Автор: Денис Аветисян
Новая платформа ScheMatiQ помогает исследователям извлекать структурированные данные из текстов, превращая исследовательский вопрос в конкретные схемы и облегчая процесс анализа.

Интерактивная система ScheMatiQ использует возможности больших языковых моделей для обнаружения схем и извлечения структурированных данных, ориентируясь на заданный исследовательский вопрос и обеспечивая участие человека в процессе.
Извлечение структурированных данных из больших текстовых корпусов традиционно требует трудоемкой ручной разработки схем аннотаций, что является медленным и подверженным ошибкам процессом. В работе, посвященной системе ‘ScheMatiQ: From Research Question to Structured Data through Interactive Schema Discovery’, представлен интерактивный фреймворк, использующий возможности больших языковых моделей (LLM) для автоматического определения схем и создания структурированных баз данных на основе заданного исследовательского вопроса. Этот подход позволяет исследователям эффективно извлекать знания из неструктурированных данных и проводить анализ в различных областях, таких как право и вычислительная биология. Какие перспективы открываются для адаптации ScheMatiQ к задачам обработки данных в других дисциплинах и для создания более сложных систем анализа знаний?
От вопроса к структуре: вызов неструктурированных данных
Многие исследовательские вопросы сегодня требуют извлечения информации из обширных текстовых массивов, однако данные в подавляющем большинстве случаев представлены в неструктурированном виде. Это означает, что необходимые сведения не организованы в таблицы или базы данных, пригодные для непосредственного анализа. Вместо этого, информация разбросана по предложениям, абзацам и целым документам, что требует значительных усилий для ее выявления и систематизации. Сложность заключается в том, что извлечение релевантных фактов и связей становится трудоемким и подверженным ошибкам, особенно при работе с документами, созданными в разных стилях и форматах. По сути, перед исследователями стоит задача преобразования хаотичного потока текстовой информации в упорядоченную структуру, которая позволит проводить осмысленный анализ и делать обоснованные выводы.
Традиционные методы извлечения данных, такие как основанные на регулярных выражениях или ручном определении ключевых слов, часто оказываются хрупкими и негибкими. Они требуют значительных усилий по ручной разметке данных, что является трудоемким и дорогостоящим процессом. При изменении структуры документов или появлении новых источников информации, эти методы быстро устаревают и требуют существенной переработки. Например, система, обученная извлекать данные из одного формата отчета, может оказаться неспособной справиться с незначительными изменениями в макете или использовании другого стиля форматирования. Эта неспособность к адаптации создает серьезные препятствия для исследователей, стремящихся автоматизировать анализ больших объемов текстовой информации и синтезировать новые знания из постоянно растущего потока данных.
Возникающий дефицит в исследовательских возможностях обусловлен всё возрастающим объёмом текстовой информации, анализ которой затруднён отсутствием структурированных данных. Невозможность оперативно извлекать и обобщать знания из этой массы текстов существенно замедляет научный прогресс, поскольку исследователи сталкиваются с трудностями при выявлении закономерностей, подтверждении гипотез и синтезе новых идей. Этот «информационный затор» требует разработки более эффективных методов автоматической обработки текстов, способных преодолеть ограничения традиционных подходов и обеспечить быстрый доступ к ценным знаниям, скрытым в неструктурированных данных. В результате, способность оперативно получать и анализировать информацию становится критически важным фактором, определяющим скорость и качество научных исследований.

ScheMatiQ: Интерактивный фреймворк для обнаружения схемы
ScheMatiQ представляет собой инновационный фреймворк, использующий возможности больших языковых моделей (LLM) для автоматического формирования схемы, релевантной конкретному исследовательскому вопросу. В отличие от традиционных методов, требующих ручного определения структуры данных, ScheMatiQ позволяет LLM анализировать исходные данные и выводить оптимальную схему, включающую необходимые атрибуты и связи между ними. Этот подход автоматизирует процесс создания схемы, сокращая время и усилия, затрачиваемые исследователем на подготовку данных к анализу и позволяя сосредоточиться непосредственно на решении поставленной задачи. Фреймворк способен адаптироваться к различным доменам, автоматически определяя наиболее значимые характеристики данных в контексте конкретного исследования.
Процесс в ScheMatiQ начинается с определения единицы наблюдения, которая представляет собой ключевую сущность, вокруг которой структурированы данные. Этот этап критически важен для последующего извлечения релевантной схемы, поскольку именно единица наблюдения определяет контекст и содержание атрибутов, которые необходимо определить для ответа на поставленный исследовательский вопрос. Идентификация единицы наблюдения осуществляется автоматически и является первым шагом в построении схемы, позволяя системе сфокусироваться на наиболее значимых данных и избежать избыточной информации.
Процесс определения схемы в ScheMatiQ, следующий за выявлением основной сущности, заключается в уточнении структуры данных посредством определения атрибутов, необходимых для ответа на поставленный исследовательский вопрос. Этот этап полностью управляется большой языковой моделью (LLM), которая анализирует данные и автоматически определяет релевантные поля, необходимые для структурирования информации. LLM не просто извлекает существующие поля, но и способен предложить новые, ранее не определенные, атрибуты, расширяя возможности анализа данных и способствуя более полному пониманию предметной области.
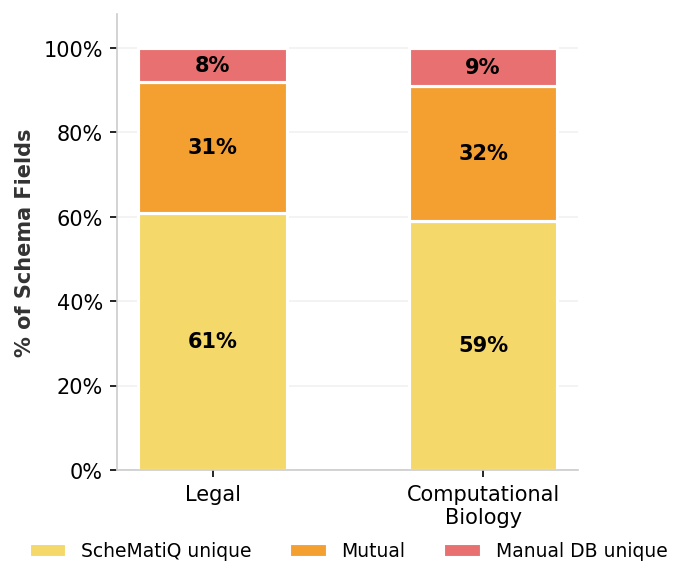
В ходе тестирования, фреймворк ScheMatiQ успешно воспроизводил вручную разработанные схемы данных, демонстрируя высокую точность автоматизированного процесса. Помимо этого, система способна предлагать новые, релевантные поля, не включенные в исходные схемы, что расширяет возможности анализа и извлечения информации. Это подтверждает потенциал ScheMatiQ для автоматизации создания схем данных и поддержки практических исследовательских рабочих процессов, сокращая временные затраты и повышая эффективность анализа.
В ходе тестирования в областях права и вычислительной биологии, система ScheMatiQ успешно восстановила практически все поля, входящие в состав эталонных схем, упустив лишь два широких поля, классифицируемых как “прочие”. Данный результат демонстрирует высокую степень охвата и точность системы в автоматическом определении релевантных атрибутов данных, необходимых для ответа на поставленные исследовательские вопросы, и подтверждает её способность эффективно автоматизировать процесс создания схем в различных предметных областях.
Автоматизированное извлечение и уточнение значений
Извлечение значений осуществляется с использованием обнаруженной схемы для идентификации и извлечения релевантной информации из корпуса документов. В процессе применяется использование больших языковых моделей (LLM), которые, основываясь на определенной схеме, автоматически выделяют необходимые данные. Этот подход позволяет обрабатывать значительные объемы текстовой информации, выявляя и структурируя ключевые элементы в соответствии с заранее определенными параметрами и типами данных, что обеспечивает высокую точность и эффективность автоматизированного анализа документов.
В основе системы заложена интерактивная схема, предусматривающая участие человека в процессе уточнения схемы и исправления ошибок извлечения данных. Этот подход “человек в цикле” позволяет оперативно корректировать неточности, возникающие при автоматическом извлечении информации, и повышать общую надежность системы. Пользователь может просматривать извлеченные значения, вносить правки и предоставлять обратную связь, которая используется для переобучения и улучшения модели извлечения. Такая итеративная схема позволяет системе адаптироваться к специфике различных документов и доменов, обеспечивая более высокую точность и релевантность извлеченных данных.
В основе системы лежит бэкенд, разработанный на FastAPI, что обеспечивает высокую производительность обработки данных и масштабируемость. FastAPI выбран благодаря своей асинхронной архитектуре и поддержке современных стандартов API. Пользовательский интерфейс реализован с использованием React, что позволяет создать интерактивное и отзывчивое окружение для работы с извлеченными данными и схемами. React обеспечивает эффективное обновление компонентов и упрощает взаимодействие пользователя с системой, предоставляя удобный инструмент для проверки и корректировки результатов извлечения информации.
Эффективность извлечения значений напрямую зависит от качества промптов, используемых для управления большими языковыми моделями (LLM). Промпты, разработанные с учетом определенной схемы данных, служат инструкцией для LLM, определяя, какие именно данные необходимо извлечь и в каком формате. Четко сформулированные промпты, учитывающие структуру схемы и специфику извлекаемой информации, позволяют значительно повысить точность и согласованность извлеченных значений. Некорректно сформулированные или неполные промпты приводят к снижению точности, неполному извлечению данных и возникновению ошибок, что требует последующей ручной корректировки и снижает общую эффективность процесса.
Экспертная оценка предложенных полей извлечения информации показала средний балл релевантности 4.2 из 5 в области вычислительной биологии и 3.6 из 5 в юридической сфере. Данная оценка была получена в результате анализа качества извлеченных данных экспертами в соответствующих областях, что подтверждает высокую точность и применимость системы ScheMatiQ для задач извлечения структурированной информации из неструктурированных документов в обеих областях.
В ходе тестирования системы ScheMatiQ в области вычислительной биологии была достигнута точность идентификации белков на уровне 87%. В юридической области система продемонстрировала 74% точность в идентификации судей. Данные показатели отражают эффективность системы в извлечении и распознавании ключевых сущностей в различных предметных областях, подтверждая её применимость для автоматизированного анализа документов.

Влияние на различные дисциплины: от правового анализа до вычислительной биологии
В рамках анализа юридической документации, система ScheMatiQ продемонстрировала высокую эффективность в извлечении ключевой информации из судебных решений и нормативных актов по вопросам иммиграционной политики. Автоматизированный процесс позволяет идентифицировать и структурировать важные прецеденты, правовые основания и условия, что значительно упрощает и ускоряет работу юристов и исследователей. В частности, система способна выявлять связи между различными судебными делами, определять тенденции в правоприменительной практике и анализировать изменения в иммиграционном законодательстве, предоставляя ценные сведения для принятия обоснованных решений и проведения углубленных исследований в области права.
В области вычислительной биологии, платформа ScheMatiQ проявила значительную эффективность в анализе научных публикаций, посвященных последовательностям белков. Система способна автоматически извлекать и структурировать информацию о аминокислотных последовательностях, мутациях и функциональных доменах, что существенно упрощает процесс выявления закономерностей и взаимосвязей. Это позволяет исследователям ускорить изучение сложных биологических процессов, таких как свертывание белков, взаимодействие белок-белок и эволюция белков, а также более эффективно прогнозировать структуру и функцию белков на основе анализа больших объемов научной литературы. Автоматизация этого процесса позволяет ученым сосредоточиться на интерпретации результатов и выдвижении новых гипотез, открывая возможности для прорывных исследований в области протеомики и биоинформатики.
Универсальность ScheMatiQ проявляется в его способности эффективно работать с разнообразными источниками данных и решать широкий спектр исследовательских задач. Не ограничиваясь определенным типом информации, фреймворк успешно адаптируется к структуре и формату как юридических документов, содержащих сложные правовые формулировки, так и научных статей, описывающих последовательности белков. Эта гибкость достигается благодаря тщательно разработанной архитектуре, позволяющей автоматически идентифицировать и извлекать ключевые данные вне зависимости от их изначального представления. Подобная адаптивность делает ScheMatiQ ценным инструментом для исследователей, работающих в различных областях, и открывает новые возможности для междисциплинарных исследований.
Автоматизация процесса подготовки данных, осуществляемая ScheMatiQ, позволяет исследователям высвободить значительные ресурсы и сосредоточиться на задачах более высокого уровня — анализе и открытиях. Традиционно, значительная часть времени ученого уходит на очистку, форматирование и структурирование данных, что замедляет прогресс исследований. ScheMatiQ эффективно устраняет эту проблему, предоставляя инструменты для автоматической обработки разнообразных источников информации. Это не только ускоряет исследовательский цикл, но и минимизирует вероятность ошибок, связанных с ручной обработкой данных, позволяя ученым более уверенно интерпретировать результаты и делать значимые открытия в различных областях, от юриспруденции до вычислительной биологии.

Исследование, представленное в ScheMatiQ, демонстрирует стремление к систематизации хаоса информации, что перекликается с философией Пола Эрдеша. Он говорил: «Математика — это искусство находить закономерности, скрытые в кажущемся беспорядке». Система, позволяющая преобразовывать неструктурированные данные в структурированный формат, опираясь на исследовательский вопрос, фактически взламывает систему информации, выявляя её внутренние связи. Подобно реверс-инжинирингу, ScheMatiQ деконструирует текст, чтобы понять его суть и представить её в удобном для анализа виде. Этот процесс, подобно выявлению закономерностей, требует пристального внимания к деталям и способности видеть скрытые связи, что является ключевым элементом как в математике, так и в научном исследовании. Система позволяет исследователям не просто извлекать данные, но и понимать их контекст, что значительно повышает ценность полученных результатов.
Куда же дальше?
Представленный фреймворк, ScheMatiQ, позволяет взглянуть на процесс извлечения структурированных данных под новым углом. Однако, если присмотреться, возникает вопрос: а не является ли сама идея “схемы” — лишь удобной иллюзией порядка в хаосе информации? Ведь любое структурирование — это неизбежная потеря нюансов, отбрасывание потенциально значимых деталей. Возникает искушение предположить, что наиболее ценные открытия скрываются именно в тех данных, которые не укладываются в заранее заданные рамки.
Следующим шагом видится отказ от жесткого следования заданному вопросу исследования. Что, если позволить системе самостоятельно выявлять закономерности, не ограничивая ее рамками человеческого любопытства? Отказ от предварительного определения “единицы наблюдения” может привести к неожиданным, нетривиальным связям, которые ускользнут от внимания исследователя, уверенного в своей правоте. Интересно, как изменится результат, если дать алгоритму “поиграть” с данными, прежде чем задавать вопросы.
И, наконец, стоит задуматься о природе “интерактивности”. Не является ли она лишь способом успокоить исследователя, заставить его поверить в контроль над процессом? Что, если истинный потенциал системы раскроется только в режиме полной автономии, когда она сможет самостоятельно формулировать вопросы и проверять гипотезы, минуя человека как посредника? Возможно, тогда и станет ясно, где заканчивается наука и начинается истинное познание.
Оригинал статьи: https://arxiv.org/pdf/2604.09237.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Карта ошибок: Анатомия сбоев больших языковых моделей
- Надежность ускорителей: от замысла до реализации
- Квантовые нейросети для реалистичной 3D-визуализации
- Искусственный интеллект рисует по заказу: Новый масштабный датасет для редактирования изображений
- Квантовые сети под контролем: новая библиотека для моделирования гибридных схем
- Вода под микроскопом: как машинное обучение предсказывает таяние льда
- Обучение с подкреплением: новый взгляд на самообучение
- Законы масштабирования в биомоделировании: как точно определить параметры?
- Диагностика заболеваний печени: новый подход с использованием искусственного интеллекта
2026-04-14 03:56