Автор: Денис Аветисян
Исследователи представили MemFly — систему, оптимизирующую память языковых моделей для повышения качества рассуждений и сохранения важной информации.
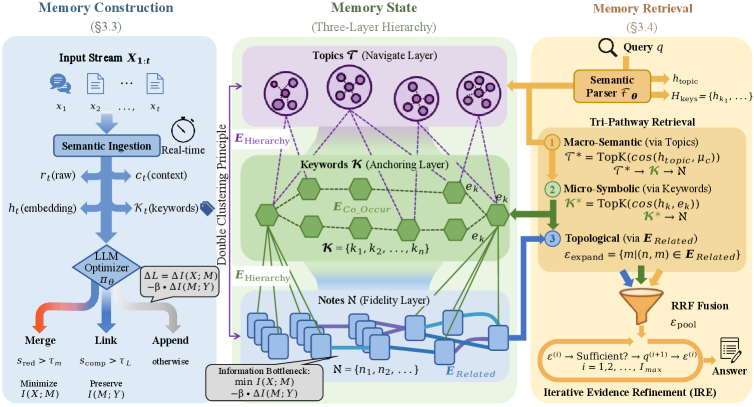
MemFly использует принцип информационного узкого места для динамической оптимизации памяти, обеспечивая баланс между сжатием и сохранением релевантных знаний в больших языковых моделях.
Долгосрочная память является ключевым компонентом для решения сложных задач агентами на основе больших языковых моделей, однако существующие подходы сталкиваются с противоречием между эффективной компрессией данных и сохранением релевантной информации. В данной работе представлена система ‘MemFly: On-the-Fly Memory Optimization via Information Bottleneck’, использующая принципы информационного «бутылочного горлышка» для динамической оптимизации памяти, минимизируя энтропию сжатия и максимизируя релевантность. Разработанный гибридный механизм извлечения информации, объединяющий семантические, символические и топологические пути, обеспечивает высокую точность и согласованность ответов. Способна ли система MemFly открыть новые горизонты в области долгосрочного рассуждения и агентного обучения?
Пределы Масштабирования: Узкие Места в Рассуждениях БЯМ
Несмотря на впечатляющую способность больших языковых моделей (БЯМ) к распознаванию закономерностей, их возможности в области долгосрочного рассуждения и поддержания согласованности информации в ходе продолжительных взаимодействий остаются ограниченными. БЯМ демонстрируют высокую эффективность в задачах, требующих анализа статистических связей в данных, однако сталкиваются с трудностями при решении проблем, требующих логического вывода, планирования и учета контекста на протяжении длительного периода времени. Эта особенность проявляется в склонности моделей к «забыванию» ранее предоставленной информации или внесению противоречий в свои ответы, особенно при увеличении сложности и продолжительности диалога. Таким образом, способность к поверхностному сопоставлению с образцами не гарантирует глубокое понимание и последовательность в рассуждениях, что является критическим ограничением для создания действительно интеллектуальных систем.
Несмотря на впечатляющие успехи больших языковых моделей, увеличение их размера перестаёт приносить соразмерный прирост в способностях к рассуждению. Дальнейшее наращивание количества параметров сталкивается с законом убывающей доходности, поскольку модель всё чаще оказывается перегружена информацией и испытывает трудности с выделением действительно значимых закономерностей. Исследования показывают, что ключевым направлением развития является не просто увеличение масштаба, а поиск принципиально новых архитектурных решений, способных эффективно обрабатывать и удерживать информацию на протяжении длительных взаимодействий. Необходимо отойти от традиционных подходов и вдохновляться биологическими системами, которые демонстрируют высокую эффективность и надежность в управлении сложными данными и процессами.
Современные большие языковые модели (LLM) часто демонстрируют «забывчивость» и склонность к контекстуальным ошибкам, что связано с принципиальными отличиями их систем памяти от биологических аналогов. В отличие от человеческого мозга, где информация распределена и надежно сохраняется благодаря сложным нейронным сетям и механизмам консолидации памяти, LLM полагаются на относительно простые и неэффективные подходы к хранению контекста. Это приводит к тому, что при обработке длинных текстов или ведении продолжительных диалогов модели постепенно «теряют» важную информацию, искажают факты или противоречат самим себе. Неспособность эффективно управлять контекстом становится серьезным ограничением для решения задач, требующих долгосрочного планирования, анализа сложных ситуаций и поддержания последовательности рассуждений, подчеркивая необходимость разработки новых архитектур памяти, вдохновленных принципами работы биологических систем.
MemFly: Информационное Горлышко для Памяти Агента
MemFly представляет собой новую структуру агентурной памяти, основанную на принципе Информационного Бутылочного Горлышка (Information Bottleneck, IB). Данный подход позволяет эффективно сжимать и сохранять релевантные знания путем минимизации избыточности информации. В основе лежит идея о том, что агент должен сохранять только ту информацию, которая наиболее важна для решения поставленных задач, отбрасывая несущественные детали. Принцип IB предполагает оптимизацию компромисса между сжатием данных и сохранением необходимой информации для прогнозирования или принятия решений. Это достигается путем построения компактного представления входных данных, которое сохраняет максимальное количество информации, релевантной для целевой переменной, минимизируя при этом размер представления.
Система MemFly использует стратифицированную организацию памяти, именуемую Иерархией Заметки-Ключевое слово-Тема. Эта иерархия обеспечивает структурированное хранение информации, где отдельные заметки содержат конкретные факты, ключевые слова служат для индексации и связи заметок, а темы представляют собой абстракции, объединяющие связанные заметки и ключевые слова. Такая организация позволяет системе эффективно кодировать семантические связи между различными элементами информации, что, в свою очередь, значительно улучшает скорость и точность поиска и извлечения релевантных данных. Структура позволяет осуществлять навигацию по памяти на различных уровнях абстракции, оптимизируя процесс доступа к нужной информации.
Иерархическая структура памяти в MemFly, основанная на двойной кластеризации (Double Clustering), обеспечивает эффективную навигацию и доступ к информации. Данный подход подразумевает последовательное формирование кластеров: сначала формируются кластеры отдельных «заметок» (Note), затем эти кластеры группируются в кластеры «ключевых слов» (Keyword), и, наконец, кластеры ключевых слов объединяются в кластеры «тем» (Topic). Такая многоуровневая организация позволяет агенту быстро находить релевантную информацию, избегая необходимости полного перебора всей базы знаний, что, в свою очередь, повышает эффективность процессов рассуждения и принятия решений.
Динамическая Консолидация и Извлечение Памяти
В MemFly динамическая оптимизация представления памяти осуществляется с помощью оптимизатора, не требующего вычисления градиентов, управляемого большой языковой моделью (LLM). Этот оптимизатор работает в связке с семантической оценкой, позволяющей выявлять и объединять избыточную информацию, одновременно усиливая важные связи между элементами памяти. LLM выступает в роли функции оценки, определяющей значимость различных элементов и направляющей процесс оптимизации. Семантическая оценка позволяет системе отличать релевантные данные от нерелевантных, обеспечивая эффективное использование ресурсов памяти и повышение точности извлечения информации.
Для повышения эффективности динамической консолидации памяти в MemFly, алгоритм Agglomerative Information Bottleneck (AIB) был адаптирован для работы в онлайн-режиме. В традиционном AIB процесс сжатия информации происходит дискретно, после получения всего набора данных. В MemFly, модифицированный AIB обеспечивает непрерывное сжатие и эволюцию памяти по мере поступления новой информации. Это достигается путем итеративного объединения схожих представлений данных и отбрасывания избыточной информации, что позволяет поддерживать компактное и релевантное хранилище знаний без необходимости полного пересчета после каждого обновления. Адаптация включает в себя динамическую оценку взаимной информации между представлениями для определения приоритетов объединения и сохранения наиболее значимых данных.
Механизм извлечения информации в системе MemFly использует три пути доступа к памяти — семантический, символьный и топологический — для обеспечения надежного и эффективного поиска. Семантический путь основывается на смысловом сходстве запроса и сохраненных данных, символьный — на точных совпадениях ключевых слов или идентификаторов, а топологический — на структуре связей между различными фрагментами памяти. Для объединения результатов, полученных по каждому из этих путей, применяется метод Reciprocal Rank Fusion (RRF), который позволяет взвешивать и ранжировать результаты, учитывая их релевантность и позицию в каждом рейтинге. Использование RRF способствует повышению точности и скорости извлечения информации, особенно в случаях, когда один из путей доступа предоставляет неполные или неточные результаты.
Превосходная Производительность и Масштабируемость
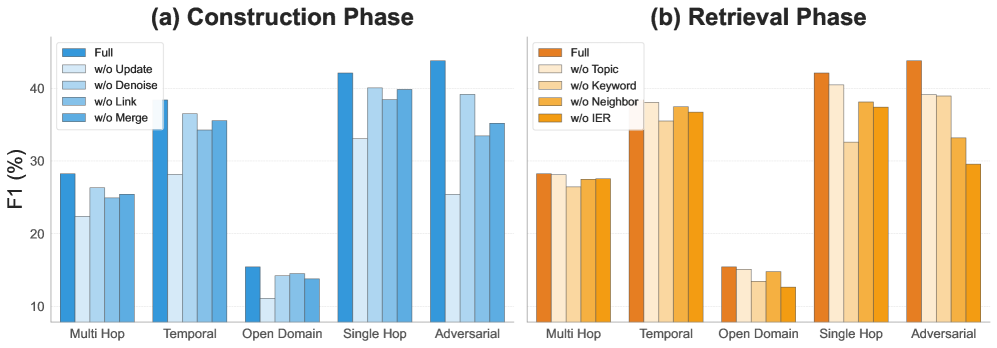
Оценка MemFly на эталонном наборе данных LoCoMo продемонстрировала его превосходную способность к синтезу информации в длинных контекстах, значительно превосходящую возможности базовых моделей, таких как MemoryBank, ReadAgent, MemGPT и A-MEM. Данные исследования указывают на то, что MemFly эффективно извлекает и объединяет релевантную информацию из обширных текстовых последовательностей, что позволяет ему выдавать более точные и связные ответы по сравнению с альтернативными подходами. Это преимущество особенно заметно при обработке сложных запросов, требующих анализа большого объема данных, и подтверждает потенциал MemFly для решения задач, связанных с обработкой длинных документов и ведением содержательных диалогов.
В ходе оценки на базе GPT-4o, система MemFly продемонстрировала передовые результаты, достигнув показателя F1 в 43.76%. Этот результат превосходит производительность наиболее сильного конкурента на 1.79 пункта, что свидетельствует о значительном улучшении способности MemFly к точному извлечению и синтезу информации. Достижение такого уровня эффективности подтверждает потенциал системы для решения сложных задач, требующих глубокого понимания контекста и высокой точности ответов, и подчеркивает ее превосходство в области обработки больших объемов данных.
В ходе оценки на модели Qwen3-8B система MemFly продемонстрировала значительное превосходство над ближайшим конкурентом, A-mem, достигнув показателя F1 в 38.62%. Этот результат на 5.86 пункта выше, чем у A-mem, что свидетельствует о более эффективной обработке и синтезе информации в длинных контекстах. Полученный показатель F1 указывает на улучшенную точность и полноту извлечения релевантных данных, что делает MemFly особенно перспективной для задач, требующих глубокого понимания и анализа больших объемов текста.
Дополнительные результаты тестирования MemFly демонстрируют стабильное повышение эффективности при использовании различных базовых моделей. На платформе GPT-4o достигнут показатель F1 в 44.39%, а при использовании Qwen3-14B — 42.25%. Эти данные свидетельствуют о том, что MemFly не просто превосходит существующие методы в определенных условиях, но и сохраняет высокую производительность при интеграции с разными архитектурами, что делает её универсальным и надежным решением для задач, требующих обработки больших объемов информации и долгосрочной памяти.
Будущее Агентного Интеллекта
Система MemFly демонстрирует принципиально новый подход к организации памяти в интеллектуальных агентах, делая акцент на сжатии информации и семантической организации данных. Вместо простого хранения больших объемов информации, MemFly стремится к выявлению и сохранению лишь наиболее значимых концепций и связей между ними. Такой подход позволяет не только существенно снизить требования к объему памяти, но и повысить устойчивость системы к помехам и неполноте данных. Эффективное сжатие и семантическое структурирование позволяют агенту быстро извлекать необходимую информацию и адаптироваться к изменяющимся условиям, что является ключевым фактором для создания действительно интеллектуальных и автономных систем.
Принципы, лежащие в основе MemFly, обладают широким потенциалом применения в различных областях. В сфере управления знаниями система способна обеспечить более эффективную организацию и извлечение информации, значительно превосходя традиционные методы. Персонализированное обучение может быть качественно улучшено за счет адаптации к индивидуальным потребностям обучающегося и динамического формирования учебного контента. Наиболее перспективным направлением представляется использование в системах автономного принятия решений, где MemFly позволяет агентам быстро обрабатывать большие объемы данных, извлекать ключевые закономерности и принимать обоснованные решения в сложных и динамичных условиях, приближая их к человеческому уровню когнитивных способностей.
Дальнейшие исследования в области агентного интеллекта сосредоточены на оптимизации процесса консолидации памяти, что позволит системам более эффективно удерживать и использовать накопленный опыт. Особое внимание уделяется разработке новых методов интеграции внешних источников знаний — от структурированных баз данных до неформальных текстовых ресурсов. Это предполагает создание механизмов, способных не только извлекать релевантную информацию, но и критически оценивать её достоверность и согласованность с уже имеющимися знаниями. Успешная реализация этих направлений позволит значительно расширить возможности агентных систем в решении сложных задач, требующих адаптации к меняющимся условиям и непрерывного обучения.
Исследование представляет MemFly — попытку обуздать растущие аппетиты больших языковых моделей к памяти. Авторы предлагают механизм, балансирующий сжатие информации и сохранение релевантных знаний, что, в теории, должно улучшить способность к долгосрочному рассуждению. Однако, опыт подсказывает: каждая элегантная архитектура со временем превращается в анекдот, особенно когда сталкивается с жестокой реальностью продакшена. В связи с этим, вспоминается высказывание Блеза Паскаля: «Все великие вещи требуют времени». Иными словами, оптимизация памяти — это бесконечная гонка, где каждая победа — лишь временная передышка перед новым витком технического долга. Сжатие информации — это хорошо, но прод всегда найдёт способ сломать даже самую продуманную систему.
Что дальше?
Представленный подход, безусловно, демонстрирует потенциал в оптимизации долговременной памяти агентов, основанных на больших языковых моделях. Однако, стоит помнить, что каждая элегантная схема сжатия информации рано или поздно встретится с данными, которые её сломают. Проблема не в теории «информационного горлышка», а в том, что реальные данные редко соответствуют идеальным распределениям, на которых строятся модели. Вполне вероятно, что в ближайшем будущем появятся adversarial примеры, способные обходить предложенные механизмы сжатия, заставляя систему забывать критически важную информацию.
Более того, оптимизация памяти — лишь одна сторона медали. Настоящая проблема заключается в том, что MVP в области агентного ИИ — это, по сути, обещание пользователю: «Подождите, мы потом исправим логику принятия решений». Следовательно, усилия по оптимизации памяти должны сопровождаться строгим аудитом и формализацией принципов принятия решений, иначе все улучшения окажутся бесполезными в условиях непредсказуемой среды.
В перспективе, можно ожидать, что фокус исследований сместится от чисто технической оптимизации памяти к разработке более robustных и самообучающихся механизмов, способных адаптироваться к изменяющимся данным и компенсировать неизбежные потери информации. Если код выглядит идеально — значит, его никто не деплоил, и, вероятно, данное решение не выдержит проверки временем и реальными нагрузками.
Оригинал статьи: https://arxiv.org/pdf/2602.07885.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Языковые модели и границы возможного: что делает язык человеческим?
- Искусственный интеллект на страже экологии: защита данных и справедливые алгоритмы
- Обучение языковых моделей по предпочтениям: новый подход к повышению точности
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Игры без модели: новый подход к управлению в условиях неопределенности
- Конфиденциальный анализ больших данных: новый подход к быстрым ответам
- Визуальное мышление машин: новый вызов для ИИ
- Ожившие Пиксели: Создание Реалистичных Видео с Сохранением Личности
- Гендерные стереотипы в найме: что скрывают языковые модели?
2026-02-15 12:21