Автор: Денис Аветисян
В статье рассматривается адаптация архитектуры сервера параметров для эффективного обучения больших языковых моделей с использованием современных методов параллелизма данных.
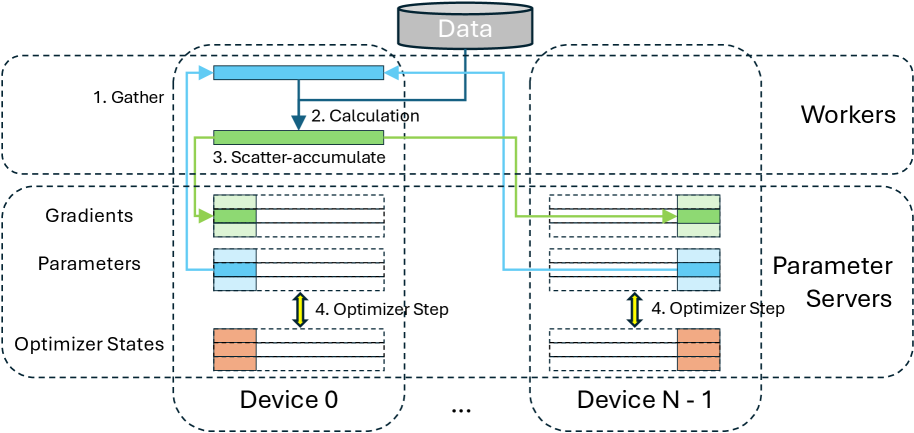
Предложена схема On-demand Communication (ODC) для снижения дисбаланса нагрузки и повышения пропускной способности при обучении больших языковых моделей с использованием шардированного параллелизма данных.
Несмотря на широкое распространение коллективных коммуникаций в распределенном обучении, их эффективность снижается при неравномерной нагрузке, характерной для дообучения больших языковых моделей (LLM). В работе ‘Revisiting Parameter Server in LLM Post-Training’ предложен новый подход, возвращающийся к архитектуре параметрических серверов, адаптированный для современных методов шардированного параллелизма данных. Ключевым элементом является схема On-Demand Communication (ODC), снижающая барьеры синхронизации и повышающая утилизацию устройств. Способно ли данное решение стать стандартом де-факто для дообучения LLM в условиях растущей гетерогенности вычислительных ресурсов?
Вызовы масштабирования больших языковых моделей
Современные большие языковые модели демонстрируют впечатляющие возможности в обработке и генерации текста, однако их обучение сталкивается с существенными трудностями, обусловленными необходимостью распределения вычислительной нагрузки между множеством устройств. Эта проблема проистекает из самой природы параллельных вычислений, где эффективное разделение задачи между доступными ресурсами является ключевым фактором. Несмотря на значительные успехи в области распределенных вычислений, обучение LLM требует координации огромного количества параметров и данных, что создает серьезные препятствия для масштабирования. Ограничения в пропускной способности сети, задержки при передаче данных и сложность синхронизации вычислений между устройствами приводят к снижению эффективности обучения и увеличению затрат, что становится критическим фактором при создании и развитии все более сложных моделей.
Неоднородность длины последовательностей в обучающих данных представляет собой серьезную проблему для масштабирования больших языковых моделей. В то время как некоторые примеры требуют минимальных вычислительных ресурсов, другие, содержащие значительно более длинные последовательности, оказываются крайне ресурсоемкими. Эта диспропорция создает значительный дисбаланс рабочей нагрузки между вычислительными узлами, что приводит к неэффективному использованию оборудования и, как следствие, к увеличению затрат на обучение. Поскольку время обучения определяется самым медленным узлом, неравномерное распределение нагрузки существенно замедляет процесс и ограничивает возможность параллельной обработки данных, препятствуя масштабированию моделей до необходимых размеров для достижения оптимальной производительности. Таким образом, решение проблемы дисбаланса рабочей нагрузки, вызванного переменной длиной последовательностей, является ключевым для снижения стоимости и повышения эффективности обучения больших языковых моделей.
Традиционные подходы к распределенному обучению, такие как параллелизм данных, сталкиваются с существенными трудностями при обработке неравномерной нагрузки, возникающей из-за различной длины последовательностей в обучающих данных. Вместо эффективного использования вычислительных ресурсов, эти методы часто приводят к тому, что часть оборудования простаивает, ожидая завершения обработки более длинных последовательностей, в то время как другие компоненты уже закончили свою работу. Это не только замедляет процесс обучения, но и значительно увеличивает его стоимость, поскольку необходимо поддерживать простаивающие ресурсы. В результате, масштабирование обучения больших языковых моделей становится проблематичным, требуя разработки новых стратегий, способных более эффективно балансировать нагрузку и оптимизировать использование доступных вычислительных мощностей.
Полностью шардированный параллелизм: эффективное решение для экономии памяти
Полностью шардированный параллелизм данных (FSDP) представляет собой эффективное решение для преодоления ограничений по памяти при обучении больших моделей. В отличие от традиционных подходов к параллелизму, FSDP распределяет параметры модели, градиенты и состояния оптимизатора между несколькими устройствами. Это означает, что каждое устройство хранит лишь часть полной модели, существенно снижая потребность в памяти на каждом отдельном устройстве. Шардирование позволяет обучать модели, которые в противном случае не поместились бы в память одного или даже нескольких GPU, открывая возможности для работы с моделями значительно большего размера и сложности.
Для эффективной синхронизации распределенных фрагментов параметров модели, градиентов и состояний оптимизатора в процессе обучения, FSDP использует коллективные коммуникационные операции, такие как all-gather и reduce-scatter. Операция all-gather позволяет каждому устройству собрать полные данные из всех остальных устройств, необходимые для вычисления градиентов или обновления параметров. Reduce-scatter, в свою очередь, выполняет агрегацию данных (например, суммирование градиентов) на всех устройствах и распределяет результат обратно, при этом каждое устройство получает только свою часть агрегированных данных. Эти операции оптимизированы для параллельного выполнения на множестве устройств, что минимизирует задержки и обеспечивает высокую пропускную способность обмена данными, необходимую для эффективного обучения масштабных моделей.
Использование Fully Sharded Data Parallel (FSDP) позволяет существенно снизить объем памяти, необходимый на каждом устройстве в процессе обучения. Это достигается за счет разделения параметров модели, градиентов и состояний оптимизатора между несколькими устройствами. Благодаря такому подходу, становится возможным обучение моделей, которые ранее были недоступны из-за ограничений по памяти, поскольку общий объем памяти, необходимый для обучения, распределяется между всеми участвующими устройствами. Это критически важно для обучения больших языковых моделей и других ресурсоемких нейронных сетей, где размер модели может превышать объем памяти одного GPU или сервера.

Коммуникация по требованию: переосмысление коллективных операций
Коммуникация по требованию (On-Demand Communication, ODC) представляет собой переход от традиционных коллективных коммуникаций, основанных на широковещательных вызовах типа all-gather/reduce-scatter, к более целенаправленной, межпроцессной передаче данных. Вместо одновременной передачи данных между всеми процессами, ODC фокусируется на отправке данных только тем процессам, которым они необходимы в конкретный момент времени. Это позволяет избежать избыточной передачи данных и снизить задержки, характерные для коллективных операций, особенно в сценариях распределенного обучения с большим количеством участников. Переход к модели point-to-point позволяет оптимизировать использование пропускной способности сети и вычислительных ресурсов, что приводит к повышению общей эффективности системы.
Для минимизации накладных расходов и повышения скорости обмена данными, On-Demand Communication (ODC) использует эффективные механизмы межпроцессного взаимодействия, такие как CUDA IPC, NVSHMEM и RDMA. CUDA IPC обеспечивает прямой доступ к памяти GPU между процессами, снижая задержки при передаче данных. NVSHMEM предоставляет унифицированную модель разделяемой памяти, оптимизированную для GPU, и позволяет эффективно реализовывать операции чтения и записи. RDMA (Remote Direct Memory Access) позволяет процессам напрямую обмениваться данными в памяти, минуя центральный процессор и значительно уменьшая нагрузку на него, что особенно важно для высокопроизводительных вычислений и распределенного обучения.
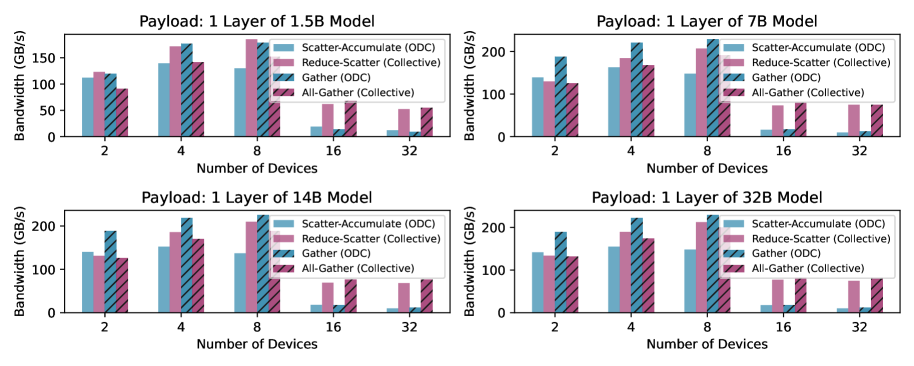
Переосмысление базовых принципов обмена данными позволяет On-Demand Communication (ODC) существенно снизить узкие места в коммуникации и ускорить распределенное обучение, в том числе при использовании архитектуры Parameter Server (PS). В результате применения ODC наблюдается увеличение пропускной способности до 36% по сравнению с традиционным Fully Sharded Data Parallel (FSDP). Это достигается за счет оптимизации передачи данных и минимизации задержек, что особенно важно при масштабировании обучения на большое количество узлов и больших моделях.
Влияние и перспективы развития
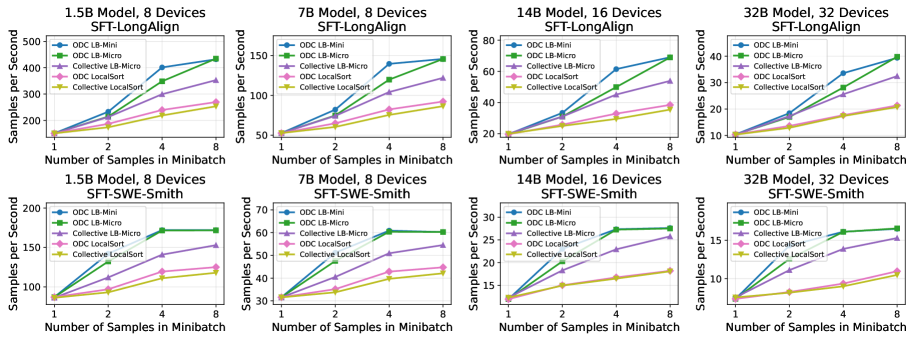
Оптимизированные методы распределенного обучения играют ключевую роль в расширении контекстных окон больших языковых моделей (LLM). Способность обрабатывать более длинные последовательности текста критически важна для решения сложных задач, требующих понимания дальних зависимостей. Это подтверждается результатами, полученными при использовании наборов данных, таких как LongAlign, специально разработанного для оценки производительности LLM при работе с увеличенными контекстными окнами. Успешное применение данных техник позволяет значительно повысить эффективность обучения, открывая путь к созданию моделей, способных к более глубокому и осмысленному анализу информации, а также к генерации более связных и релевантных текстов.
Разработка оптимизированных методов распределенного обучения открывает возможности для создания сложных моделей агентов, способных к решению разнообразных задач. В частности, использование наборов данных, таких как SWE-Smith, позволяет обучать агентов для выполнения сложных манипуляций и планирования действий в виртуальных средах. Применение алгоритмов обучения с подкреплением, в том числе GRPO, позволяет агентам совершенствовать свои стратегии посредством взаимодействия со средой и получения обратной связи. Такой подход обеспечивает не только повышение эффективности агентов, но и возможность их адаптации к новым, ранее не встречавшимся ситуациям, что является ключевым фактором для создания действительно интеллектуальных систем.
Гибридные методы шардинга значительно расширяют возможности FSDP, обеспечивая повышенную масштабируемость и эффективность при обучении больших языковых моделей. Эти техники позволяют распределять параметры модели и вычисления между несколькими устройствами, снижая требования к памяти каждого отдельного устройства. Ключевую роль в оптимизации микропакетов играют накопление градиентов и упаковка последовательностей. Накопление градиентов позволяет эмулировать большие размеры пакетов, не увеличивая потребление памяти, а упаковка последовательностей повышает эффективность использования вычислительных ресурсов за счет обработки нескольких коротких последовательностей одновременно. Сочетание этих подходов позволяет достичь существенного прироста производительности при обучении моделей, требующих больших объемов данных и вычислительных ресурсов.
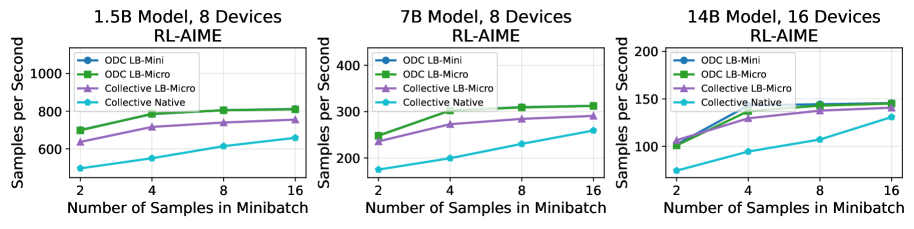
Оптимизация данных и вычислений (ODC) демонстрирует значительное повышение эффективности обучения больших языковых моделей. Исследования показывают, что применение ODC позволяет добиться увеличения скорости обработки данных до 10% при обучении с подкреплением, используя 14-миллиардную модель. Более того, как наглядно представлено на Рисунке 8, ODC обеспечивает стабильное улучшение пропускной способности при работе с наборами данных для обучения с учителем (SFT), такими как LongAlign и SWE-Smith, при использовании 32-миллиардной модели. Данные результаты подтверждают, что ODC является перспективным подходом для ускорения обучения масштабных моделей и повышения их производительности в различных задачах машинного обучения.
Исследование, представленное в данной работе, акцентирует внимание на адаптации архитектуры Parameter Server к современным методам шардированного параллелизма данных. Этот подход направлен на смягчение дисбаланса рабочей нагрузки, что особенно актуально при пост-тренинге больших языковых моделей. В стремлении к оптимизации использования ресурсов и увеличению пропускной способности, авторы предлагают схему On-demand Communication (ODC). Как точно подметила Грейс Хоппер: «Лучший способ предсказать будущее — создать его». Подобно тому, как предвидение и активное формирование будущего позволяет создавать эффективные системы, так и представленное исследование стремится к созданию более адаптивной и эффективной инфраструктуры для обучения моделей, способной противостоять вызовам, связанным с масштабируемостью и дисбалансом нагрузки.
Куда же дальше?
Представленные в данной работе модификации архитектуры Parameter Server, направленные на адаптацию к фрагментированному параллелизму данных, лишь отсрочивают неизбежное. Все системы стареют, и данная, несомненно, тоже. Проблема дисбаланса нагрузки, хотя и смягчается предложенной схемой On-demand Communication, по сути, является симптомом более глубокой болезни — неспособности существующих моделей масштабироваться без экспоненциального увеличения коммуникационных издержек. Стабильность — это иллюзия, кэшированная временем, и каждый запрос платит налог задержки.
Будущие исследования, вероятно, будут сосредоточены не на оптимизации существующих коммуникационных схем, а на радикальном переосмыслении принципов распределенных вычислений. Возможно, стоит обратить внимание на архитектуры, вдохновленные биологическими системами, где информация распространяется не по жестко заданным каналам, а посредством самоорганизующихся сетей. Или же на модели, в которых вычисления приближаются к данным, а не наоборот.
Не стоит забывать, что время — это не метрика, а среда, в которой существуют системы. Любая оптимизация — временна. Задача не в том, чтобы создать идеальную систему, а в том, чтобы создать систему, способную достойно стареть, адаптируясь к меняющимся условиям и извлекая уроки из собственной несовершенности.
Оригинал статьи: https://arxiv.org/pdf/2601.19362.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сердце музыки: открытые модели для создания композиций
- Эмоциональный отпечаток: Как мы научили ИИ читать душу (и почему рейтинги вам врут)
- Квантовый скачок из Андхра-Прадеш: что это значит?
- LLM: математика — предел возможностей.
- Волны звука под контролем нейросети: моделирование и инверсия в вязкоупругой среде
- Почему ваш Steam — патологический лжец, и как мы научили компьютер читать между строк
2026-01-28 06:47