Автор: Денис Аветисян
Исследователи представили ActionMesh — модель, способную быстро и эффективно создавать детализированные анимированные 3D-меши из различных источников данных.
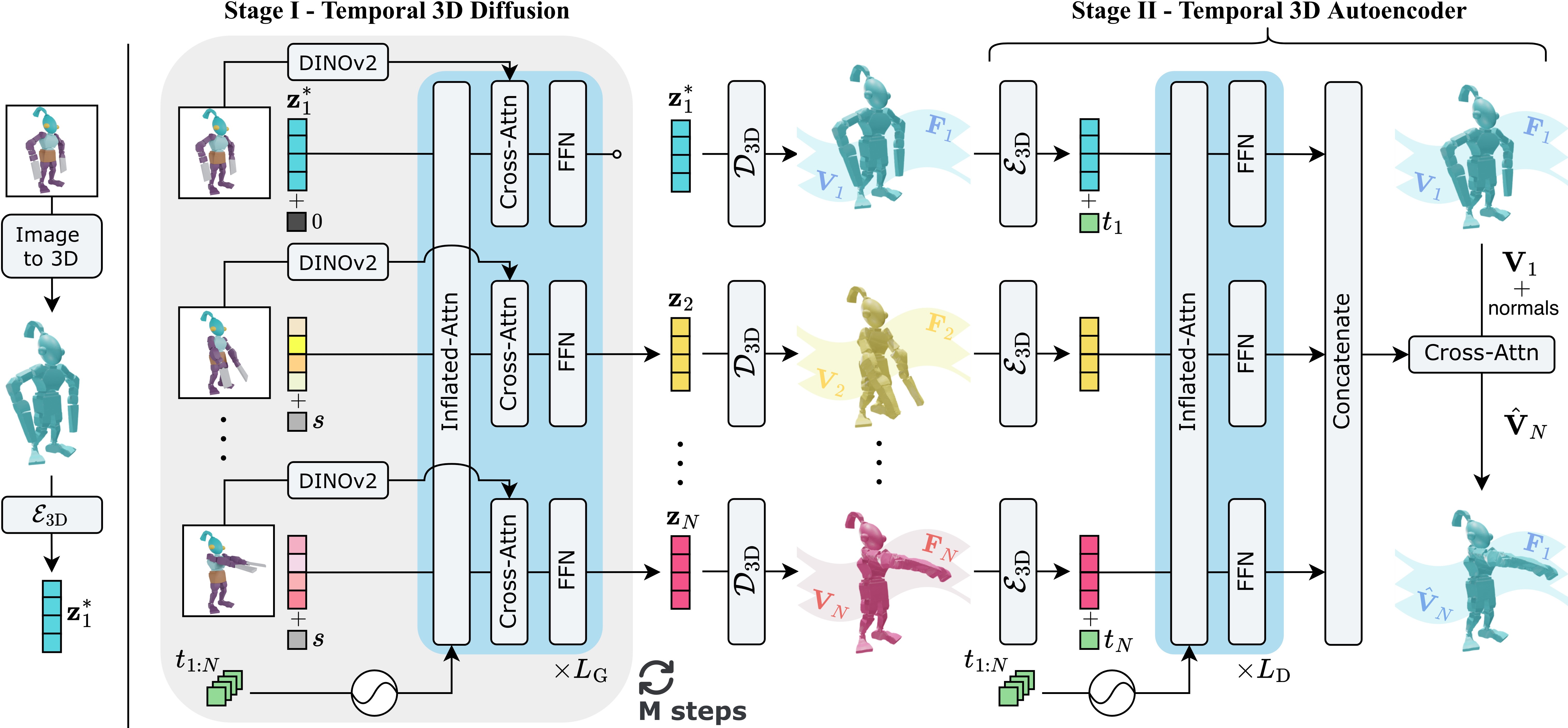
ActionMesh — это быстрая feed-forward модель для генерации анимированных 3D-мешей, использующая диффузионные модели и решающая проблему временной согласованности.
Создание реалистичных анимированных 3D-моделей остается сложной задачей, требующей значительных вычислительных ресурсов и зачастую приводящей к компромиссам в качестве или скорости генерации. В данной работе представлена модель ActionMesh: Animated 3D Mesh Generation with Temporal 3D Diffusion, которая решает эту проблему путем создания готовых к производству анимированных 3D-сеток в режиме прямой передачи. Ключевая идея заключается в адаптации 3D-диффузионных моделей с добавлением временной оси, позволяющей генерировать последовательности согласованных 3D-форм и преобразовывать их в анимацию с сохранением топологии. Может ли предложенный подход стать основой для новых, более эффективных инструментов создания 3D-контента и упростить процесс анимации для широкого круга пользователей?
От формы к движению: вызовы 4D реконструкции
Построение реалистичных и когерентных анимированных 3D-моделей по видеоматериалам — так называемая «Видео-в-4D проблема» — остаётся одной из ключевых задач в области компьютерного зрения. Суть сложности заключается в воссоздании не только геометрической формы объекта, но и его динамического изменения во времени. Современные алгоритмы часто сталкиваются с трудностями в обеспечении временной согласованности, что приводит к мерцанию или разрывам в анимации. Достижение плавного и правдоподобного движения требует точного отслеживания деформаций, текстур и освещения на протяжении всей видеопоследовательности, а также эффективного заполнения пропущенных данных и устранения шумов, что представляет собой значительный вычислительный вызов и требует разработки инновационных подходов к обработке видеоинформации.
Традиционные методы трехмерной реконструкции часто сталкиваются с проблемой временной согласованности, что приводит к появлению мерцающих или прерывистых анимаций. Суть сложности заключается в том, что при создании последовательности трехмерных моделей из видеоряда, незначительные ошибки в каждом кадре накапливаются со временем, вызывая визуальные артефакты. Особенно заметно это при реконструкции динамичных сцен или объектов с мелкими деталями, где даже небольшое смещение или искажение геометрии может привести к заметному “дрожанию” или разрывам в анимации. Это связано с тем, что большинство алгоритмов фокусируются на восстановлении геометрии в каждом отдельном кадре, не учитывая должным образом плавность перехода между кадрами и сохранение целостности формы во времени. В результате, восстановленная трехмерная модель может казаться нестабильной и неестественной, что снижает реалистичность и качество визуализации.
Существующие методы трехмерной реконструкции зачастую испытывают трудности с фиксацией тонких деталей и динамических изменений в объектах. Это связано с тем, что большинство алгоритмов фокусируются на общей форме и структуре, упуская из виду незначительные, но важные деформации, такие как мимика лица, колебания ткани или изменения в выражении эмоций. В результате, реконструированные модели могут казаться статичными или нереалистичными, особенно при воспроизведении сложных движений. Поэтому, для достижения действительно правдоподобной анимации, необходимы инновационные подходы, способные улавливать и воспроизводить мельчайшие нюансы, определяющие естественность и реалистичность движения.

ActionMesh: латентная диффузия для динамического 3D
ActionMesh использует прямое генеративное моделирование, основанное на подходе ‘Temporal 3D Diffusion’, для преобразования входных данных в анимированные 3D-сетки. В основе лежит процесс диффузии, адаптированный для работы с трехмерными данными и временными последовательностями, что позволяет генерировать динамические 3D-модели непосредственно из входного сигнала без необходимости в итеративных процессах, характерных для других генеративных моделей. Этот подход обеспечивает возможность создания анимации 3D-сетки на основе входных данных, представляющих собой, например, видео или текстовые описания, посредством прямого отображения входного сигнала в выходную 3D-анимацию.
Модель ActionMesh использует представление в латентном пространстве, известном как ‘VecSet’, для кодирования и захвата внутренней структуры и динамики трехмерных форм. VecSet представляет собой набор векторов, описывающих геометрию и ее изменения во времени. Использование латентного пространства позволяет эффективно сжимать данные, сохраняя при этом важные детали, необходимые для реалистичной анимации. Вместо непосредственной работы с большим количеством вершин и полигонов, модель манипулирует этими компактными векторными представлениями, что снижает вычислительные затраты и повышает скорость генерации анимации.
Использование латентного пространства, в частности представления VecSet, позволяет ActionMesh достичь значительного улучшения эффективности и реалистичности по сравнению с традиционными методами генерации динамических 3D-моделей. Работа в латентном пространстве снижает вычислительную сложность за счет оперирования с более компактными представлениями данных, что позволяет обрабатывать более сложные анимации и модели с меньшими затратами ресурсов. Кроме того, латентное пространство способствует созданию более плавных и правдоподобных деформаций, поскольку модель обучается на сжатых представлениях динамики, что приводит к уменьшению артефактов и повышению визуального качества генерируемых 3D-моделей.

Моделирование времени с помощью расширенного внимания и не только
Для обеспечения временной согласованности, ActionMesh использует механизм ‘Inflated Attention’ — расширение стандартных механизмов внимания, разработанное для обработки последовательностей 3D-латент. В отличие от стандартного внимания, которое обрабатывает каждый момент времени независимо, ‘Inflated Attention’ учитывает контекст предыдущих и последующих латентов, что позволяет модели лучше понимать и прогнозировать изменения в 3D-пространстве во времени. Это достигается путем расширения матрицы внимания, чтобы включить информацию о более широком временном окне, что способствует созданию более плавных и реалистичных анимаций. Данный механизм эффективно обрабатывает последовательности 3D-латент, представляющих собой компактное представление 3D-сцены в каждый момент времени.
Внедрение вращающихся позиционных вложений (Rotary Positional Embedding, RoPE) значительно улучшает способность механизма внимания модели ActionMesh к моделированию временных зависимостей. RoPE кодирует позиционную информацию, используя вращения в пространстве латентов, что позволяет модели учитывать не только порядок, но и длительность движений. В отличие от абсолютных позиционных кодировок, RoPE использует относительные позиции, что обеспечивает лучшую обобщающую способность и устойчивость к изменениям длины последовательности. Этот подход позволяет эффективно захватывать долгосрочные зависимости во временных рядах 3D-латент, что критически важно для генерации когерентных и реалистичных анимаций.
Для повышения точности и детализации генерируемых анимаций ActionMesh использует методы обучения с подкреплением, такие как ‘Flow Matching’, и ‘Masked Generation’. ‘Flow Matching’ позволяет модели оптимизировать процесс диффузии, направляя его к более реалистичным траекториям движения. ‘Masked Generation’ предполагает маскирование определенных частей генерируемой последовательности, заставляя модель предсказывать недостающие данные и тем самым улучшая когерентность и правдоподобность анимации. Оба метода применяются в процессе диффузии, позволяя модели эффективно изучать сложные временные зависимости и генерировать более качественные результаты.
ActionMesh использует архитектуру диффузионной модели в латентном 3D-пространстве, что позволяет эффективно генерировать сложные анимации. В качестве отправной точки для генерации начальной формы используется TripoSG — система, предоставляющая реалистичные 3D-модели. Такой подход позволяет снизить вычислительную нагрузку, поскольку диффузионный процесс применяется не к пикселям, а к компактному латентному представлению формы, полученному от TripoSG. Это значительно ускоряет процесс обучения и генерации анимаций, сохраняя при этом высокое качество и детализацию.

Валидация и более широкие последствия для компьютерного зрения
Работа ActionMesh демонстрирует передовые результаты на наборе данных ‘Consistent4D’, подтверждая его превосходство в задаче 4D реконструкции. Модель позволяет создавать высококачественные и динамичные 3D анимации, превосходя существующие решения в точности и реалистичности. Полученные данные свидетельствуют о значительном прогрессе в области компьютерного зрения, открывая новые возможности для создания интерактивных 3D моделей и реалистичных виртуальных сред. Достигнутая производительность позволяет надеяться на широкое применение технологии в таких областях, как робототехника, анимация и создание цифрового контента.
Оценка качества сгенерированных анимаций проводилась с использованием метрики ‘Chamfer Distance’, позволяющей точно измерить геометрическое соответствие между реконструированными и исходными данными. Результаты демонстрируют значительное повышение точности и реалистичности анимаций, созданных ActionMesh, по сравнению с существующими методами. В частности, зафиксировано улучшение на 21% по метрике CD-3D, оценивающей точность 3D-реконструкции, на 46% по CD-4D, учитывающей временную согласованность 4D-анимаций, и на 45% по CD-M, измеряющей соответствие между мешами. Эти показатели подтверждают, что ActionMesh обеспечивает высокую степень детализации и точности в процессе 4D-реконструкции, открывая новые возможности для применения в различных областях компьютерного зрения и графики.
Основой успеха ActionMesh является его зависимость от масштабных наборов данных, в частности, от Objaverse. Этот факт подчеркивает возрастающую роль подходов, основанных на данных, в современной компьютерной зримости. Использование огромного количества 3D-моделей позволяет модели эффективно обучаться и обобщать полученные знания для реконструкции сложных анимированных сцен. Становится очевидным, что производительность алгоритмов компьютерного зрения напрямую связана с объемом и качеством данных, используемых для обучения, что открывает новые перспективы для создания более точных и реалистичных систем восприятия и анализа изображений.
Повышение точности 3D-реконструкции в ActionMesh стало возможным благодаря применению алгоритма ‘Iterative Closest Point’ (ICP). Данный метод позволяет выполнять прецизионное выравнивание полученных 3D-моделей, находя наилучшее соответствие между точками в разных кадрах анимации. ICP итеративно уточняет положение и ориентацию модели, минимизируя расстояние между соответствующими точками, что особенно важно для создания реалистичных и плавных движений. Эффективность данного подхода заключается в его способности компенсировать небольшие погрешности, возникающие в процессе захвата данных или при построении моделей, тем самым существенно повышая общее качество и визуальную достоверность реконструируемых анимаций.
![Дополнительное качественное сравнение на наборе данных Consistent4D[14] демонстрирует эффективность предложенного подхода.](https://arxiv.org/html/2601.16148v1/figures/qualitative_c4d_large.jpg)
Исследование, представленное в данной работе, фокусируется на создании анимированных 3D-моделей напрямую из видео, что требует преодоления сложностей, связанных с временной согласованностью и топологической корректностью. Подход ActionMesh, предлагаемый авторами, демонстрирует значительный прогресс в этой области благодаря своей способности к быстрому и эффективному преобразованию видеоданных в готовые к использованию 3D-сетки. Как отмечал Дэвид Марр: «Визуальное восприятие — это процесс построения структур из элементов изображения». В контексте ActionMesh, алгоритм, по сути, строит 3D-структуру из последовательности визуальных кадров, обеспечивая при этом временную согласованность и топологическую корректность, что позволяет создавать убедительные и реалистичные анимации.
Что дальше?
Представленная работа, безусловно, демонстрирует прогресс в создании анимированных 3D-моделей из видео, однако полное понимание системы требует признания сохраняющихся сложностей. Несмотря на улучшенную скорость и топологическую согласованность, вопрос о генерации действительно сложных и детализированных анимаций остаётся открытым. Очевидно, что существующие диффузионные модели, хотя и мощные, всё ещё сталкиваются с трудностями в улавливании тонкостей человеческого движения и передачи его в трёхмерном пространстве.
Перспективным направлением представляется исследование гибридных подходов, сочетающих в себе сильные стороны диффузионных моделей с более традиционными методами анимации и моделирования. Также, важным представляется разработка более эффективных способов контроля над процессом генерации, позволяющих пользователю задавать желаемые характеристики анимации с большей точностью. В конечном итоге, истинный прорыв, вероятно, потребует не просто улучшения существующих алгоритмов, а принципиально нового взгляда на проблему представления и воспроизведения движения.
Иронично, но в погоне за автоматизацией создания 3D-анимации, мы всё ещё зависим от глубокого понимания принципов, лежащих в основе движения и формы. Понимание системы — это не просто создание алгоритма, а постижение самой природы динамики. Визуальные данные, предоставляемые такими моделями, как ActionMesh, становятся лишь отправной точкой для дальнейших исследований, требующих как строгого анализа, так и творческой интуиции.
Оригинал статьи: https://arxiv.org/pdf/2601.16148.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Кванты в Финансах: Не Шутка!
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-23 20:36