Автор: Денис Аветисян
Новая система позволяет преобразовывать научные концепции в полные статьи, значительно ускоряя процесс исследований и открытий.

Представлен фреймворк Idea2Story, использующий предварительно вычисленные знания и агентов на основе больших языковых моделей для автоматизированного создания научных нарративов.
Несмотря на значительный прогресс в автоматизированном научном открытии на базе больших языковых моделей, существующие системы часто сталкиваются с вычислительными ограничениями и нестабильностью результатов. В данной работе представлена система ‘Idea2Story: An Automated Pipeline for Transforming Research Concepts into Complete Scientific Narratives’, предлагающая принципиально новый подход, основанный на предварительном вычислении и структурировании научных знаний в виде графа. Такой подход позволяет агентам, использующим LLM, эффективно извлекать и использовать готовые исследовательские шаблоны, значительно снижая вычислительные затраты и повышая надежность генерируемых научных нарративов. Может ли предварительное конструирование знаний стать основой для масштабируемого и достоверного автоматизированного научного открытия?
За гранью вычислений: вызовы автономных исследований
Современные агенты, основанные на больших языковых моделях (LLM), такие как SWE-Agent и OpenHands, демонстрируют ограниченные возможности при решении сложных исследовательских задач. Основная проблема заключается в недостаточной способности к логическому выводу и пониманию взаимосвязей между различными элементами задачи. Эти агенты часто испытывают трудности с выявлением скрытых зависимостей, определением приоритетов и планированием последовательности действий, необходимых для достижения поставленной цели. Несмотря на впечатляющие успехи в генерации текста и ответов на вопросы, им пока не хватает критического мышления и способности к абстракции, что ограничивает их возможности в области научных исследований, требующих глубокого анализа и синтеза информации. В результате, даже относительно сложные задачи могут оказаться за пределами их компетенции, что подчеркивает необходимость разработки новых подходов к созданию интеллектуальных агентов для автоматизации научных открытий.
Современные исследовательские агенты, основанные на больших языковых моделях, часто полагаются на вычисления в реальном времени для решения сложных задач. Этот подход, характерный для направления Runtime-Centric Research, создает существенные узкие места и снижает общую эффективность работы. Вместо использования накопленных знаний и предварительных расчетов, система вынуждена каждый раз заново анализировать данные и выполнять сложные операции непосредственно в процессе исследования. Это приводит к замедлению работы, увеличению потребления ресурсов и ограничению масштабируемости, поскольку скорость выполнения ограничена вычислительными возможностями в текущий момент времени. Таким образом, зависимость от вычислений в реальном времени препятствует развитию автономных исследовательских агентов, способных к быстрому и эффективному решению сложных научных задач.
Ограниченность контекстного окна, присущая современным большим языковым моделям (LLM), существенно затрудняет их способность эффективно использовать долгосрочные зависимости и накопленные знания. Этот фактор становится критическим препятствием при решении сложных исследовательских задач, требующих анализа обширных массивов данных и выявления взаимосвязей между отдаленными элементами информации. Модели, сталкиваясь с необходимостью обработки данных, превышающих размер контекстного окна, вынуждены либо усекать информацию, теряя важные детали, либо прибегать к сложным и ресурсоемким методам сегментации и повторной обработки. В результате, способность LLM к комплексному анализу и генерации новых знаний значительно снижается, ограничивая их потенциал в автоматизированных исследованиях и требуя разработки инновационных подходов к управлению и расширению контекстного окна.
Выращивание знаний: от идеи к истории
Подход Idea2Story решает проблему сложности и избыточности информации, разделяя процессы построения базы знаний и генерации результатов поиска. Отделение этих этапов позволяет предварительно обработать и структурировать научную информацию в автономном режиме, создавая готовую к использованию базу знаний. Это позволяет снизить вычислительные затраты во время онлайн-поиска и повысить эффективность работы с научными данными, поскольку система не тратит ресурсы на повторную обработку информации во время каждого запроса.
Процесс конструирования знаний начинается с извлечения повторно используемых Методических Блоков (Method Units) из научной литературы. Эти блоки представляют собой стандартизированные описания методологических подходов, протоколов и процедур, применяемых в исследованиях. Извлеченные блоки затем организуются в структурированный Граф Знаний (Knowledge Graph), где узлы соответствуют Методическим Блокам, а ребра — взаимосвязям между ними, таким как последовательность выполнения, альтернативные подходы или общие принципы. Такая организация позволяет эффективно моделировать сложные взаимосвязи между различными методологическими элементами и обеспечивает возможность поиска и повторного использования знаний.
Для эффективной организации и навигации по сложному графу знаний, построенному на основе извлеченных из научной литературы методологических блоков, используются методы снижения размерности, такие как Umap. Umap позволяет представить высокоразмерные данные, отражающие взаимосвязи между элементами графа знаний, в виде двумерных или трехмерных представлений, сохраняя при этом топологическую структуру исходных данных. Это обеспечивает визуализацию связей, упрощает поиск релевантной информации и повышает эффективность исследования, позволяя пользователям быстро ориентироваться в сложных взаимосвязях между методологическими блоками и выявлять скрытые закономерности.
Предварительно вычисленная база знаний значительно снижает вычислительные затраты в процессе исследования. Вместо повторного анализа больших объемов научной литературы во время работы, система использует уже структурированные и взаимосвязанные фрагменты информации — так называемые Method Units. Это позволяет ускорить поиск релевантных данных и снизить потребность в вычислительных ресурсах, особенно при работе с обширными наборами данных. Предобработка информации и создание графа знаний позволяют проводить более эффективное исследование, фокусируясь на анализе и синтезе данных, а не на их первоначальном извлечении и структурировании.
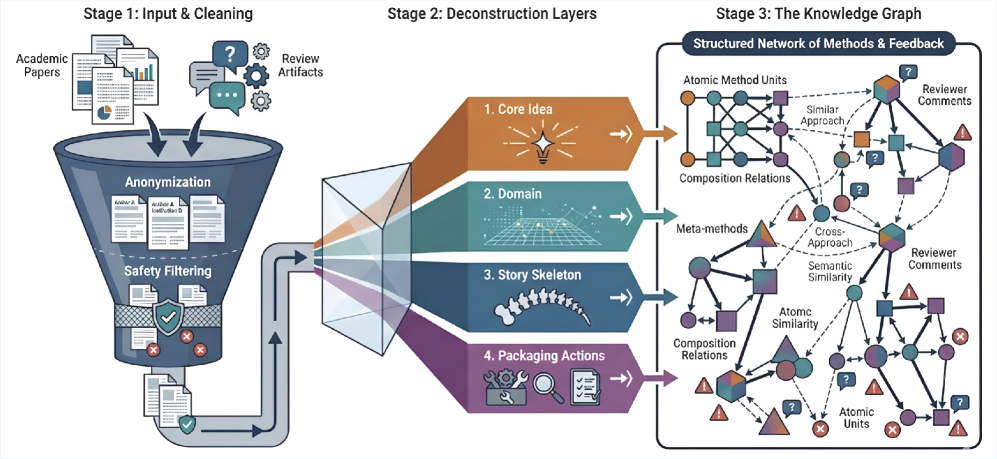
Динамическая генерация исследований с предварительной проработкой
Онлайн-генерация исследований, реализованная с помощью Idea2Story, функционирует путем извлечения и компиляции Шаблонов исследований (Research Patterns) из предварительно построенного Графа знаний. Этот процесс включает в себя поиск релевантных методологических компонентов, взаимосвязей и данных, хранящихся в графе, и их объединение в структурированные шаблоны. Шаблоны исследований представляют собой предварительно определенные рамки для проведения исследований, включающие в себя гипотезы, методы сбора данных, аналитические подходы и ожидаемые результаты. Использование предварительно скомпилированных шаблонов позволяет системе быстро формировать исследовательские планы, адаптированные к конкретным запросам и задачам.
Предварительные вычисления в системе Idea2Story направлены на решение двух ключевых проблем, возникающих в стандартных рабочих процессах больших языковых моделей (LLM). Во-первых, это снижение необходимости в повторном логическом выводе, поскольку часто используемые методические компоненты уже определены и сохранены. Во-вторых, предварительная обработка позволяет обойти ограничение на размер контекстного окна, типичное для LLM, поскольку вся необходимая информация не должна помещаться в один запрос. Вместо этого, система получает доступ к предварительно скомпилированным паттернам исследования, что значительно повышает эффективность и скорость генерации релевантных результатов.
Система ускоряет процесс исследований и повышает его надежность за счет проактивной сборки релевантных методологических компонентов. Вместо того, чтобы выполнять поиск и компоновку необходимых элементов в процессе генерации, система заранее формирует набор методологических блоков, готовых к использованию. Это позволяет избежать повторных рассуждений и ограничений, связанных с объемом контекстного окна, характерных для стандартных рабочих процессов с использованием больших языковых моделей. Предварительная сборка компонентов обеспечивает более быстрое и последовательное формирование структуры исследования, снижая вероятность ошибок и повышая воспроизводимость результатов.
Оценка с использованием Gemini 3 Pro последовательно демонстрировала превосходство исследовательских шаблонов, генерируемых Idea2Story, по показателям новизны, методологической проработки и общего качества исследования. Это указывает на переход от подхода, ориентированного на вычисления в процессе выполнения (runtime-centric), к автономным исследованиям, основанным на предварительных вычислениях (pre-computation-driven). Результаты подтверждают, что предварительная сборка релевантных методологических компонентов позволяет повысить эффективность и надежность исследовательского процесса, а также генерировать более содержательные и инновационные результаты по сравнению с традиционными подходами.
Сгенерированные шаблоны исследований служат готовыми схемами для разработки экспериментальных дизайнов, значительно упрощая переход от гипотезы к практическому исследованию. Эти шаблоны включают в себя предопределенные методологические компоненты, такие как выборка, методы анализа данных и ключевые показатели, позволяя исследователям быстро структурировать свои эксперименты и избежать повторных рассуждений. Использование этих шаблонов сокращает время, необходимое для планирования и подготовки исследований, и повышает воспроизводимость результатов, поскольку методологическая основа уже определена и задокументирована.

К новой эре научных агентов
Фреймворк Idea2Story открывает новые возможности для агентов, основанных на больших языковых моделях (LLM), предоставляя структурированную базу знаний и эффективный конвейер генерации исследований. В отличие от предшествующих систем, полагавшихся на заранее заданные шаблоны, данный подход позволяет агентам самостоятельно формировать логическую цепочку от идеи к научной истории. Это достигается за счет организации информации в виде взаимосвязанных утверждений и доказательств, что значительно повышает надежность и воспроизводимость генерируемых результатов. Такой структурированный подход не только облегчает процесс исследования, но и позволяет агентам более эффективно синтезировать информацию из различных источников, выявлять пробелы в знаниях и предлагать новые направления для научных изысканий, тем самым приближая эру действительно автономных научных исследователей.
Современные системы, такие как Kosmos и Agent Review, демонстрируют значительный потенциал в автоматизации научных исследований, однако их эффективность напрямую зависит от качества и доступности исходных знаний. Предлагаемый подход, основанный на предварительно выстроенной базе структурированных данных и оптимизированном конвейере генерации научных материалов, позволяет существенно расширить возможности этих систем. Вместо того, чтобы полагаться исключительно на поиск и анализ информации в реальном времени, Kosmos и Agent Review получают возможность оперировать уже обработанными и верифицированными данными, что значительно повышает скорость и надежность получаемых результатов. Такое предварительное вычисление и структурирование знаний снижает вероятность ошибок, связанных с интерпретацией неоднозначной информации, и позволяет агентам сосредоточиться на более сложных задачах, таких как выдвижение гипотез и планирование экспериментов.
В отличие от ранних систем, таких как AI Scientist, которые опирались на заранее разработанные, жестко заданные шаблоны для проведения исследований, новый подход обеспечивает значительно большую гибкость и адаптивность. Вместо использования фиксированных инструкций, ограничивающих возможности системы, данный метод позволяет агенту самостоятельно генерировать и адаптировать исследовательские стратегии, опираясь на структурированную базу знаний и эффективный конвейер генерации информации. Это устраняет необходимость в трудоемкой ручной настройке и позволяет агенту исследовать более широкий спектр гипотез и подходов, существенно расширяя потенциал автоматизированного научного поиска и открытий.
Предложенная методология открывает путь к принципиально новым масштабам и надёжности в процессе научных открытий. В отличие от предыдущих систем, опиравшихся на жёстко заданные шаблоны, данный подход обеспечивает гибкость и адаптивность, необходимые для решения сложных научных задач. Это позволяет создавать искусственных учёных, способных самостоятельно генерировать и проверять гипотезы, анализировать большие объёмы данных и эффективно проводить исследования. Подобная автоматизация не только ускоряет темпы научного прогресса, но и предоставляет возможность исследовать области, ранее недоступные из-за ограничений ресурсов или времени, формируя основу для качественно нового этапа в развитии науки и технологий.
В представленной работе исследователи стремятся создать не просто инструмент, а скорее экосистему для автоматизированного научного поиска. Подобно тому, как садовник ухаживает за растущим деревом, они предварительно вычисляют и структурируют научные знания в графе знаний, позволяя агентам на основе больших языковых моделей (LLM) эффективнее обнаруживать закономерности. Как однажды заметил Джон Маккарти: «Всякий интеллект — это способность находить закономерности». Эта фраза особенно актуальна в контексте Idea2Story, где предварительное структурирование знаний служит своеобразным «кэшем порядка» среди неизбежного хаоса исследовательского процесса. Архитектурный выбор в пользу графа знаний — это пророчество о будущем, которое позволит агентам избегать тупиковых ветвей и быстрее достигать новых открытий.
Что дальше?
Представленная работа, стремясь структурировать научное знание для автономных агентов, неизбежно выявляет фундаментальную дилемму. Создание «знаниевого графа» — это попытка зафиксировать текущее понимание, но сама природа науки заключается в постоянном пересмотре этих основ. Каждый добавленный узел — это пророчество о будущем опровержении, каждая связь — предчувствие новой парадигмы. Не стоит обольщаться кажущейся стабильностью построенной структуры; долгая работа системы лишь маскирует надвигающуюся необходимость её радикальной перестройки.
Более того, акцент на «шаблонах исследований» может оказаться опасным упрощением. Настоящие открытия редко следуют предсказуемым траекториям. Попытка автоматизировать «творческий процесс» рискует привести к воспроизведению существующих знаний, а не к генерации принципиально нового. Система не сломается, она эволюционирует в неожиданные формы, возможно, совершенно непредсказуемые для своих создателей.
Истинный прогресс, вероятно, лежит не в создании всеобъемлющих структур, а в разработке гибких, самоадаптирующихся механизмов, способных не только обрабатывать существующие данные, но и эффективно справляться с неполнотой, противоречивостью и неопределенностью, которые являются неотъемлемой частью научного поиска. Иллюзия контроля над сложной системой — опасный соблазн.
Оригинал статьи: https://arxiv.org/pdf/2601.20833.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Лунный гелий-3: Охлаждение квантового будущего
2026-01-29 11:22