Автор: Денис Аветисян
Новый подход позволяет автоматически выявлять ключевые темы и смыслы в больших объемах текста, открывая возможности для глубокого анализа политического дискурса.
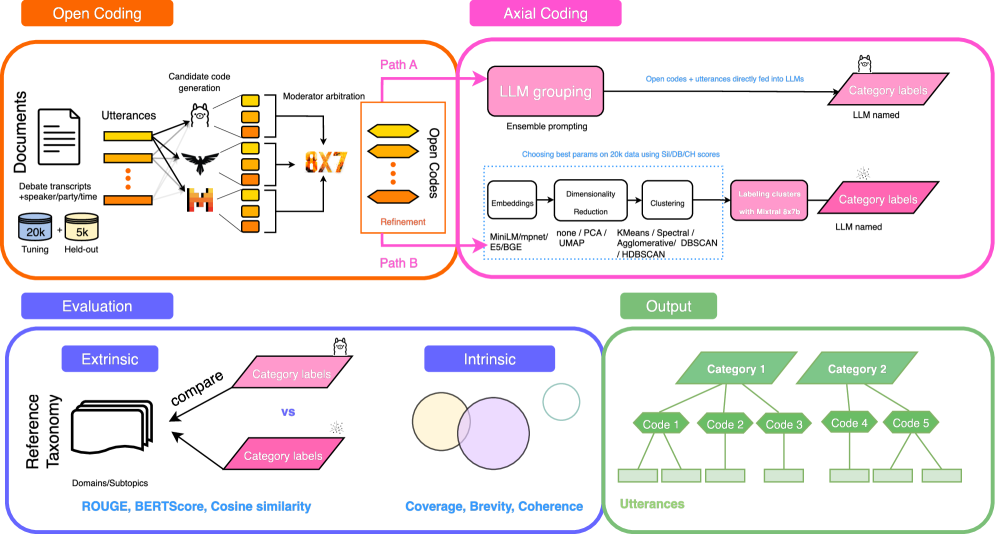
Исследование применяет ансамбль больших языковых моделей и методы кластеризации для автоматизации этапов открытого и аксиального кодирования качественных данных.
Качественный анализ больших текстовых корпусов, таких как стенограммы парламентских дебатов, традиционно требует значительных трудозатрат. В статье ‘From Quotes to Concepts: Axial Coding of Political Debates with Ensemble LMs’ предложен подход к автоматизации осевой кодировки, ключевого метода качественного анализа, с использованием ансамбля больших языковых моделей и алгоритмов кластеризации. Полученные результаты демонстрируют, что комбинация кластеризации эмбеддингов и прямого кодирования LLM позволяет эффективно преобразовывать сырые транскрипты в иерархически структурированные коды и категории, при этом наблюдается компромисс между охватом и детализацией. Какие перспективы открываются для дальнейшей автоматизации и масштабирования методов качественного анализа политического дискурса с помощью современных языковых моделей?
От ручного кодирования к автоматизированному анализу: вызовы качественного анализа
Традиционный метод качественного кодирования текстовых данных, предполагающий ручную маркировку и категоризацию отрывков, является чрезвычайно трудоемким процессом. Значительные временные затраты обусловлены необходимостью внимательного прочтения и интерпретации каждого фрагмента текста. Более того, субъективность исследователя неизбежно влияет на процесс кодирования, приводя к различиям в интерпретации и, как следствие, к неоднозначности результатов. Эта предвзятость может существенно ограничить возможность получения надежных и воспроизводимых выводов, особенно при анализе больших объемов информации. В итоге, традиционные методы часто оказываются препятствием для выявления закономерностей и получения глубоких знаний из текстовых данных в масштабе, необходимом для современных исследований и практических приложений.
В настоящее время наблюдается экспоненциальный рост объемов текстовых данных, генерируемых различными источниками — от социальных сетей и онлайн-форумов до научных публикаций и корпоративной документации. Этот колоссальный поток информации делает традиционные методы качественного анализа, требующие ручной обработки и интерпретации, практически нереализуемыми в масштабе. Необходимость в автоматизированных подходах к тематическому анализу становится все более острой, поскольку они позволяют эффективно обрабатывать большие объемы текста, выявлять ключевые темы и закономерности, а также обеспечивать более надежные и воспроизводимые результаты, что критически важно для принятия обоснованных решений в различных областях, начиная от маркетинга и заканчивая научными исследованиями.
Существующие методы автоматического анализа текста, несмотря на прогресс в области искусственного интеллекта, зачастую испытывают трудности с распознаванием тонких смысловых оттенков и контекстуальных нюансов. Это требует значительного вмешательства человека для проверки и корректировки результатов, что существенно ограничивает их применимость при обработке больших объемов данных. Неспособность алгоритмов адекватно учитывать идиоматические выражения, сарказм или иные формы непрямого выражения мысли приводит к ошибкам в категоризации и интерпретации информации. В результате, несмотря на стремление к автоматизации, процесс анализа остается трудоемким и требует квалифицированных специалистов для обеспечения достоверности и точности полученных выводов.

Открытое кодирование на основе LLM: новый подход к анализу
Предлагаемый фреймворк для открытого кодирования основан на использовании ансамбля больших языковых моделей (LLM) для автоматической генерации начальных кодов из текстовых данных. Вместо использования одной LLM, система применяет несколько моделей параллельно, каждая из которых интерпретирует текст и предлагает собственные варианты кодирования. Этот подход позволяет охватить более широкий спектр возможных интерпретаций и повысить надежность процесса кодирования за счет агрегации результатов, полученных от разных моделей. Автоматизация начальной фазы кодирования значительно ускоряет процесс анализа качественных данных и позволяет исследователям сосредоточиться на более глубокой интерпретации полученных результатов.
В основе предложенного подхода лежит Модераторская LLM, выполняющая функцию арбитра между результатами, генерируемыми различными языковыми моделями. Эта модель оценивает сгенерированный код по критериям разнообразия и качества, отбирая наиболее релевантные и эффективные решения. Оценка включает в себя анализ синтаксической корректности, семантической значимости и потенциальной эффективности кода, что позволяет формировать более широкий и надежный набор исходных кодов для дальнейшего качественного анализа. Использование Модераторской LLM обеспечивает снижение рисков, связанных с предвзятостью или ограничениями, свойственными отдельным языковым моделям, и способствует созданию более полного представления о возможном кодовом пространстве.
Использование ансамбля больших языковых моделей (LLM) позволяет преодолеть ограничения, присущие применению единственной модели для генерации кода. Вместо получения единственного варианта решения, предлагаемый подход создает более широкое и разнообразное пространство кодовых решений. Это достигается за счет параллельной генерации кода несколькими LLM, каждая из которых может предложить уникальную перспективу и подход к решению задачи. В результате формируется более полная и репрезентативная кодовая база, включающая различные стили кодирования, алгоритмы и структуры данных, что повышает вероятность обнаружения оптимального или наиболее подходящего решения для конкретной задачи.
Автоматизация начальной фазы кодирования данных позволяет существенно снизить временные и трудовые затраты на последующий качественный анализ. Традиционно, кодирование требует значительного ручного труда, особенно при работе с большими объемами текстовой информации. Наша система, автоматизируя этот этап, высвобождает ресурсы исследователей для более глубокой интерпретации результатов и выявления закономерностей. Сокращение времени, затрачиваемого на рутинные операции кодирования, позволяет быстрее перейти к фазе анализа и синтеза данных, что повышает общую эффективность исследования и сокращает сроки получения результатов.
Структурирование кодового пространства: от фрагментов к темам
Для структурирования кодовой базы применялись различные методы аксиального кодирования, включая неконтролируемую кластеризацию с использованием алгоритма HDBSCAN и прямое группирование на основе больших языковых моделей (LLM). HDBSCAN позволяет автоматически выявлять кластеры в данных, не требуя предварительной информации о количестве или структуре этих кластеров. Параллельно исследовалось применение LLM для непосредственного определения тематических групп кодовых фрагментов, что предоставляет альтернативный подход к организации кодовой базы без необходимости в предварительном обучении или настройке параметров кластеризации.
Для представления кодов и обеспечения вычисления их семантической близости в рамках как кластерного, так и основанного на больших языковых моделях (LLM) подходов, используются SBERT-вложения (embeddings). SBERT позволяет преобразовать текстовые коды в векторные представления фиксированной длины, что облегчает количественную оценку их сходства посредством таких метрик, как косинусное расстояние. Полученные векторные представления служат основой для алгоритмов кластеризации, таких как HDBSCAN, а также для LLM-методов, позволяя эффективно группировать семантически близкие коды и выявлять темы в данных.
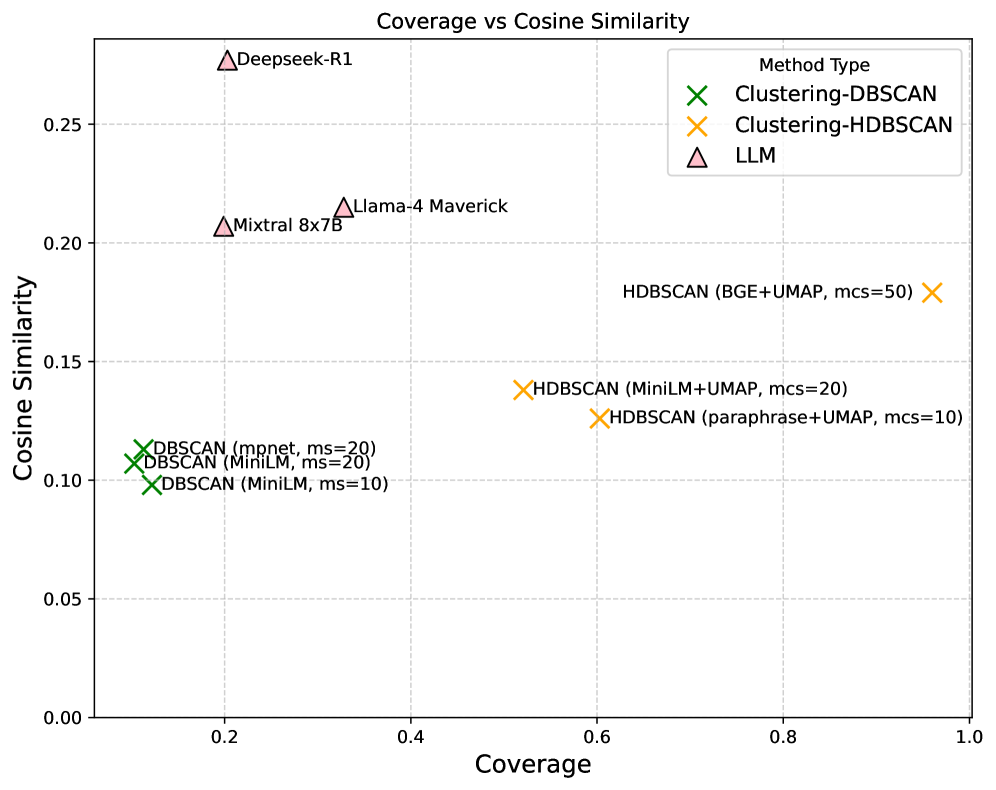
При использовании алгоритма HDBSCAN для кластеризации кодов, в сочетании с векторными представлениями, полученными посредством модели BGE, и последующим снижением размерности с помощью UMAP, достигнуто покрытие 96% всех речевых фрагментов (utterances). При этом, оценка качества кластеризации, полученная с помощью метрики BERTScore, составила 0.867. Данный результат демонстрирует высокую эффективность предложенного подхода в автоматической организации кодов и обеспечении практически полного охвата данных при сохранении высокого уровня семантической согласованности внутри кластеров.
Эксперименты с моделью Deepseek-R1 показали результаты в 0.248 по метрике ROUGE-L и 0.328 по косинусной мере сходства при оценке качества сгенерированных категорий на уровне субтем. Данные показатели свидетельствуют об эффективности модели в автоматической классификации и выделении тематических блоков из текстовых данных, демонстрируя её способность к генерации релевантных и когерентных категорий.
В ходе экспериментов было выявлено компромиссное соотношение между охватом данных и соответствием внешним критериям оценки. Метод Deepseek-R1 продемонстрировал значительно более низкий охват (20%) по сравнению с HDBSCAN, который обеспечил покрытие 96% всех высказываний. Это указывает на то, что HDBSCAN способен более полно классифицировать все доступные данные, в то время как Deepseek-R1 фокусируется на более узком наборе тем, возможно, с большей степенью согласованности с заранее определенными категориями, но за счет снижения общего охвата.
Валидация и интерпретация результатов: практическое применение системы
Для оценки качества сформированных категорий применялся комплексный подход, включающий как внешние, так и внутренние метрики. Внешние метрики, такие как ROUGE и BERTScore, позволили сопоставить автоматически сгенерированные категории с эталонными метками, созданными экспертами, тем самым подтвердив точность метода. Внутренние метрики, в свою очередь, оценивали когерентность и осмысленность категорий, основываясь на их внутренней структуре и взаимосвязях между элементами. Сочетание этих двух типов оценок обеспечило всесторонний анализ и позволило получить надежную оценку эффективности предложенного подхода к автоматическому качественному анализу.
Для подтверждения точности разработанного метода автоматической категоризации использовалась внешняя оценка, включающая метрики ROUGE и BERTScore. Эти метрики позволяют сопоставить автоматически сгенерированные категории с категориями, присвоенными экспертами-людьми, тем самым количественно оценивая степень соответствия. ROUGE оценивает перекрытие n-грамм между автоматически сгенерированным текстом и эталонными категориями, а BERTScore использует контекстуализированные векторные представления слов, полученные с помощью модели BERT, для более точного измерения семантического сходства. Высокие значения этих метрик свидетельствуют о том, что метод способен генерировать категории, которые тесно соответствуют человеческому пониманию и классификации данных.
Исследование продемонстрировало, что модель Deepseek-R1 показала наименьшее расхождение с агрегированным пространством кодов, что было количественно оценено с помощью метрики Jensen-Shannon Distance (JSD). Полученное значение JSD, равное 0.134, указывает на высокую степень соответствия между представлением, сформированным моделью, и общим пространством кодирования данных. Это свидетельствует о способности модели эффективно захватывать и воспроизводить основные характеристики исходной информации, обеспечивая тем самым более точное и надежное представление данных в процессе автоматического качественного анализа. Низкое значение JSD подтверждает, что модель генерирует категории, близкие к тем, которые были бы созданы человеком, что является важным показателем ее эффективности.
Исследование продемонстрировало практическую применимость и надёжность разработанного автоматизированного конвейера качественного анализа на материалах дебатов в Нидерландском парламенте. Анализ дискуссий, представленных в виде текстовых данных, позволил оценить эффективность предложенного метода в извлечении ключевых тем и определении позиций участников. Полученные результаты свидетельствуют о способности системы автоматически обрабатывать большие объемы текстовой информации и выделять значимые аспекты парламентских дискуссий, что открывает возможности для более глубокого изучения политических процессов и общественного мнения. Данный подход может быть использован для анализа широкого спектра текстовых данных, представляющих интерес для политических наук, социологии и других гуманитарных дисциплин.
Исследование демонстрирует, что масштабируемость качественного анализа политических дебатов напрямую зависит не от вычислительной мощности, а от четкости и ясности идей, лежащих в основе методологии. Как отмечал Пол Эрдёш: «Математика — это искусство видеть невидимое». Этот принцип применим и к анализу больших текстовых корпусов: необходимо уметь выделять ключевые концепции и связи между ними, чтобы понять общую картину. Предложенный подход, комбинирующий ансамбль больших языковых моделей с кластеризацией и прямым группированием на основе LLM, позволяет эффективно проводить как открытое, так и осевое кодирование, выявляя закономерности в политическом дискурсе и создавая структурированное представление данных.
Что дальше?
Представленная работа, стремясь к масштабированию качественного анализа политических дискурсов, неизбежно обнажает границы применимости автоматизированных подходов. Элегантность предложенной архитектуры — в объединении возможностей ансамбля больших языковых моделей и методов кластеризации — становится очевидной лишь при столкновении с неоднозначностью и контекстуальной зависимостью политического языка. Очевидно, что автоматическое выявление и кодирование концепций, даже с использованием передовых моделей, требует постоянной калибровки и валидации экспертами — живая система не терпит упрощений.
Перспективные направления исследований лежат в области повышения устойчивости моделей к манипуляциям и предвзятостям, присущим политическому дискурсу. Необходимо развивать методы, позволяющие не просто группировать высказывания по ключевым словам, но и понимать скрытые смыслы, иронию и сарказм. Успех, вероятно, придет через углубленное изучение взаимосвязи между структурой текста и его интерпретацией — архитектура поведения проявляется в деталях.
Хорошая архитектура незаметна, пока не ломается, и только тогда видна настоящая цена решений. Дальнейшее развитие методов автоматического качественного анализа должно быть направлено не только на увеличение скорости и масштаба, но и на повышение прозрачности и надежности получаемых результатов — в конечном итоге, задача состоит не в замене исследователя, а в усилении его возможностей.
Оригинал статьи: https://arxiv.org/pdf/2601.15338.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Кванты в Финансах: Не Шутка!
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-25 23:09