Автор: Денис Аветисян
Новый подход к выбору эпизодов в алгоритмах Монте-Карло позволяет значительно ускорить обучение и повысить качество стратегий.
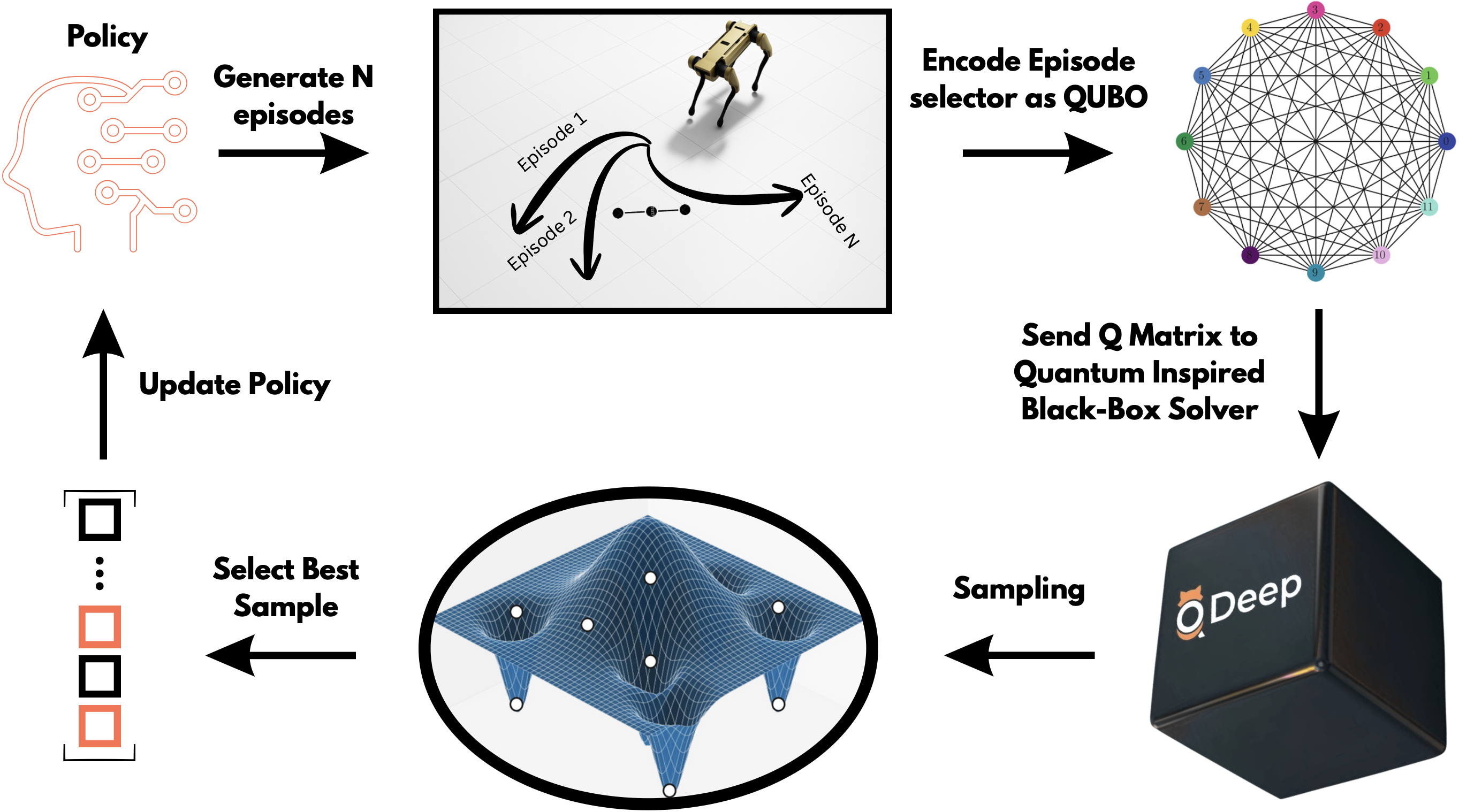
В статье демонстрируется интеграция оптимизации на основе QUBO в обучение с подкреплением Монте-Карло для улучшения скорости сходимости, качества стратегий и стабильности, особенно в сложных средах.
Обучение с подкреплением методом Монте-Карло часто сталкивается с проблемой высокой вычислительной сложности, особенно в средах с разреженным вознаграждением и большими пространствами состояний. В статье «Quantum-Inspired Episode Selection for Monte Carlo Reinforcement Learning via QUBO Optimization» предложен новый подход, основанный на формулировке задачи выбора эпизодов в виде задачи квадратичной неограниченной двоичной оптимизации (QUBO) и решении ее с помощью квантово-вдохновленных алгоритмов. Показано, что интеграция QUBO-основанного выбора эпизодов в стандартный алгоритм Монте-Карло позволяет ускорить сходимость и улучшить качество получаемой политики. Способны ли квантово-вдохновленные методы оптимизации стать эффективным инструментом для повышения производительности алгоритмов обучения с подкреплением в сложных задачах?
В поисках оптимального решения: вызовы современной оптимизации
Многие задачи, с которыми сталкиваются современные технологии и промышленность, требуют решения сложных задач оптимизации. От планирования логистических маршрутов и управления цепочками поставок до обучения моделей машинного обучения и разработки финансовых стратегий — все они сводятся к поиску наилучшего решения среди огромного числа возможных вариантов. Например, задача коммивояжера, поиск кратчайшего маршрута посещения нескольких городов, или оптимизация параметров нейронной сети для достижения максимальной точности — это лишь некоторые примеры. Сложность заключается в экспоненциальном росте числа возможных решений с увеличением масштаба задачи, что делает перебор всех вариантов невозможным даже для современных вычислительных систем. Поэтому разработка эффективных алгоритмов оптимизации является ключевым направлением исследований в различных областях науки и техники.
Традиционные методы оптимизации, несмотря на свою устоявшуюся эффективность в решении узкоспециализированных задач, часто сталкиваются с существенными трудностями при работе с пространствами решений, экспоненциально растущими в размерах. Это связано с тем, что полный перебор всех возможных вариантов становится вычислительно невозможным даже при умеренном увеличении числа переменных или ограничений. Например, задача маршрутизации транспортного парка с десятками автомобилей и сотнями точек доставки требует оценки огромного числа комбинаций, что приводит к неприемлемым временным затратам. Вследствие этого, традиционные алгоритмы, такие как линейное программирование или методы ветвей и границ, теряют свою масштабируемость и эффективность, ограничивая их применимость к реальным задачам, требующим обработки больших объемов данных и принятия решений в условиях ограниченных ресурсов.
Классические подходы к оптимизации: от Изинга до облачных вычислений
Модель Изинга представляет собой базовую структуру для представления комбинаторных задач оптимизации, использующих бинарные переменные. В данной модели, каждая переменная может принимать одно из двух значений — +1 или -1, что соответствует спину в физической системе. Задача оптимизации формулируется как минимизация энергии системы, определяемой взаимодействием между переменными и внешними полями. E = -J\sum_{\langle i,j \rangle} s_i s_j - h\sum_i s_i, где J — константа взаимодействия, h — внешнее поле, а s_i — значение i-ой переменной. Такая формулировка позволяет моделировать широкий спектр задач, включая задачи о покрытии множества, задачи о раскраске графов и другие комбинаторные задачи, сводя их к поиску минимальной энергии в системе Изинга.
Методы, такие как симулированный бифуркационный анализ и симулированный отжиг, представляют собой классические алгоритмы, предназначенные для решения задач комбинаторной оптимизации, вдохновленные физическими процессами. Симулированный отжиг моделирует процесс охлаждения материала для достижения состояния с минимальной энергией, а симулированный бифуркационный анализ имитирует переход системы через точку бифуркации, позволяя исследовать различные решения и находить оптимальные. Оба подхода используют вероятностные методы для избежания локальных минимумов и поиска глобального оптимума, применяя принципы статистической механики и термодинамики к задачам оптимизации.
Методы, такие как симулированный бифуркационный анализ и симулированный квантовый отжиг, используют облачную платформу Qonquester для выполнения и ускорения процессов оптимизации. Qonquester предоставляет масштабируемые вычислительные ресурсы, необходимые для обработки сложных комбинаторных задач, представленных, например, моделью Изинга. Использование облака позволяет значительно сократить время вычислений по сравнению с локальными решениями, особенно при увеличении размера и сложности оптимизируемой задачи. Платформа обеспечивает доступ к специализированному оборудованию и оптимизированным алгоритмам, что повышает эффективность и производительность процессов оптимизации.

Обучение с подкреплением: новый взгляд на адаптивную оптимизацию
Обучение с подкреплением (RL) представляет собой принципиально новый подход к оптимизации, в котором агент не программируется явно, а самостоятельно вырабатывает оптимальную стратегию принятия решений посредством взаимодействия со средой. В отличие от традиционных методов, требующих предварительного определения оптимальных действий, RL позволяет агенту исследовать пространство состояний и действий, получая вознаграждение или штраф за каждое действие. Этот процесс итеративного обучения позволяет агенту адаптироваться к динамически меняющимся условиям и находить решения, которые максимизируют суммарное вознаграждение в долгосрочной перспективе. Такой подход особенно эффективен в задачах, где явное определение оптимальной стратегии затруднено или невозможно из-за сложности среды или отсутствия полной информации.
Метод обучения с подкреплением Монте-Карло, в сочетании с аппроксимацией функции ценности, позволяет оценивать ценность различных состояний и действий в процессе обучения агента. Вместо точного перебора всех возможных состояний, аппроксимация функции ценности использует обобщенные представления, такие как нейронные сети или линейные модели, для предсказания ожидаемой совокупной награды, получаемой при нахождении в определенном состоянии и выполнении конкретного действия. Это особенно важно в задачах с большим или непрерывным пространством состояний, где полный перебор невозможен. Оценка производится на основе усредненных результатов множества эпизодов, где агент взаимодействует со средой, и функция ценности корректируется для повышения точности предсказаний.
Эффективный отбор эпизодов обучения играет ключевую роль в процессе обучения с подкреплением. Стратегии, такие как Reward-Independent Selection (RIS), позволяют улучшить стабильность и скорость сходимости алгоритма. RIS предполагает выбор эпизодов на основе критериев, не связанных напрямую с немедленной наградой, например, на основе разнообразия посещенных состояний или длительности эпизода. Это позволяет агенту исследовать более широкий спектр возможностей и избегать застревания в локальных оптимумах, даже при наличии разреженных или зашумленных сигналов вознаграждения. Применение RIS особенно эффективно в задачах, где немедленная награда не является надежным индикатором долгосрочной эффективности действий агента.
Баланс между исследованием и использованием: влияние на обучение с подкреплением
Выбор стратегии отбора эпизодов оказывает существенное влияние на способность агента обучаться и обобщать полученный опыт на новые, ранее не встречавшиеся проблемные ситуации. Эффективный отбор эпизодов позволяет агенту целенаправленно исследовать наиболее информативные области пространства состояний, избегая зацикливания на малопродуктивных траекториях. Неудачно выбранная стратегия может привести к неполному исследованию пространства решений и, как следствие, к формированию неоптимальной политики, неспособной адаптироваться к изменениям в окружающей среде. Таким образом, грамотный подход к отбору эпизодов является ключевым фактором для достижения высокой производительности и надежности агента в различных условиях, обеспечивая его способность к эффективному обучению и обобщению.
Эффективное исследование пространства состояний является фундаментальным требованием для успешного обучения агента в рамках обучения с подкреплением. Недостаточное покрытие пространства состояний может привести к застреванию в локальных оптимумах и, как следствие, к субоптимальным решениям. Агент, ограничивающий себя в исследовании, упускает из виду потенциально выгодные области, что снижает его способность к обобщению и адаптации к новым, ранее не встречавшимся ситуациям. Поэтому, стратегии, направленные на максимизацию посещения различных состояний, играют ключевую роль в обеспечении надежности и эффективности алгоритмов обучения с подкреплением, позволяя агенту полноценно освоить сложный ландшафт задачи и находить оптимальные стратегии поведения.
Исследования показали, что внедрение отбора эпизодов на основе квадратичной неограниченной двоичной оптимизации (QUBO) в алгоритмы обучения с подкреплением методом Монте-Карло последовательно повышает скорость сходимости и качество получаемой политики. Данный подход позволяет агенту более эффективно исследовать пространство состояний, фокусируясь на эпизодах, которые наиболее информативны для улучшения стратегии принятия решений. QUBO-основанный отбор эпизодов формирует бинарный вектор, представляющий выбор эпизодов, оптимизируя его для максимизации вознаграждения и минимизации неопределенности, что приводит к более быстрому обучению и более надежной политике даже в сложных средах. Экспериментальные результаты демонстрируют значительное улучшение производительности по сравнению с традиционными методами отбора эпизодов, подтверждая эффективность предложенного подхода.
Пределы вычислений: сложность задач и поиск альтернатив
Проблема Min-QUBO, являющаяся фундаментальной частью формулировки QUBO, относится к классу NP-трудных задач. Это означает, что на данный момент не существует алгоритма, способного решить её за полиномиальное время — то есть, время решения растет не быстрее, чем полином от размера входных данных. По сути, сложность этой задачи возрастает экспоненциально с увеличением числа переменных, что делает точное решение практически невозможным для больших экземпляров. Данное ограничение не является уникальным для Min-QUBO; многие важные задачи оптимизации и комбинаторики также принадлежат к классу NP-трудных, что подчеркивает необходимость разработки альтернативных подходов, таких как эвристики и приближенные алгоритмы, для получения приемлемых решений в разумные сроки.
Внутренняя сложность задач оптимизации, ярко демонстрируемая классической проблемой о разбиении множества на подмножества с равной суммой, обуславливает необходимость применения эвристических методов и алгоритмов приближённого решения. Полный перебор вариантов для таких задач становится невозможным при увеличении их масштаба, поскольку время вычислений растёт экспоненциально. Вместо поиска оптимального решения, эвристики направлены на нахождение «достаточно хорошего» результата за приемлемое время, а алгоритмы приближения гарантируют, что найденное решение отличается от оптимального не более чем на заданную величину. Такой подход позволяет эффективно решать сложные оптимизационные задачи, даже если точное решение недостижимо, что особенно актуально в контексте комбинаторной оптимизации и машинного обучения.
Представленный подход к выбору эпизодов, основанный на QUBO-формулировке, демонстрирует впечатляющую скорость решения задач. Эксперименты показали, что время обработки одного пакета данных (batch) для n, не превышающего 200, составляет всего 0.5-2 секунды, при этом фактическое время работы решателя (solver) составляет лишь 10-100 миллисекунд. Эти результаты указывают на перспективность использования QUBO-моделирования для оптимизации сложных задач и открывают возможности для разработки более эффективных алгоритмов, способных справляться с возрастающими объемами данных и требованиями к скорости вычислений. Данная оптимизация позволяет значительно ускорить процесс выбора оптимальных эпизодов, что особенно важно в динамически меняющихся условиях.
Исследование демонстрирует, что оптимизация выбора эпизодов посредством QUBO значительно ускоряет сходимость алгоритмов обучения с подкреплением, особенно в сложных средах. Это напоминает о важности архитектуры систем и их способности адаптироваться к изменениям. Как однажды заметил Клод Шеннон: «Теория коммуникации измеряет, что можно, и не более того». Применительно к данной работе, это означает, что эффективность обучения напрямую зависит от грамотной организации процесса выбора эпизодов — от того, насколько эффективно система ‘коммуницирует’ с окружающей средой, выбирая наиболее информативные данные для обучения. Архитектура выбора эпизодов, лишенная исторической перспективы и оптимизации, подобна хрупкой конструкции, обреченной на скорое разрушение под давлением сложности решаемой задачи.
Что дальше?
Представленная работа демонстрирует ускорение сходимости обучения с подкреплением посредством оптимизации выбора эпизодов на основе QUBO. Однако, следует признать, что любое улучшение, каким бы элегантным оно ни казалось, подвержено старению. Скорость, с которой эффективность подобного подхода снизится в еще более сложных средах, остается вопросом эмпирической проверки. Ведь, по сути, откат — это лишь путешествие назад по стрелке времени, и неминуемо наступит момент, когда первоначальный импульс иссякнет.
Будущие исследования должны быть направлены не только на масштабирование предложенного метода, но и на поиск механизмов адаптации к изменяющимся условиям. Использование QUBO, как инструмента выбора эпизодов, может оказаться лишь временным решением, требующим постоянной переоценки и, возможно, замены на более устойчивые подходы. Важно помнить, что сама оптимизация — это лишь попытка замедлить энтропию, а не остановить ее.
В конечном счете, истинный прогресс заключается не в создании все более сложных алгоритмов, а в понимании фундаментальных ограничений, накладываемых временем на любые системы. Любая система стареет — вопрос лишь в том, насколько достойно она это делает. Изучение способов продления «жизни» подобного подхода, а не просто его ускорения, представляется более перспективной задачей.
Оригинал статьи: https://arxiv.org/pdf/2601.17570.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-27 12:16