Автор: Денис Аветисян
Новая архитектура Aeon позволяет агентам искусственного интеллекта сохранять и использовать информацию на качественно новом уровне, открывая путь к более сложным и последовательным взаимодействиям.
Aeon — это когнитивная операционная система, оптимизирующая семантическую память за счет иерархического индекса и архитектуры без копирования данных, что значительно повышает скорость извлечения информации и обеспечивает более связное поведение агентов на больших временных горизонтах.
Несмотря на впечатляющие возможности больших языковых моделей (LLM), их производительность ограничена квадратичной сложностью механизма внимания и ухудшением логических рассуждений при расширении контекстного окна. В данной работе, посвященной системе ‘Aeon: High-Performance Neuro-Symbolic Memory Management for Long-Horizon LLM Agents’, предлагается принципиально новый подход к организации семантической памяти, рассматривающий ее не как статичное хранилище, а как управляемый ресурс операционной системы. Aeon объединяет иерархический индекс с архитектурой нулевого копирования, обеспечивая субмиллисекундное извлечение информации и поддерживая согласованность состояния агента. Способна ли подобная организация памяти радикально улучшить когерентность поведения автономных агентов в долгосрочных взаимодействиях?
Преодолевая Границы Контекста: Ограничения Современных LLM
Современные большие языковые модели, несмотря на впечатляющие возможности, сталкиваются с фундаментальным ограничением — фиксированным размером контекстного окна. Это означает, что модель способна эффективно обрабатывать лишь ограниченный объем информации за один раз, что существенно затрудняет понимание длинных текстов и решение сложных задач, требующих учета большого количества взаимосвязанных фактов. По сути, модель вынуждена «забывать» информацию, находящуюся за пределами этого окна, что приводит к неполному анализу и, как следствие, к ошибкам в рассуждениях или нелогичным ответам. Это ограничение особенно критично при работе с объемными документами, историческими текстами или при попытке моделировать сложные сценарии, где контекст играет решающую роль в принятии правильных решений.
Основополагающая архитектура Transformer, лежащая в основе современных больших языковых моделей, сталкивается с фундаментальным ограничением, связанным с квадратичной сложностью обработки последовательностей. Это означает, что вычислительные затраты и требования к памяти растут пропорционально квадрату длины входного текста. O(n^2), где n — длина последовательности, определяет экспоненциальный рост ресурсов, необходимых для анализа длинных документов или сложных диалогов. В результате, обработка действительно больших объемов информации становится практически невозможной даже при использовании самых мощных вычислительных систем, что серьезно ограничивает способность моделей к глубокому пониманию контекста и выполнению сложных рассуждений, требующих учета большого количества информации.
Существующие подходы генерации с расширением извлечением (RAG) призваны обойти ограничения фиксированного контекстного окна больших языковых моделей, однако часто сталкиваются с проблемой, известной как «векторный туман». Суть явления заключается в том, что при поиске релевантной информации в векторной базе данных, алгоритм нередко извлекает не только полезные, но и семантически близкие, но нерелевантные фрагменты текста. Это происходит из-за того, что векторные представления слов и фраз могут быть схожими для разных понятий, что приводит к извлечению «шума», снижающего качество генерируемого ответа. Таким образом, несмотря на потенциал RAG, проблема «векторного тумана» требует разработки более точных методов семантического поиска и фильтрации информации, чтобы обеспечить релевантность и достоверность генерируемого контента.
Aeon: Когнитивная Операционная Система для Искусственного Интеллекта
Система Aeon представляет собой Когнитивную Операционную Систему (COS), разработанную для преодоления ограничений памяти, свойственных большим языковым моделям (LLM). В отличие от традиционных LLM, хранящих знания исключительно в параметрах модели, Aeon использует внешнее хранилище знаний, организованное в виде графа. Это позволяет агенту динамически управлять информацией, сохранять и извлекать релевантные данные по мере необходимости, эффективно расширяя возможности памяти и контекстуального понимания. Внешнее хранилище знаний позволяет масштабировать объем доступной информации, не увеличивая при этом размер самой модели, что повышает эффективность и снижает вычислительные затраты.
В основе Aeon лежит концепция ‘Trace’ — нейро-символического ориентированного ациклического графа (DAG), который отслеживает эпизодическое состояние агента. В отличие от традиционных подходов к хранению памяти, Trace представляет собой динамичную и контекстуально релевантную память, поскольку граф постоянно обновляется и адаптируется к текущим взаимодействиям и полученным данным. Каждый узел графа содержит семантические векторы, представляющие собой информацию, полученную агентом, а направленные ребра отражают взаимосвязи и зависимости между этими данными. Эта структура позволяет Aeon эффективно извлекать и использовать релевантную информацию из прошлого опыта, обеспечивая более гибкое и адаптивное поведение.
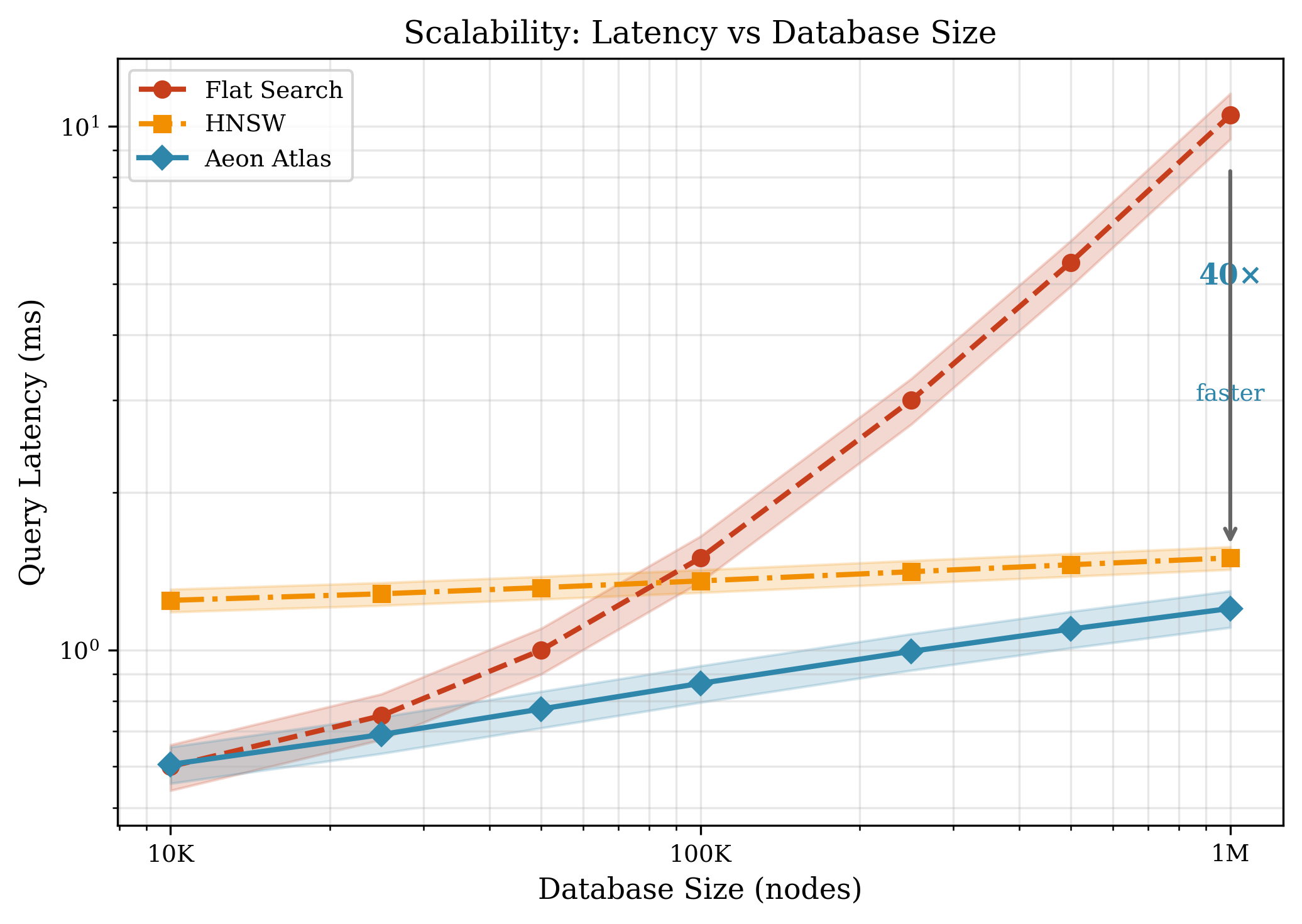
В основе Aeon лежит высокопроизводительная система хранения и извлечения семантических векторов, реализованная с использованием memory-mapped B+ дерева под названием ‘Atlas’. B+ дерево обеспечивает логарифмическую сложность поиска, что критически важно для обработки больших объемов данных. Использование memory-mapping позволяет напрямую отображать данные из файла в оперативную память, минимизируя накладные расходы на ввод-вывод и обеспечивая быстрый доступ к семантическим векторам, необходимым для работы когнитивной системы. Такая архитектура позволяет эффективно хранить и извлекать информацию, формируя основу для динамической и контекстно-зависимой памяти агента.
Эффективное Извлечение: Скорость и Точность
В Aeon для быстрого поиска релевантных семантических векторов используется алгоритм приближённого поиска ближайших соседей (Approximate Nearest Neighbor, ANN), основанный на графах Hierarchical Navigable Small World (HNSW). HNSW представляет собой графовую структуру данных, оптимизированную для эффективного поиска в многомерных пространствах. Иерархическая организация графа позволяет быстро сужать область поиска, а структура «малого мира» обеспечивает высокую скорость доступа к ближайшим соседям. Этот подход позволяет существенно снизить время отклика при поиске семантически близких векторов по сравнению с полным перебором или другими алгоритмами поиска.
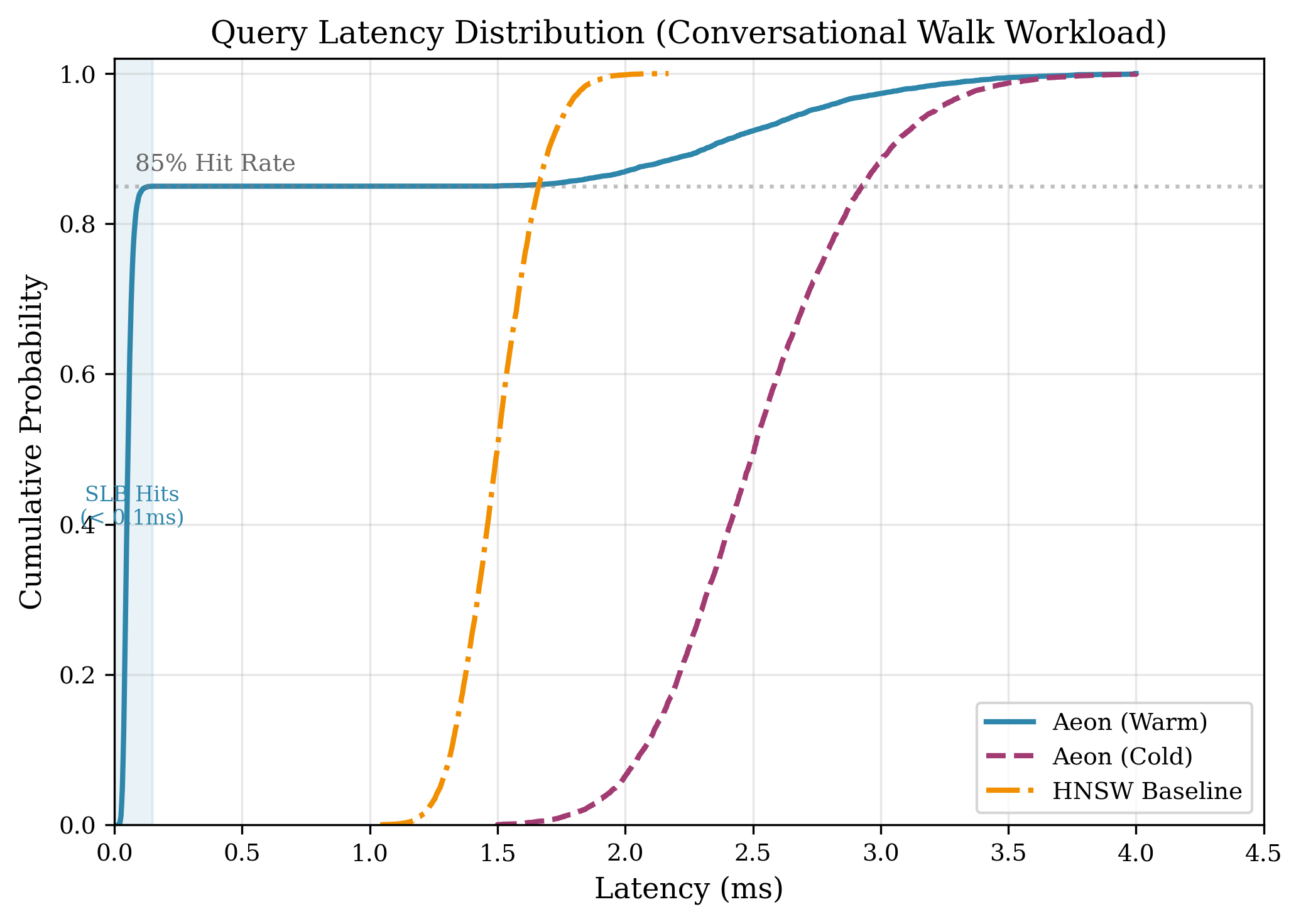
Для дополнительной оптимизации производительности в системе используется Semantic Lookaside Buffer — кэш, хранящий часто запрашиваемые векторы. В ходе тестирования на реалистичных нагрузках, имитирующих диалоговые взаимодействия, достигнута эффективность кэширования в 85%. Это означает, что в 85% случаев запрошенные векторы обнаруживаются в кэше, что значительно снижает задержку и повышает скорость ответа системы.
Эффективная задержка в 0.42 мс демонстрирует высокую отзывчивость системы Aeon. Данный показатель является результатом комплексной оптимизации, включающей использование графов HNSW для приближенного поиска ближайших соседей, кэширование часто используемых векторов с 85% попаданием в Semantic Lookaside Buffer, а также оптимизацию передачи данных между Python и C++ посредством ‘nanobind’ и интерфейса нулевого копирования. Низкая задержка критически важна для интерактивных приложений, таких как диалоговые системы, и позволяет обеспечивать практически мгновенный отклик на запросы пользователей.
Для оптимизации обмена данными между Python и C++ в Aeon используется библиотека ‘nanobind’ и ‘zero-copy интерфейс’. Данный подход позволяет минимизировать накладные расходы при передаче данных, достигая времени передачи 10МБ информации всего за 2 микросекунды. ‘Zero-copy’ интерфейс исключает необходимость копирования данных между адресными пространствами Python и C++, что существенно снижает задержки и повышает общую производительность системы. Использование ‘nanobind’ обеспечивает эффективное и типобезопасное взаимодействие между кодом на Python и C++.

Построение Надёжной и Адаптируемой Системы
В основе архитектуры Aeon лежит дуалистический подход к разработке, сочетающий в себе высокую производительность и гибкость. Критически важные компоненты системы реализованы на языке C++23, что обеспечивает детальный контроль над ресурсами и максимальную скорость выполнения операций. Одновременно с этим, для ускорения прототипирования новых функций и интеграции с внешними системами активно используется Python 3.12. Такое сочетание позволяет разработчикам быстро экспериментировать и внедрять инновации, не жертвуя при этом эффективностью и надежностью ключевых алгоритмов. Данная стратегия позволяет Aeon динамически адаптироваться к изменяющимся требованиям и поддерживать высокую скорость разработки.
Для значительного повышения производительности вычислений, система Aeon активно использует возможности SIMD-ускорения, опираясь на инструкции AVX-512. Этот подход позволяет параллельно обрабатывать несколько элементов данных в рамках одной инструкции, что существенно сокращает время обработки. В результате, ключевой вычислительный модуль системы демонстрирует впечатляющую пропускную способность — всего 50 наносекунд на сравнение векторных данных. Такая скорость обеспечивает эффективную обработку больших объемов информации и позволяет системе быстро реагировать на изменяющиеся условия, делая её особенно подходящей для задач, требующих высокой производительности и минимальной задержки.
В основе системы Aeon лежит концепция «дельта-буфера», позволяющая осуществлять инкрементные обновления базы знаний без необходимости полной перестройки. Такой подход радикально повышает эффективность процесса обучения и адаптации системы к новым данным. Вместо трудоемкой переработки всего объема информации, изменения вносятся лишь в те участки, которые претерпели модификацию. Это обеспечивает не только значительное снижение вычислительных затрат и времени реакции, но и возможность непрерывного обучения в режиме реального времени. Благодаря «дельта-буферу», система Aeon способна динамически эволюционировать, сохраняя при этом высокую производительность и актуальность знаний.
Будущее Когнитивного Искусственного Интеллекта
Проект Aeon представляет собой инновационный подход к созданию искусственного интеллекта, способного к длительному запоминанию и обработке огромных объемов информации. В основе лежит концепция COS (Cognitive Operating System), которая отделяет механизм запоминания от самой языковой модели. Это позволяет агентам не просто генерировать текст, но и накапливать знания, формировать сложные связи между ними и использовать их для принятия обоснованных решений. В отличие от традиционных моделей, где вся информация содержится в параметрах сети и теряется после завершения сеанса, COS создает внешнее, постоянное хранилище знаний, доступное для агента в любой момент. Такой подход открывает перспективы для создания ИИ, способного к обучению на протяжении всей своей «жизни», адаптации к меняющимся условиям и решению задач, требующих глубокого понимания контекста и долгосрочной памяти.
Для повышения надёжности и конфиденциальности когнитивных систем искусственного интеллекта, всё большее внимание уделяется интеграции аппаратных анклавов. Эти специализированные, защищённые области памяти, функционирующие как “безопасные хранилища”, позволяют изолировать и защитить критически важные данные и знания от несанкционированного доступа и манипуляций. Внедрение аппаратных анклавов обеспечивает не только защиту конфиденциальной информации, но и повышает доверие к принимаемым решениям искусственного интеллекта, гарантируя целостность и достоверность используемой базы знаний. Такой подход особенно важен в областях, где точность и надёжность информации имеют первостепенное значение, например, в медицине, финансах и правоохранительных органах, где компрометация данных может иметь серьёзные последствия.
В основе подхода Aeon лежит принципиальное отделение памяти от самой большой языковой модели (LLM), что открывает новые горизонты для масштабирования возможностей искусственного интеллекта. Традиционно, LLM хранят знания непосредственно в своих параметрах, что ограничивает объем доступной информации и затрудняет ее обновление без переобучения всей модели. Aeon, напротив, использует внешнюю базу знаний, к которой LLM обращается для получения необходимой информации. Такое разделение позволяет значительно увеличить объем памяти, доступной системе, а также упрощает процесс обучения и адаптации к новым данным. Более того, это создает основу для построения действительно когнитивных систем, способных не просто генерировать текст, но и рассуждать, планировать и решать сложные задачи, опираясь на обширный и постоянно обновляемый объем знаний.
Представленная работа демонстрирует, что эффективное управление семантической памятью является ключевым фактором для создания когерентных агентов с широким горизонтом планирования. Авторы подчеркивают важность иерархической организации данных и архитектуры нулевого копирования для оптимизации скорости извлечения информации. Это созвучно мысли Брайана Кернигана: «Простота — это высшая степень утонченности». Подобно тому, как элегантный дизайн требует минимализма, так и эффективная система управления памятью нуждается в оптимизации структуры для достижения максимальной производительности и ясности. Разработанная Aeon, как и продуманная городская инфраструктура, позволяет развивать отдельные компоненты без необходимости перестройки всей системы, обеспечивая масштабируемость и долговечность.
Куда Ведет Дорога?
Представленная работа, бесспорно, демонстрирует элегантность подхода к организации семантической памяти. Однако, подобно любому хорошо спроектированному механизму, Aeon лишь частично решает проблему. Скорость извлечения данных — важный параметр, но истинная сложность заключается в динамике знаний. Система, способная быстро находить информацию, еще не является системой, способной к адаптации и самообучению в условиях непредсказуемости реального мира. Необходимо исследовать, как подобная архитектура взаимодействует с постоянно меняющимися представлениями агента о мире, избегая накопления когнитивного “шума”.
Особое внимание следует уделить границам системы. Идея “нулевого копирования” впечатляет своей эффективностью, но возникает вопрос о масштабируемости и поддержании консистентности данных в условиях параллельной обработки и распределенных вычислений. Необходимо помнить, что любая оптимизация имеет свою цену, и важно тщательно оценить, не приводит ли стремление к скорости к потере гибкости и способности к обобщению.
В конечном счете, создание действительно “когнитивной операционной системы” требует не только улучшения технических характеристик, но и глубокого понимания принципов работы интеллекта. Успех в этой области зависит не от количества “хитрых” алгоритмов, а от ясности и простоты базовых принципов организации знаний. Подобно хорошо настроенному музыкальному инструменту, система должна не просто “работать”, а “звучать” гармонично и естественно.
Оригинал статьи: https://arxiv.org/pdf/2601.15311.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-25 11:18