Автор: Денис Аветисян
Исследователи предлагают принципиально новый подход к организации памяти для языковых агентов, позволяющий им сохранять и использовать информацию на протяжении неограниченно длительных периодов.
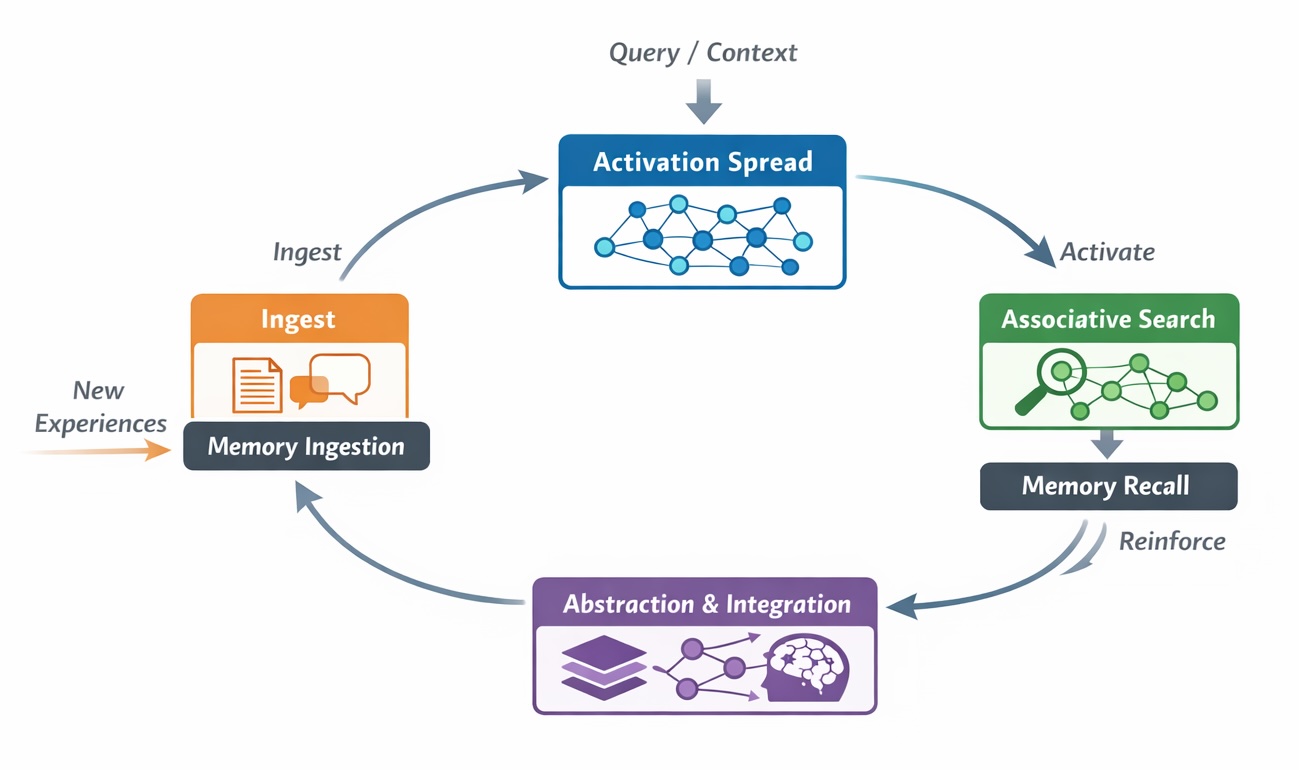
В статье представлена архитектура непрерывной памяти (CMA) для создания агентов с устойчивой памятью, превосходящая возможности традиционных систем поиска и генерации (RAG).
Несмотря на успехи генеративных моделей с извлечением информации (RAG), стандартные подходы к организации памяти для долгосрочных агентов остаются статичными и не учитывают временную динамику. В работе «Архитектуры непрерывной памяти для долгосрочных LLM-агентов» предложена концепция архитектур непрерывной памяти (CMA), обеспечивающих поддержание и обновление внутреннего состояния агента посредством постоянного хранения, селективного удержания, ассоциативного маршрутизирования и консолидации знаний. Данный подход позволяет преодолеть структурные ограничения RAG в задачах, требующих накопления, изменения и уточнения информации. Какие новые возможности откроются для создания действительно «думающих» агентов, способных к обучению и адаптации в течение длительного времени?
За пределами масштабируемости: Ограничения традиционной памяти
Современные системы искусственного интеллекта, особенно те, что используют генерацию с расширением извлечением (RAG), сталкиваются с трудностями в поддержании связного контекста при продолжительном взаимодействии. Эта проблема возникает из-за ограниченной способности таких систем эффективно обрабатывать и удерживать информацию на протяжении длинных диалогов или сессий. По мере увеличения объема обмениваемых данных, алгоритмы RAG все сложнее сохраняют согласованность ответов, что приводит к потере логической нити и снижению релевантности генерируемого текста. Исследователи отмечают, что простое увеличение объема извлекаемой информации не решает проблему, а лишь усугубляет её, создавая информационную перегрузку и затрудняя выделение наиболее важной информации для поддержания последовательности.
В основе современных систем генерации с расширением извлечением (RAG) лежат векторные базы данных, однако их внутренняя архитектура создает определенные ограничения. Несмотря на эффективность в быстром поиске семантически близких фрагментов информации, векторные базы данных испытывают трудности при обработке сложных запросов, требующих синтеза знаний из множества источников. Основная проблема заключается в том, что процесс извлечения информации часто приводит к перегрузке системы избыточными данными, что замедляет время отклика и снижает качество генерируемого текста. Вместо того чтобы находить наиболее релевантную информацию, система может возвращать большое количество фрагментов, лишь косвенно связанных с запросом, что затрудняет ее последующую обработку и синтез в последовательный и осмысленный ответ. В результате, производительность RAG-систем ограничена не столько масштабом базы знаний, сколько способностью эффективно отбирать и интегрировать релевантную информацию из этой базы.
Традиционные методы работы с информацией, используемые в современных системах искусственного интеллекта, зачастую не способны эффективно расставлять приоритеты в объеме доступных знаний. Это приводит к перегрузке информацией и, как следствие, к снижению производительности. Вместо того, чтобы фокусироваться на наиболее релевантных данных, системы обрабатывают весь доступный объем, что замедляет процесс принятия решений и ухудшает качество ответов. Отсутствие тонкой настройки приоритетов не позволяет выделить ключевые факты и взаимосвязи, необходимые для поддержания связного контекста в длительных взаимодействиях. В результате, система может упускать важные детали или генерировать неточные ответы, даже располагая огромным объемом информации.
Архитектуры непрерывной памяти (CMA): Новый взгляд на организацию знаний
Архитектуры непрерывной памяти (CMA) представляют собой принципиально новый подход к организации памяти в вычислительных системах. В отличие от традиционных архитектур, рассматривающих память как статичный набор ячеек, CMA оперирует с концепцией памяти как динамически развивающейся среды. Это означает, что информация не просто хранится и извлекается, а непрерывно трансформируется и реорганизуется в соответствии с поступающими данными и контекстом. Такой подход позволяет преодолеть ограничения традиционных систем, связанных с фиксированным объемом памяти и сложностью поддержания актуальности информации, открывая возможности для создания систем, способных к самообучению и адаптации в реальном времени.
Архитектура Continuum Memory (CMA) использует графовую структуру в качестве основы для хранения и организации знаний. В этой структуре, отдельные фрагменты информации представлены как узлы графа, а связи между ними устанавливаются посредством семантических и временных ребер. Семантические ребра отражают смысловую связь между фрагментами, позволяя устанавливать ассоциации на основе их значения. Временные ребра фиксируют последовательность возникновения или изменения фрагментов, обеспечивая контекст и возможность отслеживания эволюции знаний. Такая организация позволяет эффективно моделировать сложные взаимосвязи между данными и обеспечивает возможность быстрого доступа к релевантной информации, основываясь не только на содержании, но и на контексте и истории ее формирования.
Архитектура Continuum Memory Architectures (CMA) в своей основе опирается на принципы когнитивной науки, делая акцент на трех ключевых процессах: устойчивости (Persistence) — долгосрочном хранении информации; селективном удержании (Selective Retention) — приоритезации и сохранении наиболее релевантных данных, отбрасывании избыточной или устаревшей информации; и эффективной консолидации (Consolidation) — процессе стабилизации и интеграции новой информации с уже существующими знаниями, что способствует формированию прочных и взаимосвязанных воспоминаний. Эти процессы моделируют механизмы работы человеческой памяти, обеспечивая адаптивность и эффективность хранения и извлечения информации в системе.
Активация знаний: От структуры к функциональности
В рамках Когнитивного Механизма Активации (CMA) поле активации распространяет сигналы вдоль ребер графа, представляющего знания. Этот процесс преобразует входной запрос или намерение в градиент доступности релевантных фрагментов памяти. Интенсивность активации ослабевает по мере распространения, что обеспечивает приоритет информации, имеющей сильные ассоциации и недавно использовавшейся. По сути, поле активации динамически определяет, какие узлы графа знаний наиболее вероятно содержат информацию, необходимую для удовлетворения текущего запроса, и делает эти узлы более доступными для последующей обработки.
Механизм распространяющейся активации в системе обеспечивает затухание сигнала по мере его распространения по графу знаний. Это затухание не является случайным; оно пропорционально силе ассоциаций между узлами и времени последнего доступа к информации. В результате, наиболее сильно связанные и недавно использованные фрагменты памяти получают приоритетный доступ к активации, что позволяет быстро и эффективно извлекать релевантные данные. Уменьшение интенсивности сигнала на больших расстояниях и для слабо связанных элементов предотвращает перегрузку системы и обеспечивает фокусировку на наиболее важных и актуальных знаниях.
Сервис приема данных (Ingest Service) непрерывно записывает поступающие наблюдения в графообразную подложку (Graph-Structured Substrate), осуществляя постоянное обновление и уточнение базы знаний. Этот процесс включает в себя создание новых узлов и ребер в графе для представления новых фактов и связей, а также модификацию существующих узлов и ребер на основе поступающей информации. Входящие данные преобразуются в структурированный формат, пригодный для хранения в графе, что обеспечивает эффективный поиск и извлечение информации в дальнейшем. Сервис работает в режиме реального времени, позволяя системе оперативно реагировать на изменения в окружающей среде и адаптировать свою модель знаний.
Фоновые задания консолидации (Consolidation Jobs) выполняют несколько процессов для оптимизации представления знаний в системе. Воспроизведение (replay) позволяет повторно активировать и укрепить недавно полученную информацию. Абстракция (abstraction) обобщает конкретные наблюдения, выявляя общие закономерности и связи. Извлечение сути (gist extraction) концентрирует ключевую информацию из наблюдений, формируя сжатое, но информативное представление. Эти процессы, выполняемые в фоновом режиме, способствуют долгосрочному хранению знаний и повышению эффективности доступа к ним.
Оценка и совершенствование производительности CMA
Оценка производительности CMA осуществляется посредством комплекса специализированных тестов, включающих Associative Recall Probe, оценивающий способность модели извлекать связанные знания; Temporal Association Probe, проверяющий понимание временных связей в данных; и Selective Retention Probe, предназначенный для измерения способности CMA к выборочному сохранению релевантной информации. Данные пробы позволяют комплексно оценить качество запоминания, ассоциативного мышления и понимания контекста, что необходимо для обеспечения надежности и точности работы модели в различных сценариях применения.
Для объективной оценки способности CMA к разрешению контекстной неоднозначности и сохранению релевантной информации используется LLM Judge — система, основанная на большой языковой модели. LLM Judge выступает в роли независимого арбитра, анализируя ответы CMA и сравнивая их с эталонными решениями. Этот подход позволяет минимизировать субъективность оценки, часто возникающую при использовании ручных методов, и обеспечивает количественно измеримые результаты, необходимые для точной оценки производительности CMA в задачах, требующих понимания контекста и долгосрочной памяти.
В ходе оценки производительности, Contextual Memory Augmentation (CMA) продемонстрировала значительное превосходство над сильным baseline на основе Retrieval-Augmented Generation (RAG) по четырем поведенческим тестам. Общий процент побед CMA в решающих испытаниях составил 82%. Данный показатель отражает статистически значимое улучшение способности CMA эффективно использовать и удерживать контекстную информацию по сравнению с базовым подходом RAG, что подтверждается результатами тестов по различным аспектам когнитивной обработки.
В ходе оценки производительности CMA, система продемонстрировала следующие показатели успешности в различных поведенческих тестах: 84% в задачах обновления знаний, 86% в задачах временной ассоциации, 74% в задачах ассоциативного извлечения и 85% в задачах контекстной десамбигуации. Эти результаты, полученные с использованием объективной оценки LLM Judge, указывают на превосходство CMA в удержании актуальной информации и корректной интерпретации контекста по сравнению с базовым уровнем RAG.
Несмотря на существенное повышение производительности, применение CMA приводит к увеличению задержки обработки в 2.4 раза по сравнению с базовым решением RAG. Данный прирост задержки является следствием более сложной архитектуры CMA и дополнительных вычислительных затрат, связанных с поддержанием и анализом контекста, а также с механизмом обновления информации. Хотя CMA демонстрирует значительно более высокую точность и способность к адаптации, необходимо учитывать компромисс между производительностью и задержкой при выборе архитектуры для конкретных приложений.
Оценочный модуль поиска (Retrieval Scorer) оптимизирует точность извлечения информации, комбинируя несколько факторов и используя подструктуру на основе графа (Graph-Structured Substrate). Эта подструктура позволяет учитывать взаимосвязи между фрагментами данных, что повышает релевантность извлеченных результатов. Комбинация факторов включает в себя семантическое соответствие запросу, частоту доступа к фрагментам (Reinforcement History) и другие параметры, определяющие значимость и актуальность информации. Использование графовой структуры позволяет более эффективно находить и извлекать наиболее подходящие фрагменты для ответа на запрос, улучшая общую производительность системы.
История обращений к фрагментам информации используется в системе для приоритизации наиболее часто запрашиваемых данных. Этот механизм позволяет системе динамически адаптироваться к паттернам использования, повышая скорость и точность извлечения релевантной информации. Частота доступа к фрагментам служит индикатором их важности и актуальности, что позволяет системе оптимизировать процесс поиска и предоставлять пользователю наиболее востребованные данные в первую очередь. Такой подход способствует улучшению производительности системы и повышению её способности к обучению и адаптации к изменяющимся потребностям пользователя.
Будущее адаптивного интеллекта
Архитектура CMA демонстрирует ключевую способность поддерживать временную непрерывность, что является основополагающим аспектом для создания действительно интеллектуальных агентов. В отличие от традиционных систем, которые обрабатывают информацию изолированно, CMA позволяет агентам сохранять контекст прошлых взаимодействий и учитывать их при принятии текущих решений. Это достигается за счет динамического обновления и хранения информации о последовательности событий, позволяя агенту адаптироваться к изменяющимся обстоятельствам и учиться на собственном опыте. Способность интегрировать новую информацию в существующую базу знаний, не теряя при этом целостности предыдущего опыта, делает CMA перспективным инструментом для разработки систем искусственного интеллекта, способных к долгосрочному планированию, проактивному поведению и сложным взаимодействиям с окружающей средой.
Архитектура CMA открывает новые горизонты в области персонализированной и проактивной помощи, позволяя агентам на основе больших языковых моделей (LLM) сохранять информацию о предпочтениях пользователей и отслеживать ход выполнения проектов. Вместо того чтобы каждый раз заново обрабатывать запросы, такие агенты способны учитывать предыдущий опыт взаимодействия, адаптируя свои ответы и действия к индивидуальным потребностям. Это позволяет не просто получать информацию по запросу, но и предвидеть будущие потребности, предлагая решения ещё до того, как пользователь сформулирует вопрос. Благодаря способности запоминать контекст и отслеживать прогресс, агенты становятся более эффективными помощниками в решении сложных задач, от управления личным расписанием до реализации масштабных проектов, существенно повышая удобство и продуктивность взаимодействия человека и искусственного интеллекта.
Предлагаемая архитектура открывает многообещающий путь к созданию искусственного интеллекта, который не просто обладает обширными знаниями, но и способен к непрерывному обучению и адаптации. В отличие от традиционных систем, ограниченных статичными данными, данная модель позволяет агентам накапливать опыт, изменять стратегии поведения на основе поступающей информации и оптимизировать процессы принятия решений в динамично меняющейся среде. Это достигается за счет интеграции механизмов, обеспечивающих долгосрочную память и способность к обобщению, что позволяет системе не просто запоминать факты, но и извлекать из них уроки, предвидеть будущие события и эффективно реагировать на новые вызовы. В перспективе, такая адаптивность позволит создавать интеллектуальные системы, способные к автономной работе в сложных условиях и предоставляющие персонализированные решения, соответствующие индивидуальным потребностям пользователей.
Исследование архитектур непрерывной памяти (CMA) демонстрирует, что попытки создать идеальную систему долгосрочной памяти для LLM-агентов обречены на неудачу. Стремление к оптимизации производительности часто приводит к потере гибкости, а попытки предвидеть все возможные сценарии — к созданию хрупких конструкций. Как однажды заметил Дональд Дэвис: «Каждый архитектурный выбор — это пророчество о будущем сбое». Эта фраза особенно точно отражает суть CMA, поскольку данная архитектура признает неизбежность ошибок и стремится не к их предотвращению, а к созданию системы, способной к адаптации и восстановлению после них. Подобно тому, как эволюционирует живая система, CMA позволяет агенту непрерывно совершенствовать свою память, извлекая уроки из прошлого опыта и адаптируясь к меняющимся условиям.
Что дальше?
Предложенные архитектуры непрерывной памяти, безусловно, представляют собой шаг за пределы устоявшихся схем обогащения генерации с помощью извлечения. Однако, стоит признать, что каждая попытка построить «долговременную» память для агента — это, по сути, пророчество о неизбежном сбое. Неизбежно возникнет вопрос о критериях «значимости» воспоминаний, о механизмах их естественного «забывания» и о том, как предотвратить превращение системы в хаотичное хранилище нерелевантной информации. Мониторинг в данном контексте — это не поиск ошибок, а осознанное предвидение моментов истины, когда система неизбежно столкнется со своей собственной неполнотой.
Истинная устойчивость, вероятно, не в достижении идеальной памяти, а в способности агента адаптироваться к ее несовершенству. Важнее не «сохранить все», а научиться эффективно использовать то, что доступно, признавая, что каждое решение — это выбор между возможными мирами, каждый из которых имеет свою цену. Следующим шагом, возможно, станет исследование механизмов «внутренней критики» — способности агента оценивать достоверность и релевантность собственных воспоминаний.
В конечном счете, архитектуры непрерывной памяти — это не инструменты, а экосистемы. Их нельзя «построить», их можно только «вырастить», позволяя им эволюционировать в ответ на непрерывный поток опыта. И в этой эволюции, вероятно, кроется ключ к созданию действительно долгосрочных и адаптивных агентов.
Оригинал статьи: https://arxiv.org/pdf/2601.09913.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2026-01-19 05:25