Автор: Денис Аветисян
Исследователи предлагают переосмыслить «забывчивость» больших языковых моделей, рассматривая её не как недостаток, а как полезный когнитивный механизм, аналогичный человеческой памяти.
В статье представлена методика контролируемого забывания в больших языковых моделях для улучшения темпорального рассуждения и адаптации к изменяющимся данным.
Несмотря на стремление к совершенству в задачах логического вывода, большие языковые модели (LLM) демонстрируют склонность к забыванию ранее полученной информации. В работе ‘Forgetting as a Feature: Cognitive Alignment of Large Language Models’ предложена переосмысление этого явления не как недостатка, а как функционального когнитивного механизма, аналогичного человеческой памяти. Авторы показывают, что моделирование процесса забывания с помощью экспоненциального затухания позволяет LLM демонстрировать адаптивность и эффективность, сопоставимые с человеческими когнитивными способностями. Можно ли, используя принципы человеческой памяти, создать более интеллектуальные и эффективные языковые модели, способные к долгосрочному рассуждению и адаптации к изменяющимся условиям?
Парадокс масштаба: ограничения памяти в больших языковых моделях
Несмотря на впечатляющие возможности, большие языковые модели (LLM) демонстрируют ограничения в поддержании связного рассуждения при работе с расширенными контекстами, что является ключевой проблемой при решении сложных задач. Способность LLM удерживать информацию и последовательно применять её к новым данным снижается пропорционально увеличению объема текста. Это проявляется в трудностях с отслеживанием зависимостей между отдаленными частями текста, что приводит к логическим ошибкам и неточностям в ответах. Исследования показывают, что LLM часто “забывают” раннюю информацию в длинном тексте, сосредотачиваясь на последних фрагментах, что существенно ограничивает их применение в задачах, требующих глубокого понимания и синтеза больших объемов информации, таких как анализ юридических документов или научные исследования.
В отличие от биологического интеллекта, чья память динамична и адаптивна, большие языковые модели полагаются на статическую, параметрическую память. Это означает, что знания модели зафиксированы в весах нейронной сети во время обучения и не изменяются в процессе работы с новыми данными. В то время как мозг способен формировать новые связи, усиливать одни воспоминания и ослаблять другие, языковые модели, по сути, «запоминают» информацию, а не «понимают» её в контексте текущей задачи. Эта статичность представляет собой фундаментальное ограничение, препятствующее способности модели эффективно интегрировать новую информацию с ранее полученными знаниями и адаптироваться к изменяющимся обстоятельствам, что особенно заметно при обработке длинных и сложных текстов.
Возникающие трудности в интеграции новой информации с уже накопленными знаниями существенно ограничивают возможности больших языковых моделей в решении сложных задач. В отличие от биологического интеллекта, способного динамически адаптировать и переосмысливать информацию в контексте меняющихся обстоятельств, параметрическая память LLM остается относительно статичной. Это приводит к тому, что модели испытывают затруднения при обработке нюансированных или развивающихся сценариев, где требуется не просто воспроизведение заученных паттернов, а гибкое применение знаний к новым, неожиданным ситуациям. В результате, даже обладая огромным объемом информации, языковая модель может демонстрировать нелогичные или нерелевантные ответы, когда сталкивается с контекстом, требующим адаптации и критического мышления.
Вероятностное побуждение памяти: имитация забывания в LLM
Метод вероятностного запроса памяти (Probabilistic Memory Prompting) представляет собой новый подход к формированию интеграции доказательств в больших языковых моделях (LLM) путем моделирования человеческих следов забывания. В отличие от традиционных методов, где вся предыдущая информация сохраняется с равным весом, данный подход имитирует когнитивные процессы, при которых релевантность прошлых опытов со временем уменьшается. Это достигается путем динамической оценки и взвешивания предыдущих данных, позволяя модели избирательно «забывать» менее значимую информацию и отдавать приоритет текущим входным данным, что способствует более эффективной обработке и интеграции новых знаний.
Метод использует принципы Байесовского вывода для динамической оценки веса предыдущего опыта. Это позволяет модели выборочно “забывать” менее релевантную информацию, уменьшая ее влияние на текущие вычисления, и одновременно усиливать значимость текущих входных данных. Веса, присваиваемые каждому элементу памяти, рассчитываются на основе вероятности того, что он соответствует текущему контексту, что обеспечивает автоматическую приоритизацию наиболее актуальной информации и снижение влияния устаревших данных. P(x|y) = \frac{P(y|x)P(x)}{P(y)} — базовая формула Байеса, используемая для обновления весов памяти в зависимости от новых входных данных.
Для управления скоростью “забывания” информации в модели, используется коэффициент дисконтирования, откалиброванный с помощью расхождения Кульбака-Лейблера (KL Divergence). Этот коэффициент позволяет динамически уменьшать вес прошлых опытов, придавая больший приоритет текущим входным данным. Калибровка посредством KL Divergence обеспечивает соответствие скорости затухания памяти наблюдаемым когнитивным принципам, а именно — моделированию естественного забывания нерелевантной информации в человеческой памяти. D_{KL}(P||Q) = \sum_i P(i) \log \frac{P(i)}{Q(i)} — данная формула отражает меру различия между распределениями вероятностей, используемую для настройки коэффициента дисконтирования.
Проверка подхода: сопоставление с когнитивными способностями человека
Для оценки эффективности метода Probabilistic Memory Prompting был проведен комплексный анализ на трех ключевых задачах: «Темпоральное Рассуждение», «Ассоциативное Воспроизведение» и «Концептуальный Дрейф». Эти задачи были специально разработаны для моделирования процессов забывания и оценки способности модели к сохранению и восстановлению информации с течением времени. Задача «Темпоральное Рассуждение» требовала от модели установления последовательности событий, «Ассоциативное Воспроизведение» проверяло способность к установлению связей между различными понятиями, а «Концептуальный Дрейф» моделировал изменения в данных и необходимость адаптации модели к новым условиям. Результаты тестирования по этим задачам позволили количественно оценить поведение модели в условиях, имитирующих забывание, и сравнить его с аналогичным поведением у людей.
Результаты экспериментов показали, что языковые модели, использующие метод Probabilistic Memory Prompting, демонстрируют повышенную способность к адаптации к изменяющимся контекстам и поддержанию производительности с течением времени. В ходе тестирования на различных задачах, включая Temporal Reasoning, Associative Recall и Concept Drift, модели с этим методом превосходили базовые модели в задачах, требующих учета новых данных и забывания устаревшей информации. Наблюдаемое улучшение производительности связано с тем, что Probabilistic Memory Prompting позволяет модели более эффективно отслеживать релевантность информации в динамически меняющейся среде, что приводит к более устойчивым и надежным результатам.
Результаты моделирования показали, что кривые забывания, демонстрируемые языковой моделью с использованием предложенного метода, качественно соответствуют кривым забывания, наблюдаемым в экспериментах с человеческой памятью. В частности, наблюдается схожая экспоненциальная зависимость потери информации от времени, а также эффект первоначального быстрого забывания с последующим замедлением. Такое соответствие в динамике забывания подтверждает предположение о том, что данная методика способствует достижению когнитивного выравнивания модели с принципами работы человеческой памяти, что является важным шагом на пути к созданию более адаптивных и надежных систем искусственного интеллекта.
Расширение горизонтов: надежные рассуждения и адаптивное обучение
Исследования показали, что применение вероятностного подкрепления памяти значительно улучшает результаты на сложных задачах, требующих рассуждений, таких как HotpotQA, GSM8K и HumanEval. Данный подход позволяет модели более эффективно обрабатывать информацию и находить решения, даже в условиях неполных или противоречивых данных. В частности, улучшение наблюдается в задачах, требующих многоступенчатых рассуждений и анализа больших объемов информации, где традиционные методы часто демонстрируют ограниченную эффективность. Вероятностное подкрепление памяти обеспечивает динамическое управление информацией, позволяя модели сосредотачиваться на наиболее релевантных данных и отбрасывать ненужные, что повышает точность и надежность принимаемых решений.
Исследования показывают, что управляемое забывание в моделях искусственного интеллекта — это не просто оптимизация использования памяти, а фундаментальный механизм, способствующий повышению надёжности и точности рассуждений. Вместо пассивного хранения всей доступной информации, способность избирательно отбрасывать нерелевантные или потенциально вводящие в заблуждение данные позволяет модели фокусироваться на наиболее значимых аспектах задачи. Этот процесс, подобный фильтрации шума, позволяет избежать когнитивных искажений и повысить устойчивость к ошибкам, что особенно важно при решении сложных задач, требующих логического мышления и анализа. Таким образом, контролируемое «забывание» становится неотъемлемой частью процесса принятия решений, обеспечивая более обоснованные и достоверные результаты.
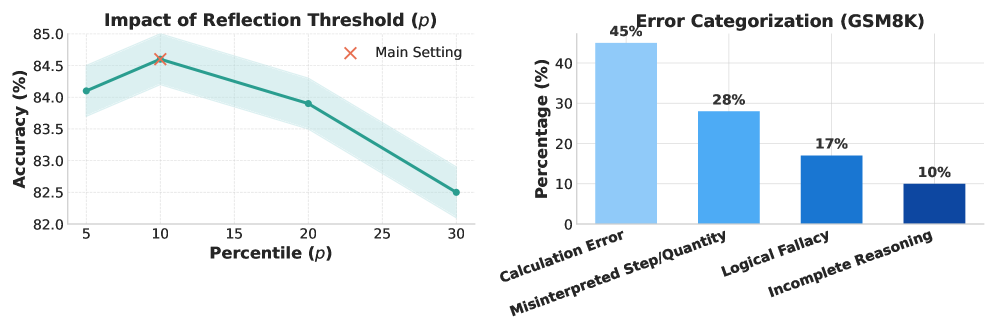
Внедрение Рамочной Системы Оценки Надежности (Reflection Confidence Framework) позволило модели активно снижать количество ошибок при решении задач. Исследования показали, что данный подход обеспечивает абсолютное улучшение точности до 4.2% в наборе данных GSM8K, превосходя как стандартные методы запросов, так и стратегии ранней остановки, основанные на оценке уверенности. Это свидетельствует о том, что активное выявление и исправление собственных ошибок значительно повышает надежность и эффективность модели в сложных задачах математического рассуждения, позволяя ей достигать более точных и обоснованных результатов.
К когнитивному ИИ: будущее адаптивной памяти
Метод вероятностной подсказки памяти представляет собой важный шаг на пути к созданию больших языковых моделей (LLM), способных не просто обрабатывать информацию, но и обучаться и адаптироваться подобно человеку. В отличие от традиционных LLM, которые полагаются на статичные параметры, этот подход позволяет моделям оценивать надежность воспоминаний и соответствующим образом корректировать свои ответы. Суть заключается в том, что при извлечении информации из «памяти» модели, учитывается вероятность ее достоверности, что позволяет избежать распространения неточной или устаревшей информации. По сути, модель учится «сомневаться» в своих знаниях, что имитирует когнитивные процессы, свойственные человеческому мозгу. Это открывает возможности для создания более надежных и адаптивных систем искусственного интеллекта, способных к непрерывному обучению и самосовершенствованию, что является ключевым аспектом в стремлении к созданию действительно «когнитивного» ИИ.
Предстоящие исследования направлены на интеграцию вероятностного побуждения памяти с другими когнитивными архитектурами, что позволит создать более сложные и универсальные системы искусственного интеллекта. Ученые стремятся объединить данный метод с моделями, имитирующими внимание, планирование и рассуждение, чтобы получить ИИ, способный не просто хранить и извлекать информацию, но и активно использовать её для решения задач, требующих гибкости и адаптивности. Ожидается, что подобный симбиоз различных когнитивных механизмов приведет к созданию ИИ, демонстрирующего не только улучшенную производительность в конкретных областях, но и более широкие возможности для обучения и обобщения знаний, приближая его к уровню человеческого интеллекта. Разработка таких систем откроет новые перспективы для применения ИИ в различных сферах, от автоматизации сложных процессов до создания интеллектуальных помощников, способных понимать и реагировать на меняющиеся условия окружающей среды.
В стремлении к созданию действительно интеллектуальных систем искусственного интеллекта, все больше внимания уделяется принципам, лежащим в основе биологического разума. Изучение механизмов памяти, обучения и адаптации, характерных для живых организмов, открывает новые горизонты для разработки языковых моделей. Применение этих принципов позволяет не просто обрабатывать информацию, но и формировать устойчивые знания, обобщать опыт и находить решения в сложных, непредсказуемых ситуациях. В результате, языковые модели перестают быть лишь инструментами для генерации текста и превращаются в системы, способные к глубокому пониманию и эффективному решению реальных задач, приближаясь к уровню когнитивных способностей человека.
Исследование, представленное в статье, подчёркивает важность не только запоминания, но и контролируемого забывания для эффективного рассуждения в больших языковых моделях. Этот подход перекликается с идеями Тима Бернерса-Ли, который однажды сказал: «Интернет — это для всех, и он должен быть доступен каждому». Подобно тому, как Интернет должен адаптироваться и обновляться, чтобы оставаться актуальным, языковые модели нуждаются в механизмах, позволяющих им отбрасывать устаревшую информацию и фокусироваться на текущих задачах. Внедрение контролируемого забывания, как описано в статье, способствует когнитивному выравниванию моделей, делая их более гибкими и способными к адаптации к изменяющимся данным и концептуальному дрейфу.
Куда двигаться дальше?
Представление о «забывании» как о полезном когнитивном механизме в больших языковых моделях, предложенное в данной работе, открывает плодотворное поле для размышлений. Однако, подобно попыткам воссоздать человеческое сознание из отдельных нейронов, необходимо осознавать границы этой аналогии. Если система держится на костылях «вероятностной подсказки памяти», значит, мы переусложнили её, не сумев создать подлинную основу для адаптивного поведения. Модульность без понимания контекста — иллюзия контроля, а способность «забывать» устаревшую информацию — лишь первый шаг к подлинному пониманию времени и изменяющегося мира.
Особое внимание следует уделить исследованию концептуального дрейфа. Недостаточно просто «стирать» старые данные; необходимо понимать, как происходит переоценка информации, какие факторы влияют на изменение веса концепций, и как это связано с долгосрочной когнитивной согласованностью. Более того, предложенный подход нуждается в тщательной проверке на различных задачах и архитектурах, чтобы избежать ситуации, когда «контролируемое забывание» становится лишь еще одним параметром, требующим тонкой настройки.
В конечном счете, задача заключается не в том, чтобы создать модель, имитирующую человеческую память, а в том, чтобы разработать принципиально новые системы, способные к адаптивному обучению и эффективному управлению знаниями. Поиск элегантных решений, основанных на простоте и ясности, остается главным вызовом в этой области.
Оригинал статьи: https://arxiv.org/pdf/2601.09726.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2026-01-19 05:27