Квантовое тестирование: новая эра контроля качества
По мере развития квантовых вычислений возрастает потребность в принципиально новых методах тестирования, способных обеспечить надежность и корректность квантового программного обеспечения.
По мере развития квантовых вычислений возрастает потребность в принципиально новых методах тестирования, способных обеспечить надежность и корректность квантового программного обеспечения.
Квантовый скачок: От теории к практике Представьте себе, что вы пытаетесь предсказать погоду, но у вас есть только очень грубые данные и неточные инструменты. Вроде того, как пытаться понять сложную систему, используя лишь приблизительные модели. Вот что сейчас происходит в квантовых вычислениях: мы на пороге использования этих мощных инструментов, но должны научиться справляться с их … Читать далее
Исследователи предлагают использовать нейронные сети для оптимизации контурных деформаций, значительно повышая эффективность численного вычисления многомерных интегралов Фейнмана.
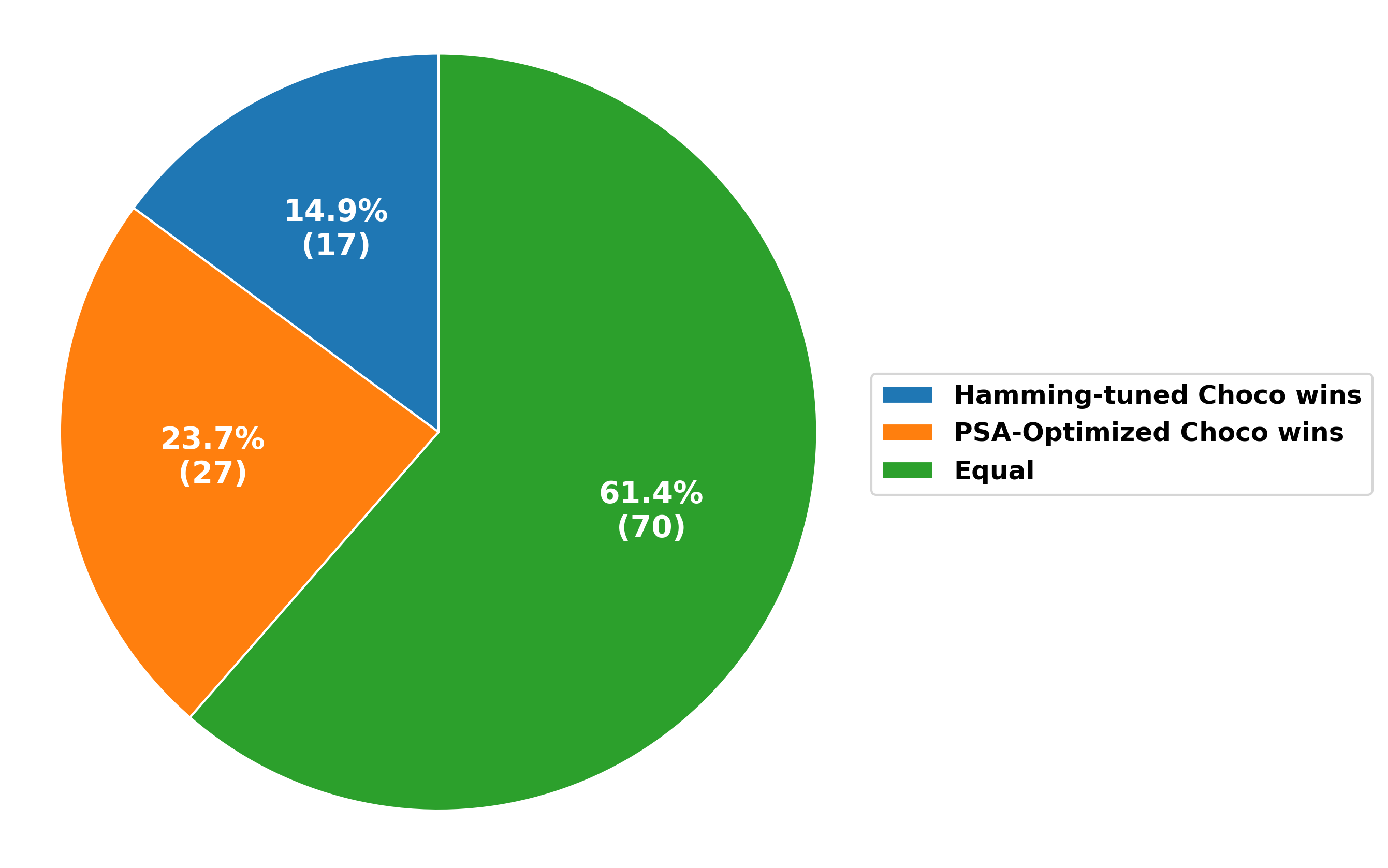
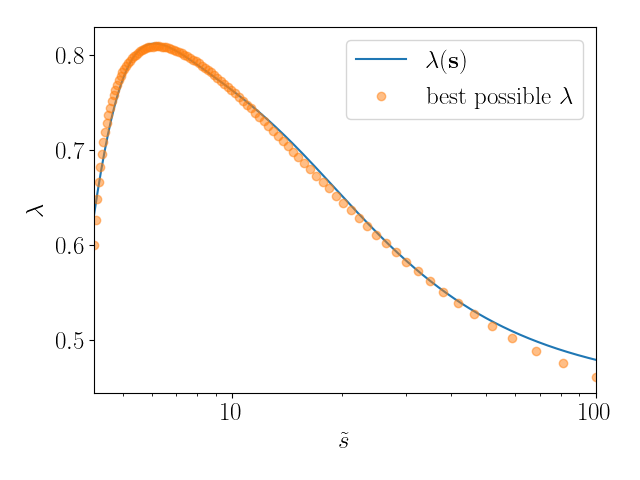
Новый подход позволяет автоматически оптимизировать параметры решателей задач ограничений, значительно повышая их эффективность.
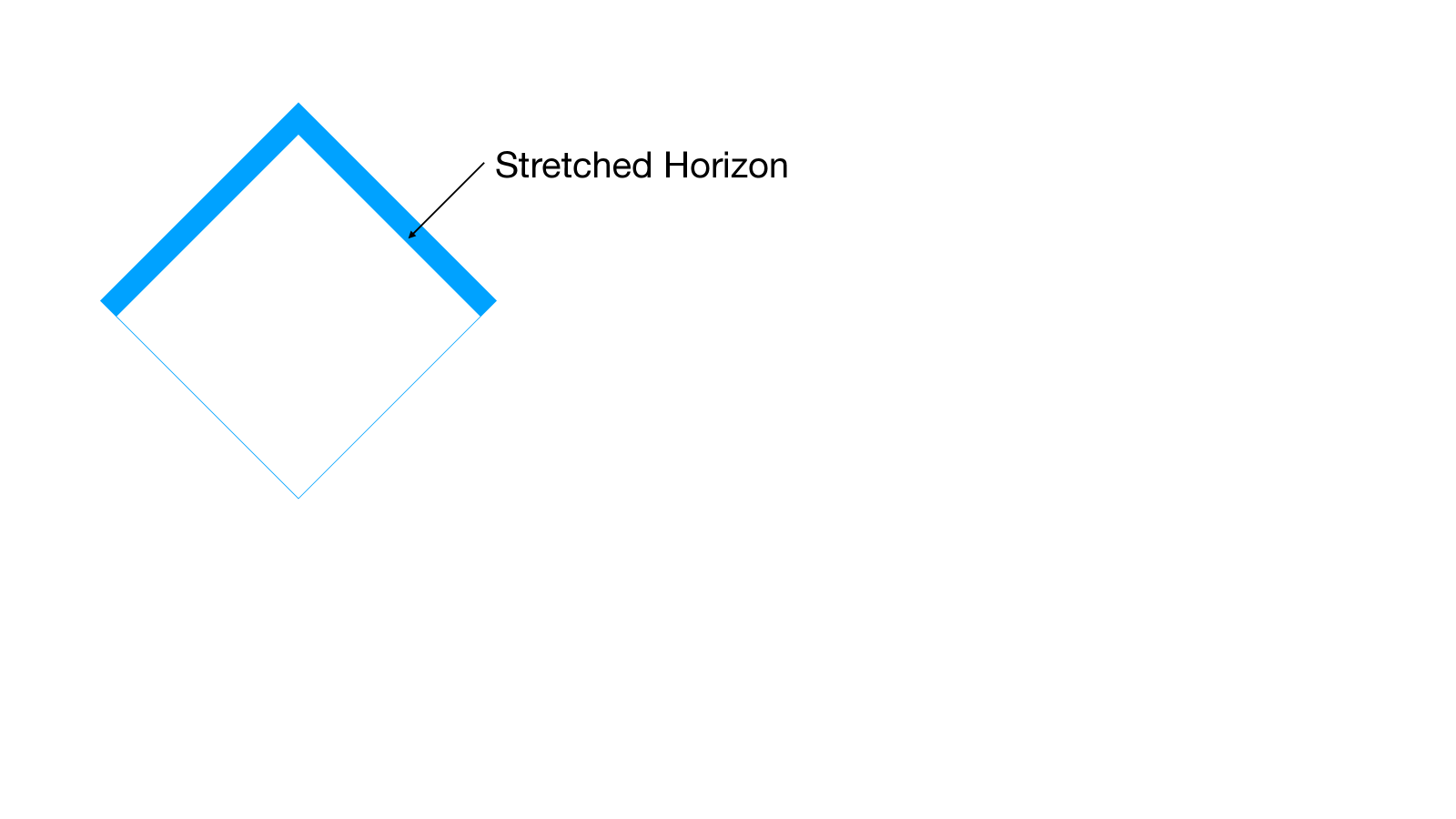
Исследование предлагает гидродинамический подход к пониманию гравитационных интегралов, связывая квантовые плотности вероятности с поверхностями максимального объема.
В статье рассматриваются ключевые аспекты проектирования механических систем ускорителей частиц, обеспечивающие их долговечность и безотказную работу.
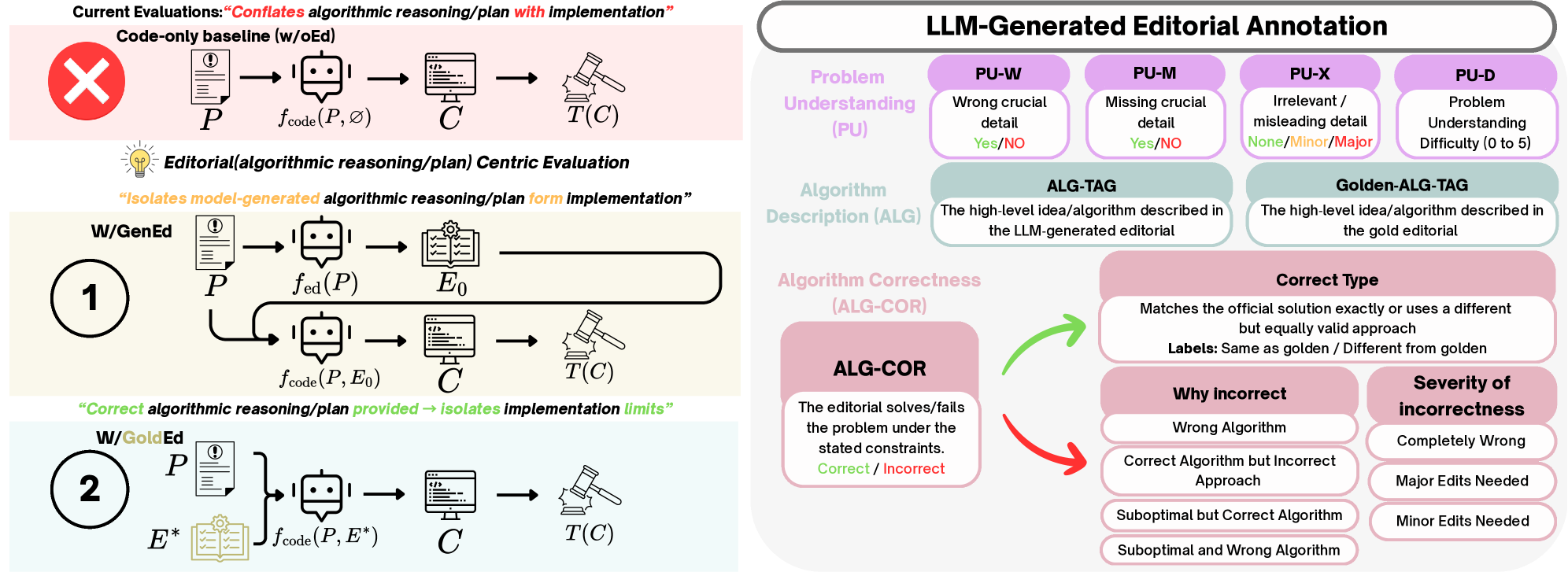
Новое исследование показывает, что оценка способностей больших языковых моделей к решению задач олимпиадного программирования требует четкого разделения этапов логического мышления и написания кода.
![В рамках разработанной системы нейросимволического поиска [latex]NCoTS[/latex] используется оценка потенциала пути, основанная на дистилляции политики от обучающей модели, для захвата возможностей высокоуровневого планирования, а также предсказание прогресса рассуждений на уровне токенов посредством плотного обучения, что позволяет модели во время работы останавливаться в ключевых точках для оценки различных вариантов дальнейших рассуждений с использованием двойного эвристического критерия.](https://arxiv.org/html/2601.11340v1/x2.png)
Новый подход позволяет большим языковым моделям активно исследовать различные цепочки рассуждений, повышая точность и эффективность ответов.
![Процесс TSQCA итерирует по заданному диапазону пороговых значений, применяя стандартный анализ качественного сравнительного анализа (QCA) посредством функций [latex]QCA::truthTable()[/latex] и [latex]QCA::minimize()[/latex] из пакета QCA, агрегируя результаты для предоставления сводной таблицы межпорогового сравнения и детальных данных для каждого порога.](https://arxiv.org/html/2601.11229v1/figures/Figure2_workflow.png)
Исследование представляет пакет TSQCA, позволяющий систематически анализировать влияние пороговых значений на результаты качественного сравнительного анализа (QCA).
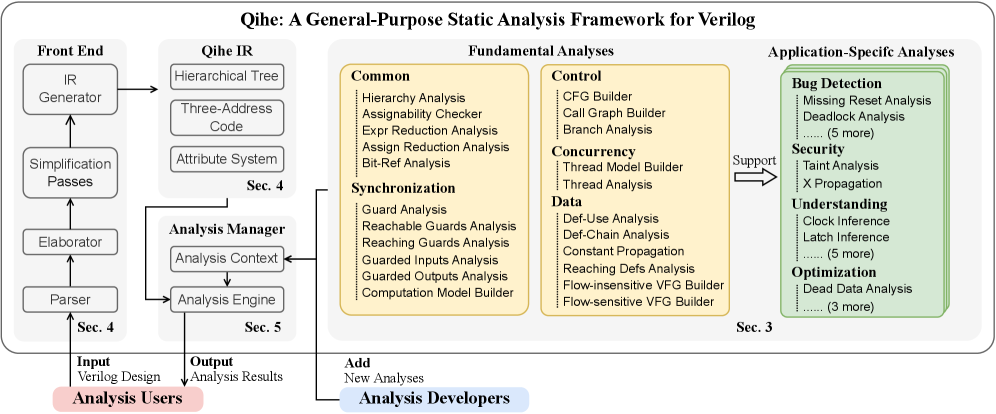
Представлен Qihe — универсальный фреймворк для статического анализа Verilog, открывающий возможности для глубокого понимания и верификации аппаратного обеспечения.