Автор: Денис Аветисян
Исследователи предлагают эффективный метод переноса движения в видео, позволяющий значительно ускорить процесс обработки без потери качества.

FastVMT: Безобусловный перенос движения в видео за счет устранения избыточности в механизмах внимания и оптимизации градиентов в диффузионных моделях.
Несмотря на значительный прогресс в области переноса движения в видео, существующие методы часто страдают от вычислительной неэффективности. В данной работе, представленной под названием ‘FastVMT: Eliminating Redundancy in Video Motion Transfer’, предложен новый подход, направленный на устранение избыточности в механизмах внимания и вычислении градиентов в диффузионных моделях. Разработанная система FastVMT обеспечивает ускорение в 3.43 раза без снижения качества и временной согласованности генерируемых видео, используя маскирование внимания и повторное использование градиентов. Не приведет ли данное решение к новым возможностям для создания реалистичных видео в реальном времени и расширению применения диффузионных моделей в различных областях?
Эра ИИ-Генерируемого Контента и Перенос Движения: Новые Горизонты Визуального Синтеза
Сфера контента, созданного искусственным интеллектом, переживает стремительный рост, и синтез видео становится одной из ключевых границ, которые предстоит преодолеть. Ранее требующие значительных усилий и ресурсов, теперь видеоматериалы могут генерироваться и модифицироваться алгоритмами машинного обучения с беспрецедентной скоростью и детализацией. Это открывает новые возможности для кинематографа, рекламы, образования и развлечений, позволяя создавать визуальный контент, который ранее был недоступен или слишком дорог. Возможности ИИ в данной области простираются от автоматической генерации коротких роликов до создания реалистичных дипфейков и даже полноценных фильмов, что указывает на радикальные изменения в индустрии производства видеоконтента.
Перенос движения, или способность наделять новые видео динамикой существующих, представляет собой ключевую задачу в области синтеза видео и компьютерного зрения. Эта проблема выходит за рамки простой замены внешнего вида; речь идет о воспроизведении сложных, нелинейных движений, выражений и взаимодействий, которые делают видео реалистичными и убедительными. Успешный перенос движения требует понимания не только визуальных изменений, но и базовых физических принципов, определяющих эти движения. В перспективе, разработка эффективных методов переноса движения позволит создавать персонализированный контент, оживлять цифровые аватары и значительно расширять возможности редактирования и создания видеоматериалов, открывая новые горизонты для развлечений, образования и коммуникаций.
Традиционные методы переноса движений в видеоматериалах часто требуют значительных вычислительных ресурсов, поскольку предполагают индивидуальную дообутку диффузионных моделей для каждого нового видео. Этот процесс, заключающийся в адаптации модели к специфическим особенностям каждого ролика, оказывается весьма затратным по времени и требует мощного оборудования. Особенно остро эта проблема проявляется при работе с большими объемами данных или при необходимости обработки видео в режиме реального времени. Существующие подходы, хотя и демонстрируют впечатляющие результаты в отдельных случаях, зачастую оказываются непрактичными для широкого применения из-за высоких требований к вычислительной мощности и энергопотреблению.
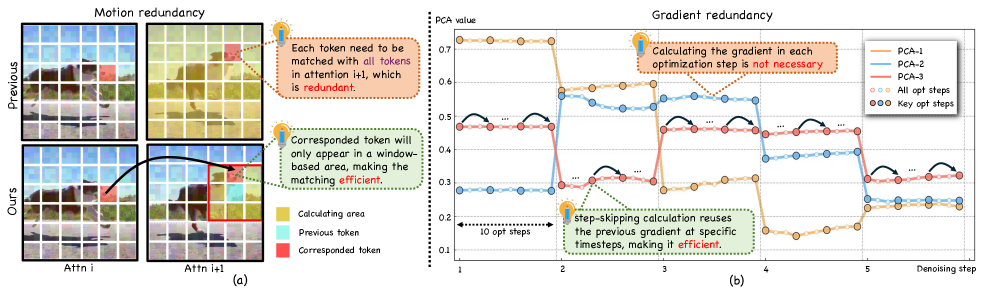
Безобусловный Перенос Движения: Новый Подход к Визуальному Синтезу
Безобусловный перенос движения представляет собой альтернативный подход, исключающий необходимость индивидуальной оптимизации для каждого видео. Традиционные методы переноса движения часто требуют обучения модели для каждого конкретного видео, что является ресурсоемким и требует значительных вычислительных затрат. Безобусловные методы, напротив, позволяют напрямую переносить информацию о движении с исходного видео на целевую последовательность без этапа обучения, что значительно сокращает время обработки и снижает требования к вычислительным ресурсам. Это достигается за счет использования предобученных моделей и эффективных алгоритмов переноса движения, что делает подход особенно привлекательным для приложений реального времени и обработки больших объемов видеоданных.
В основе методов переноса движения без обучения лежит эффективная передача информации о движении, представленной в виде векторного представления — Motion Embedding — из исходного видео на целевую последовательность. Этот Embedding кодирует ключевые характеристики движения, такие как траектории объектов, скорость и ускорение. Перенос осуществляется путем сопоставления Motion Embedding исходного видео с целевым видео, позволяя применить динамику исходного видео к новому контенту. Эффективность переноса напрямую зависит от точности кодирования и сопоставления Motion Embedding, а также от способности модели декодировать это представление в реалистичное видео.
В основе методов переноса движения без обучения лежат диффузионные модели, в частности, архитектура DiT (Diffusion Transformers). Данные модели обеспечивают генерацию видео высокого качества за счет итеративного процесса добавления и удаления шума. Архитектура DiT, используя механизм внимания, позволяет эффективно моделировать временные зависимости в видеопоследовательности, что критически важно для сохранения когерентности и реалистичности генерируемого видео. Диффузионные модели преобразуют данные в шум, а затем обучаются восстанавливать исходные данные из шума, что позволяет генерировать новые видео, комбинируя информацию из исходного видео и заданного движения.
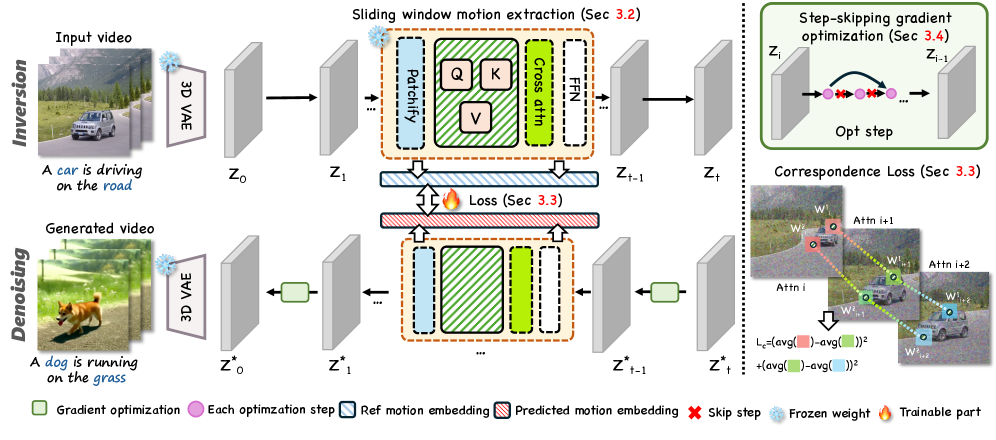
FastVMT: Эффективный Перенос Движения Благодаря Повторному Использованию Градиентов
FastVMT представляет собой новый, не требующий обучения фреймворк, разработанный для решения вычислительных проблем, возникающих в традиционных методах переноса движения. В отличие от подходов, требующих предварительного обучения или значительных вычислительных ресурсов, FastVMT позволяет эффективно переносить движение между различными объектами или последовательностями, обходясь без этапа обучения. Это достигается за счет оптимизации вычислений и повторного использования градиентов, что значительно снижает затраты по времени и вычислительной мощности, сохраняя при этом качество переноса движения. Фреймворк ориентирован на применение в задачах, требующих скорости и эффективности обработки, таких как анимация в реальном времени или обработка видео.
В основе FastVMT лежит принцип стабильной оптимизации градиентов, который учитывает высокую корреляцию между градиентами, вычисленными на последовательных шагах оптимизации. Этот феномен обусловлен тем, что на каждом шаге оптимизации решение незначительно меняется, что приводит к небольшим изменениям в градиентах. Таким образом, повторное вычисление градиентов на каждом шаге является избыточным, поскольку большая часть информации о направлении оптимизации сохраняется от предыдущих шагов. FastVMT использует эту корреляцию для уменьшения вычислительной нагрузки, переиспользуя градиенты, вычисленные ранее, вместо их полного пересчета на каждом шаге, что позволяет снизить потребность в вычислительных ресурсах без существенной потери качества оптимизации.
Метод Step-Skipping Gradient Computation, применяемый в FastVMT, существенно снижает вычислительные затраты без потери качества результата. Вместо вычисления градиентов на каждом шаге оптимизации, FastVMT вычисляет их лишь через определенные интервалы, используя предположение о высокой корреляции между последовательными градиентами. Это позволяет сократить количество необходимых операций обратного распространения ошибки, что особенно важно при обработке больших объемов данных и сложных моделей. Экспериментальные данные демонстрируют, что данная оптимизация позволяет добиться значительного ускорения обучения без ухудшения метрик качества, таких как PSNR и SSIM.
Для эффективного извлечения представлений движения (Motion Embeddings) в FastVMT используется стратегия скользящего окна, применяемая к картам внимания (Attention Maps). Данный подход позволяет улавливать локальное соответствие между кадрами, фокусируясь на небольших, смежных областях изображения. Использование скользящего окна не только обеспечивает сохранение пространственных взаимосвязей, но и значительно снижает размерность данных, поскольку обрабатывается только локальная информация, а не все изображение целиком. Это приводит к снижению вычислительных затрат и ускорению процесса извлечения признаков, сохраняя при этом качество представления движения.
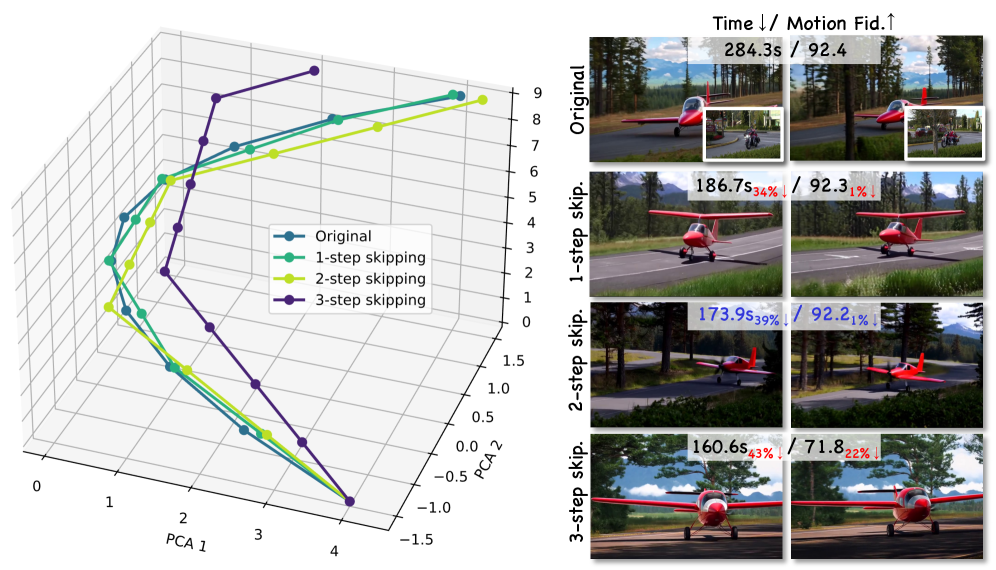
Валидация и Широкие Возможности для Синтеза Видео
Эффективность FastVMT была подтверждена посредством количественного анализа с использованием стандартных бенчмарков, таких как VBench. Данные тесты позволили объективно оценить производительность системы в различных сценариях синтеза видео, сравнивая её с результатами, полученными при использовании традиционных методов обучения. Результаты демонстрируют, что FastVMT не только обеспечивает значительно более высокую скорость обработки видео, но и сохраняет высокое качество генерируемого контента, что подтверждается метриками, измеряющими визуальное восприятие и точность передачи динамики. Использование VBench, как общепринятого стандарта, позволяет достоверно оценить вклад данной разработки в область синтеза видео и подтвердить её практическую значимость.
Представленная система демонстрирует существенное превосходство в скорости работы по сравнению с традиционными методами, требующими обучения. В ходе тестирования зафиксировано ускорение в обработке данных до 14.91 раз по сравнению с задержкой, а общая скорость работы увеличена в 3.43 раза. Такой прирост производительности достигается без потери качества генерируемого видео, что открывает возможности для применения технологии в задачах, требующих обработки видео в реальном времени, и позволяет значительно сократить время, необходимое для создания и редактирования видеоконтента с использованием искусственного интеллекта.
В рамках представленной работы особое внимание уделено обеспечению точной передачи динамики движения в синтезируемых видео. Для этого была разработана функция потерь, получившая название Window Loss, которая позволяет устанавливать надежное соответствие между движущимися объектами в исходном и сгенерированном видеоматериале. Принцип действия Window Loss заключается в сопоставлении небольших окон (фрагментов) изображения, что позволяет учитывать локальные изменения в движении и минимизировать искажения. Благодаря этому подходу, система демонстрирует повышенную устойчивость к изменениям в скорости и направлении движения, что существенно улучшает визуальную достоверность и реалистичность синтезируемых видеороликов. Особенно важно, что Window Loss позволяет сохранять плавность и когерентность движений даже в сложных сценах с множеством объектов, обеспечивая высокую степень соответствия между динамикой исходного и сгенерированного контента.
Разработанная система открывает новые перспективы для приложений, работающих в режиме реального времени, в области редактирования и синтеза видео. Благодаря значительному ускорению процессов обработки, становится возможным мгновенное создание и модификация видеоконтента, что существенно расширяет творческие возможности для художников, дизайнеров и создателей контента. Эта технология позволяет не просто автоматизировать рутинные задачи, но и экспериментировать с новыми визуальными эффектами и стилями, открывая путь к интерактивному и динамичному видеопроизводству, ранее недоступному из-за вычислительных ограничений. В перспективе, подобный подход может найти применение в различных сферах, от создания персонализированного контента до разработки инновационных инструментов для кинематографа и виртуальной реальности.

Исследование, представленное в данной работе, демонстрирует стремление к математической чистоте в области диффузионных моделей. Авторы эффективно устраняют избыточность в механизмах внимания и вычислении градиентов, что напрямую соответствует принципу детерминизма: если результат нельзя воспроизвести эффективно, он вызывает сомнения. Как однажды заметил Джеффри Хинтон: «Я думаю, что мы должны прекратить думать об обучении как о поиске параметров, которые хорошо работают на обучающих данных, и начать думать об обучении как о создании модели, которая хорошо обобщается на новые данные». Данный подход к оптимизации вычислительной эффективности, сохраняя при этом качество видео, является ярким примером создания доказуемо корректного алгоритма, а не просто решения, работающего на тестовых примерах. Это особенно важно при работе с временной согласованностью в видео, где даже незначительные ошибки могут привести к заметным артефактам.
Что дальше?
Представленная работа, безусловно, демонстрирует изящный подход к оптимизации вычислительных затрат в задачах переноса движения в видео. Однако, истинная элегантность алгоритма не должна заслонять фундаментальный вопрос: насколько эффективно решается базовая проблема представления и манипулирования движением в пространстве латентных переменных? Устранение избыточности в механизмах внимания — это, несомненно, полезный шаг, но он не отменяет необходимости более глубокого понимания того, как движение кодируется и декодируется. Очевидно, что текущие диффузионные модели, несмотря на впечатляющие результаты, по-прежнему полагаются на эмпирические методы и не обладают достаточной математической строгостью.
Перспективным направлением представляется разработка алгоритмов, основанных на принципах доказанной корректности. Необходимо стремиться к созданию моделей, для которых можно формально доказать, что перенос движения будет осуществляться без артефактов и с сохранением временной согласованности. Иными словами, решение должно быть гарантированно корректным, а не просто “работать на тестах”. Важно помнить, что кажущаяся плавность видеоряда — это лишь следствие статистической корреляции, а не признак истинной математической гармонии.
В конечном счете, будущее исследований в этой области, вероятно, будет связано с поиском более компактных и выразительных представлений движения, а также с разработкой методов, позволяющих верифицировать корректность алгоритмов переноса движения. И пусть красота алгоритма не зависит от языка реализации, важна только непротиворечивость.
Оригинал статьи: https://arxiv.org/pdf/2602.05551.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- Графы и действия: новый подход к планированию для роботов
- Bibby AI: Новый помощник для исследователей в LaTeX
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Квантовые амбиции: Иран вступает в гонку
- Диффузия против Квантов: Новый Взгляд на Факторизацию
- Федеративное обучение: баланс между конфиденциальностью и скоростью
- Многокритериальная оптимизация: взгляд на народные методы
2026-02-07 12:23