Автор: Денис Аветисян
Исследователи предлагают инновационный подход к непрерывному обучению, фокусирующийся на создании структурированной памяти для повышения эффективности ответов на сложные вопросы.
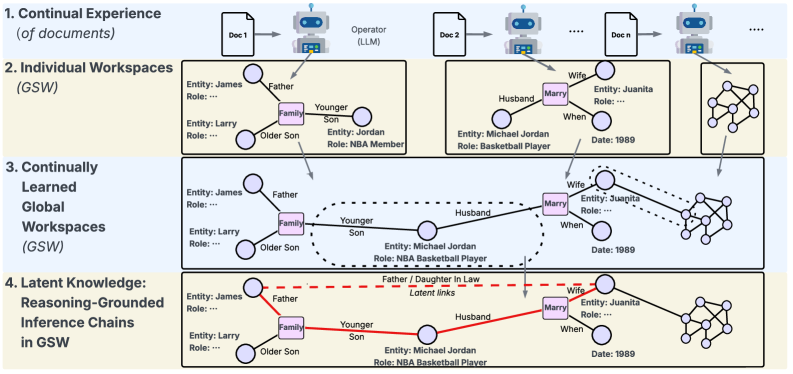
Представлена система Panini, непараметрический фреймворк, использующий структурированную память и механизм извлечения цепочек для повышения точности и надежности многошагового вопросно-ответного анализа.
Современные языковые модели сталкиваются с ограничениями при работе с постоянно меняющейся информацией, требуя повторного анализа больших объемов данных. В статье ‘Panini: Continual Learning in Token Space via Structured Memory’ предложен новый подход к непрерывному обучению, основанный на построении структурированной семантической памяти. Авторы демонстрируют, что инвестиции в организацию опыта на этапе записи позволяют значительно повысить эффективность и надежность многоступенчатого вопросно-ответного анализа, используя представление документов в виде сети «вопрос-ответ». Не откроет ли это путь к созданию более адаптивных и экономичных систем обработки знаний?
Преодолевая Границы Понимания: Вызовы Глубинного Рассуждения в Ответах на Вопросы
Традиционные системы ответов на вопросы сталкиваются с серьезными трудностями при обработке запросов, требующих анализа информации из нескольких источников и выполнения сложных логических выводов. Они зачастую ограничиваются простым извлечением фактов, неспособными синтезировать разрозненные данные для формирования комплексного ответа. Вместо глубокого понимания контекста и установления связей между различными фрагментами информации, такие системы полагаются на поверхностное сопоставление ключевых слов, что приводит к неточностям или неполноте ответа, особенно когда вопрос требует неявного знания или применения здравого смысла. Подобные ограничения подчеркивают необходимость разработки новых подходов, способных к многоступенчатому рассуждению и интеграции информации из различных источников для обеспечения более точных и содержательных ответов.
Существующие методы обработки вопросов и ответов зачастую сталкиваются с трудностями при объединении информации из различных источников, что приводит к неточностям или неполноте ответов. Проблема заключается в неспособности систем эффективно выявлять взаимосвязи между разрозненными данными, а также в недостаточной обработке контекста и нюансов, содержащихся в каждом источнике. В результате, даже если отдельные фрагменты информации верны, их синтез может приводить к ошибочным выводам или неполному освещению темы. Это особенно заметно в задачах, требующих многоступенчатых умозаключений и понимания скрытых связей между фактами, что делает поиск точных и исчерпывающих ответов весьма сложной задачей.

Усиление Рассуждений с Итеративным Поиском и Цепочкой Мыслей
Агентный поиск (Agentic Retrieval) представляет собой механизм итеративного уточнения запросов и сбора релевантной информации из источников знаний. В отличие от однократного поиска, агентный подход предполагает последовательное формирование новых запросов на основе полученных результатов. Каждая итерация использует информацию, полученную на предыдущем шаге, для уточнения исходного запроса или формулирования новых, более конкретных вопросов. Это позволяет модели эффективно исследовать пространство знаний, выявлять сложные взаимосвязи и извлекать информацию, которая могла бы быть упущена при однократном поиске. Итеративный процесс продолжается до достижения заданного критерия остановки, например, достижения определенного уровня релевантности или исчерпания доступных источников информации.
Комбинирование агентного поиска с рассуждениями типа «Цепочка мыслей» (Chain-of-Thought) позволяет моделям не только предоставлять ответ, но и демонстрировать последовательность логических шагов, приведших к этому ответу. Такой подход повышает прозрачность процесса принятия решений моделью, что облегчает верификацию и отладку. Более того, явное представление рассуждений способствует повышению точности ответов, поскольку позволяет модели самостоятельно выявлять и корректировать возможные ошибки на промежуточных этапах. Данная комбинация особенно эффективна в задачах, требующих многоступенчатого анализа и синтеза информации, где понимание логики рассуждений критически важно.
Эффективное решение задач, требующих многошагового рассуждения (multi-hop QA), значительно выигрывает от использования структурированных знаний, представленных в виде графа знаний. Граф знаний позволяет модели не просто находить релевантную информацию, но и устанавливать связи между различными фактами и сущностями. Это обеспечивает возможность последовательного логического вывода, когда ответ на вопрос формируется на основе нескольких связанных фактов, а не только одного. Использование графа знаний снижает вероятность ошибок, связанных с неверной интерпретацией информации, и повышает точность ответов, особенно в сложных задачах, требующих анализа взаимосвязей между различными элементами знаний.
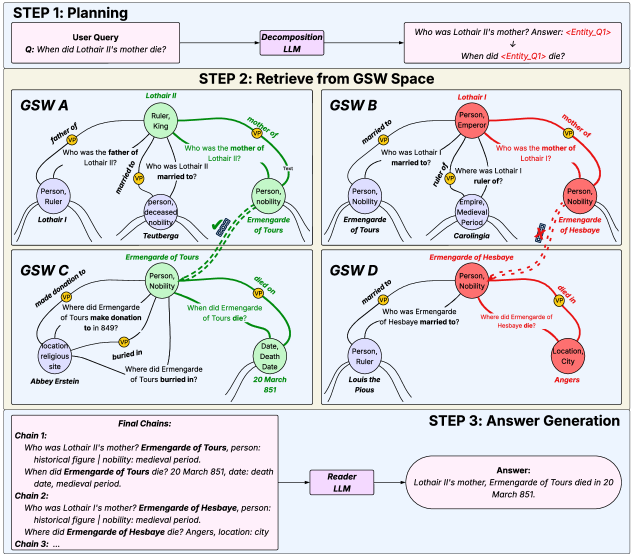
Panini: Непрерывное Обучение для Надежных Систем Ответов на Вопросы
Panini представляет собой новый непараметрический подход к непрерывному обучению, разработанный для достижения передовых результатов в задачах вопросно-ответных систем (QA). В отличие от традиционных методов, требующих переобучения модели при появлении новых данных, Panini сохраняет и эффективно использует ранее полученные знания, что позволяет ему адаптироваться к новым вопросам без существенной потери производительности. Этот подход позволил Panini добиться среднего показателя качества ответов в 56.1 на стандартных QA-бенчмарках, превзойдя результаты таких систем, как HippoRAG2 (53.3) и методов на основе плотного поиска (50.5). Ключевым отличием является способность к динамическому расширению базы знаний без необходимости полной перестройки модели, что обеспечивает более эффективное и масштабируемое решение для задач QA.
В ходе оценки качества ответов на вопросы (QA) система Panini продемонстрировала средний показатель в 56.1, что превосходит результаты системы HippoRAG2 (53.3) и методов, основанных на плотном векторном поиске (50.5). Данный результат указывает на превосходство Panini в задачах извлечения информации и формирования ответов по сравнению с существующими подходами, подтверждая ее эффективность в обработке вопросов и предоставлении точных ответов на их основе. Оценка проводилась на стандартных QA-бенчмарках, позволяющих объективно сравнить производительность различных систем.
В основе работы Panini лежит механизм связывания сущностей (Entity Linking), позволяющий устанавливать связи между понятиями, представленными в различных источниках информации. Это достигается путем идентификации и нормализации сущностей, что позволяет системе объединять знания из разных документов и формировать более полное представление о предметной области. Благодаря этому, Panini способна проводить более глубокий и контекстуально-обоснованный анализ вопросов, значительно повышая качество ответов, особенно в случаях, когда ответ требует синтеза информации из нескольких источников. Механизм связывания сущностей является ключевым компонентом, обеспечивающим возможность комплексного рассуждения и преодоления ограничений, присущих системам, оперирующим только локальным контекстом.
В архитектуре Panini реализованы методы оптимизации вычислительных ресурсов, такие как Sleep-Time Compute, позволяющие минимизировать затраты на проведение логического вывода. Данные методы позволяют снизить потребление ресурсов за счет эффективного управления вычислительными процессами во время обучения и работы системы. Кроме того, Panini использует значительно меньший объем токенов для формирования контекста ответа — в 2-30 раз меньше, чем у конкурирующих базовых моделей, что снижает требования к памяти и повышает скорость обработки информации при сохранении качества ответов.
В рамках оценки надёжности системы Panini было установлено, что она демонстрирует высокую точность определения неразрешимых вопросов, достигая 74.0% точности воздержания (abstention accuracy) при оценке неразрешимых запросов. При этом, система сохраняет высокую точность ответов на разрешимые вопросы, что свидетельствует о её способности эффективно различать вопросы, на которые можно дать ответ, и те, которые выходят за рамки доступной информации или логических возможностей. Данный показатель надёжности позволяет использовать Panini в сценариях, где критически важна уверенность в корректности предоставляемой информации и избежание ложных ответов.
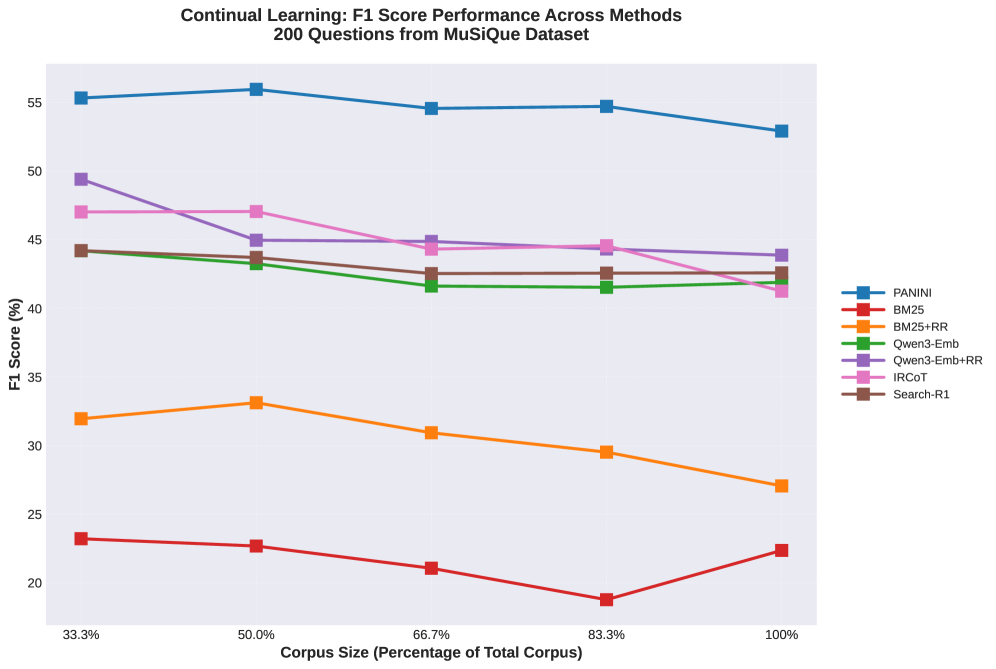
Строгая Оценка и Спектр Многошаговых Наборов Данных
Стандартизированная методология “Platinum Evaluation” предоставляет надежный инструмент для оценки систем, решающих задачи многошагового вопросно-ответного поиска. В отличие от традиционных подходов, оценивающих только вопросы с известными ответами, “Platinum Evaluation” включает в себя наборы данных, содержащие как вопросы, на которые можно дать ответ, так и те, которые остаются без ответа. Это позволяет более точно оценить способность системы не только находить информацию, но и распознавать случаи, когда ответа не существует, избегая ложных положительных результатов и обеспечивая более реалистичную оценку производительности в сложных информационных средах. Такой подход критически важен для развития надежных систем искусственного интеллекта, способных эффективно работать с неполной или противоречивой информацией.
Наборы данных, такие как HotpotQA, MuSiQue и 2WikiMultihopQA, представляют собой разнообразные испытания для систем, способных отвечать на вопросы, требующие нескольких шагов рассуждений. HotpotQA фокусируется на вопросах, требующих поиска информации из нескольких документов и синтеза ответов, в то время как MuSiQue проверяет способность модели к пониманию и применению сложных логических связей. 2WikiMultihopQA, в свою очередь, делает акцент на нахождении связей между различными сущностями и фактами, разбросанными по нескольким статьям Википедии. Разнообразие этих наборов данных позволяет всесторонне оценить возможности модели в обработке сложных запросов, требующих не только извлечения информации, но и ее анализа и синтеза, выявляя слабые места и стимулируя разработку более продвинутых алгоритмов.
Успехи, достигнутые на таких наборах данных, как HotpotQA, MuSiQue и 2WikiMultihopQA, наглядно демонстрируют перспективность подхода Panini и сопутствующих техник в решении проблем, с которыми сталкиваются традиционные системы ответов на вопросы. Традиционные методы часто испытывают трудности при обработке вопросов, требующих синтеза информации из нескольких источников, и не всегда способны эффективно определять, когда ответ на вопрос вообще отсутствует в имеющемся корпусе знаний. Panini, в свою очередь, благодаря своей архитектуре и алгоритмам, позволяет более точно моделировать сложные логические связи и осуществлять более глубокий анализ информации, что приводит к повышению точности ответов и улучшению способности системы определять неразрешимые вопросы. Эти улучшения открывают новые возможности для создания интеллектуальных систем, способных не только находить информацию, но и рассуждать над ней.
Исследование представляет Panini — систему, стремящуюся к эффективному непрерывному обучению, используя структурированную память для ответов на сложные вопросы. Подход, заключающийся в инвестировании в создание этой памяти на этапе записи и использовании облегченного поиска по цепочке на этапе чтения, демонстрирует стремление к оптимизации процессов обработки информации. Как однажды заметил Брайан Керниган: «Простота — это высшая степень совершенства». Эта фраза перекликается с концепцией Panini, поскольку система стремится к элегантности и эффективности за счет структурирования знаний и оптимизации поиска, избегая излишней сложности, характерной для многих современных систем непрерывного обучения. Panini, подобно хорошо спроектированному инструменту, стремится к ясности и функциональности в своей архитектуре.
Что Дальше?
Представленная работа, фокусируясь на структурированной памяти как среде для накопления знаний, лишь частично решает проблему старения систем. Эффективность Panini в многошаговом вопросно-ответном взаимодействии — это не конечная точка, а скорее, свидетельство того, что система способна адаптироваться, а не просто сохранять функциональность. Важно помнить: время — не метрика оценки производительности, а среда, в которой ошибки неизбежны, а исправления — естественный процесс созревания.
Очевидным направлением дальнейших исследований является расширение области применения структурированной памяти за пределы семантических задач. Вопрос заключается не в том, чтобы создать идеальную систему, а в том, чтобы построить такую, которая достойно стареет, извлекая уроки из каждого инцидента. Следует исследовать, как подобные подходы могут быть интегрированы с другими методами непрерывного обучения, формируя более устойчивые и гибкие архитектуры.
В конечном счете, истинный прогресс заключается не в достижении максимальной точности в текущий момент времени, а в создании систем, способных к долгосрочной эволюции и адаптации. Необходимо осознать, что любая система несовершенна, и её ценность определяется не отсутствием ошибок, а способностью их преодолевать, превращая их в ступени к зрелости.
Оригинал статьи: https://arxiv.org/pdf/2602.15156.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Таблицы оживают: Искусственный интеллект осваивает структурированные данные
- Искусственный интеллект и квантовая физика: кто кого?
- Большие языковые модели как судьи перевода: бюджет на размышления и калибровка реальности.
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Геометрия жизни: что скрывают модели геномных данных?
- Видео по требованию: Управление генерацией с помощью траекторий
- Серебро и медь: новый взгляд на наноаллои
- Языковые модели диффузии: новый уровень эффективности
- Разделяй и Властвуй: Новый Подход к Развёртке 3D-Моделей
2026-02-19 00:31