Автор: Денис Аветисян
Новый метод позволяет создавать более реалистичные видео, перенимая принципы отслеживания движения из существующих моделей.

Исследователи разработали способ дистилляции структурно-сохраняющего движения из модели SAM2 в диффузионные модели для генерации видео, повышая их временную согласованность и реалистичность.
Несмотря на значительный прогресс в области генерации видео, сохранение реалистичной и структурно связной динамики остается сложной задачей, особенно для объектов с гибкой деформацией. В работе ‘Structure From Tracking: Distilling Structure-Preserving Motion for Video Generation’ предложен новый подход, основанный на дистилляции априорных знаний о движении из рекуррентной модели отслеживания видео (SAM2) в диффузионную модель (CogVideoX). Разработанный метод SAM2VideoX, использующий двунаправленное слияние признаков и локальный градиентный поток, позволяет добиться существенного улучшения качества генерируемых видеороликов. Сможет ли данный подход открыть новые возможности для создания более реалистичных и правдоподобных видеопоследовательностей, особенно в сложных динамических сценах?
Вызов Реалистичной Видеогенерации
Современные модели генерации видео часто сталкиваются с проблемой реалистичной передачи движения, что приводит к появлению неестественных и даже «парящих» объектов в сгенерированных роликах. Данное ограничение связано с трудностями в моделировании физических взаимодействий и динамики сложных сцен. Вместо плавного и правдоподобного движения, алгоритмы нередко создают визуальные артефакты, когда объекты перемещаются рывками или не подчиняются законам гравитации. Это особенно заметно в сложных сценах с большим количеством движущихся элементов, где поддержание когерентности и физической достоверности требует значительных вычислительных ресурсов и усовершенствованных алгоритмов. В результате, создаваемые видеоролики, хоть и визуально привлекательные, часто лишены необходимого уровня реализма, что снижает эффект погружения и ограничивает их применение в требовательных сферах, таких как виртуальная реальность и кинематограф.
Для создания действительно захватывающих визуальных впечатлений, крайне важна согласованность движений во времени и их физическая правдоподобность. Неестественные или «плавающие» объекты моментально разрушают иллюзию реальности, отвлекая зрителя от происходящего. Достижение плавных, реалистичных перемещений требует точного моделирования физических законов, таких как гравитация и инерция, а также учета взаимодействия объектов между собой. Успех в этой области напрямую зависит от способности систем генерировать не просто отдельные кадры, но и последовательность, в которой каждое движение логически вытекает из предыдущего, создавая убедительную и целостную картинку для восприятия.
Существующие методы генерации видео зачастую сталкиваются с трудностями в эффективной дистилляции и переносе информации о движении, что негативно сказывается на реалистичности итогового результата. Вместо точного воспроизведения сложных кинематических закономерностей, алгоритмы нередко упрощают движение, создавая эффект «плавающего» объекта или неестественной анимации. Это связано с тем, что извлечение ключевых характеристик движения из исходных данных и последующее их применение к новым объектам или сценам требует сложной обработки и глубокого понимания физических принципов. Отсутствие эффективных механизмов для сохранения временной согласованности и физической правдоподобности движения приводит к тому, что сгенерированные видеоролики, хотя и визуально привлекательные, не способны полностью обмануть восприятие зрителя и создать ощущение подлинности.

SAM2VideoX: Дистилляция Движения для Повышенного Реализма
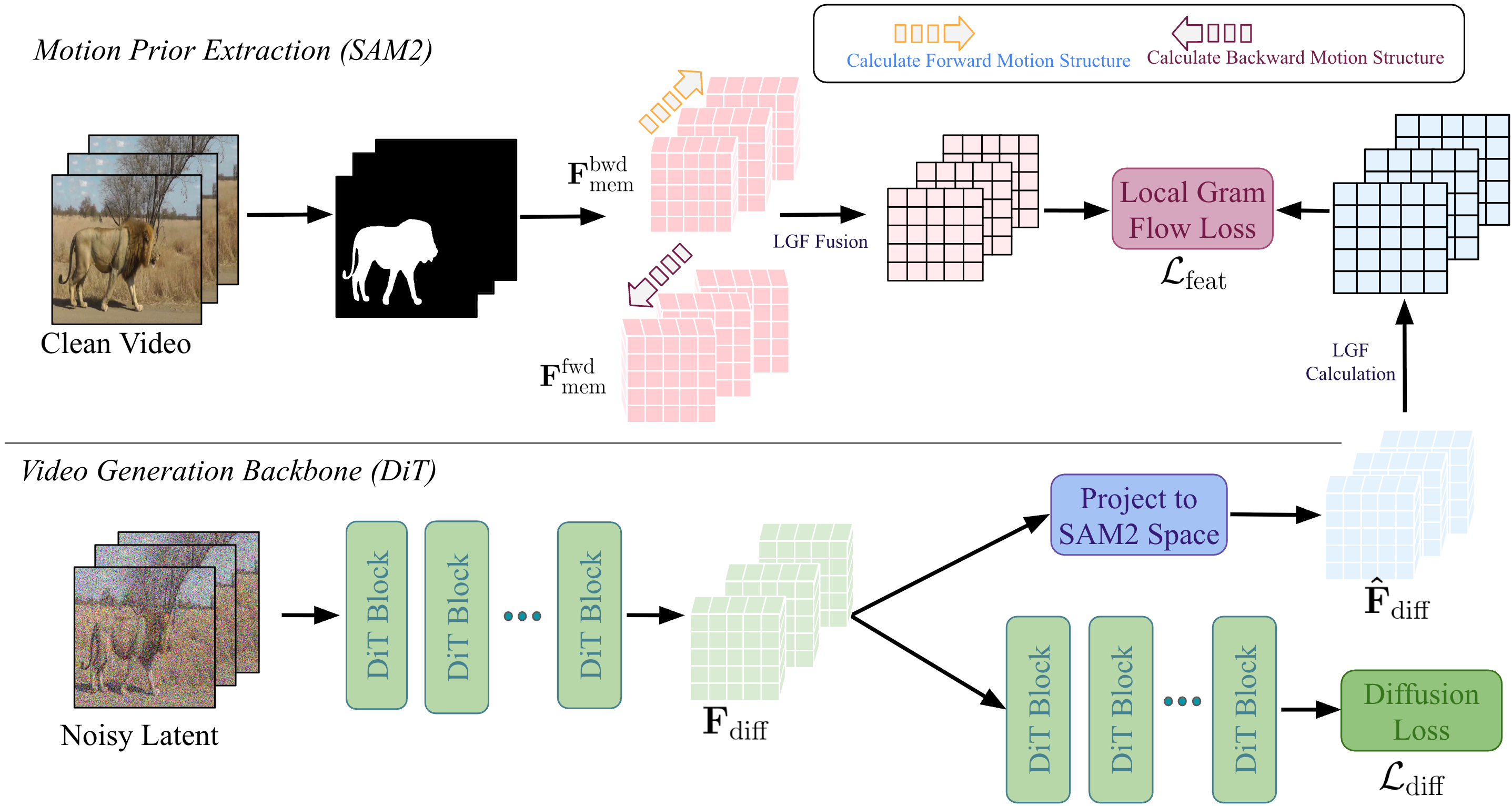
SAM2VideoX представляет новый подход к дистилляции априорных знаний о движении из мощной модели видео-трекинга SAM2. Метод заключается в извлечении информации о траекториях и динамике объектов, отслеживаемых SAM2, и последующей передаче этих данных в модель видео-диффузии. В процессе дистилляции используются данные о положении, скорости и ускорении объектов, что позволяет модели генерировать видео с повышенной согласованностью во времени и реалистичным отображением движения. Ключевым аспектом является использование SAM2 в качестве «учителя», передающего знания о движении модели-студенту для улучшения качества генерируемого видео.
Метод, используемый в SAM2VideoX, осуществляет передачу знаний об движении объектов из модели отслеживания видео SAM2 непосредственно в модель диффузии видео. Это достигается путем использования информации о траекториях и скоростях объектов, полученной от SAM2, в качестве управляющих сигналов для процесса генерации видео. В результате, модель диффузии ориентируется на сохранение согласованности во времени, предотвращая резкие изменения в положении или деформации объектов между кадрами, и обеспечивая плавное и реалистичное движение на протяжении всей сгенерированной видеопоследовательности.
Использование SAM2 позволяет модели сохранять структуру объектов и реалистичные паттерны движения на протяжении всего генерируемого видео. SAM2 предоставляет информацию о траекториях и деформациях объектов, которая используется в качестве руководства для модели диффузии. Это позволяет избежать временных несоответствий и артефактов, обеспечивая, что объекты в видео сохраняют свою форму и перемещаются правдоподобным образом. В процессе генерации видео, модель опирается на данные SAM2 для прогнозирования последующих кадров, гарантируя, что изменения в положении и форме объектов соответствуют физическим принципам и визуальным ожиданиям.

Согласование Приоритетов Движения с Видеогенерацией
В качестве оператора сопоставления признаков для выравнивания пространственно-временных характеристик между SAM2 и моделью видео-диффузии используется Local Gram Flow. Этот метод сопоставляет признаки, извлеченные из SAM2, с признаками в модели диффузии, обеспечивая соответствие между представлениями движения в обеих системах. Local Gram Flow вычисляет градиенты признаков и использует их для определения степени сходства между пространственно-временными областями, что позволяет точно сопоставлять динамические элементы в видео. Точное выравнивание признаков критически важно для передачи информации о движении от SAM2 к модели диффузии, обеспечивая согласованность и реалистичность генерируемого видео.
Выравнивание, дополнительно уточняемое функцией потерь Local Gram Flow, обеспечивает точное включение априорных данных о движении в модель диффузии. Local Gram Flow Loss минимизирует расхождение между признаками движения, полученными из SAM2 и моделью диффузии, что позволяет модели генерировать видео, согласованные с заданными движениями. Оптимизация на основе данной функции потерь способствует сохранению временной когерентности и реалистичности генерируемых видеопоследовательностей, поскольку она напрямую влияет на соответствие генерируемых кадров априорным данным о движении, заданным в SAM2. Эффективность Local Gram Flow Loss заключается в ее способности точно настраивать процесс диффузии, гарантируя, что генерируемые кадры будут соответствовать желаемой динамике движения.
В SAM2 используется двунаправленное объединение признаков (Bidirectional Feature Fusion) для создания надежного обучающего сигнала (teacher signal), улучшающего качество управления движением в процессе генерации видео. Этот процесс предполагает объединение признаков, извлеченных из текущего и предыдущего кадров, что позволяет модели более точно понимать и воспроизводить временные зависимости. Двунаправленное объединение позволяет учитывать контекст как до, так и после текущего кадра, что повышает устойчивость и точность генерируемого движения, особенно в сложных сценах или при наличии быстрых изменений. Такой подход обеспечивает более надежное руководство для модели видеодиффузии, что приводит к более реалистичному и согласованному движению в сгенерированном видеопотоке.
Архитектура DiT (Diffusion Transformer) в используемой модели видеодиффузии обеспечивает эффективную обработку и генерацию видеоданных благодаря своей способности к параллельной обработке и масштабируемости. В основе DiT лежит применение трансформеров, что позволяет модели улавливать долгосрочные зависимости во временных последовательностях, критичные для генерации когерентного видео. Использование аттеншн-механизмов в архитектуре DiT позволяет эффективно обрабатывать большие объемы данных и снижает вычислительную сложность по сравнению с рекуррентными сетями, что способствует более быстрой генерации видео высокого разрешения. $O(n^2)$ вычислительная сложность аттеншн частично компенсируется использованием разреженных аттеншн-слоев и оптимизированных реализаций, что делает DiT подходящей для задач генерации видео в реальном времени.
Количественные и Качественные Результаты: Доказательство Эффективности
Оценка с использованием VBench и Fréchet Video Distance (FVD) продемонстрировала существенные улучшения в качестве видео и согласованности движения при использовании SAM2VideoX. Данная модель демонстрирует превосходные результаты в сохранении четкости изображения и реалистичности динамики, что подтверждается снижением показателя FVD. В частности, SAM2VideoX достигает значения FVD 360.57, что свидетельствует о значительном прогрессе по сравнению с альтернативными подходами к тонкой настройке, таким как REPA и LoRA, и подчеркивает способность модели генерировать более правдоподобные и визуально привлекательные видеоматериалы. Полученные данные подтверждают, что SAM2VideoX представляет собой значительный шаг вперед в области генерации видео, обеспечивая более высокое качество и плавность движения по сравнению с существующими решениями.
Результаты количественного анализа демонстрируют значительное улучшение качества генерируемого видео с использованием SAM2VideoX. Модель достигла показателя Fréchet Video Distance (FVD) в 360.57, что свидетельствует о существенном снижении различий между сгенерированным и реальным видео по сравнению с альтернативными методами. В частности, данный показатель на 21.20% ниже, чем при использовании метода REPA, и на 22.46% ниже, чем при использовании LoRA-тонкой настройки. Низкий показатель $FVD$ указывает на то, что генерируемое видео обладает большей реалистичностью и визуальным качеством, что делает SAM2VideoX перспективным инструментом для задач создания и обработки видеоматериалов.
Модель SAM2VideoX продемонстрировала превосходную способность к сохранению плавности и реалистичности движения в генерируемых видео, достигнув показателя в 95.51 балла по шкале VBench. Этот результат значительно превосходит аналогичный показатель, полученный для модели REPA, который составил 92.91 балла. Данное улучшение свидетельствует о более эффективной обработке временной информации и способности SAM2VideoX создавать видеоролики с более естественным и правдоподобным движением объектов, что является критически важным для восприятия качества и реалистичности визуального контента. Повышенный показатель Motion Score подтверждает, что модель способна генерировать видео с меньшим количеством артефактов и более плавной анимацией, что особенно заметно при отображении динамичных сцен и сложных движений.
В ходе оценки на платформе VBench модель SAM2VideoX продемонстрировала выдающийся результат, достигнув показателя Extended Motion Score в 96.03 балла. Этот результат является наивысшим из всех ранее зарегистрированных на данной платформе, что свидетельствует о значительном прогрессе в обеспечении плавности и реалистичности движения в генерируемых видео. Достижение такого высокого балла указывает на превосходную способность модели к последовательному и когерентному воспроизведению динамических сцен, превосходящую существующие аналоги и открывающую новые возможности для создания высококачественного видеоконтента. Высокий показатель подчеркивает эффективность архитектуры модели и используемых алгоритмов обработки движения.
Методы адаптации низкого ранга, известные как LoRA, позволяют существенно упростить процесс тонкой настройки модели SAM2VideoX, делая его более доступным и эффективным. В отличие от традиционных методов, требующих обновления всех параметров модели, LoRA фокусируется на обучении лишь небольшого числа дополнительных параметров, сохраняя при этом исходные веса неизменными. Это значительно снижает вычислительные затраты и требования к объему памяти, что открывает возможности для применения модели на более широком спектре оборудования и для большего числа пользователей. Такой подход не только ускоряет процесс обучения, но и способствует сохранению обобщающей способности модели, предотвращая переобучение и обеспечивая высокую производительность в различных сценариях.
Разработка модели опирается на значительный прогресс в областях обнаружения и сегментации объектов, достигнутый благодаря алгоритму GroundingDINO, а также на современные методы оценки движения, представленные RAFT и VideoMAEv2. Эти технологии, в свою очередь, поддерживают работу REPA, обеспечивая точное отслеживание и реконструкцию объектов в видеопоследовательности. Сочетание этих передовых инструментов позволяет добиться высокой степени согласованности и реалистичности генерируемого видео, улучшая восприятие динамики и обеспечивая плавное отображение движущихся элементов. Благодаря этому подходу, модель способна эффективно обрабатывать сложные сцены и создавать визуально привлекательный контент.

Исследование демонстрирует стремление к созданию видео, в которых движение не просто воспроизводится, но и структурировано, сохраняя когерентность и реалистичность. Это согласуется с представлениями Дэвида Марра о важности организации информации для ее эффективного восприятия. Он говорил: «Интеллект — это способность преобразовывать информацию из одной формы в другую». Подобно тому, как мозг преобразует визуальные данные в осмысленное представление мира, данная работа преобразует данные отслеживания движения в структурированные шаблоны для генерации видео, подчеркивая, что истинная элегантность достигается через глубокое понимание и гармоничное сочетание формы и функции. Метод, предложенный в статье, особенно акцентирует внимание на сохранении структуры движения, что напрямую связано с понятием когерентности и реализма в генерируемых видеоматериалах.
Что дальше?
Представленная работа, безусловно, делает шаг к более гармоничной генерации видео, но не стоит обманываться кажущейся простотой решения. Извлечение «приоров движения» из модели отслеживания, как бы элегантно это ни звучало, лишь смещает проблему. В конечном итоге, качество генерируемого видео по-прежнему сильно зависит от совершенства исходной модели отслеживания. А совершенство, как известно, требует постоянной доработки, особенно когда речь идет о динамичных, сложных сценах.
Будущие исследования, вероятно, будут сосредоточены на преодолении этой зависимости. Возможно, стоит рассмотреть возможность создания «двигательных приоров», независимых от конкретных моделей отслеживания, или разработать методы, позволяющие «очищать» полученные приоры от артефактов и шумов, присущих любой модели машинного зрения. Или же, что еще более интересно, исследовать возможность интеграции принципов физического моделирования движения непосредственно в архитектуру диффузионных моделей — создать не просто правдоподобное, а физически корректное движение.
Очевидно, что элегантность в генерации видео заключается не в количестве параметров или сложности алгоритмов, а в способности создавать иллюзию естественности и гармонии. И достижение этой гармонии требует не только технических ухищрений, но и глубокого понимания принципов, лежащих в основе движения, и, возможно, даже немного философского осмысления самой природы времени и пространства.
Оригинал статьи: https://arxiv.org/pdf/2512.11792.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовый оптимизатор: Новый подход к сложным задачам
- Оптимизация квантовых вычислений: новый подход к порядку переменных
- Кванты в Финансах: Не Шутка!
- Квантовая обработка данных: новый подход к повышению точности моделей
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Прогнозирование задержек контейнеров: Синергия ИИ и машинного обучения
- Квантовый скачок из Андхра-Прадеш: что это значит?
2025-12-15 17:23