моделей. Этот подход не ограничивается конкретным типом нейронной сети, что позволяет использовать его для улучшения способностей к рассуждению в широком спектре приложений, от небольших моделей, предназначенных для работы на устройствах с ограниченными ресурсами, до крупных моделей, требующих высокой вычислительной мощности. Полученные результаты свидетельствуют о потенциале FROST как универсального инструмента для повышения производительности языковых моделей в задачах, требующих сложных логических выводов и математических вычислений.
Исследования показали, что предложенный метод демонстрирует устойчивое повышение как точности, так и эффективности работы различных языковых моделей. В частности, даже модели меньшего размера, такие как Magistral-Small-1.1, значительно улучшают свои способности к логическому мышлению благодаря применению данной методики. Особенно заметным является снижение времени обработки — зафиксировано уменьшение на 28.6% по сравнению с другими базовыми моделями, прошедшими тонкую настройку (SFT). Это свидетельствует о потенциале данного подхода для оптимизации работы языковых моделей, делая их более быстрыми и точными в решении сложных задач, требующих логических рассуждений.
К надежным и эффективным рассуждениям
Механизм FROST демонстрирует способность эффективно отсекать непродуктивные этапы рассуждений, что открывает путь к значительному снижению вычислительных затрат и повышению масштабируемости языковых моделей. Вместо обработки всей цепочки логических шагов, FROST динамически определяет и исключает те, которые не вносят существенного вклада в конечный результат, тем самым оптимизируя процесс принятия решений. Этот подход особенно важен для решения сложных задач, требующих многоступенчатых рассуждений, поскольку позволяет значительно сократить время вычислений и потребление ресурсов, не жертвуя при этом точностью и надежностью ответов. В перспективе, подобная оптимизация может сделать более доступными и эффективными сложные AI-системы, способные решать широкий спектр интеллектуальных задач.
В дальнейшем планируется расширить область применения FROST на более сложные задачи, требующие рассуждений, такие как здравый смысл и логический вывод. Исследователи стремятся адаптировать существующий механизм отсечения неэффективных шагов рассуждений к сценариям, где необходимы не только фактические знания, но и способность к интуитивному пониманию мира и дедуктивным умозаключениям. Это включает в себя разработку новых метрик для оценки продуктивности шагов рассуждений в контексте этих задач и усовершенствование алгоритмов для более эффективного выявления и отсечения нерелевантных или ошибочных умозаключений. Успешная адаптация FROST к этим областям откроет новые возможности для создания более интеллектуальных и надежных систем искусственного интеллекта, способных решать широкий спектр задач, требующих сложных когнитивных способностей.
Технология FROST представляет собой значительный шаг к созданию надежных и эффективных систем искусственного интеллекта, благодаря уникальному сочетанию двух ключевых подходов. Эффективное отсечение непроизводительных шагов рассуждений позволяет существенно снизить вычислительные затраты и повысить масштабируемость языковых моделей. В сочетании с параметрически-эффективной тонкой настройкой, FROST обеспечивает возможность развертывания сложных AI-систем с минимальными ресурсами, не жертвуя при этом точностью и надежностью. Данный подход открывает перспективы для широкого применения искусственного интеллекта в различных областях, где важны как производительность, так и экономичность.
Исследование, представленное в данной работе, демонстрирует стремление к оптимизации сложных систем, что находит отклик в словах Кен Томпсона: «Простота — высшая степень изысканности». Методика FROST, направленная на отсечение некритичных шагов рассуждений посредством модифицированного механизма внимания (Softmax1), является ярким примером этого принципа. Удаляя избыточность, алгоритм не только повышает эффективность работы больших языковых моделей, но и приближается к идеалу компрессии без потерь, где каждая часть системы служит своей цели. В конечном итоге, FROST стремится к ясности и лаконичности, подобно тому, как опытный архитектор избавляется от всего лишнего, чтобы создать гармоничное и функциональное целое.
Что Дальше?
Представленный метод, хоть и демонстрирует улучшение эффективности рассуждений больших языковых моделей, лишь отодвигает проблему, а не решает её. Удаление «шума» в виде некритичных шагов — это, по сути, признание избыточности, присущей текущим архитектурам. Вопрос не в оптимизации существующего хаоса, а в создании моделей, изначально лишенных этой тенденции к многословию. Стремление к плотности смысла — новый минимализм — должно стать определяющим принципом, а не постфактум-коррекцией.
Особого внимания требует изучение природы этих самых «отклонений». Являются ли они результатом неточностей в обучении, недостаточной контекстуализации или фундаментальным ограничением способности модели к логическому выводу? Более глубокое понимание этих механизмов позволит перейти от поверхностного удаления «шума» к созданию моделей, способных к более последовательному и лаконичному рассуждению. Простое повышение скорости обработки информации — это иллюзия прогресса, если не сопровождается повышением качества логики.
В конечном счете, истинный прорыв заключается не в усовершенствовании существующих методов, а в пересмотре базовых принципов. Повторяющиеся попытки оптимизировать избыточность — это упражнение в тщеславии. Необходима парадигма, где ясность — это не результат оптимизации, а фундаментальное свойство модели. Иначе, мы обречены вечно убирать мусор, вместо того чтобы строить чистое пространство.
Оригинал статьи: https://arxiv.org/pdf/2601.19001.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовый оптимизатор: Новый подход к сложным задачам
- Кванты в Финансах: Не Шутка!
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Взлом языковых моделей: эволюция атак, а не подсказок
- Квантовый скачок из Андхра-Прадеш: что это значит?
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Искусственный интеллект на допросе: как объяснить решения в цифровой криминалистике?
2026-02-01 13:23