Автор: Денис Аветисян
Новое исследование показывает, что традиционные методы объяснения работы искусственного интеллекта неэффективны при анализе многошаговых действий, требуя более глубокого подхода к пониманию логики агентов.
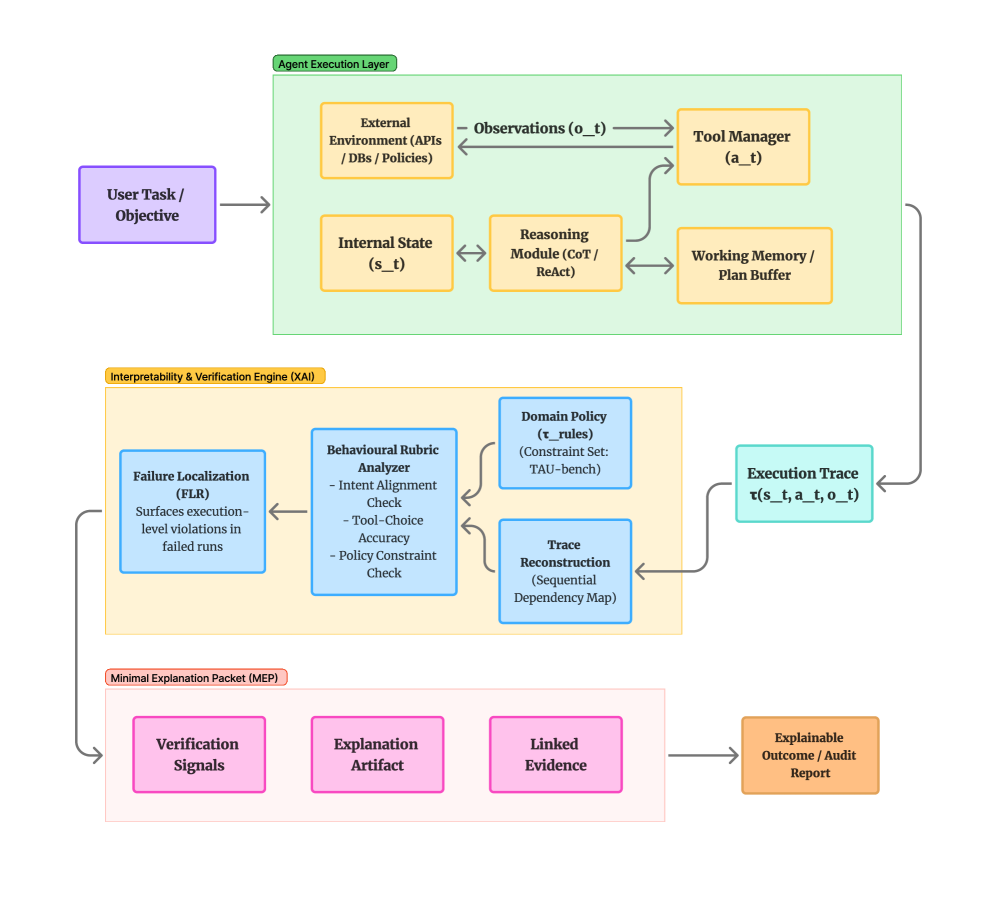
В статье предлагается использовать анализ траекторий поведения и поведенческие рубрики для диагностики сбоев в системах, управляемых ИИ.
Несмотря на значительный прогресс в области объяснимого искусственного интеллекта (XAI), существующие подходы часто оказываются неэффективными при анализе сложных, многошаговых действий автономных агентов. В работе ‘From Features to Actions: Explainability in Traditional and Agentic AI Systems’ проведено сравнение методов, основанных на атрибуции признаков, и диагностических инструментов, ориентированных на трассировку поведения, как в традиционных, так и в агентных системах. Полученные результаты показывают, что методы атрибуции, стабильно ранжирующие признаки в статических задачах (коэффициент корреляции Спирмена \rho = 0.86), не применимы для надежной диагностики ошибок в траекториях агентных систем. Не является ли переход к анализу поведения на уровне траектории ключевым для оценки и улучшения автономных систем ИИ?
Раскрытие Потенциала Агентов: Вызов Объяснимости
Агенты на базе больших языковых моделей (LLM) демонстрируют стремительное развитие, открывая перспективы автоматизации широкого спектра задач. От планирования сложных проектов до решения повседневных бытовых вопросов, эти системы способны выполнять действия, требующие ранее человеческого интеллекта. Их способность к адаптации и обучению на больших объемах данных позволяет им эффективно справляться с разнообразными сценариями, значительно повышая производительность и освобождая ресурсы. По мере совершенствования архитектур и алгоритмов, агенты LLM всё активнее внедряются в различные отрасли, от обслуживания клиентов и финансового анализа до разработки программного обеспечения и научных исследований, предвещая новую эру автоматизации и интеллектуальных систем.
Агенты, основанные на больших языковых моделях, демонстрируют впечатляющую способность к автоматизации различных задач, однако их внутренняя работа часто остается непрозрачной, что создает серьезные проблемы для обеспечения надежности и безопасности. Отсутствие понимания того, как агент принимает решения, затрудняет выявление потенциальных ошибок, предвзятостей или уязвимостей, особенно в критически важных областях применения. Эта «черный ящик» природа порождает обоснованные опасения относительно непредсказуемого поведения и возможности непреднамеренных последствий, что требует разработки методов для обеспечения прозрачности и объяснимости их действий. Без возможности проследить логику рассуждений агента, сложно гарантировать, что он действует в соответствии с ожидаемыми нормами и этическими принципами, что является ключевым препятствием для широкого внедрения подобных систем.
Для эффективной оценки возможностей агентов, основанных на больших языковых моделях, необходимы не только метрики производительности, но и четкие поведенческие критерии, а также методы, позволяющие понять логику их действий. Текущие показатели точности, демонстрируемые на бенчмарках вроде TAU-bench Airline (56.0%) и AssistantBench (17.39%), подчеркивают острую потребность в более совершенных методах оценки. Эти результаты указывают на то, что, несмотря на значительный прогресс, агенты всё ещё часто допускают ошибки, и для обеспечения их надежности и безопасности критически важно понимать, как именно они приходят к своим решениям, а не просто констатировать факт успеха или неудачи.
Стандартизация Оценки: Рубежи Поведения Агентов
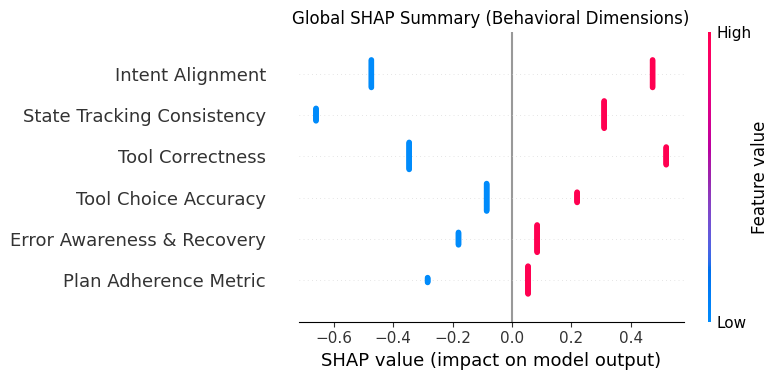
Стандартизированная оценка поведения агентов требует четко определенных критериев, таких как консистентность отслеживания состояния (State Tracking Consistency) и точность выбора инструментов (Tool Choice Accuracy). Консистентность отслеживания состояния подразумевает способность агента корректно поддерживать и обновлять внутреннее представление о текущем состоянии окружения и задачи на протяжении всего взаимодействия. Точность выбора инструментов оценивает способность агента выбирать наиболее подходящие инструменты или функции для достижения поставленной цели, избегая нерелевантных или неэффективных действий. Оценка по данным критериям позволяет объективно сравнить производительность различных агентов и выявить области для улучшения.
Инструмент Docent предоставляет возможности для маркировки трасс выполнения агента, что позволяет проводить объективную оценку поведения агента на основе заданных критериев. Процесс маркировки включает в себя аннотирование каждого шага выполнения агента с указанием корректности действий, что позволяет автоматизировать процесс оценки и снизить субъективность. Полученные размеченные данные используются для обучения моделей оценки и выявления слабых мест в поведении агента, что способствует его дальнейшей оптимизации и повышению эффективности. Docent поддерживает различные форматы данных и позволяет интегрироваться с существующими системами тестирования и оценки.
Для проведения строгой оценки и сопоставления возможностей агентов используются специализированные бенчмарки, такие как TAU-bench Airline и AssistantBench, представляющие собой реалистичные сценарии взаимодействия. На текущий момент, средний показатель успешности агентов в среде TAU-bench Airline составляет 56.0%, в то время как в AssistantBench — 17.39%. Эти показатели служат отправной точкой для оценки прогресса в разработке и совершенствовании агентов, позволяя количественно измерить их эффективность в решении конкретных задач и сравнить различные подходы.
Раскрытие Черного Ящика: Методы Объяснимости Агентов
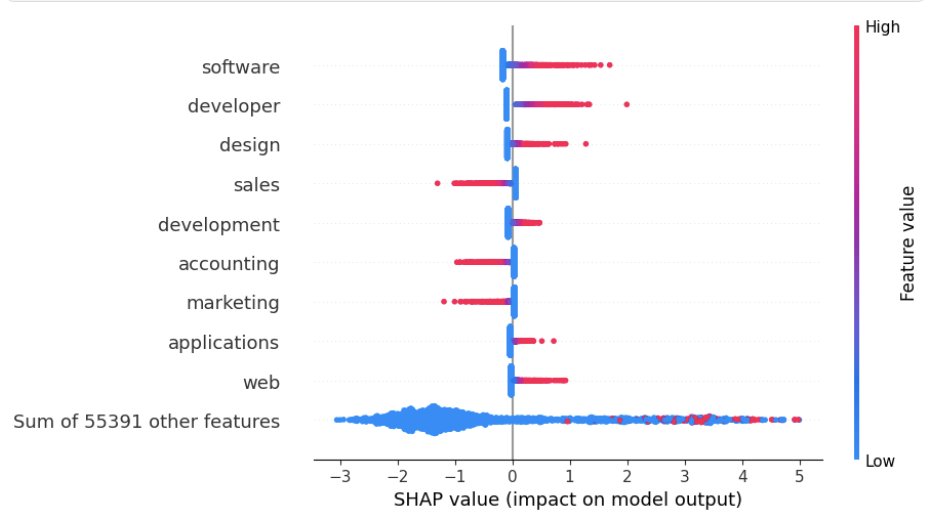
Статические методы объяснимости предсказаний, такие как SHAP, LIME и графики частичной зависимости (Partial Dependence Plots), предоставляют возможность анализа факторов, влияющих на отдельные решения агента. SHAP (SHapley Additive exPlanations) основывается на теории игр для оценки вклада каждой входной переменной в предсказание. LIME (Local Interpretable Model-agnostic Explanations) аппроксимирует поведение модели локально, вокруг конкретного предсказания, для выявления наиболее значимых признаков. Графики частичной зависимости демонстрируют среднее влияние конкретного признака на предсказание, усредненное по всем другим признакам. Эти методы позволяют оценить, какие входные данные привели к конкретному действию агента, обеспечивая понимание логики принятия решений в конкретной ситуации.
Для понимания последовательности действий, приводящих к принятию решения агентом, необходимы методы, ориентированные на объяснение траектории (Trajectory-Level Explainability). В отличие от статических методов, анализирующих отдельные прогнозы, эти подходы позволяют проследить логику рассуждений агента на протяжении всего процесса принятия решения. Это достигается за счет анализа промежуточных состояний, внутренних переменных и последовательности шагов, предпринятых агентом для достижения конечного результата. Такой анализ критически важен для выявления потенциальных ошибок в логике агента, оптимизации его поведения и повышения доверия к его решениям, особенно в критически важных приложениях.
HAL-Harness предоставляет стандартизированную платформу для выполнения и протоколирования действий агентов, что является критически важным для детального анализа их поведения. Исследования показывают, что стабильность методов статической объяснимости подвержена колебаниям при небольших изменениях входных данных. В частности, при использовании модели TF-IDF в сочетании с логистической регрессией, корреляция Спирмена составила 0.8577, в то время как при использовании Text CNN этот показатель снизился до 0.6127. Эти результаты демонстрируют, что надежность объяснений, полученных с помощью статических методов, может варьироваться в зависимости от используемой архитектуры модели и подверженности к возмущениям.
Прозрачность как Основа Доверия: Влияние Объяснимости
Для формирования доверия к автономным системам, крайне важна не только надежная оценка их работы, но и всестороннее объяснение принимаемых решений. Исследования показывают, что предоставление прозрачной информации о логике действий агента, например, посредством использования “минимальных пакетов объяснений” (Minimal Explanation Packets), значительно повышает уверенность пользователей. Такой подход позволяет не просто констатировать факт успеха или неудачи, но и демонстрировать, как система пришла к определенному выводу, выявляя ключевые шаги рассуждений и используемые данные. В результате, пользователи получают возможность оценить обоснованность действий агента и убедиться в его компетентности, что является необходимым условием для широкого внедрения подобных технологий.
Современные агентские системы демонстрируют повышенную эффективность благодаря внедрению таких методов, как Reflexion и ReAct, а также использованию RAG (Retrieval-Augmented Generation). Reflexion позволяет агенту рефлексировать над своими предыдущими действиями, выявлять ошибки и корректировать стратегию, что способствует улучшению результатов. ReAct, объединяя рассуждения и действия, предоставляет агенту возможность планировать и выполнять задачи более осознанно. RAG, в свою очередь, расширяет знания агента за счет доступа к внешним источникам информации, что позволяет генерировать более точные и обоснованные ответы. Эти методы не только повышают производительность, но и создают возможность для самооценки и предоставления обоснований принимаемых решений, что является ключевым фактором для повышения доверия к таким системам.
Анализ результатов работы агентов в тестовом окружении TAU-bench Airline показал, что нарушения согласованности отслеживания состояния (State Tracking Consistency) встречаются в 2.7 раза чаще в случаях неудачного выполнения задачи. Примечательно, что даже в тех случаях, когда задача все же завершалась успешно, но при этом наблюдалось указанное нарушение, вероятность успеха составляла всего 0.51. Данные результаты подчеркивают критическую важность поддержания согласованности отслеживания состояния для надежной и предсказуемой работы агентов, и указывают на необходимость разработки методов для выявления и исправления подобных несоответствий.
Взгляд в Будущее: Самосознательные Интеллектуальные Системы
Будущие исследования в области создания интеллектуальных агентов направлены на разработку систем, способных не просто объяснять свои действия, но и аргументированно их обосновывать, опираясь на этические принципы и специализированные знания. Такой подход предполагает, что агент сможет не только предоставить последовательность шагов, приведших к определенному решению, но и продемонстрировать, что это решение соответствует принятым нормам и контексту задачи. Обоснование действий, основанное на четко определенных этических рамках и глубоком понимании предметной области, позволит создать агентов, способных принимать ответственные решения, предвидеть потенциальные последствия и адаптироваться к сложным ситуациям, что является ключевым шагом на пути к созданию по-настоящему самосознательных и надежных интеллектуальных систем.
Интеграция методов объяснимости с алгоритмами обучения открывает принципиально новые возможности для совершенствования интеллектуальных агентов. Вместо простого исправления ошибок, система получает возможность анализировать причины, приведшие к неверному решению, опираясь на логику, заложенную в процессе объяснения. Такой подход позволяет агенту не только адаптироваться к новым ситуациям, но и формировать более глубокое понимание предметной области, повышая надежность и эффективность принимаемых решений. В результате, агенты становятся способны к самообучению и самокоррекции, что существенно расширяет границы их применения в сложных и динамичных средах, приближая их к уровню автономности и интеллекта, сопоставимого с человеческим.
Разработка интеллектуальных систем, способных к самоанализу и обоснованию своих действий, открывает перспективы для создания принципиально нового уровня взаимодействия человека и машины. Предполагается, что такие системы смогут не просто выполнять поставленные задачи, но и учитывать этические нормы и контекст ситуации, обеспечивая предсказуемость и надежность своих решений. Это позволит реализовать полноценное сотрудничество, где искусственный интеллект станет не просто инструментом, а партнером, способным адаптироваться к потребностям человека и приносить ощутимую пользу в различных сферах деятельности — от медицины и образования до промышленности и научных исследований. Подобный симбиоз предполагает не только повышение эффективности работы, но и снижение рисков, связанных с непредсказуемым поведением машин, что является ключевым фактором для широкого внедрения подобных технологий в повседневную жизнь.
Исследование демонстрирует, что традиционные методы объяснимости оказываются недостаточными при анализе сложных, многошаговых действий агентов. Автор подчеркивает необходимость перехода к анализу на уровне трасс поведения, используя поведенческие рубрики для диагностики ошибок в агентивных системах. Это созвучно словам Андрея Николаевича Колмогорова: «Вероятность — это разум, выраженный в количественной форме». В данном контексте, понимание вероятностной логики действий агента, выявляемое через детальный анализ трасс, позволяет не просто объяснить поведение системы, но и предсказать его, что, в свою очередь, открывает возможности для ее улучшения и контроля. Таким образом, исследование предлагает способ ‘взломать’ систему, разобрав ее на составляющие и поняв логику ее работы.
Что дальше?
Представленная работа заставляет задуматься: а не является ли сама концепция “объяснимости” для сложных агентов — иллюзией? Традиционные методы, безусловно, полезны для понимания логики отдельных шагов, но они, как показывает анализ, не способны уловить суть поведения, разворачивающегося во времени. Если агент действует, словно решает головоломку, состоящую из бесконечного числа ходов, то достаточно ли знать, почему он сделал этот ход, а не понять, почему он вообще пытается решить эту головоломку? Очевидно, требуется переход к более глубокому, “уровню трассировки”, где акцент делается не на атрибуции, а на диагностике — выявлении не просто ошибок, но и скрытых закономерностей, приводящих к нежелательному поведению.
Ограничения рубричной оценки также заслуживают внимания. Создание универсальной системы оценки поведения агента — задача, граничащая с утопией. Каждый агент, каждая задача требует своего набора критериев, своей логики успеха и провала. Возникает вопрос: а не является ли попытка формализации “разумного” поведения, ограничением самой способности агента к адаптации и творчеству? Возможно, вместо поиска идеальной рубрики, стоит сосредоточиться на разработке систем, способных к самообучению и самодиагностике, способных выявлять свои собственные ошибки и корректировать траекторию.
В конечном счете, исследование поднимает фундаментальный вопрос: что мы действительно хотим “объяснить”? Просто ли нам нужно знать, как агент пришел к определенному решению, или мы хотим понять его мотивацию, его цели? Если последнее, то перед исследователями стоит задача разработки принципиально новых методов, способных выйти за рамки атрибуции и анализа траекторий, и проникнуть в “черный ящик” сознания искусственного интеллекта. Или, возможно, признать, что некоторые “баги” — это не ошибки, а просто проявления непредсказуемости, неотъемлемой части сложной системы.
Оригинал статьи: https://arxiv.org/pdf/2602.06841.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Плоские зоны: от теории к новым материалам
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Квантовые амбиции: Иран вступает в гонку
- Искусственный интеллект на службе редких болезней
- Язык тела под присмотром ИИ: архитектура и гарантии
- Самообучающиеся агенты: новый подход к автономным системам
- Понимание мира в динамике: новая модель для анализа 4D-данных
- Квантовые Хроники: Добро, Зло и Запутанные Связи
- Квантовый поиск: новый взгляд на оптимизацию
2026-02-09 13:22