Автор: Денис Аветисян
Новое исследование показывает, что тонкая настройка данных на уровне токенов во время предварительного обучения позволяет целенаправленно формировать возможности языковых моделей, повышая их надежность и соответствие ожиданиям.
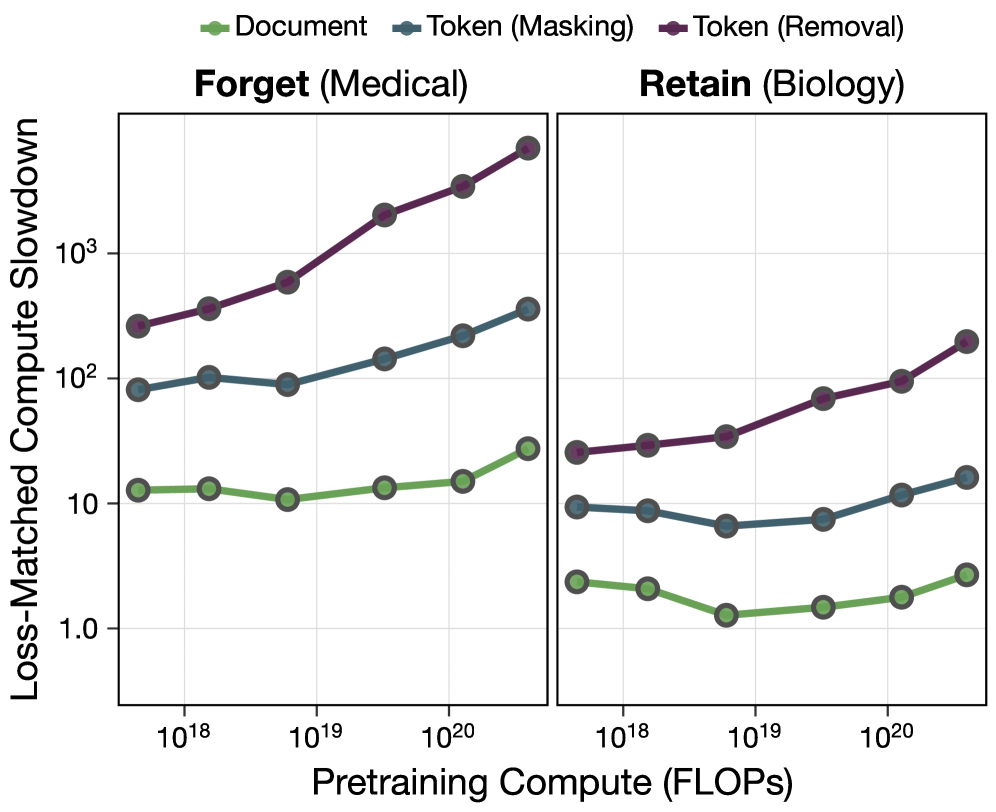
Фильтрация данных на уровне токенов во время предварительного обучения позволяет управлять способностями языковых моделей, улучшая их устойчивость и согласованность, не снижая при этом общую производительность.
Существующие подходы к снижению нежелательных возможностей языковых моделей зачастую являются реактивными и уязвимы к обходу. В работе, озаглавленной ‘Shaping capabilities with token-level data filtering’, исследуется возможность формирования этих возможностей непосредственно в процессе предварительного обучения. Показано, что простая интервенция — фильтрация токенов в обучающих данных — является высокоэффективным, масштабируемым и экономичным способом управления способностями модели, особенно в контексте удаления медицинских знаний. При этом, фильтрация на уровне токенов демонстрирует превосходство над фильтрацией целых документов, сохраняя полезные навыки. Не является ли точечная фильтрация данных ключом к созданию более управляемых и безопасных языковых моделей будущего?
Формирование способностей: обещание фильтрации данных
Современные предварительно обученные языковые модели, накапливая обширные знания из разнообразных источников, зачастую демонстрируют недостаточный контроль над тем, какие именно возможности они проявляют. Этот феномен обусловлен тем, что процесс обучения ориентирован на предсказание следующего слова в тексте, а не на целенаправленное развитие конкретных навыков. В результате, модель может обладать потенциалом для решения широкого спектра задач, но не всегда способна эффективно и безопасно применять эти знания в заданном контексте. Несмотря на впечатляющий объем накопленных знаний, отсутствие тонкой настройки и управления над проявлением способностей требует разработки методов, позволяющих формировать желаемое поведение и минимизировать нежелательные последствия.
Предварительная фильтрация данных в процессе обучения больших языковых моделей представляет собой перспективный метод формирования желаемых возможностей. Вместо ограничения общего потенциала модели, этот подход позволяет целенаправленно исключать определенные типы информации, которые могут привести к нежелательному поведению или не соответствовать предполагаемому применению. По сути, это как скульптор, удаляющий лишний материал, чтобы выявить желаемую форму — удаление специфических данных позволяет «отшлифовать» модель, сконцентрировав её способности на определенных задачах и повысив безопасность её работы. Данный метод позволяет не просто ограничить нежелательные функции, но и оптимизировать производительность в целевых областях, открывая новые возможности для контроля и адаптации языковых моделей к различным сценариям использования.
Вместо искусственного ограничения возможностей больших языковых моделей, предлагаемый подход направлен на их целенаправленное формирование в соответствии с конкретными задачами и требованиями безопасности. Исследования показали, что выборочное удаление данных на этапе предварительного обучения позволяет не просто снизить нежелательные проявления, но и улучшить производительность модели в целевых областях. Данная методика представляет собой улучшение по Парето по сравнению с существующими подходами, поскольку позволяет одновременно повысить как функциональность, так и безопасность, избегая компромиссов между этими важными аспектами. Благодаря такому формированию, модель может эффективно решать поставленные задачи, оставаясь при этом предсказуемой и надежной в своей работе.

Гранулярный контроль: от документов к токенам
Традиционные методы фильтрации на уровне документов, несмотря на свою простоту, часто оказываются избыточными и приводят к потере ценной информации. Принцип работы этих методов заключается в полном исключении документов, содержащих нежелательные элементы, вне зависимости от их объема или значимости. Это означает, что даже документы, содержащие небольшое количество нежелательного контента, могут быть отбракованы целиком, что снижает эффективность обработки и упускает потенциально полезные данные. В результате, применение фильтрации на уровне документов может приводить к значительным потерям информации и снижению общей производительности системы.
В отличие от фильтрации на уровне документов, которая оперирует целыми текстами, фильтрация на уровне токенов позволяет избирательно удалять или маскировать отдельные элементы — токены — несущие нежелательные концепции. Это достигается путем анализа каждого токена в последовательности и определения его вклада в потенциально вредоносный или нежелательный вывод. Такой подход обеспечивает более гранулярный контроль, позволяя сохранять полезную информацию в документе, удаляя лишь конкретные концепции, представленные отдельными токенами. Вместо отбрасывания всего документа, система может выборочно модифицировать или игнорировать только те токены, которые связаны с нежелательным содержанием, что повышает точность и эффективность фильтрации.
Для повышения точности фильтрации на уровне токенов используются методы маскирования потерь (Loss Masking) и извлечения признаков SAE (Sparse Autoencoder Feature Extraction). Данные методы позволяют идентифицировать и приоритизировать релевантные признаки, что существенно улучшает селективность фильтрации. Экспериментальные результаты демонстрируют, что фильтрация на уровне токенов является паретовским улучшением по сравнению с фильтрацией на уровне документов: достигается сопоставимое снижение нежелательных возможностей, но при меньших потерях в отношении желательных. Иными словами, предлагаемый подход позволяет более эффективно удалять нежелательный контент, сохраняя при этом полезную информацию.

Уточнение поведения модели: за пределами простой фильтрации
Фильтрация данных является базовым этапом, однако для закрепления желаемого поведения моделей активно применяются методы обучения отказам (Refusal Training). Данная техника подразумевает явное обучение модели отклонять запросы, которые считаются вредоносными или нежелательными. В процессе обучения модели предоставляются примеры вредоносных запросов, и она обучается генерировать ответы, выражающие отказ в выполнении таких запросов. Это позволяет не только предотвратить генерацию нежелательного контента, но и сформировать у модели устойчивое поведение, направленное на соблюдение установленных ограничений и принципов безопасности.
Методы «разучивания» (unlearning) и состязательного дообучения (adversarial finetuning) активно используются для удаления нежелательных возможностей модели, обеспечивая защиту от возникновения проблемного поведения. “Разучивание” предполагает модификацию весов модели для подавления конкретных, нежелательных ответов или действий. Состязательное дообучение, в свою очередь, включает в себя обучение модели на специально подобранных примерах, предназначенных для выявления и устранения уязвимостей и склонности к генерации вредоносного контента. Эти подходы позволяют целенаправленно снизить вероятность нежелательных реакций модели, в отличие от простой фильтрации данных, и являются важным элементом обеспечения безопасности и соответствия нормам.
Комбинация методов обучения отказам, удаления нежелательных способностей и состязательного дообучения обеспечивает надежный подход к согласованию моделей с человеческими ценностями и стандартами безопасности. В ходе экспериментов с 1.8B-параметрическими моделями наблюдалось 7000-кратное снижение вычислительной нагрузки в нежелательных областях применения после применения этих техник. Данный показатель демонстрирует значительное улучшение управляемости и снижение рисков, связанных с потенциально опасным поведением модели.

Масштабирование с учётом безопасности: архитектурные соображения
Увеличение масштаба языковых моделей, хотя и часто приводит к повышению производительности, несёт в себе риск усиления существующих предвзятостей и нежелательного поведения. По мере роста числа параметров модели, она становится более восприимчивой к усвоению и воспроизведению предвзятых представлений, содержащихся в обучающих данных. Это может проявляться в виде стереотипных ответов, дискриминационных высказываний или даже генерации вредоносного контента. Поэтому, при масштабировании моделей, крайне важно тщательно контролировать качество данных, применять методы смягчения предвзятостей и внедрять механизмы для выявления и подавления нежелательных результатов. В противном случае, простое увеличение размера модели может привести к обратному эффекту — ухудшению её надёжности и этической приемлемости.
Метод кодирования RoPE (Rotary Positional Embedding) представляет собой эффективную технику позиционного встраивания, которая особенно полезна при работе с большими языковыми моделями и последовательными данными. В отличие от традиционных методов, RoPE кодирует позиционную информацию непосредственно в механизм внимания, используя вращения в многомерном пространстве. Это позволяет модели эффективно обрабатывать длинные последовательности, сохраняя при этом информацию о порядке элементов. Благодаря своей вычислительной эффективности и способности обобщать на последовательности различной длины, RoPE становится ключевым компонентом современных архитектур больших языковых моделей, позволяя им лучше понимать контекст и генерировать более связные и релевантные тексты. Внедрение RoPE позволяет существенно улучшить способность модели к обработке последовательных данных, обеспечивая более точное и эффективное представление позиционной информации.
Взаимодействие между масштабом модели, фильтрацией данных и усовершенствованными методами обучения имеет решающее значение для раскрытия всего потенциала больших языковых моделей с соблюдением принципов безопасности и ответственности. Исследования показали, что фильтрация токенов демонстрирует меньший масштабный показатель в области «забывания» информации, что указывает на её способность к более эффективному удержанию знаний при увеличении размера модели. Более того, наблюдается прямая корреляция между более высоким значением AUROC (Area Under the Receiver Operating Characteristic curve) и улучшенной производительностью фильтрации, что подтверждает важность качественной очистки данных для достижения оптимальных результатов и минимизации рисков, связанных с предвзятостью или нежелательным поведением модели. Таким образом, комплексный подход, учитывающий все три фактора, является необходимым условием для создания надежных и эффективных больших языковых моделей.

Изучение методов фильтрации данных на уровне токенов, предложенное в статье, вызывает стойкое дежавю. Кажется, будто история повторяется: сначала — элегантная теория о формировании желаемых способностей у языковых моделей, а затем — неизбежный приём отладки в продакшене. Как метко заметил Г.Х. Харди: «Математика — это наука о том, что невозможно». В данном случае, невозможно создать идеальную модель, но можно отсрочить её неизбежное столкновение с реальностью, аккуратно отбирая обучающие данные. Улучшение устойчивости и соответствия — это всего лишь временная передышка перед новой волной непредвиденных ошибок. Система все еще жива, а значит, и баги тоже.
Куда Поведёт Нас Эта Дорога?
Предложенная фильтрация данных на уровне токенов, безусловно, добавляет ещё один инструмент в арсенал «шейпинга» языковых моделей. Однако, как показывает опыт, любое утончение претренировки — это лишь отсрочка неизбежного. Все эти усилия по повышению «надёжности» и «соответствия» рискуют обернуться лишь более изощрёнными способами обхода ограничений, когда модель столкнётся с реальным, нефильтрованным потоком данных. И тогда окажется, что «улучшенная» модель просто лучше маскирует свои ошибки.
Более того, возникает вопрос масштабируемости. Очевидно, что фильтрация, эффективная для медицинских текстов, потребует принципиально иных подходов для других предметных областей. И чем сложнее критерии фильтрации, тем выше вероятность внесения систематических ошибок, которые будут проявляться в самых неожиданных местах. Не стоит забывать, что «масштабируемое» — часто просто синоним «не тестировалось под нагрузкой».
В конечном счёте, это лишь ещё один шаг в бесконечной гонке между создателями и «взломщиками» моделей. Иногда лучше монолит, который честно признаёт свои ограничения, чем сто микросервисов, каждый из которых врёт по-своему. Остаётся надеяться, что в будущем исследователи не забудут о простоте и здравом смысле, и не увлекутся бесконечной оптимизацией, которая, в конечном итоге, ни к чему не приведёт.
Оригинал статьи: https://arxiv.org/pdf/2601.21571.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Кванты в Финансах: Не Шутка!
- Взлом языковых моделей: эволюция атак, а не подсказок
- Квантовый оптимизатор: Новый подход к сложным задачам
- Оптимизация Комбинаторных Задач: Новый Взгляд с Помощью Автокодировщиков
- Волны спинов для нейроморфных вычислений: новый подход к скорости и эффективности
2026-01-31 00:16