Автор: Денис Аветисян
Новый подход позволяет генеративным моделям создавать более реалистичные видео, учитывая законы физики, без переобучения самой модели.

В статье представлена методика WMReward, использующая латентные модели мира (VJEPA-2) для оценки физической правдоподобности генерируемых видео во время работы.
Несмотря на значительный прогресс в области генерации видео, современные модели часто демонстрируют нарушение базовых законов физики, ограничивая их практическую применимость. В данной работе, посвященной проблеме ‘Inference-time Physics Alignment of Video Generative Models with Latent World Models’, предлагается новый подход к повышению реалистичности генерируемых видео путем выравнивания с физическими принципами на этапе инференса. Разработанный метод WMReward использует латентную модель мира (VJEPA-2) в качестве сигнала вознаграждения для выбора наиболее физически правдоподобных траекторий генерации. Достигнуты ли таким образом новые рубежи в создании правдоподобных и физически корректных видео, и какие перспективы открываются для дальнейшего развития данного направления?
Иллюзия Реальности: Вызовы Физически Правдоподобной Видеогенерации
Несмотря на значительный прогресс в области генерации видео, современные модели зачастую испытывают трудности с поддержанием физической реалистичности. Новейшие разработки демонстрируют впечатляющую способность создавать визуально правдоподобные последовательности, однако при внимательном рассмотрении часто обнаруживаются нарушения законов физики. Объекты могут нереалистично деформироваться, двигаться неестественным образом или взаимодействовать друг с другом, игнорируя гравитацию и инерцию. Это несоответствие между визуальной привлекательностью и физической достоверностью существенно снижает степень погружения зрителя и ограничивает применение генерируемых видео в таких областях, как симуляции, виртуальная реальность и создание цифровых двойников. Для достижения подлинного реализма необходимы новые подходы, способные обеспечить соответствие генерируемых видео фундаментальным принципам физического мира.
Существенная проблема в создании реалистичных видео заключается в сложности обеспечения соответствия с фундаментальными законами физики, что напрямую влияет на степень их достоверности. Современные генеративные модели часто демонстрируют впечатляющие визуальные результаты, однако могут создавать сцены, в которых объекты ведут себя неправдоподобно — например, нарушают законы сохранения энергии или демонстрируют неестественные траектории движения. Данные несоответствия, даже если и незначительные, способны мгновенно разрушить иллюзию реализма и вызвать у зрителя ощущение неправдоподобия. В результате, несмотря на визуальную привлекательность, сгенерированные видео могут казаться искусственными и неправдоподобными, ограничивая их применение в сферах, требующих высокой степени достоверности, таких как симуляции, обучение или создание спецэффектов.
Современные методы генерации видео, несмотря на впечатляющий прогресс, часто сталкиваются с проблемой обеспечения физической достоверности. Отсутствие надежных механизмов проверки и принудительного соблюдения законов физики приводит к заметным визуальным несоответствиям, снижающим реалистичность создаваемых роликов. Например, объекты могут неестественно проникать друг сквозь друга, демонстрировать невозможные траектории движения или игнорировать гравитацию. Эти аномалии, хоть и кажутся незначительными, существенно влияют на восприятие, создавая эффект «зловещей долины» и разрушая иллюзию правдоподобия. Разработка алгоритмов, способных оценивать и корректировать физическую правдоподобность генерируемого видео, является ключевой задачей для дальнейшего развития этой области.
Латентные Миры: Предсказание Физического Будущего
Латентные модели мира представляют собой перспективный подход к прогнозированию будущих состояний системы, основываясь на изученных динамиках. В отличие от традиционных методов, которые часто полагаются на явное моделирование физических законов, эти модели обучаются непосредственно на наблюдаемых данных, выявляя закономерности и зависимости во временных рядах. Обучение происходит путем анализа последовательности состояний и прогнозирования следующего состояния на основе предыдущих. Эффективность таких моделей зависит от способности извлекать компактные и информативные представления (латентные переменные) из входных данных, что позволяет им обобщать на новые, ранее не встречавшиеся ситуации и предсказывать развитие событий с высокой точностью. Особенностью является возможность прогнозирования не только ближайшего будущего, но и долгосрочных изменений в динамической системе.
VJEPA-2 представляет собой конкретную латентную модель мира, которая кодирует наблюдаемые данные в компактные представления, позволяющие прогнозировать динамику развития сцены. Этот процесс включает в себя сжатие входных данных — например, последовательности кадров видео — в латентное пространство меньшей размерности, сохраняя при этом ключевую информацию, необходимую для предсказания будущих состояний. Модель использует полученные латентные представления для моделирования временной зависимости и прогнозирования последующих кадров, эффективно предсказывая эволюцию сцены на основе предыдущих наблюдений. Компактность представления критична для эффективности вычислений и снижения требований к памяти, позволяя модели обрабатывать и прогнозировать сложные сцены в реальном времени.
Прогнозирование ожидаемого развития событий является ключевым фактором в генерации физически правдоподобных видео. Модели, способные предсказывать, как объекты должны взаимодействовать и изменяться во времени, позволяют создавать видеоматериалы, которые соответствуют законам физики и кажутся реалистичными. Вместо того, чтобы просто воспроизводить наблюдаемые данные, такие модели активно моделируют физические процессы, обеспечивая последовательность и правдоподобие в генерируемых кадрах. Это особенно важно для сложных сцен с множеством взаимодействующих объектов, где ручное создание реалистичной анимации было бы крайне трудоемким и ресурсозатратным.
WMReward: Оценка Физической Правдоподобности
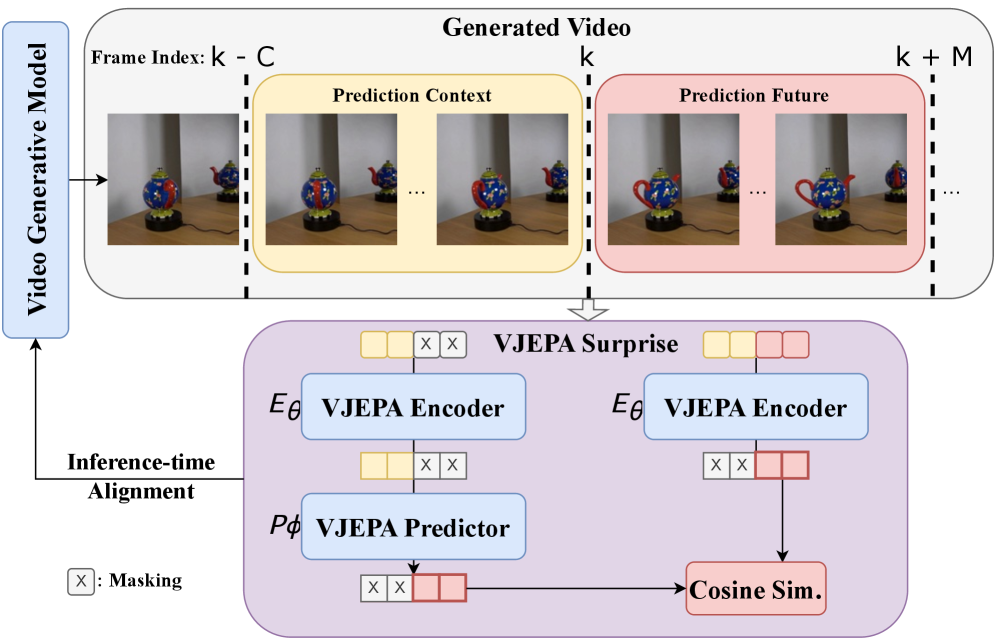
WMReward представляет новую функцию вознаграждения, основанную на оценке «удивления» (surprise score), полученной из модели VJEPA-2, для оценки физической правдоподобности генерируемых видео. Оценка «удивления» количественно определяет степень расхождения между предсказанным поведением физических объектов и их фактическим поведением в сгенерированном видео. Чем выше оценка «удивления», тем больше отклонение от ожидаемой физической динамики, и, соответственно, ниже значение вознаграждения. Таким образом, функция вознаграждения WMReward напрямую связывает физическую правдоподобность видео с численным значением, используемым для обучения генеративных моделей.
Сигнал вознаграждения WMReward направляет процесс генерации видео путем применения штрафов за отклонения от предсказанного поведения, что способствует созданию реалистичной динамики. В частности, отклонения от ожидаемых траекторий движения объектов и их взаимодействия с окружающей средой оцениваются, и величина штрафа пропорциональна степени этого отклонения. Такой подход позволяет моделировать физически правдоподобные сцены, где движение и взаимодействие объектов соответствуют законам физики, что существенно улучшает визуальное качество и реалистичность генерируемых видеороликов. Уменьшение штрафов за отклонения от предсказанного поведения является ключевым фактором в оптимизации процесса генерации и повышении физической согласованности получаемых результатов.
Для повышения эффективности и точности вычисления сигнала вознаграждения в WMReward используются методы Sequential Monte Carlo (SMC) и Support Vector Data Description (SVDD). SMC позволяет аппроксимировать распределение вероятностей состояний системы, что необходимо для оценки степени правдоподобия физической симуляции. SVDD, в свою очередь, применяется для определения границ допустимых состояний, эффективно идентифицируя отклонения от реалистичного поведения. Комбинация этих методов позволяет снизить вычислительные затраты и повысить надежность оценки физической правдоподобности генерируемых видеопоследовательностей, что критически важно для достижения реалистичной динамики.
Для повышения качества генерируемых видеопоследовательностей и обеспечения физической согласованности кадров, в WMReward применяется комбинация методов Guidance и Best-of-NN Search. Guidance позволяет направлять процесс генерации, корректируя выборку на основе рассчитанного физически обоснованного вознаграждения. Best-of-NN Search, в свою очередь, осуществляет поиск наиболее подходящих кандидатов из большого пространства возможных кадров, используя информацию о соседних кадрах и предсказуемость динамики. Этот метод позволяет значительно улучшить стабильность и реалистичность генерируемых движений, отбирая наиболее вероятные и физически правдоподобные варианты развития событий в видео.
Влияние и Перспективы Развития Видеогенерации
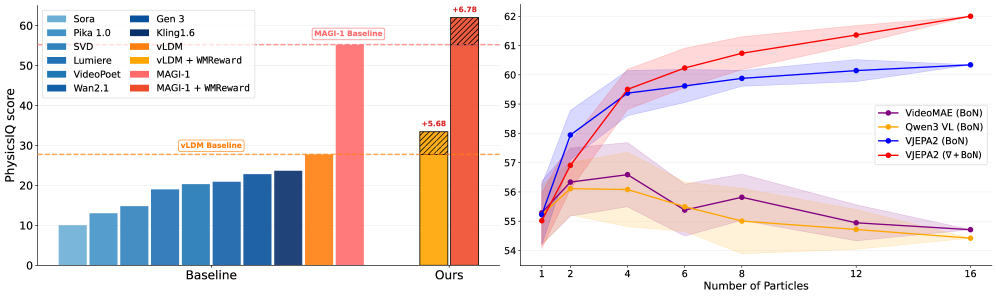
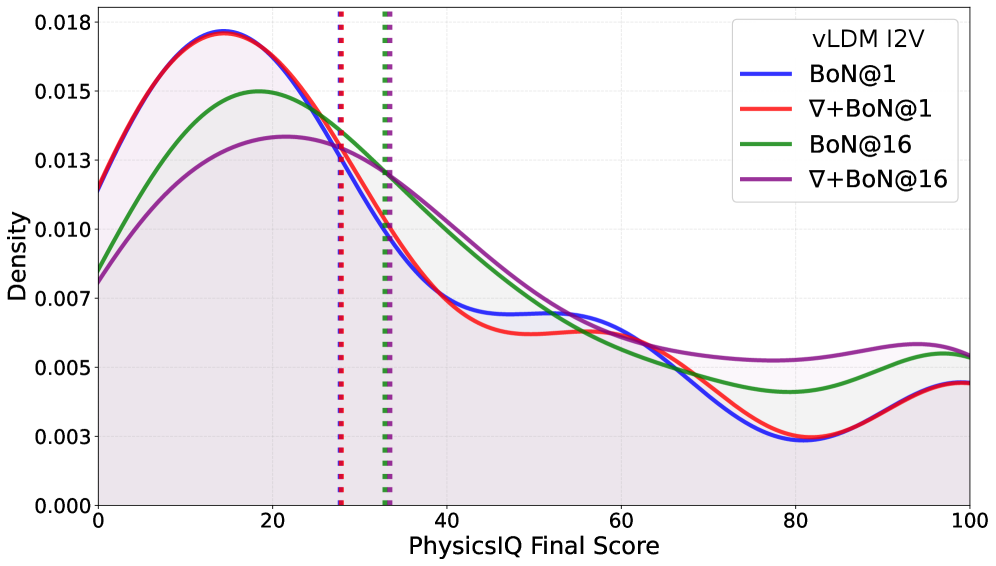
Оценка предложенного подхода с использованием эталонных тестов, таких как PhysicsIQ и VideoPhy, наглядно демонстрирует значительное улучшение правдоподобия физических процессов в генерируемых видео. Эти бенчмарки, специально разработанные для проверки соответствия виртуальной физики реальной, позволили количественно оценить эффективность новой методики. Результаты показывают, что предложенный метод не только воспроизводит более реалистичные взаимодействия объектов, но и успешно решает сложные задачи, связанные с динамикой и гравитацией, что подтверждается повышением показателей точности и прохождения тестов по сравнению с существующими подходами. Такая возможность генерации физически корректных видео имеет потенциал для широкого применения, от создания убедительных виртуальных сред до совершенствования симуляций и разработки систем робототехники.
Предложенный подход продемонстрировал значительный прогресс в области генерации физически правдоподобных видео, достигнув нового рекордного результата в 62.0% на бенчмарке PhysicsIQ. Этот показатель на 6.78% превосходит предыдущие достижения, что свидетельствует о существенном улучшении способности модели к симуляции реалистичного поведения объектов. Достигнутый прогресс указывает на возможность создания более достоверных и захватывающих виртуальных сред, открывая новые перспективы для применения в таких областях, как робототехника, компьютерная графика и реалистичное моделирование.
Предложенный подход продемонстрировал значительное улучшение точности генерации видео, что подтверждается результатами тестирования на бенчмарке VideoPhy. В частности, зафиксировано увеличение доли успешно пройденных тестов на 8.1% для модели MAGI-1 и на 6.9% для vLDM. Данный прирост свидетельствует о повышенной способности системы создавать видеоролики, физически достоверные и соответствующие реальным законам движения. Повышение точности на обеих моделях указывает на общую эффективность разработанного метода и его потенциал для широкого применения в задачах генерации видеоконтента.
Модель VLDM, представляющая собой диффузионную модель видео в латентном пространстве, демонстрирует практическое применение разработанных методов. Используя архитектуру DiT (Diffusion Transformer) и VAE (Variational Autoencoder), VLDM эффективно кодирует и декодирует видеоданные, позволяя генерировать реалистичные и последовательные видеоролики. Данная модель позволяет снизить вычислительные затраты за счет работы в латентном пространстве, сохраняя при этом высокое качество генерируемого видео. VLDM служит ярким примером того, как передовые методы, направленные на улучшение физической правдоподобности, могут быть интегрированы в существующие системы генерации видео, открывая новые возможности для создания иммерсивных и реалистичных виртуальных сред.
Разработка открывает новые горизонты в создании виртуальных сред, стремящихся к максимальной реалистичности и правдоподобности. Улучшенное моделирование физических процессов позволяет генерировать видеоматериалы, которые не просто визуально привлекательны, но и соответствуют законам физики, что критически важно для таких областей, как робототехника и симуляционное моделирование. Возможность создавать убедительные виртуальные миры способствует более эффективной разработке и тестированию алгоритмов управления роботами, а также позволяет проводить реалистичные симуляции в различных областях науки и техники, от проектирования транспортных средств до моделирования сложных производственных процессов. В перспективе, подобные технологии могут значительно расширить возможности обучения и подготовки специалистов в различных сферах деятельности, предлагая им безопасную и контролируемую среду для отработки навыков и экспериментов.

Работа демонстрирует стремление обуздать хаос, запечатлённый в движении. Вместо того чтобы требовать абсолютной точности в симуляции физики, предлагается метод, позволяющий моделировать правдоподобные видео, используя латентные модели мира как некий компас в океане возможностей. Этот подход перекликается с мыслями Дэвида Марра: «Данные — это не цифры, а шёпот хаоса. Их нельзя понять, только уговорить». Вместо жесткого кодирования правил, WMReward позволяет модели «услышать» правдоподобность, формируя видео, которые кажутся физически согласованными, даже если они не соответствуют строгим математическим моделям. И это не поиск корреляции, а попытка найти смысл в кажущемся беспорядке, в шепоте хаоса, который формирует визуальную реальность.
Что дальше?
Предложенный подход, при всей своей элегантности, лишь слегка усмиряет буйство энтропии. Он позволяет говорить с моделью на языке физики, но не гарантирует, что она услышит. По сути, это не обучение, а убеждение — временное заклинание, работающее, пока не столкнётся с реальностью продакшена. Вместо того, чтобы стремиться к абсолютной точности, следует признать, что визуализация — это всегда акт сокрытия, попытка придать смысл неразберихе.
Истинным вызовом остаётся создание моделей, способных к внутреннему пониманию физических законов, а не просто к их имитации на основе внешних сигналов. Следующим шагом видится не просто улучшение reward modeling, а разработка латентных пространств, в которых физические принципы встроены в саму структуру представления данных. Или, возможно, стоит признать, что хаос — это не ошибка, а свойство Вселенной, и научиться генерировать видео, которые правдиво отражают эту неопределённость.
В конечном счете, данная работа — это ещё один шаг на пути к приручению случайности. Но стоит помнить: данные всегда правы — пока не попадут в прод. И тогда, как всегда, придётся украшать хаос.
Оригинал статьи: https://arxiv.org/pdf/2601.10553.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
- Квантовые нейросети на службе нефтегазовых месторождений
2026-01-17 23:06