Автор: Денис Аветисян
Новый подход позволяет автоматически извлекать механические модели материалов из научных публикаций, открывая возможности для более точного и эффективного сохранения памятников истории и культуры.
Представлен автоматизированный рабочий процесс на основе больших языковых моделей для извлечения механических конститутивных моделей из научной литературы и их применения в задачах сохранения культурного наследия.
Несмотря на растущий интерес к предиктивному обслуживанию и созданию «цифровых двойников» объектов культурного наследия, необходимые механические модели материалов остаются разрозненными в огромном объеме научной литературы. В данной работе, озаглавленной ‘Automated Extraction of Mechanical Constitutive Models from Scientific Literature using Large Language Models: Applications in Cultural Heritage Conservation’, представлен автоматизированный агентный фреймворк, использующий большие языковые модели для извлечения уравнений, параметров и метаданных из научных статей. Разработанная система успешно извлекла более 185 моделей и 450 калиброванных параметров с точностью 80.4%, значительно сокращая время ручной обработки данных. Не откроет ли это путь к созданию полноценного «цифрового материального двойника» объектов культурного наследия и повышению эффективности их сохранения?
Пророчество Материалов: Сложности Моделирования Исторического Наследия
Точность структурного моделирования исторических материалов напрямую зависит от использования корректных конститутивных моделей, определяющих поведение вещества под механическим напряжением. Эти модели представляют собой математическое описание взаимосвязи между деформацией и возникающими в материале напряжениями, учитывая его внутреннюю структуру и свойства. \sigma = E \epsilon — простейшее выражение закона Гука, демонстрирующее линейную зависимость напряжения σ от деформации ε при известной константе упругости E . Однако, для сложных исторических материалов, подверженных старению, коррозии и другим факторам, требуется разработка значительно более сложных и детализированных моделей, способных адекватно описывать их нелинейное, вязкоупругое и даже разрушающееся поведение под нагрузкой. От точности этих моделей напрямую зависит надежность прогнозов относительно долговечности и устойчивости исторических объектов, а также эффективность планируемых реставрационных работ.
Материалы исторического наследия, в силу своей долгой истории и естественной изменчивости, представляют собой серьезную проблему для традиционных методов моделирования. В отличие от современных материалов с четко определенными свойствами, старинные образцы демонстрируют значительные отклонения в составе и структуре даже в пределах одного артефакта. Это вызвано процессами старения, такими как коррозия, кристаллизация солей, биологическое разрушение и многочисленными реставрационными вмешательствами. Следовательно, для точного прогнозирования поведения этих материалов под нагрузкой необходимо учитывать не только их базовые механические характеристики, но и сложные взаимодействия между различными компонентами, а также влияние факторов окружающей среды. Успешное моделирование требует глубокого понимания уникальных свойств каждого конкретного объекта и разработки специализированных подходов, учитывающих его индивидуальную историю и текущее состояние.
Существующие методы извлечения конститутивных моделей из научной литературы, описывающей поведение исторических материалов, сталкиваются со значительными трудностями. Разнообразие источников, устаревшие терминологии и отсутствие стандартизации в описании свойств материалов приводят к неполноте и противоречивости данных. Это затрудняет создание точных симуляций и прогнозирование долговечности объектов культурного наследия. В результате, процессы реставрации и консервации оказываются менее эффективными, а риски повреждения или утраты ценных артефактов возрастают. Необходимость в разработке новых, автоматизированных подходов к анализу научной литературы и извлечению релевантной информации становится всё более актуальной для успешной реализации проектов по сохранению исторического наследия.
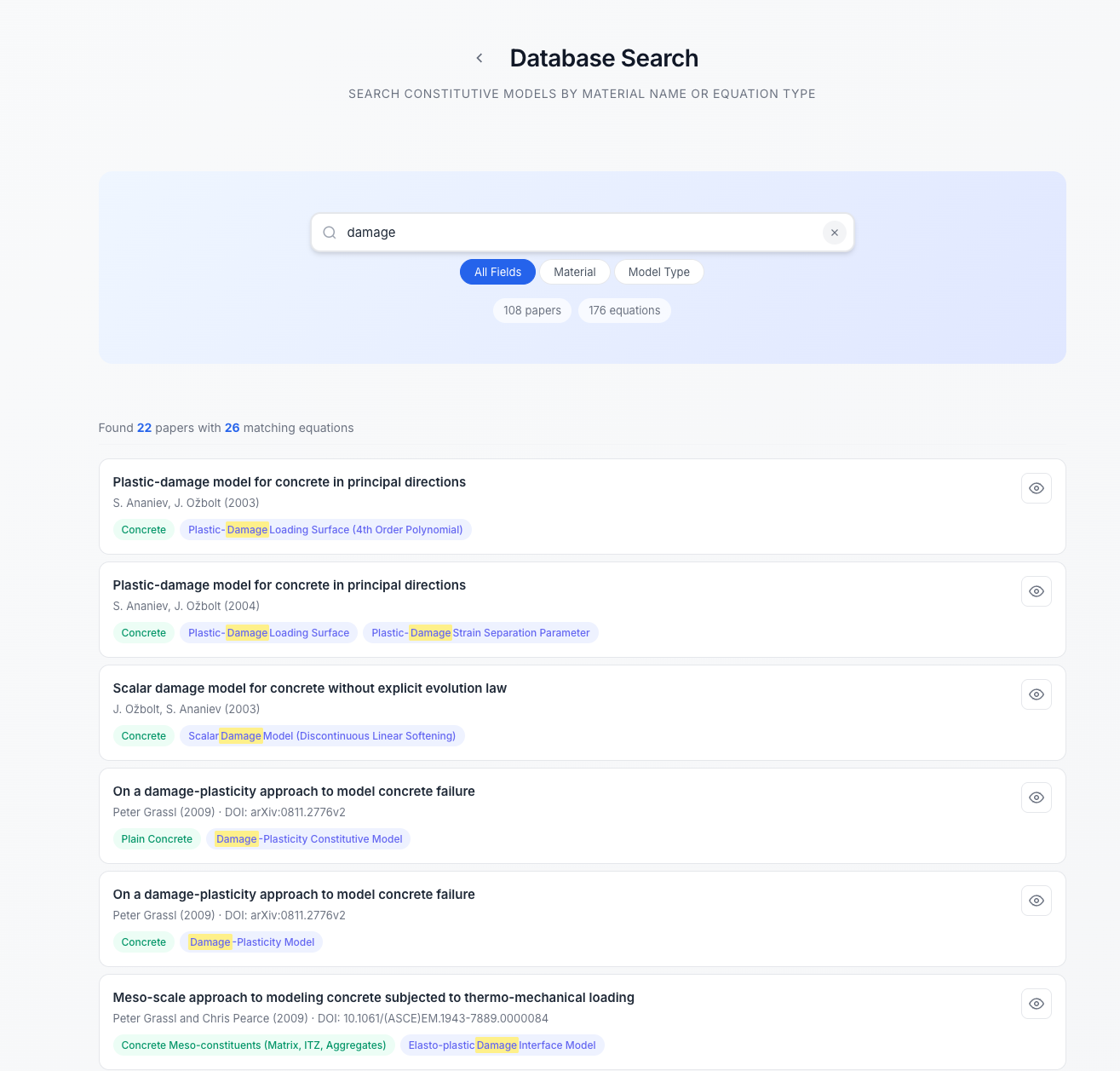
Агентный Фреймворк: Автоматизированное Извлечение Знаний
Предлагаемая архитектура использует двухзвенную систему агентов для автоматизированного извлечения данных. Первый уровень представлен агентом-фильтром («Gatekeeper Agent»), который осуществляет предварительную оценку релевантности документов, отсеивая неактуальную информацию. Второй уровень — агент-аналитик («Analyst Agent») — выполняет детальное извлечение модели из предварительно отобранных документов. Такое разделение функциональности позволяет оптимизировать процесс извлечения, снижая вычислительные затраты и повышая точность, поскольку агент-аналитик фокусируется исключительно на релевантных данных, предварительно отфильтрованных агентом-фильтром.
Агент «Аналитик» использует метод контекстного слияния (Contextual Fusion) для всестороннего понимания смысла документов. Этот подход позволяет учитывать не только непосредственное окружение уравнений и параметров, но и более широкий контекст, включая предшествующие и последующие предложения, заголовки разделов и общую тематику документа. В результате достигается более точное определение релевантных y = f(x) выражений и связанных с ними параметров, что существенно снижает вероятность ошибочной экстракции, особенно в случаях неоднозначной записи или неполного описания.
Ключевым элементом предложенной системы является применение JSON-схемы для стандартизации выходных данных. Это обеспечивает согласованность структуры извлекаемой информации, что критически важно для последующего автоматизированного анализа и обработки. JSON-схема определяет ожидаемый формат данных, включая типы полей, обязательные атрибуты и допустимые значения. Такая строгая типизация позволяет избежать неоднозначностей и ошибок при интерпретации извлеченных данных, упрощая интеграцию с другими системами и инструментами анализа, а также обеспечивая воспроизводимость результатов. Стандартизация выходных данных в формате JSON, соответствующем определенной схеме, значительно снижает затраты на разработку и поддержку downstream-приложений.
Построение Базы Данных Конститутивных Моделей Исторических Материалов
Модуль загрузки данных, основанный на анализе PDF-документов, обеспечивает автоматизированный процесс загрузки и обработки научной литературы, поступающей в систему. Этот модуль использует алгоритмы извлечения текста и данных из PDF-файлов, позволяя избежать ручного ввода и снизить вероятность ошибок. Автоматизация охватывает как сканирование документов, так и структурирование извлеченной информации для последующего анализа и интеграции в базу данных конститутивных моделей материалов культурного наследия. Данный процесс позволяет эффективно обрабатывать большие объемы научной литературы и поддерживать актуальность базы данных.
Агент-аналитик решает проблему «математического шума» путём интеллектуальной фильтрации нерелевантных уравнений, сосредотачиваясь на ключевых конститутивных зависимостях. Этот процесс включает в себя автоматическое выявление и исключение уравнений, не относящихся непосредственно к описанию механических свойств материалов, используемых в задачах сохранения культурного наследия. Алгоритмы агента идентифицируют и отбрасывают формулы, представляющие собой вспомогательные вычисления, определения переменных или частные случаи, не влияющие на основную модель. Фокусировка на ключевых конститутивных связях позволяет агенту извлекать только те уравнения, которые непосредственно описывают взаимосвязь между механическими напряжениями, деформациями и другими важными параметрами материала, такими как модуль упругости E или коэффициент Пуассона ν.
В процессе обработки более 2000 научных публикаций, разработанный фреймворк успешно извлек 185 экземпляров конститутивных моделей и более 450 откалиброванных параметров. Достигнутая точность идентификации и извлечения релевантных данных, необходимых для задач консервации культурного наследия, составила 80.4%. Извлеченные данные включают в себя как сами математические модели, описывающие поведение материалов, так и численные значения параметров, полученные в результате экспериментальных исследований и используемые для прогнозирования их свойств.
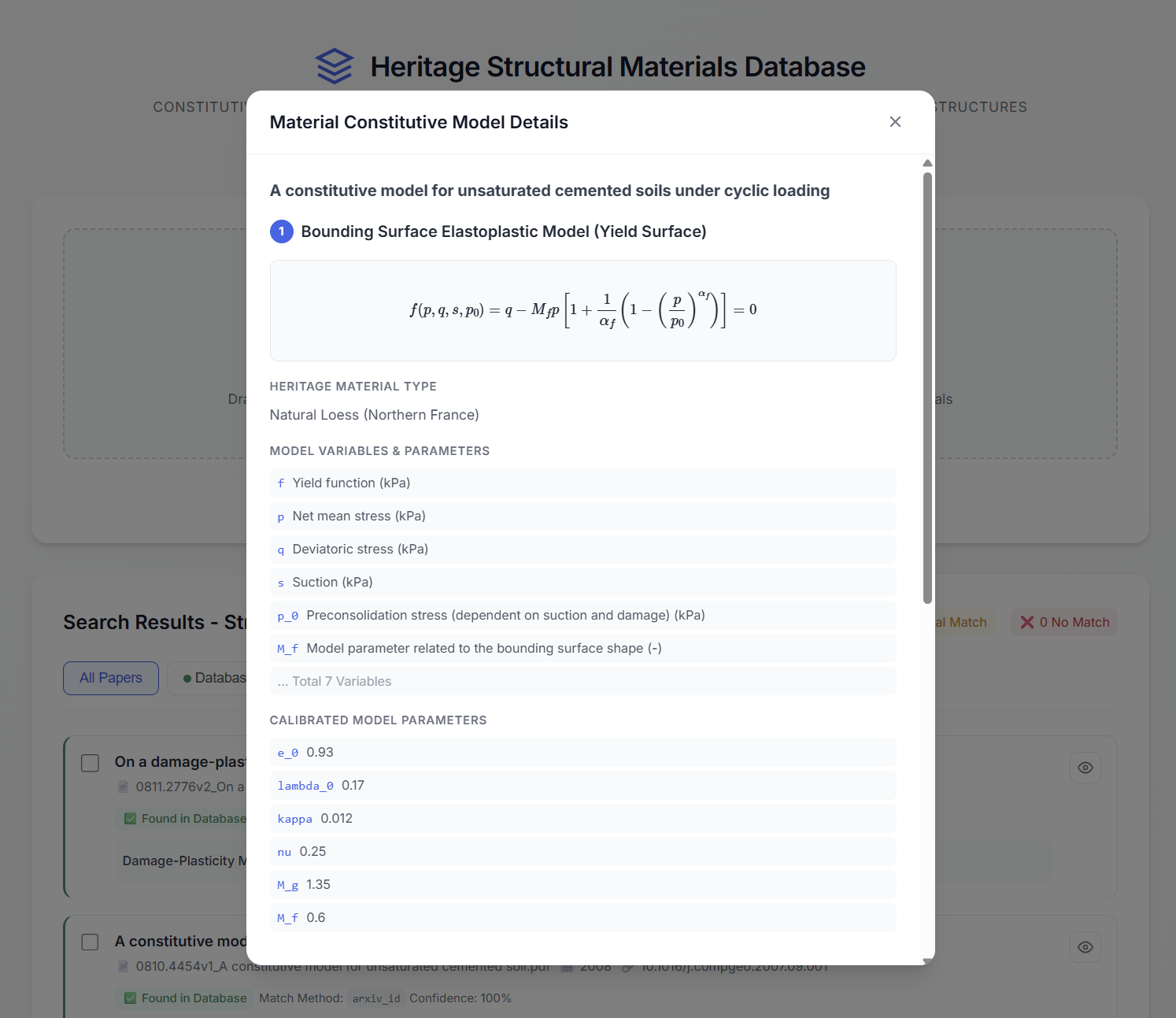
Семантический Доступ и Перспективы Развития
Система семантического поиска позволяет исследователям и реставраторам эффективно извлекать информацию о конкретных свойствах материалов или параметрах моделей из накопленной базы данных. Этот подход значительно ускоряет процесс исследований, проектирования и, что особенно важно, реставрационных работ. Вместо трудоемкого ручного поиска по многочисленным публикациям, пользователи могут напрямую запрашивать необходимые данные, получая релевантные результаты за считанные секунды. Такая возможность особенно ценна при работе с историческими материалами, где точное понимание состава и свойств является ключевым для сохранения культурного наследия. Автоматизированный доступ к структурированным знаниям позволяет не только сократить время, затрачиваемое на предварительные исследования, но и повысить точность и надежность принимаемых решений.
Система продемонстрировала способность автоматически извлекать и структурировать конститутивные модели, что решает важную проблему в области сохранения культурного наследия. Анализ 113 ключевых публикаций позволил выявить и систематизировать данные о материалах и их свойствах, необходимые для восстановления и реставрации исторических объектов. Этот подход позволяет преодолеть трудности, связанные с разрозненностью информации и ее представлением в различных форматах, обеспечивая исследователям доступ к структурированным знаниям. Автоматизация процесса позволяет значительно ускорить научные исследования и повысить точность реставрационных работ, поскольку ранее извлечение и систематизация таких данных требовали значительных трудозатрат и времени.
Автоматизированный процесс извлечения и структурирования данных значительно сократил трудозатраты при анализе научной литературы — ручной труд снижен на 90%. Оценка эффективности системы показала высокий уровень точности: значение F1-меры составило 81.9%, а площадь под кривой ROC (AUC) — 0.782. Эти показатели демонстрируют, что разработанный подход не только существенно экономит время исследователей, но и обеспечивает надежное и точное извлечение ключевой информации из большого объема научных публикаций, что особенно важно для проектов, требующих комплексного анализа данных.

Исследование демонстрирует, что создание структурированной базы данных механических моделей материалов, извлеченных из научной литературы, — это не просто техническая задача, а скорее процесс культивирования знания. Подобно тому, как садовник ухаживает за растениями, позволяя им расти и развиваться, данная работа позволяет материаловедческим знаниям «прорастать» в цифровой форме, обеспечивая более точное и эффективное сохранение культурного наследия. Карл Фридрих Гаусс однажды сказал: «Математика — это королева наук, и теория чисел — королева математики». В данном контексте, LLM выступают не просто инструментами извлечения данных, а своеобразными «математиками», способными выявлять скрытые закономерности и строить модели, необходимые для прогнозирования поведения материалов и обеспечения их долговечности.
Что дальше?
Представленная работа, подобно любому акту структурирования знания, лишь временно откладывает наступление хаоса. Автоматизированное извлечение моделей механического поведения материалов из научной литературы — это не создание порядка, а скорее, временный кеш между двумя сбоями: неполнотой данных и непредсказуемостью поведения реальных объектов культурного наследия. Успех подобного подхода не измеряется точностью извлеченных параметров, но способностью системы адаптироваться к неполноте и противоречивости исходных данных.
Будущие исследования, вероятно, столкнутся с необходимостью преодоления фундаментального ограничения: моделирование — это всегда упрощение. Усилия, направленные на создание «цифровых двойников», должны быть сосредоточены не на увеличении детализации, а на разработке механизмов, позволяющих системе предсказывать собственные ошибки и оценивать степень доверия к полученным результатам. Не стоит искать «лучшие практики»; следует изучать лишь те, которые выжили.
Архитектура подобной системы — это не план строительства, а пророчество о будущих отказах. Попытки создать универсальную базу данных, несомненно, столкнутся с проблемой гетерогенности данных и разнообразием интерпретаций. Подлинный прогресс, вероятно, будет достигнут путем создания децентрализованных, самоорганизующихся систем, способных к эволюции и адаптации в условиях неопределенности. Экосистемы, а не инструменты.
Оригинал статьи: https://arxiv.org/pdf/2602.16551.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Большие языковые модели как судьи перевода: бюджет на размышления и калибровка реальности.
- Искусственный интеллект и квантовая физика: кто кого?
- Таблицы оживают: Искусственный интеллект осваивает структурированные данные
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Разумный подбор растворителей: новый подход на стыке нейросетей и физики
- Взрыв скорости: Оптимизация внимания для современных GPU
- Видео по требованию: Управление генерацией с помощью траекторий
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Понять Мысли Ученика: Как Искусственный Интеллект Расшифровывает Решения по Математике?
2026-02-19 17:32