Автор: Денис Аветисян
Исследователи представляют DISCOVER — платформу для автоматического поиска физических законов на основе данных, сочетающую в себе принципы машинного обучения и физики.
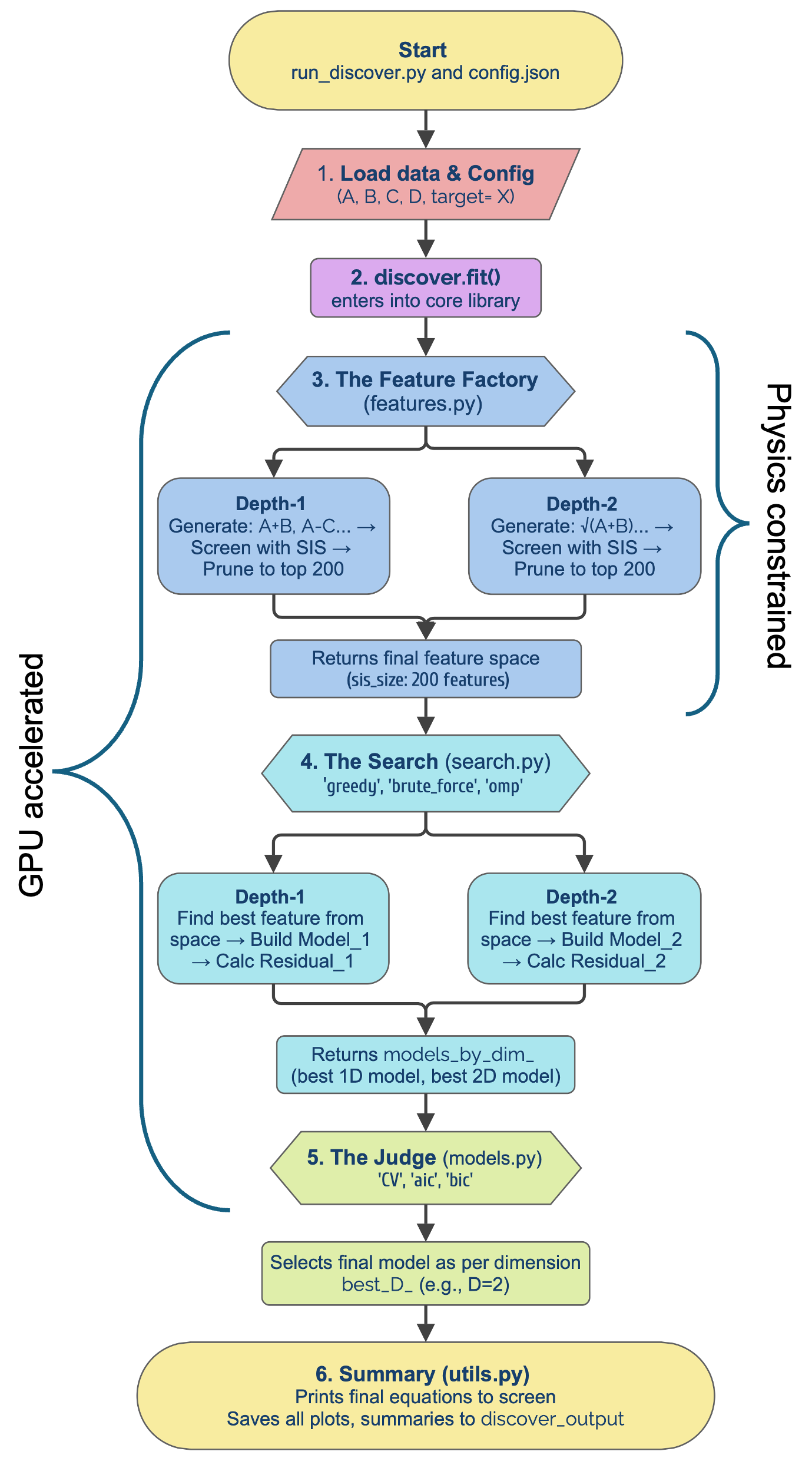
Представлен DISCOVER, открытый Python-пакет для символьной регрессии с использованием физических ограничений, GPU-ускорением и модульным дизайном для масштабируемого и интерпретируемого открытия моделей в научных областях.
Поиск интерпретируемых математических зависимостей в экспериментальных и расчетных данных часто сталкивается с ограничениями существующих инструментов символьной регрессии. В данной работе представлен DISCOVER (Data-Informed Symbolic Combination of Operators for Variable Equation Regression) — открытый пакет для символьной регрессии, сочетающий в себе физически обоснованные ограничения, опциональное GPU-ускорение и модульную структуру. DISCOVER позволяет эффективно находить компактные и физически правдоподобные дескрипторы, коррелирующие с функциональными свойствами материалов, за счет повышения масштабируемости и интерпретируемости моделей. Сможет ли данный подход существенно ускорить процесс открытия новых материалов и углубить наше понимание сложных физических явлений?
Понимание Материалов: От Интуиции к Систематическому Анализу
Традиционно поиск новых материалов осуществлялся преимущественно благодаря интуиции и методу проб и ошибок, что представляло собой длительный и весьма затратный процесс. Ученые полагались на опыт и случайные открытия, проводя многочисленные эксперименты с различными составами и структурами. Этот подход, хотя и приводил к некоторым прорывам, был крайне неэффективным и ограничивал темпы развития материаловедения. Каждая новая разработка требовала значительных временных и финансовых ресурсов, а успех зачастую зависел от удачи, нежели от систематического анализа и предсказания свойств материалов. В результате, многие перспективные материалы оставались неизученными, а потенциальные инновации — нереализованными.
Связь между свойствами материалов и их эксплуатационными характеристиками часто оказывается нелинейной и скрытой, что существенно затрудняет целенаправленную разработку новых материалов. Традиционные подходы, основанные на эмпирических наблюдениях, не всегда позволяют выявить ключевые факторы, определяющие поведение материала в конкретных условиях. Например, кажущаяся простота связи между прочностью и плотностью может быть обманчива, поскольку на прочность влияют и другие параметры, такие как микроструктура, дефекты и температура. Выявление этих сложных взаимосвязей требует применения передовых методов анализа данных и моделирования, позволяющих выйти за рамки простых корреляций и понять фундаментальные механизмы, определяющие поведение материала. Именно поэтому, понимание этих скрытых зависимостей является ключевым шагом на пути к созданию материалов с заданными свойствами и улучшенными эксплуатационными характеристиками.
Огромное количество возможных комбинаций материалов делает исчерпывающее исследование невозможным, что требует применения интеллектуальных подходов к поиску новых веществ. Пространство материалов, по сути, бесконечно, и даже при ограниченном наборе элементов и способов их соединения, количество потенциальных материалов быстро перерастает возможности экспериментальных и вычислительных методов. Вместо того чтобы пытаться перебрать все варианты, современные исследования фокусируются на разработке алгоритмов и моделей, способных предсказывать свойства материалов на основе их состава и структуры. Эти методы, включающие машинное обучение и вычислительное моделирование, позволяют ученым сузить область поиска, выявляя наиболее перспективные комбинации и значительно ускоряя процесс открытия новых материалов с заданными характеристиками. Такой подход позволяет перейти от случайных открытий к целенаправленному проектированию материалов будущего.
Анализ данных о материалах требует методов, выходящих за рамки простой констатации корреляций между свойствами. Исследования направлены на выявление глубинных механизмов, определяющих поведение материалов, а не просто на фиксацию статистических связей. Для этого применяются современные алгоритмы машинного обучения и статистического моделирования, позволяющие строить причинно-следственные связи и предсказывать свойства материалов на основе их структуры и состава. Такой подход позволяет перейти от эмпирических наблюдений к фундаментальному пониманию, что открывает возможности для целенаправленного дизайна новых материалов с заданными характеристиками и существенно ускоряет процесс их разработки. Особое внимание уделяется выявлению ключевых параметров, оказывающих наибольшее влияние на производительность материала, и построению моделей, способных прогнозировать его поведение в различных условиях эксплуатации.
Символьная Регрессия: Раскрытие Скрытых Математических Законов
Символьная регрессия представляет собой альтернативный подход к машинному обучению, который непосредственно ищет математические выражения, наилучшим образом соответствующие наблюдаемым данным. В отличие от традиционных методов, где модель строится на основе алгоритма и требует последующей интерпретации, символьная регрессия генерирует аналитическую формулу, описывающую взаимосвязь между входными и выходными переменными. Этот процесс позволяет получить явное уравнение, например, y = ax^2 + bx + c, которое может быть использовано для прогнозирования и анализа данных, а также для выявления скрытых закономерностей и взаимосвязей, не требующих предварительного задания типа модели.
В отличие от “черных ящиков”, таких как нейронные сети, символьная регрессия предоставляет не просто прогноз, но и явную математическую формулу, описывающую взаимосвязь между входными данными и результатом. Это позволяет пользователю понять, как модель приходит к своим выводам, а не только что она предсказывает. Получаемые уравнения, например, y = ax^2 + bx + c, обеспечивают возможность анализа коэффициентов и выявления значимых факторов, влияющих на целевую переменную. Такая интерпретируемость критически важна в областях, где требуется прозрачность и обоснованность принимаемых решений, например, в науке, инженерии и финансах.
Процесс символьной регрессии использует эволюционные алгоритмы для исследования огромного пространства возможных математических выражений. В основе лежит принцип естественного отбора, где каждая «особь» представляет собой математическую формулу. Алгоритм генерирует начальную популяцию формул, оценивает их способность предсказывать данные (функция пригодности), отбирает наиболее эффективные, и затем комбинирует и мутирует их для создания нового поколения. Этот итеративный процесс продолжается до тех пор, пока не будет найдено выражение, обеспечивающее оптимальную прогностическую точность. Ключевые операции включают в себя генетические операторы, такие как кроссовер (комбинирование частей двух формул) и мутация (случайное изменение части формулы), а также функции, определяющие набор базовых математических операций и констант, из которых строятся уравнения. Эффективность алгоритма зависит от параметров, таких как размер популяции, вероятность мутации и критерии остановки.
Включение априорных знаний о физических принципах в процесс символьной регрессии позволяет значительно сузить пространство поиска и получить более правдоподобные и осмысленные решения. Вместо случайного перебора математических выражений, алгоритм направляется в сторону уравнений, соответствующих известным законам физики. Это достигается путем включения соответствующих функций и операторов в генерируемые выражения, а также путем определения штрафных санкций для решений, противоречащих фундаментальным физическим принципам. Например, при моделировании движения тела можно ограничить поиск выражениями, содержащими производные по времени и учитывающими F = ma. Такой подход не только повышает точность прогнозов, но и позволяет извлекать новые физические зависимости из данных, что особенно ценно в областях, где теоретические модели неполны или отсутствуют.
DISCOVER: Оптимизированный Фреймворк для Научных Открытий
DISCOVER представляет собой программный комплекс, основанный на методах символьной регрессии и реализованный на языке Python. В отличие от традиционных подходов, DISCOVER предоставляет унифицированный и оптимизированный рабочий процесс для автоматического поиска математических выражений, описывающих заданные данные. Это достигается за счет интеграции различных алгоритмов символьной регрессии и инструментов для предобработки данных, оценки моделей и визуализации результатов. Реализация на Python обеспечивает гибкость и расширяемость системы, а также позволяет легко интегрировать её с другими научными библиотеками и инструментами анализа данных.
В DISCOVER реализована поддержка физически обоснованных ограничений посредством интеграции с библиотекой Pint, предназначенной для работы с единицами измерения. Эта интеграция обеспечивает выполнение символьных операций с учетом размерностей и проверку корректности полученных выражений на соответствие физическим законам. В частности, Pint позволяет автоматически отслеживать единицы измерения переменных и коэффициентов в символьных выражениях, предотвращая получение бессмысленных результатов и гарантируя, что полученные модели соответствуют ожидаемым физическим свойствам. Это достигается путем применения правил размерностного анализа непосредственно в процессе символьной регрессии, что повышает надежность и интерпретируемость полученных моделей.
Использование DISCOVER позволяет значительно сократить время вычислений за счет аппаратного ускорения на графических процессорах (GPU). Реализована поддержка CUDA и Metal Performance Shaders, что обеспечивает параллельную обработку данных и, как следствие, ускорение операций символьной регрессии. Это особенно важно при работе со сложными наборами данных и большим количеством признаков, где традиционные методы обработки на центральном процессоре могут быть слишком медленными. Ускорение достигается за счет переноса вычислительно-интенсивных задач, таких как оценка кандидатов в уравнения и оптимизация параметров, на GPU, что позволяет быстрее исследовать пространство возможных решений.
DISCOVER поддерживает методы обнаружения разреженных моделей, такие как ортогональный поиск соответствий (Orthogonal Matching Pursuit), квадратичное программирование со смешанными целочисленными переменными (Mixed-Integer Quadratic Programming) и имитация отжига (Simulated Annealing). Эти методы направлены на построение упрощенных и более устойчивых моделей путем выявления наиболее значимых признаков и исключения незначимых. Задача оптимизации заключается в определении разреженной линейной комбинации признаков с максимальной размерностью дескриптора D, что формально описывается в уравнении (1): \textbf{y} = \textbf{W}\textbf{x} + \textbf{b}, где \textbf{y} — вектор предсказаний, \textbf{x} — вектор признаков, \textbf{W} — матрица весов, а \textbf{b} — вектор смещений. Стремление к разреженности достигается путем минимизации количества ненулевых элементов в матрице \textbf{W}, что способствует созданию более интерпретируемых и обобщающих моделей.
Повышение Качества Кода и Эффективности Модели
Внедрение DISCOVER значительно выигрывает от применения автоматической рефакторизации кода на основе искусственного интеллекта. Этот процесс не только повышает читаемость и понятность программного обеспечения, облегчая его дальнейшую поддержку и модификацию, но и способствует устранению потенциальных ошибок и уязвимостей. Алгоритмы ИИ анализируют структуру кода, выявляют избыточные или запутанные фрагменты и предлагают оптимальные изменения для улучшения его организации и эффективности. В результате, поддерживаемый код становится более надежным, масштабируемым и удобным для совместной разработки, что критически важно для сложных проектов в области материаловедения и машинного обучения.
В рамках DISCOVER применяется L0-регуляризация, механизм, направленный на создание моделей, включающих лишь наиболее значимые признаки. Этот подход позволяет существенно повысить прогностическую способность модели, отсекая незначительные или избыточные параметры, которые могут приводить к переобучению. Суть L0-регуляризации заключается в стремлении к разреженности модели — то есть, к максимизации числа нулевых коэффициентов. В результате, модель становится не только более точной в предсказаниях на новых данных, но и более интерпретируемой, поскольку акцентирует внимание на действительно важных факторах, определяющих исследуемое явление. Использование L0-регуляризации способствует созданию лаконичных и эффективных моделей, требующих меньше вычислительных ресурсов для обучения и применения.
В рамках системы DISCOVER ключевым аспектом повышения эффективности моделирования является выявление наиболее значимых дескрипторов материальных свойств. Используя методы, такие как SISSO (Sparse Identification of Significant System Operators), система концентрирует усилия на тех параметрах, которые оказывают решающее влияние на прогнозируемые характеристики. Такой подход позволяет существенно сократить вычислительные затраты и избежать переобучения, поскольку в моделировании учитываются только наиболее важные факторы. Это не только ускоряет процесс открытия новых материалов, но и повышает надежность и интерпретируемость полученных результатов, позволяя исследователям глубже понять взаимосвязь между структурой материала и его свойствами.
Сочетание используемых методов в рамках DISCOVER позволяет создавать разреженные модели, характеризующиеся высокой точностью и вычислительной эффективностью. Удаление избыточных параметров, благодаря L0-регуляризации и фокусировке на ключевых дескрипторах, значительно снижает сложность модели, что ведет к уменьшению времени обучения и предсказания. В результате, полученные модели не только успешно предсказывают свойства материалов, но и могут быть эффективно развернуты на вычислительно ограниченных платформах, открывая возможности для широкого применения в материаловедении и смежных областях. Такой подход позволяет достичь оптимального баланса между точностью и скородействием, что является критически важным для решения сложных научных и инженерных задач.
Исследование, представленное в данной работе, демонстрирует, что построение моделей, основанных на физических принципах, требует не только вычислительной мощности, но и строгого логического подхода к интерпретации данных. Как отмечал Вернер Гейзенберг: «Самое важное в науке — это не столько знание, сколько способность задавать правильные вопросы». DISCOVER, используя физически обоснованные ограничения и методы разреженного регрессионного анализа, стремится к выявлению закономерностей в данных, а не просто к их аппроксимации. Ошибки в модели рассматриваются как ценные указания на необходимость пересмотра исходных гипотез и уточнения физических представлений, что соответствует представлению об исследовании как об итеративном процессе, направленном на углубление понимания системы.
Что дальше?
Представленная работа, безусловно, открывает новые возможности в области символической регрессии, однако не следует забывать о фундаментальной сложности задачи. Автоматическое обнаружение закономерностей, пусть даже и с учетом физических ограничений, остается процессом, требующим критической оценки полученных результатов. Визуальная интерпретация, как известно, требует терпения: быстрые выводы могут скрывать структурные ошибки. Поиск “истинных” уравнений, описывающих реальные процессы, — это не столько техническая задача, сколько философское упражнение в понимании мира.
Очевидным направлением для дальнейших исследований является расширение набора физических ограничений и дескрипторов. Однако более интересной представляется задача интеграции с системами активного обучения. Вместо пассивного поиска закономерностей, система могла бы формулировать гипотезы и предлагать эксперименты для их проверки. Это потребовало бы разработки новых метрик оценки качества моделей, учитывающих не только точность, но и информативность.
Наконец, необходимо помнить о проблеме переобучения. Сложные модели, идеально описывающие имеющиеся данные, могут оказаться бесполезными для прогнозирования новых. Разработка методов регуляризации и валидации, учитывающих специфику физических систем, представляется ключевой задачей. В конечном итоге, успех в этой области зависит не только от вычислительной мощности, но и от способности к критическому мышлению.
Оригинал статьи: https://arxiv.org/pdf/2602.06986.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Язык тела под присмотром ИИ: архитектура и гарантии
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Квантовый Переворот: От Теории к Реальности
- Границы Разума: Управление Саморазвивающимися ИИ
- Квантовый дозор: Новая система обнаружения аномалий для умных сетей
- Плоские зоны: от теории к новым материалам
- Творческий процесс под микроскопом: от логов к искусственному интеллекту
- Генетическая приоритизация: новый взгляд на отбор генов
- Квантовый поиск: новый взгляд на оптимизацию
- Генерация без рисков: как избежать нарушения авторских прав при работе с языковыми моделями
2026-02-10 13:04