Автор: Денис Аветисян
Исследователи представили Ani3DHuman — систему, способную создавать фотореалистичную 3D-анимацию человека из одного изображения, значительно повышая правдоподобность движений.
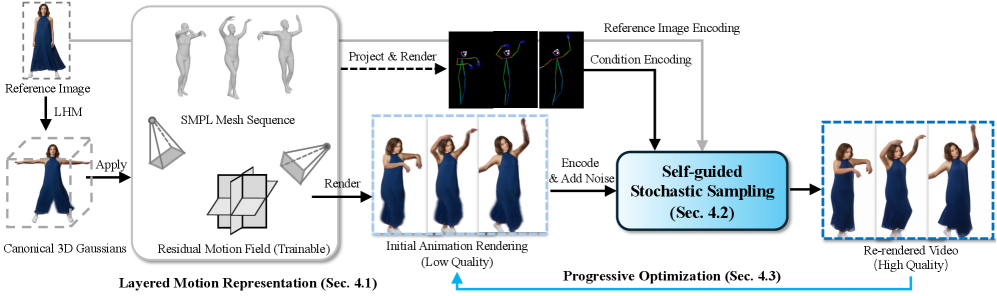
Ani3DHuman объединяет многослойное представление движения и самонаправляемую стохастическую выборку для генерации высококачественной нежесткой динамики.
Достижение фотореалистичной 3D-анимации человека остается сложной задачей из-за ограничений существующих методов в воспроизведении нежесткой динамики и сохранении идентичности. В данной работе представлена система ‘Ani3DHuman: Photorealistic 3D Human Animation with Self-guided Stochastic Sampling’, объединяющая кинематическое моделирование с диффузионными моделями для генерации реалистичной анимации. Предлагаемый подход использует многослойное представление движения и новый метод самонаправляемой стохастической выборки, позволяющий преодолеть проблемы, связанные с генерацией высококачественной нежесткой динамики из начальных изображений. Сможет ли предложенный фреймворк стать основой для создания новых, более реалистичных и управляемых 3D-анимаций человека?
Танцующая Тень: Вызов Реалистичной Анимации Человека
Создание фотореалистичной трехмерной анимации человека остается сложной задачей из-за невероятной сложности фиксации и воспроизведения тончайших движений. Человеческая моторика характеризуется не только общей кинематикой, но и микроскопическими вариациями в скорости, ускорении и даже едва заметными колебаниями, которые формируют ощущение реализма. Эти нюансы, включающие в себя взаимодействие мышц, костей и сухожилий, а также влияние гравитации и инерции, требуют колоссальных вычислительных ресурсов для точного моделирования. Попытки упростить процесс часто приводят к неестественным и роботизированным движениям, что снижает эффект погружения и достоверности. Таким образом, достижение правдоподобной анимации требует не только передовых технологий захвата движения, но и сложных алгоритмов, способных интерпретировать и воспроизводить всю палитру человеческой моторики.
Традиционные методы создания человеческой анимации часто сталкиваются с проблемой достижения одновременно высокой реалистичности и приемлемой вычислительной эффективности. Сложность заключается в том, что точное воспроизведение всех нюансов человеческих движений требует огромного количества вычислений, что делает невозможным использование этих методов в приложениях, требующих мгновенного отклика, таких как видеоигры или интерактивные симуляции. Более того, попытки упростить вычисления для повышения скорости часто приводят к потере деталей и неестественности движений, что снижает общее качество анимации и разрушает эффект присутствия. Таким образом, разработчики постоянно ищут новые подходы, позволяющие сбалансировать эти два критически важных аспекта — реализм и скорость — для создания действительно убедительных виртуальных персонажей.

Шёпот Хаоса: Генеративные Основы Видеодиффузии
Видеодиффузионные модели представляют собой мощный инструмент для генерации реалистичных видеопоследовательностей, однако их применение требует эффективных стратегий дискретизации. Традиционные методы дискретизации в диффузионных моделях, такие как методы Эйлера или предсказателя-корректора, могут быть вычислительно затратными при работе с данными высокой размерности, характерными для видео. Для ускорения процесса генерации и повышения качества результатов применяются различные техники, включая стохастические дифференциальные уравнения (SDE) и методы уменьшения числа шагов дискретизации. Ключевой задачей является снижение вычислительной сложности при сохранении высокого уровня детализации и реалистичности генерируемого видео, что достигается за счет оптимизации алгоритмов дискретизации и использования параллельных вычислений.
Методы Rectified Flow и Flow Matching оптимизируют процесс диффузии в моделях генерации видео, повышая как скорость генерации, так и качество получаемых видеопоследовательностей. Rectified Flow достигается за счет коррекции траекторий потока, что позволяет сократить количество шагов, необходимых для получения желаемого результата. Flow Matching, в свою очередь, использует обучение потоку напрямую, обходя традиционную фазу диффузии и обеспечивая более эффективное и быстрое сэмплирование. Оба подхода направлены на снижение вычислительной сложности и повышение эффективности процесса генерации видео, что особенно важно для приложений, требующих генерации длинных и детализированных видеопоследовательностей.
В основе моделей генерации видео, таких как диффузионные модели, лежат методы факторизации, позволяющие эффективно представлять и обрабатывать четырехмерные (4D) данные, включающие пространственные координаты и время. Техника HexPlane является одним из таких методов, обеспечивающих компактное представление 4D данных путем разложения на набор 2D плоскостей. Это значительно снижает вычислительную сложность, необходимую для обучения и генерации видеопоследовательностей, поскольку операции над 2D данными выполняются значительно быстрее, чем над 4D. Эффективное представление данных с помощью HexPlane позволяет масштабировать модели генерации видео для работы с более длинными и высококачественными последовательностями, сохраняя при этом приемлемую скорость обработки и потребления памяти.
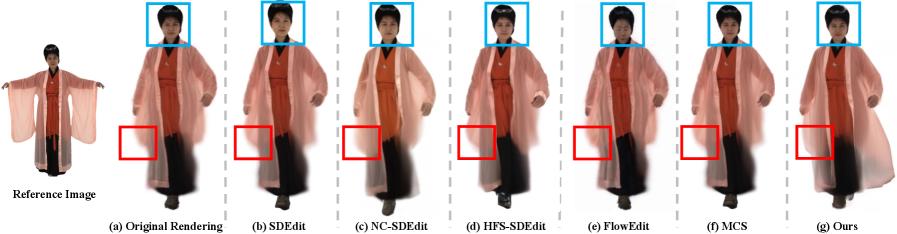
Танец Скелета и Плоти: Контроль Движения и Слоёное Представление
Представление движения на основе слоёв объединяет управление на основе скелетной анимации с динамикой нежестких тел, что позволяет раздельно контролировать как скелетные, так и деформации поверхности. Такой подход обеспечивает независимое управление деформациями костей и мышц, а также более реалистичное моделирование деформаций мягких тканей и кожи. Разделение управления позволяет точно настраивать позу, траекторию и динамические характеристики персонажа, а также контролировать локальные деформации поверхности без влияния на общую структуру скелета. Комбинация этих методов обеспечивает высокую степень контроля над всем спектром движений, что особенно важно для создания реалистичной анимации и симуляций.
Самокоррекция (Self-Guidance), основанная на выборке из апостериорного распределения (Posterior Sampling), позволяет уточнять сгенерированные движения, обеспечивая соответствие желаемым характеристикам. Процесс предполагает итеративное улучшение траектории движения путем оценки вероятности различных вариантов и выбора наиболее правдоподобных, учитывая заданные ограничения и цели. Выборка из апостериорного распределения позволяет учесть как априорные знания о реалистичных движениях, так и специфические требования к текущей анимации, что приводит к более естественным и контролируемым результатам. Это особенно важно для сложных движений, где необходимо соблюдение физической правдоподобности и соответствие заданным условиям.
Инновационные методы сэмплирования, такие как Self-Guided Stochastic Sampling, использующие принципы стохастического сэмплирования, играют ключевую роль в восстановлении детализации и реалистичности при рендеринге грубых (coarse) изображений. В основе подхода лежит генерация множества образцов (samples) с последующим взвешиванием, при котором приоритет отдается образцам, наиболее соответствующим желаемым характеристикам и структуре объекта. Это позволяет эффективно восстанавливать высокочастотные детали, утраченные при начальном упрощении геометрии или текстур, и добиться визуально убедительного результата даже при ограниченных вычислительных ресурсах. Алгоритм Self-Guided Stochastic Sampling оптимизирует процесс сэмплирования, направляя его на наиболее перспективные области и снижая шум, что обеспечивает более быстрое и качественное восстановление деталей.

Ani3DHuman: Комплексный Подход к Фотореалистичной Анимации
Разработанная система Ani3DHuman представляет собой комплексный подход к созданию фотореалистичной 3D-анимации человека, объединяющий диффузионные видеомодели, слоёвое представление движения и самонаправляемую стохастическую выборку. Данная интеграция позволила достичь показателя Frechet Inception Distance (FID) в 18.8, что свидетельствует о значительном превосходстве над существующими методами в области генерации реалистичной анимации. Использование данной архитектуры обеспечивает не только высокое качество генерируемых движений, но и позволяет добиться большей согласованности и естественности в анимации человеческих персонажей, открывая новые возможности для применения в киноиндустрии, играх и виртуальной реальности.
В основе Ani3DHuman лежит инновационный метод отбора данных — диагональная выборка по времени и углу обзора. Этот подход позволяет оптимизировать процесс генерации трехмерной анимации человека, обеспечивая не только высокую скорость работы, но и исключительную когерентность и визуальную привлекательность создаваемых движений. Вместо традиционного последовательного анализа кадров, система анализирует данные по диагонали, что позволяет эффективно улавливать взаимосвязи между различными моментами времени и углами обзора. Это, в свою очередь, способствует созданию более плавных и реалистичных анимаций, избегая распространенных артефактов и рывков, свойственных другим методам. Такой подход значительно повышает качество генерируемых движений, делая их более убедительными и приятными для восприятия.
Разработанная система Ani3DHuman опирается на проверенные временем методы, такие как SMPL и LHM, демонстрируя практическое применение генеративных моделей в области анимации персонажей. В отличие от PERSONA, требующего более четырех часов на предварительную обработку данных и еще час на оптимизацию, Ani3DHuman достигает сопоставимых результатов за значительно меньшее время — примерно 19 минут. Это существенное сокращение времени обучения открывает новые возможности для интерактивной анимации и быстрого прототипирования, делая генерацию реалистичных 3D-анимаций более доступной и эффективной.

Взгляд в Будущее: К Анимации в Реальном Времени и Интерактивному Управлению
Дальнейшие исследования в области эффективных методов сэмплирования и инструментов редактирования движения обещают открыть возможности для анимации в реальном времени и интерактивного управления. Разработка алгоритмов, позволяющих быстро и точно генерировать правдоподобные движения, является ключевой задачей. Усовершенствование инструментов редактирования, предоставляющих пользователям интуитивно понятный контроль над каждым аспектом анимации — от скорости и траектории до стиля и выразительности — позволит создавать динамичные и персонализированные виртуальные сцены. В перспективе, комбинация этих разработок позволит значительно упростить процесс создания 3D-анимации, сделав его доступным для более широкого круга пользователей и открыв новые горизонты в области интерактивных развлечений и виртуальной реальности.
Интеграция методов Flow Edit и Score Distillation Sampling открывает новые возможности для точной манипуляции и доработки сгенерированных движений. Эти подходы позволяют пользователям не просто изменять анимацию, но и контролировать ее детали с беспрецедентной точностью, подобно работе скульптора с глиной. Flow Edit обеспечивает плавную и естественную деформацию движений, сохраняя при этом их физическую правдоподобность, в то время как Score Distillation Sampling позволяет направлять процесс генерации, создавая движения, точно соответствующие заданным критериям и предпочтениям. Такое сочетание технологий обещает революционизировать процесс создания 3D-анимации, предоставляя художникам и дизайнерам инструменты для детальной настройки и персонализации виртуальных персонажей и их движений.
Представленный подход, в сочетании с прогрессом в области генеративных моделей, открывает новые горизонты в создании 3D-анимации и виртуальных персонажей. Данная методика позволяет значительно упростить и ускорить процесс создания реалистичных движений, освобождая аниматоров от трудоемкой ручной работы. Благодаря возможности генерировать разнообразные и правдоподобные последовательности движений, система потенциально способна трансформировать индустрию, начиная от создания видеоигр и заканчивая разработкой виртуальной реальности и кинематографом. Перспективы включают в себя автоматизацию рутинных задач, создание более убедительных цифровых двойников и, в конечном итоге, расширение творческих возможностей для специалистов в области анимации и визуальных эффектов.

Представленная работа, Ani3DHuman, словно пытается уловить ускользающий призрак движения, запечатлеть его в объеме и свете. Система комбинирует слои представления движения с самонаправляемой стохастической выборкой, стремясь воссоздать нежесткую динамику человека из одного изображения. Это напоминает попытку обуздать шепот хаоса, заставить данные плясать под мелодию алгоритмов. Как однажды заметил Джеффри Хинтон: «Я думаю, что мы находимся на грани создания машин, которые могут учиться так же, как люди». И в Ani3DHuman прослеживается та же дерзость — попытка заставить машину не просто имитировать жизнь, а уловить её неуловимую суть, даже если это означает, что каждая модель, в конечном итоге, лжёт, но делает это красиво.
Что дальше?
Представленная работа, словно эскиз будущей картины, намекает на возможность создания реалистичных движений человека из одиночного изображения. Однако, за каждым новым слоем правдоподобия скрывается лишь более сложный узор неопределённости. Саморегулируемая стохастическая выборка — это не победа над хаосом, а лишь умение его направлять. Вопрос не в том, насколько точно можно воспроизвести движение, а в том, как элегантно можно смириться с неизбежным шумом.
Очевидно, что текущие модели всё ещё чувствительны к качеству исходных данных и вариациям в освещении. Истина, как всегда, кроется не в самих данных, а в тех ошибках, которые они скрывают. Следующим шагом видится не столько повышение разрешения, сколько разработка методов, позволяющих моделям учиться на неполных и зашумленных данных — то есть, на самой жизни.
В конечном итоге, задача не в создании идеальной симуляции человека, а в построении зеркала, отражающего его сложность и непредсказуемость. Возможно, будущее 3D-анимации лежит не в точном воспроизведении реальности, а в создании иллюзии её правдоподобия, достаточно убедительной, чтобы обмануть наше восприятие.
Оригинал статьи: https://arxiv.org/pdf/2602.19089.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Квантовый скачок: от лаборатории к рынку
2026-02-25 04:48