Автор: Денис Аветисян
Исследователи представили новый способ оценки качества управления долгосрочной памятью в больших языковых моделях, выявляя слабые места существующих систем вознаграждения.
Представлен MemRewardBench — эталон для оценки моделей вознаграждения в задачах управления долгосрочной памятью больших языковых моделей.
Эффективная обработка длинных контекстов остается сложной задачей для больших языковых моделей, требующей совершенствования механизмов управления памятью. В данной работе представлена $\texttt{MemoryRewardBench}$: Benchmarking Reward Models for Long-Term Memory Management in Large Language Models — первая комплексная методика оценки способности моделей вознаграждения (RM) к анализу долгосрочного управления памятью в LLM. Исследование показало, что, несмотря на прогресс, существующие RM демонстрируют ограничения в оценке качества памяти, а разрыв в производительности между открытыми и проприетарными моделями постепенно сокращается. Какие новые подходы к разработке RM позволят более точно оценивать и улучшать способность LLM к эффективному использованию долгосрочной памяти?
Вызов долгосрочной памяти в больших языковых моделях
Несмотря на впечатляющие успехи в решении разнообразных задач, большие языковые модели (LLM) сталкиваются с существенной трудностью при обработке длинных последовательностей текста. Способность поддерживать согласованность и релевантность информации постепенно снижается по мере увеличения длины входного текста, что приводит к потере контекста и логической связности. В результате, даже модели, демонстрирующие выдающиеся результаты на коротких отрывках, могут выдавать бессвязные или нелогичные ответы при работе с более объемными текстами, такими как длинные статьи, книги или расширенные диалоги. Эта проблема является серьезным препятствием для применения LLM в задачах, требующих глубокого понимания и сохранения информации на протяжении всей последовательности.
Ограничение способности больших языковых моделей (БЯМ) сохранять последовательность и релевантность в длинных последовательностях текста существенно влияет на их производительность в задачах, требующих глубокого рассуждения и понимания сложного контекста. Например, при генерации объемных текстов, таких как романы или научные статьи, БЯМ часто испытывают трудности с поддержанием единой темы и логической связи между абзацами. Аналогичная проблема возникает и в многоходовых диалогах, где модель может забыть предыдущие реплики и потерять нить разговора, что приводит к бессвязным и нелогичным ответам. В результате, способность БЯМ эффективно обрабатывать длинные контексты является ключевым фактором, определяющим качество генерируемого текста и успешность взаимодействия с пользователем.
Традиционные методы последовательной обработки информации создают серьезные препятствия для эффективного доступа и использования долгосрочной памяти в больших языковых моделях. В отличие от человеческого мозга, способного параллельно обрабатывать и извлекать данные из различных областей памяти, LLM вынуждены последовательно перебирать информацию, что приводит к экспоненциальному росту вычислительных затрат и задержек при работе с длинными последовательностями. Это ограничение особенно заметно при обработке больших объемов текста, где модель сталкивается с проблемой «забывания» ранней информации, необходимой для поддержания контекста и обеспечения согласованности. В результате, способность LLM к глубокому рассуждению и сложному пониманию контекста существенно снижается, что негативно сказывается на качестве генерируемого текста и эффективности диалоговых систем.
Эффективное управление долгосрочной памятью представляется ключевым фактором для реализации полного потенциала больших языковых моделей (LLM) в сложных приложениях. Способность сохранять и оперативно использовать информацию на протяжении длительных последовательностей текста необходима для решения задач, требующих глубокого рассуждения и понимания контекста, таких как создание развернутых текстов или ведение многоходовых диалогов. Отсутствие такой способности ограничивает возможности LLM в сферах, где важна последовательность и взаимосвязь информации, препятствуя созданию действительно интеллектуальных систем, способных к сложному анализу и синтезу знаний. Разработка новых методов управления памятью, позволяющих LLM эффективно извлекать и использовать релевантную информацию из обширных объемов данных, является приоритетной задачей для исследователей, стремящихся к созданию более совершенных и функциональных языковых моделей.

Разнообразие паттернов памяти для повышения производительности
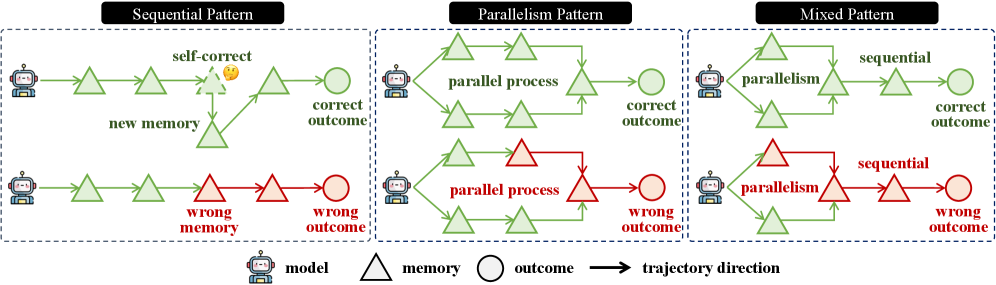
Существуют различные паттерны управления памятью, каждый из которых обладает своими особенностями и компромиссами при работе с длинными последовательностями данных. Эти паттерны варьируются по способу организации и доступа к информации, влияя на скорость обработки, точность и эффективность использования ресурсов. Например, последовательные паттерны обеспечивают строгий порядок обработки, но могут быть медленными, в то время как параллельные паттерны повышают скорость за счет одновременной обработки, но потенциально снижают когерентность данных. Выбор конкретного паттерна зависит от требований конкретной задачи и характеристик обрабатываемой последовательности.
Последовательный шаблон памяти обрабатывает информацию поэтапно, последовательно выполняя операции над каждым элементом данных. Данный подход особенно эффективен в задачах, требующих строгой упорядоченности обработки, таких как синтаксический анализ или временные ряды. Однако, обработка каждого элемента последовательно ограничивает возможности параллелизации, что может приводить к увеличению времени выполнения при работе с большими объемами данных или сложными вычислениями. В отличие от параллельных методов, последовательный шаблон не использует преимущества многоядерных процессоров или распределенных систем для ускорения обработки.
Параллельный паттерн памяти обеспечивает одновременную обработку информации, что приводит к повышению скорости работы системы. Однако, в отличие от последовательной обработки, параллельный подход может приводить к снижению когерентности данных. Это связано с тем, что несколько фрагментов информации обрабатываются одновременно, что требует дополнительных механизмов для обеспечения согласованности и избежания конфликтов при записи или чтении данных. В результате, хотя скорость обработки увеличивается, необходимо учитывать потенциальные сложности в поддержании целостности информации, особенно в задачах, требующих строгой последовательности операций.
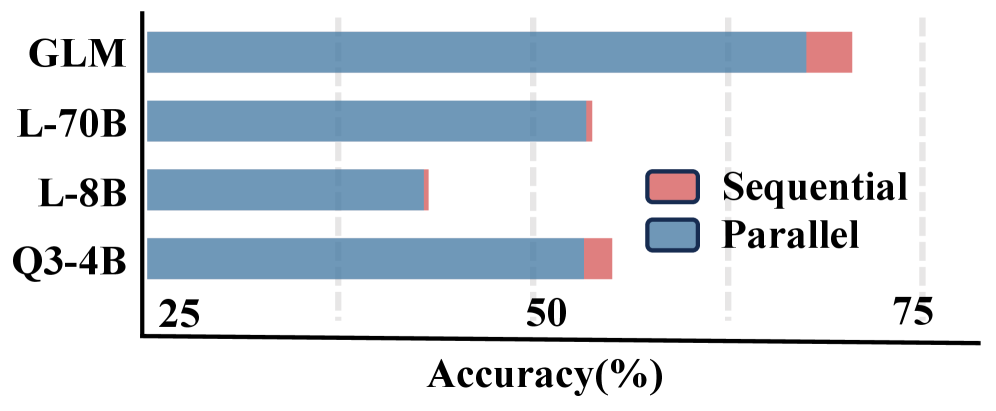
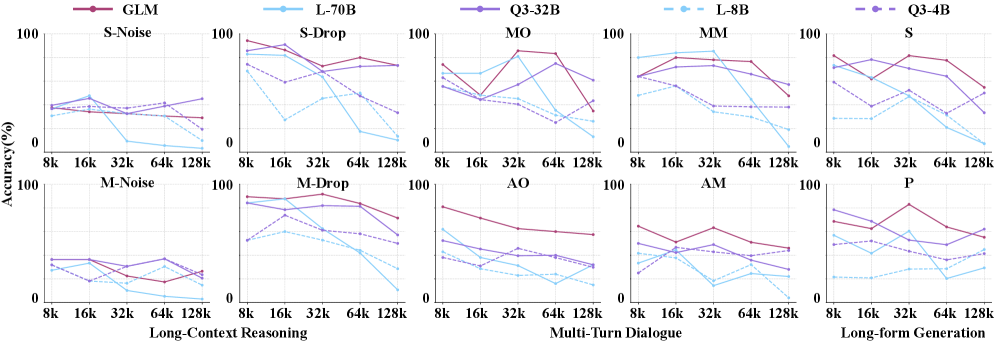
Гибридные подходы к управлению памятью, такие как Смешанный Паттерн Памяти (Mixed Memory Pattern), стремятся объединить преимущества последовательной и параллельной обработки данных. В частности, было установлено, что последовательные паттерны (Sequential Patterns) демонстрируют более высокую точность по сравнению с параллельными (Parallel Patterns). Этот факт указывает на то, что оценка результатов, полученных с использованием последовательных паттернов, проще для современных Моделей Вознаграждения (Reward Models), что может быть связано с более предсказуемой и линейной структурой процесса обработки информации.
Усовершенствованные архитектуры памяти: A-Mem и Mem0
Системы, такие как A-Mem, улучшают процесс извлечения информации из памяти за счет добавления семантических тегов к каждой записи об обновлении данных. Эти теги служат дополнительным контекстом, позволяющим более точно идентифицировать и извлекать релевантную информацию. Вместо простого хранения данных, A-Mem сохраняет не только сами данные, но и метаданные, описывающие их смысл и взаимосвязь с другими данными. Это позволяет системе проводить более сложные запросы и находить информацию, основываясь не только на точном совпадении, но и на семантической близости, что значительно повышает эффективность поиска и извлечения данных, особенно в больших объемах информации.
Mem0 использует глобальное суммарное представление памяти, которое обновляется на каждом шаге обработки последовательности. Этот подход позволяет эффективно получать доступ к ключевой информации, поскольку суммарное представление содержит сжатую версию всей релевантной истории. Обновление суммарного представления на каждом шаге обеспечивает его актуальность и позволяет избегать повторной обработки уже известной информации, что значительно снижает вычислительные затраты и повышает скорость работы системы. Фактически, Mem0 выступает в роли динамически обновляемого индекса, облегчающего поиск и извлечение наиболее важной информации из долгосрочной памяти.
Архитектуры памяти, такие как A-Mem и Mem0, в сочетании с методами сегментированной и целостной обработки, оказывают существенное влияние на способ обработки длинных последовательностей данных. Сегментированная обработка разбивает входные данные на более мелкие, управляемые сегменты, что позволяет параллельно обрабатывать отдельные части. Целостная обработка, напротив, стремится к обработке всей последовательности как единого целого, учитывая взаимосвязи между элементами. Использование этих подходов позволяет оптимизировать использование памяти и вычислительных ресурсов, снижая задержки и повышая эффективность обработки длинных последовательностей, что особенно важно в задачах, связанных с обработкой естественного языка и анализом временных рядов.
Внедрение инновационных архитектур памяти, таких как A-Mem и Mem0, а также методов обработки последовательностей, включая сегментированную и целостную обработку, является критически важным для оптимизации производительности долгосрочной памяти. Эти подходы позволяют существенно снизить задержки при доступе к данным, уменьшить избыточную обработку и повысить эффективность использования ресурсов памяти. Достигается это за счет обогащения контекста доступа к информации, создания глобальных сводок по памяти и адаптивной обработки последовательностей, что позволяет системам более эффективно извлекать и использовать информацию, накопленную в долгосрочной перспективе. Недостаточное внимание к этим архитектурам может привести к снижению производительности и ограничить возможности обработки больших объемов данных в системах искусственного интеллекта и машинного обучения.
MemRewardBench: Оценка управления памятью в больших языковых моделях
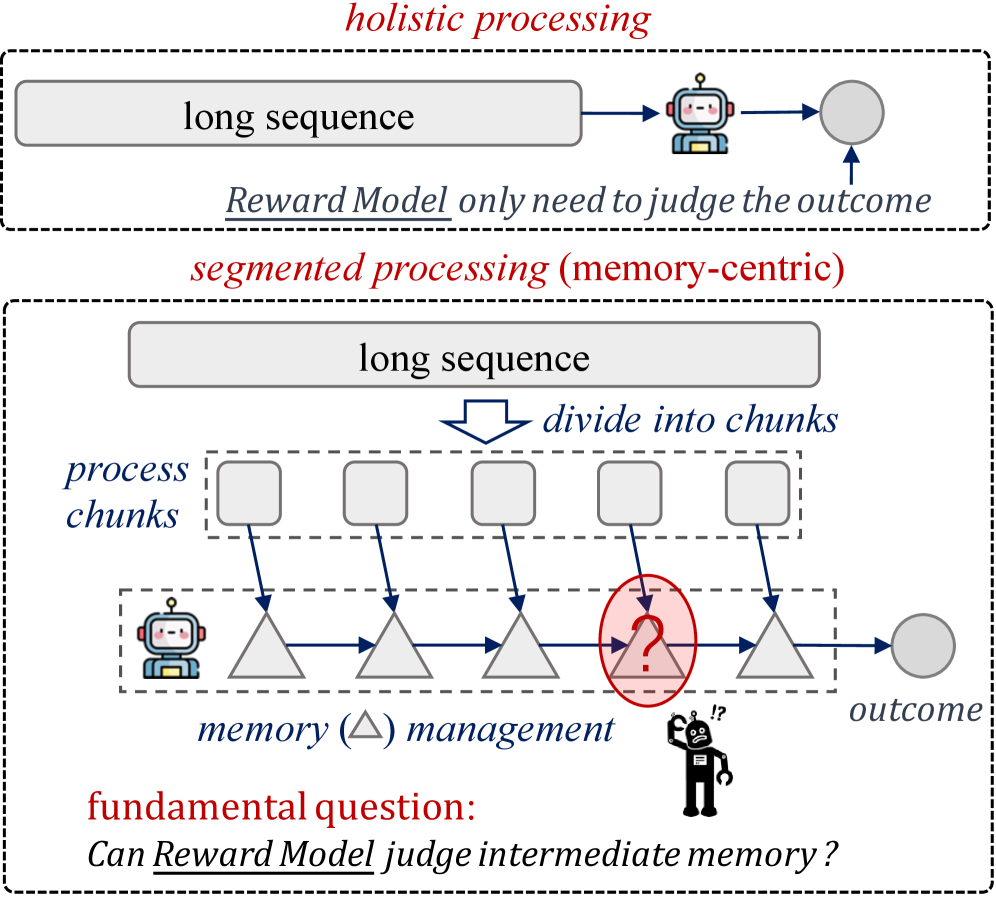
MemRewardBench — это новый эталон, разработанный для оценки эффективности работы моделей вознаграждения (Reward Models, RM) при анализе долгосрочной промежуточной памяти в больших языковых моделях (LLM). В отличие от традиционных методов оценки, ориентированных на конечный результат, MemRewardBench фокусируется на оценке качества и релевантности промежуточных представлений памяти, используемых LLM для решения сложных задач. Эталон позволяет количественно оценить, насколько хорошо RM способны различать полезные и бесполезные фрагменты памяти, что критически важно для улучшения архитектур и алгоритмов управления памятью в LLM. Оценка строится на принципах дискриминативных и генеративных моделей вознаграждения, что обеспечивает более детализированную и нюансированную обратную связь по качеству работы памяти.
В основе MemRewardBench лежит использование принципов построения моделей вознаграждения (Reward Models, RM), включающих в себя дискриминативные и генеративные модели вознаграждения. Дискриминативные модели оценивают качество памяти на основе сравнения с эталонными данными, в то время как генеративные модели вознаграждения способны генерировать обратную связь, учитывающую сложность и релевантность запомненной информации. Такой подход позволяет получать детализированную оценку качества промежуточной памяти, выходящую за рамки простой проверки соответствия конечному результату, и предоставляет более тонкие сигналы для оптимизации стратегий управления памятью в больших языковых моделях.
В MemRewardBench используется два подхода к оценке: оценка по результату (Outcome-Based Evaluation) и оценка по процессу (Process-Based Evaluation). Оценка по результату фокусируется на конечном успехе LLM в выполнении задачи, определяя, насколько эффективно использованная память способствовала достижению правильного ответа. Оценка по процессу, в свою очередь, анализирует промежуточные шаги и логику, используемые LLM при работе с памятью, оценивая качество и релевантность сохраненной информации. Комбинация этих двух подходов позволяет получить всестороннюю оценку стратегий управления памятью, выявляя как эффективность конечного результата, так и качество самого процесса доступа и использования информации.
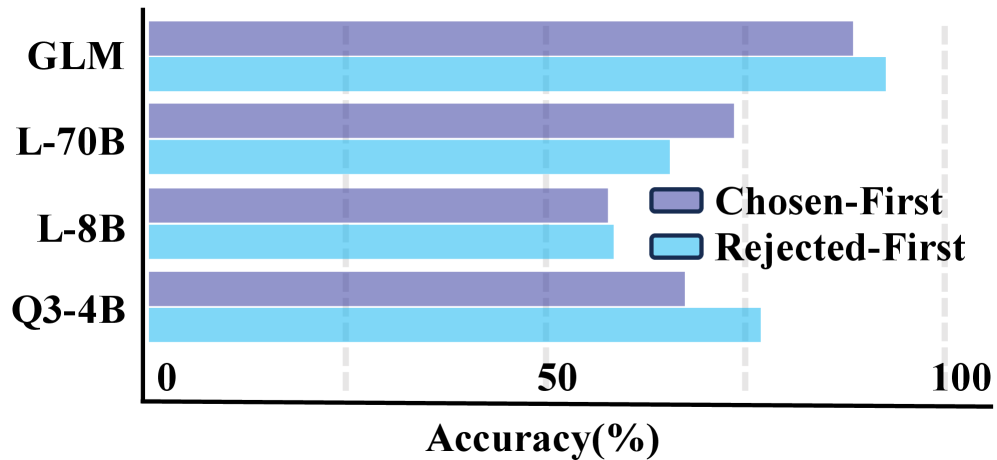
Результаты тестирования на MemRewardBench демонстрируют потенциал данного бенчмарка для оценки эффективности моделей обработки естественного языка. В частности, модель Claude-Opus-4.5 показала точность в 74.75% при решении задач, требующих рассуждений на основе длинного контекста. Кроме того, GLM-4.5-106A12B превзошла Qwen3-Max, достигнув показателя в 68.21%. Данные результаты подтверждают способность MemRewardBench к проведению объективной и надежной оценки различных архитектур и стратегий управления памятью в больших языковых моделях.
Строгая оценочная база, предоставляемая MemRewardBench, имеет решающее значение для дальнейшего развития области управления памятью в больших языковых моделях (LLM). Необходимость в стандартизированной методике оценки обусловлена разнообразием архитектур памяти и алгоритмов, применяемых в LLM. Точная и объективная оценка позволяет выявлять наиболее эффективные подходы к организации и использованию промежуточной памяти, что, в свою очередь, способствует повышению производительности моделей в задачах, требующих долгосрочного запоминания и обработки информации. Использование MemRewardBench для систематического анализа различных архитектур памяти позволит исследователям и разработчикам создавать более надежные и эффективные LLM, способные успешно решать сложные задачи, требующие контекстуального понимания и сохранения информации на протяжении длительных последовательностей.
Будущие направления: К созданию надежных больших языковых моделей с долгосрочной памятью
Для создания надежных больших языковых моделей (LLM), способных эффективно работать с длинными контекстами, необходимы дальнейшие исследования в области новых архитектур памяти и систем оценки. Существующие подходы часто сталкиваются с трудностями при обработке больших объемов информации, что приводит к потере релевантности и снижению точности. Разработка инновационных структур памяти, таких как иерархические или разреженные представления, может существенно улучшить способность моделей хранить и извлекать важную информацию из длинных текстов. Параллельно с этим, крайне важно создание более совершенных оценочных метрик и бенчмарков, которые позволят точно измерить и сравнить эффективность различных архитектур и методов в обработке длинных контекстов. Только комплексный подход, объединяющий новые архитектуры памяти и надежные системы оценки, позволит создать LLM, способные эффективно и надежно обрабатывать длинные тексты и решать сложные задачи, требующие долгосрочного запоминания и анализа информации.
Исследования, проведенные с использованием MemRewardBench, выявили ключевые аспекты эффективного управления памятью в больших языковых моделях. Интеграция полученных знаний непосредственно в процессы обучения позволяет создавать системы, способные более точно извлекать и использовать информацию из длинных контекстов. Такой подход предполагает не просто увеличение объема памяти, но и оптимизацию механизмов доступа к ней, что приводит к существенному повышению производительности в задачах, требующих долгосрочного запоминания и обработки данных. Внедрение принципов, выявленных MemRewardBench, обещает значительный прогресс в создании языковых моделей, способных к более сложному и осмысленному взаимодействию с информацией.
Исследования последних поколений больших языковых моделей демонстрируют устойчивую тенденцию к превосходству над предыдущими версиями, причем это превосходство проявляется независимо от количества параметров. Наблюдаемые улучшения в производительности не связаны напрямую с увеличением масштаба моделей, что указывает на значительный прогресс в архитектурных инновациях и методах обучения. Данный факт свидетельствует о том, что ключевым фактором развития является оптимизация алгоритмов и структур, позволяющая более эффективно использовать существующие ресурсы и извлекать больше информации из обучающих данных. Подобные достижения открывают возможности для создания более компактных и энергоэффективных моделей, способных решать сложные задачи без необходимости экспоненциального увеличения вычислительных затрат.
Применение разработанных методов к сложным задачам, таким как логическое мышление в длинном контексте, открывает значительные перспективы в областях поиска информации и открытия новых знаний. Способность эффективно обрабатывать и анализировать обширные объемы данных позволяет моделям не просто извлекать релевантную информацию, но и устанавливать сложные взаимосвязи, делать выводы и генерировать новые гипотезы. Это особенно важно для научных исследований, анализа больших данных в экономике и финансах, а также для создания интеллектуальных систем, способных к самостоятельному обучению и принятию решений на основе комплексного анализа доступной информации. Подобные технологии могут кардинально изменить подходы к обработке информации, сделав её более доступной, структурированной и полезной для различных областей деятельности.
Освоение долгосрочного управления памятью представляется ключевым фактором для раскрытия всего потенциала больших языковых моделей и создания по-настоящему интеллектуальных систем. Эффективное хранение и извлечение информации из обширных контекстов позволит моделям не просто генерировать текст, но и демонстрировать глубокое понимание, способность к рассуждению и решению сложных задач, требующих анализа больших объемов данных. В конечном итоге, прогресс в этой области откроет возможности для создания систем, способных к непрерывному обучению и адаптации, что приблизит искусственный интеллект к уровню человеческого познания и откроет новые горизонты в таких сферах, как научные исследования, образование и автоматизация сложных процессов.
Исследование, представленное в статье, неизбежно сталкивается с необходимостью оценки качества работы моделей управления долгосрочной памятью. Этот процесс, как показывает практика, требует не только разработки метрик, но и их адекватной интерпретации. Карл Фридрих Гаусс однажды заметил: «Трудность заключается не в интеллектуальных способностях, а в преодолении препятствий». Эта фраза отражает суть проблемы: сложность не в создании самих моделей, а в объективной оценке их эффективности, особенно в контексте управления памятью, где субъективность может искажать результаты. MemRewardBench, предлагаемый в статье, является попыткой создать более прозрачный и объективный инструмент оценки, минимизируя влияние субъективных факторов и приближаясь к истинной мере качества.
Куда же дальше?
Представленная работа, как и любое измерение сложности, лишь обнажила пробелы в кажущейся стройности существующих моделей. Оценка качества управления долгосрочной памятью посредством reward models оказалась делом нетривиальным, а зачастую и иллюзорным. Текущие модели, как показывает MemRewardBench, склонны к поверхностным суждениям, упуская из виду нюансы истинного знания и его эффективной организации. Удобство оценки не должно подменять глубину понимания.
Настоящая задача — не в усложнении reward models, а в их радикальном упрощении. Требуется отбросить избыточные параметры и сконцентрироваться на фундаментальных принципах: релевантность, связность и устойчивость информации. Интуиция подсказывает, что истинный «компилятор» качественной памяти — это не сложный алгоритм, а элегантный принцип.
Следующим шагом видится отказ от метрик, измеряющих лишь поверхностные признаки. Необходимо разработать методы, способные оценивать способность модели к генерации новых знаний, к адаптации к меняющимся условиям, к обнаружению и исправлению собственных ошибок. Иначе говоря, нужна оценка не просто хранения информации, а ее осмысленного использования. И тогда, возможно, мы приблизимся к созданию действительно разумных систем.
Оригинал статьи: https://arxiv.org/pdf/2601.11969.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовый Переход: Пора Заботиться о Криптографии
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовая обработка данных: новый подход к повышению точности моделей
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая криптография: от теории к практике
- Лунный гелий-3: Охлаждение квантового будущего
2026-01-21 09:29