Автор: Денис Аветисян
Новая разработка позволяет создавать правдоподобные видеоролики с человеческими фигурами, реагирующие на действия пользователя практически мгновенно.

Представлен фреймворк FlowAct-R1, использующий диффузионные модели, мультимодальное обучение и оптимизацию системы для генерации реалистичных и интерактивных видео с человеческими фигурами в режиме реального времени.
Создание реалистичных и интерактивных видео с человекоподобными персонажами долгое время сталкивалось с противоречием между качеством изображения и скоростью генерации. В данной работе представлена система FlowAct-R1: Towards Interactive Humanoid Video Generation, предназначенная для решения этой проблемы и обеспечивающая потоковую генерацию видео с человекоподобными персонажами в реальном времени. Ключевым нововведением является архитектура, сочетающая диффузионные модели, оптимизацию на системном уровне и многомодальное обучение, позволяющая достичь стабильной частоты 25 кадров в секунду при разрешении 480p и минимальной задержкой. Сможет ли предложенный подход открыть новые горизонты в создании виртуальных ассистентов и интерактивных развлечений с реалистичными цифровыми людьми?
Реалистичные Аватары: Вызов Интерактивной Генерации
Создание реалистичных и интерактивных видео с участием человекоподобных персонажей представляет собой серьезную вычислительную задачу, препятствующую их применению в реальном времени. Проблема заключается в огромном количестве вычислений, необходимых для моделирования сложных движений, реалистичной физики и визуальных деталей, что требует значительных ресурсов процессора и памяти. Современные графические процессоры, несмотря на свою мощность, зачастую не справляются с обработкой данных в достаточно быстром темпе для поддержания интерактивности — то есть, способности мгновенно реагировать на действия пользователя или изменения в окружающей среде. Это ограничивает возможности использования подобных технологий в таких областях, как виртуальная реальность, видеоигры и телеприсутствие, где важна немедленная обратная связь и отсутствие задержек.
Существующие методы генерации реалистичных человекоподобных видео сталкиваются с серьезной проблемой баланса между качеством изображения, скоростью обработки и поддержанием согласованности на протяжении всей последовательности. Достижение высокой детализации и правдоподобия часто требует значительных вычислительных ресурсов, что замедляет процесс и делает невозможным создание видео в реальном времени. Кроме того, поддержание логичной и непрерывной анимации на протяжении длительных периодов представляет собой отдельную трудность: мельчайшие несоответствия в движениях или внешнем виде могут быстро разрушить иллюзию реализма, приводя к неестественным и отвлекающим артефактам. Поэтому, разработка методов, способных одновременно обеспечивать высокую точность, скорость и долгосрочную согласованность, остается ключевой задачей в области компьютерной графики и искусственного интеллекта.
Основная сложность в создании реалистичных, интерактивных человекоподобных видео в режиме реального времени заключается в огромных вычислительных затратах, связанных с диффузионными моделями. Эти модели, хотя и демонстрируют впечатляющие результаты в генерации высококачественных изображений и видео, требуют значительных ресурсов для каждого кадра. Для достижения приемлемой скорости работы необходимы инновационные стратегии оптимизации, включая методы уменьшения размерности данных, квантование и дистилляцию моделей. Исследования направлены на разработку более эффективных архитектур и алгоритмов, позволяющих снизить вычислительную сложность без существенной потери качества генерируемого видео, что открывает путь к созданию интерактивных человекоподобных персонажей для виртуальной реальности, игр и других приложений, требующих мгновенного отклика.
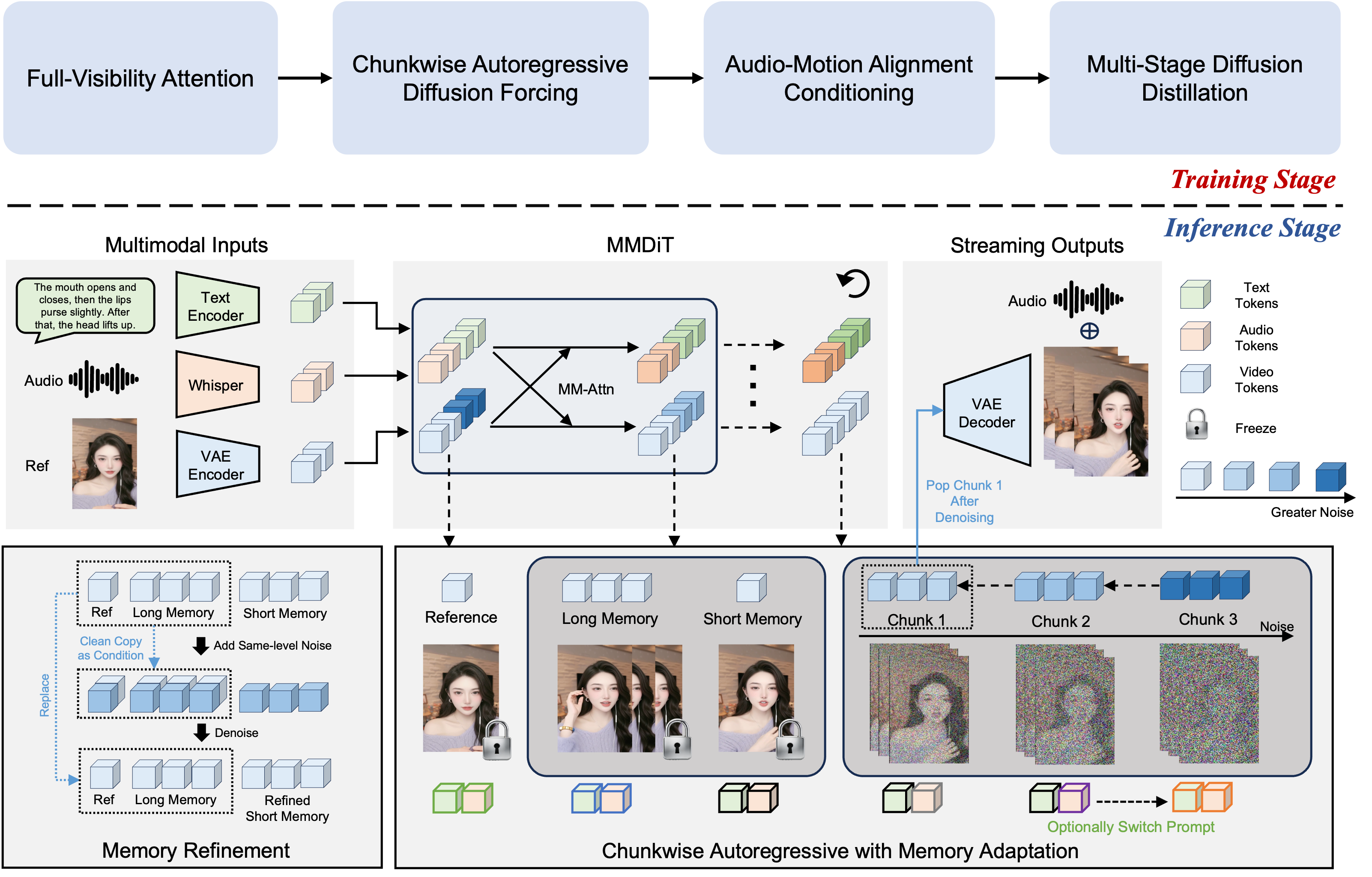
FlowAct-R1: Основа Мультимодального Диффузионного Подхода
FlowAct-R1 использует возможности мультимодальных диффузионных трансформаторов, в частности, архитектуру MMDiT, для генерации видео высокой четкости. MMDiT представляет собой модель, обученную на совместном пространстве изображений и текста, что позволяет ей синтезировать видео, сочетающее визуальную точность и семантическую согласованность. Архитектура MMDiT использует механизм внимания для эффективной обработки и объединения информации из различных модальностей, что приводит к более реалистичным и когерентным видеопоследовательностям. Ключевым преимуществом использования MMDiT является его способность генерировать видео с высоким разрешением и детализацией, сохраняя при этом временную согласованность и избегая артефактов, часто возникающих при других методах генерации видео.
В основе FlowAct-R1 лежит архитектура, развивающая принципы, реализованные в Seedance. Seedance продемонстрировала эффективность в обеспечении согласованности во времени и понимания взаимосвязей между различными модальностями данных, такими как текст и изображения. FlowAct-R1 использует эти наработки для построения надежной основы для генерации видео, где ключевым является сохранение временной последовательности событий и корректная интерпретация взаимосвязи между визуальным контентом и входными данными, например, текстовым описанием или другими модальными сигналами.
Для обеспечения возможности непрерывной генерации видео, система FlowAct-R1 использует адаптацию авторегрессии (Autoregressive Adaptation) для модификации архитектуры MMDiT. Этот процесс предполагает последовательное предсказание следующих кадров видео на основе сгенерированных ранее, что позволяет избежать необходимости полной предварительной генерации всего видеоряда. Адаптация авторегрессии позволяет обрабатывать видеопоток в режиме реального времени, генерируя каждый кадр последовательно, что критически важно для приложений, требующих низкой задержки и возможности потоковой передачи видео.
Оптимизация Скорости и Согласованности: Ключевые Инновации
FlowAct-R1 использует метод Chunkwise Diffusion Forcing для адаптации архитектуры MMDiT к потоковому синтезу, что позволяет существенно снизить вычислительную нагрузку. Данный подход предполагает разделение входных данных на последовательные фрагменты (chunks) и применение диффузионного принуждения к каждому фрагменту независимо. Это позволяет избежать необходимости обработки всей последовательности целиком, что значительно уменьшает объем вычислений и задержку. В результате достигается повышение эффективности и возможность работы в режиме реального времени, что особенно важно для приложений, требующих высокой скорости обработки данных, таких как генерация видео или обработка аудиопотоков.
Вариант Self-Forcing направлен на снижение накопления ошибок в длинных последовательностях генерации, что способствует повышению стабильности и связности результата. В традиционных подходах к последовательной генерации, небольшие ошибки на каждом шаге могут кумулятивно приводить к значительному ухудшению качества итоговой последовательности. Self-Forcing решает эту проблему, используя механизм обратной связи, при котором текущие предсказания используются в качестве входных данных для последующих шагов генерации. Это позволяет модели корректировать свои предсказания на основе предыдущих результатов, уменьшая влияние ошибок и поддерживая согласованность на протяжении всей последовательности. Применение данного подхода особенно важно при генерации длинных текстов или видео, где накопление ошибок может быть критичным.
Для обеспечения долгосрочной временной согласованности в FlowAct-R1 используется надежная стратегия памяти, состоящая из очереди долгосрочной памяти (Long-term Memory Queue) и латентной кратковременной памяти (Short-term Memory Latent). Очередь долгосрочной памяти хранит ключевые состояния и информацию из предыдущих кадров, позволяя модели сохранять контекст на протяжении длительных последовательностей. Латентная кратковременная память, функционируя как буфер, удерживает промежуточные представления, необходимые для поддержания согласованности в пределах текущего временного окна. Комбинация этих двух механизмов позволяет эффективно управлять информацией и предотвращать накопление ошибок, обеспечивая стабильность и реалистичность генерируемых последовательностей даже при больших длинах.
Эффективность вычислений в FlowAct-R1 значительно повышена за счет комплекса оптимизаций, включающего методы дистилляции, оптимизацию на уровне операторов и параллельные вычисления. Данные подходы позволили снизить количество необходимых оценок функций (Number of Function Evaluations, NFE) до всего лишь 3, что обеспечивает возможность работы в реальном времени. Дистилляция позволяет перенести знания из более сложных моделей в более компактные, снижая вычислительные затраты. Оптимизация на уровне операторов включает в себя упрощение и ускорение отдельных операций. Использование параллельных вычислений позволяет распределить нагрузку между несколькими вычислительными ядрами, дополнительно сокращая время обработки.
Превосходя Границы: Результаты и Перспективы
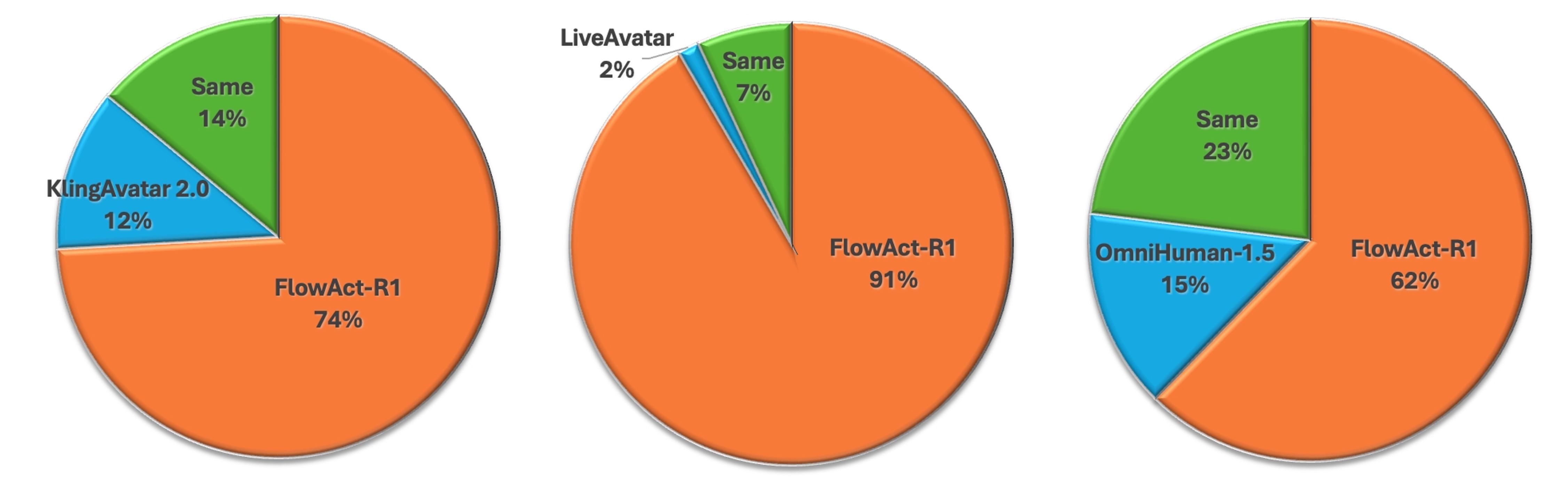
В ходе всестороннего пользовательского исследования, FlowAct-R1 продемонстрировал превосходство над существующими методами, такими как LiveAvatar и KlingAvatar 2.0. Оценка производилась с использованием метрики GSB (Grading Scale for Believability), которая позволяет объективно измерить степень реалистичности и убедительности создаваемых аватаров. Результаты исследования однозначно показали, что FlowAct-R1 генерирует более правдоподобные и естественные движения, что подтверждается более высокими оценками по GSB по сравнению с аналогами. Данное превосходство указывает на значительный прогресс в области создания реалистичных виртуальных персонажей и открывает новые возможности для применения в различных сферах, от развлечений до образования.
В основе реалистичной синхронизации губ и движений тела в FlowAct-R1 лежит совместное обучение аудио и движения. В процессе используется Whisper для эффективной компрессии аудиосигнала, что позволяет снизить вычислительные затраты без потери качества. Ключевым элементом является использование большой многомодальной языковой модели (MLLM) для планирования действий. MLLM анализирует аудио и генерирует последовательность соответствующих движений, обеспечивая не только точную синхронизацию губ с речью, но и естественные, правдоподобные жесты и позы. Такой подход позволяет создавать видео, в котором движения персонажа органично сочетаются со звуковым сопровождением, значительно повышая уровень реализма и погружения.
Механизм «Fake-Causal Attention» представляет собой инновационный подход к снижению вычислительной нагрузки и стабилизации процесса генерации реалистичных движений. Вместо традиционного внимания, требующего обработки всей последовательности данных, данный механизм фокусируется на создании «мнимых» причинно-следственных связей между аудиосигналом и генерируемыми движениями. Это позволяет значительно сократить объем вычислений, особенно при работе с длинными последовательностями, и повысить устойчивость модели к шумам и ошибкам. В результате, FlowAct-R1 способна генерировать высококачественные видеоролики с минимальными вычислительными затратами, обеспечивая плавную и реалистичную анимацию даже на менее мощном оборудовании.
В основе достижения исключительного реализма в FlowAct-R1 лежит корреляция аудиосигналов с детализированными движениями, вдохновленная разработками OmniHuman-1.5 и усиленная применением IP-Adapter. Такой подход позволяет системе не просто воспроизводить движения, а синхронизировать их с нюансами звука, создавая правдоподобную анимацию. В результате, FlowAct-R1 способна генерировать видео в разрешении 480p с частотой 25 кадров в секунду, демонстрируя минимальную задержку в 1.5 секунды до появления первого кадра, что открывает новые возможности для создания интерактивного и реалистичного контента.
Представленная работа демонстрирует стремление к элегантности в области генерации видео, воплощая идею о том, что истинное понимание алгоритмов проявляется в их способности создавать плавные, реалистичные изображения. Как однажды заметил Эндрю Ын: «Мы должны стремиться к созданию систем, которые не просто работают, а работают красиво». FlowAct-R1, объединяя диффузионные модели и мультимодальное обучение, достигает впечатляющей временной согласованности и эффективности, что свидетельствует о глубоком понимании принципов генерации видео. Система, способная к генерации реалистичных человекоподобных видео в реальном времени, представляет собой не просто технический прорыв, а шаг к созданию более интуитивных и естественных интерфейсов взаимодействия.
Куда Ведет Поток?
Представленная работа, безусловно, демонстрирует элегантность в стремлении к генерации реалистичных человекоподобных видеопотоков. Однако, стоит признать, что сама природа «реальности» остается ускользающим идеалом. Текущие достижения, хотя и впечатляющие, все еще не лишены артефактов, заметных в привязчивом внимании к деталям. Дальнейшее развитие, несомненно, потребует не только совершенствования диффузионных моделей, но и углубленного понимания принципов восприятия движения человеческим глазом — ведь даже незначительные несоответствия способны разрушить иллюзию.
Будущие исследования, вероятно, сосредоточатся на преодолении ограничения, связанного с вычислительной сложностью. Истинная интерактивность потребует не просто генерации видео в реальном времени, но и адаптации к динамически меняющимся условиям и запросам пользователя. Особенно интересным представляется направление, объединяющее возможности генерации видео с обратной связью от сенсоров и нейроинтерфейсов — создание действительно «живых» цифровых двойников.
В конечном итоге, успех данной области будет измеряться не только техническими характеристиками, но и этическими последствиями. Создание столь реалистичных виртуальных образов неизбежно ставит вопросы об аутентичности, манипуляции и ответственности. Поэтому, в погоне за совершенством, необходимо помнить, что красота кода проявляется через простоту и ясность, а каждый элемент интерфейса — часть симфонии, требующей гармоничного баланса.
Оригинал статьи: https://arxiv.org/pdf/2601.10103.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
2026-01-16 07:09