Понимание видео от первого лица: как большие языковые модели отвечают на вопросы
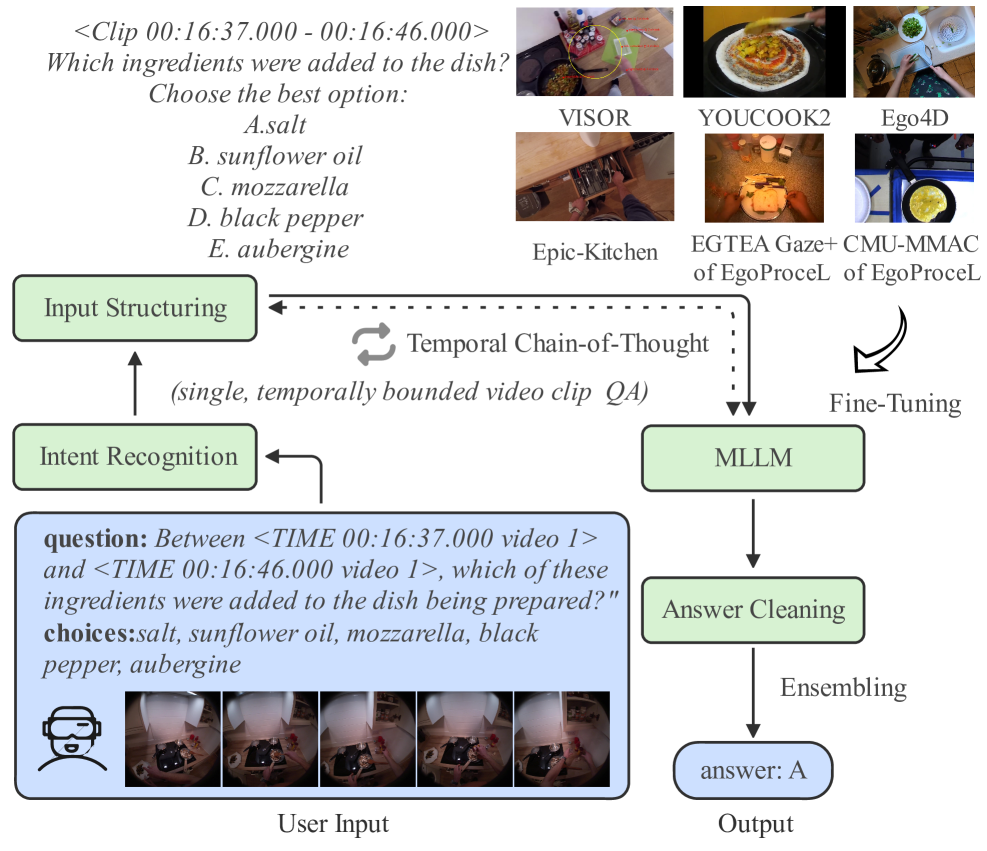
Новое исследование демонстрирует, как можно значительно улучшить способность нейросетей понимать сложные видеозаписи, снятые от первого лица, и отвечать на вопросы о них.
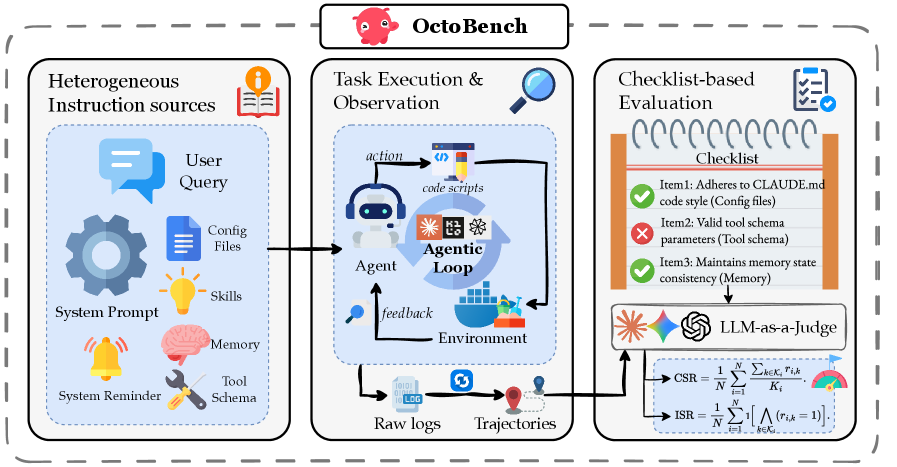
![При численном решении уравнения [latex]\eqref{eq.12}[/latex] и исследовании частоты активации нейронов в зависимости от входного сигнала [latex]I[/latex], обнаруживается, что все кривые настройки соответствуют либо](https://arxiv.org/html/2601.10482v1/Figures/ONOFF_Coding.png)

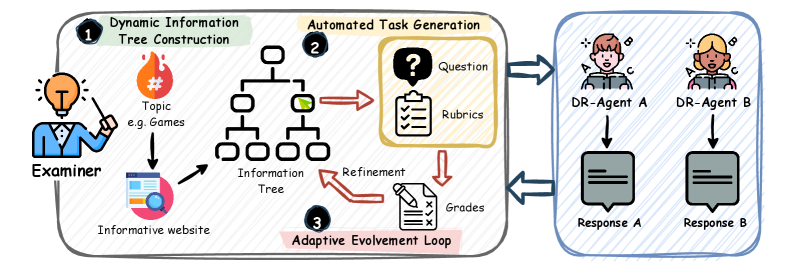
![Исследование демонстрирует масштабируемость системы при [latex]n=m=2^{12}[/latex], подтверждая её способность эффективно функционировать при увеличении вычислительной сложности.](https://arxiv.org/html/2601.10511v1/texfig/delta5000.png)
![На представленной схеме выделены рог ячейка [latex]\mathfrak{C}[/latex] и щелевой диск [latex]\mathbb{D}_{\text{s}}[/latex], границы которых обозначены пунктирными линиями, что позволяет визуализировать их геометрические характеристики и взаиморасположение.](https://arxiv.org/html/2601.09795v1/x2.png)
![В исследовании динамики углового момента при [latex] \gamma = 0 [/latex] и [latex] \gamma = 2 [/latex] установлено, что начальные условия (F и S) влияют на эволюцию орбитального и спинового угловых моментов, причем нормализация к суммарному угловому моменту в начальный момент времени позволяет оценить относительный вклад каждого компонента в общую динамику системы.](https://arxiv.org/html/2601.10136v1/x2.png)