Автор: Денис Аветисян
Исследователи представили RAM-Net — архитектуру, позволяющую эффективно обрабатывать длинные последовательности данных, не увеличивая размер модели.
RAM-Net использует дифференцируемый декодер адресов и разреженную память для повышения точности и эффективности моделирования последовательностей.
В архитектурах линейного внимания, несмотря на их вычислительную эффективность, сжатие неограниченной истории в память фиксированного размера неизбежно приводит к потере информации и снижению выразительности. В данной работе представлена новая архитектура ‘RAM-Net: Expressive Linear Attention with Selectively Addressable Memory’, использующая дифференцируемый декодер адресов и разреженную память для отделения емкости памяти от размера модели. Такой подход позволяет добиться высокой точности и эффективности при моделировании последовательностей, обеспечивая экспоненциальный рост состояния без увеличения числа параметров. Сможет ли RAM-Net стать основой для создания более мощных и экономичных моделей обработки естественного языка, способных улавливать сложные зависимости в больших объемах данных?
Память как основа: Проблема последовательного моделирования
Традиционные подходы к моделированию последовательностей, такие как архитектура Transformer, демонстрируют впечатляющую способность улавливать долгосрочные зависимости в данных. Однако, эта мощь достигается ценой квадратичного роста потребления памяти с увеличением длины последовательности. Это означает, что объем необходимой памяти увеличивается пропорционально квадрату количества элементов в последовательности O(n^2). В результате, обработка очень длинных последовательностей становится затруднительной, а в некоторых случаях и невозможной из-за ограничений вычислительных ресурсов и возросшей стоимости вычислений. Данное ограничение существенно препятствует применению этих моделей в задачах, требующих анализа обширных текстовых документов, длинных аудиозаписей или видеопотоков.
Проблема масштабируемости существенно ограничивает возможности современных последовательных моделей, таких как Трансформеры, при работе с длинными последовательностями данных. Необходимость хранения и обработки информации о взаимодействии каждого элемента последовательности с каждым другим приводит к квадратичному росту потребляемой памяти с увеличением длины последовательности. Это, в свою очередь, не только значительно увеличивает вычислительные затраты, делая обработку очень длинных текстов или видео непрактичной, но и препятствует применению этих моделей в областях, требующих анализа обширных контекстов, например, в долгосрочном прогнозировании, обработке больших объемов геномных данных или при создании детализированных языковых моделей, способных понимать и генерировать сложные нарративы.
Механизм полного внимания, являясь мощным инструментом в моделях последовательностей, сталкивается с существенными ограничениями при увеличении длины обрабатываемых последовательностей. Вычислительная сложность и потребление памяти растут квадратично относительно длины последовательности, что делает его применение непрактичным для задач, требующих обработки очень длинных текстов или временных рядов. Каждый токен должен быть сравнен со всеми остальными, что создает огромную нагрузку на память и замедляет процесс обучения и инференса. Поэтому, разработка более эффективных методов доступа к памяти и снижения вычислительной сложности, сохраняя при этом способность модели улавливать важные зависимости, является ключевой задачей в области моделирования последовательностей. Поиск компромисса между точностью и эффективностью является критически важным для расширения возможностей применения моделей к более масштабным и сложным задачам.
Существующие механизмы линейного внимания, стремясь к повышению эффективности обработки последовательностей, часто прибегают к использованию рекуррентного состояния фиксированного размера. Этот подход, хотя и позволяет снизить потребность в памяти по сравнению с полным вниманием, неизбежно приводит к потере информации и снижению точности модели. В процессе обработки длинных последовательностей, фиксированный размер состояния становится узким местом, не позволяя модели эффективно запоминать и использовать информацию из всей последовательности. В результате, такие модели могут демонстрировать ухудшение производительности при решении задач, требующих учета долгосрочных зависимостей, и уступают более ресурсоемким, но точным механизмам полного внимания в сложных сценариях. Фактически, происходит компромисс между скоростью и точностью, где снижение вычислительных затрат достигается за счет упрощения процесса внимания и, как следствие, уменьшения способности модели к детализированному анализу данных.
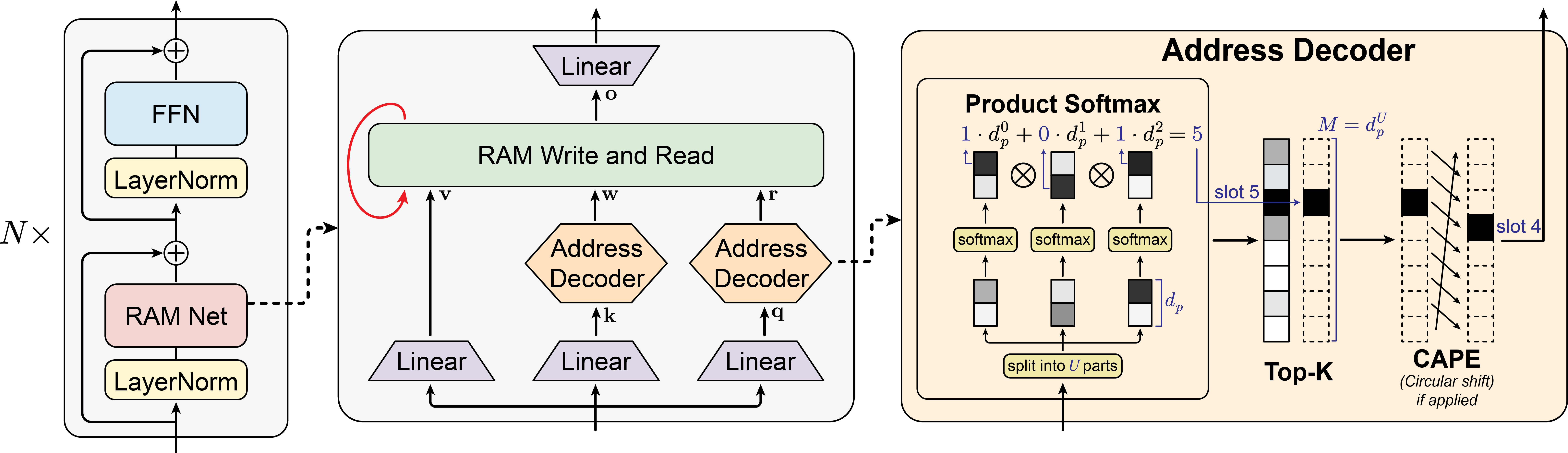
RAM-Net: Дифференцируемый доступ к памяти — решение проблемы
RAM-Net решает проблему узкого места, связанного с памятью, за счет использования дифференцируемого декодера адресов для выборочного доступа к глобальному состоянию памяти. Вместо последовательного обращения ко всем ячейкам памяти, декодер преобразует входные векторы в адреса, определяющие, к каким конкретным ячейкам следует обращаться. Этот подход позволяет системе динамически выбирать, какие части глобальной памяти релевантны для текущего ввода, избегая необходимости обработки всей памяти при каждом шаге. Дифференцируемость декодера позволяет оптимизировать процесс доступа к памяти с помощью стандартных методов градиентного спуска, интегрируя его в процесс обучения модели.
Декодер адресов в RAM-Net преобразует плотные входные векторы в разреженные векторы высокой размерности. Этот процесс позволяет осуществлять эффективный доступ к ячейкам глобальной памяти, поскольку вместо обращения ко всем ячейкам, система фокусируется на небольшом подмножестве, определенных разреженным вектором адреса. Разреженность вектора адреса существенно снижает вычислительную сложность операции доступа к памяти и уменьшает требования к пропускной способности, обеспечивая более быстрый и энергоэффективный доступ к данным. Такой подход позволяет масштабировать архитектуру RAM-Net для работы с большими объемами данных без значительного увеличения вычислительных затрат.
В отличие от традиционных рекуррентных нейронных сетей, где объем памяти растет пропорционально длине входной последовательности, RAM-Net обеспечивает постоянный объем используемой памяти, не зависящий от размера входных данных. Это достигается за счет разделения процесса извлечения информации из памяти от длины последовательности. Архитектура RAM-Net оперирует с глобальным состоянием памяти фиксированного размера и обращается к нему посредством дифференцируемого декодера адресов, что позволяет эффективно извлекать релевантную информацию независимо от длины входной последовательности. Таким образом, RAM-Net позволяет обрабатывать последовательности переменной длины без увеличения вычислительных затрат, связанных с памятью.
Архитектура RAM-Net использует Product Softmax и разреженность Top-K для концентрации распределения адресов памяти, что повышает эффективность доступа. Product Softmax применяет независимые softmax-функции к каждой размерности вектора адреса, что позволяет получить вероятностное распределение, где наиболее вероятные адреса имеют значительно больший вес. Параллельно, Top-K разреженность ограничивает количество выбранных адресов до значения K, отбрасывая наименее вероятные позиции. Это приводит к снижению вычислительных затрат, поскольку операции выполняются только по выбранному подмножеству адресов памяти, и уменьшает потребление энергии, что особенно важно для задач с большими объемами данных и ограниченными ресурсами.
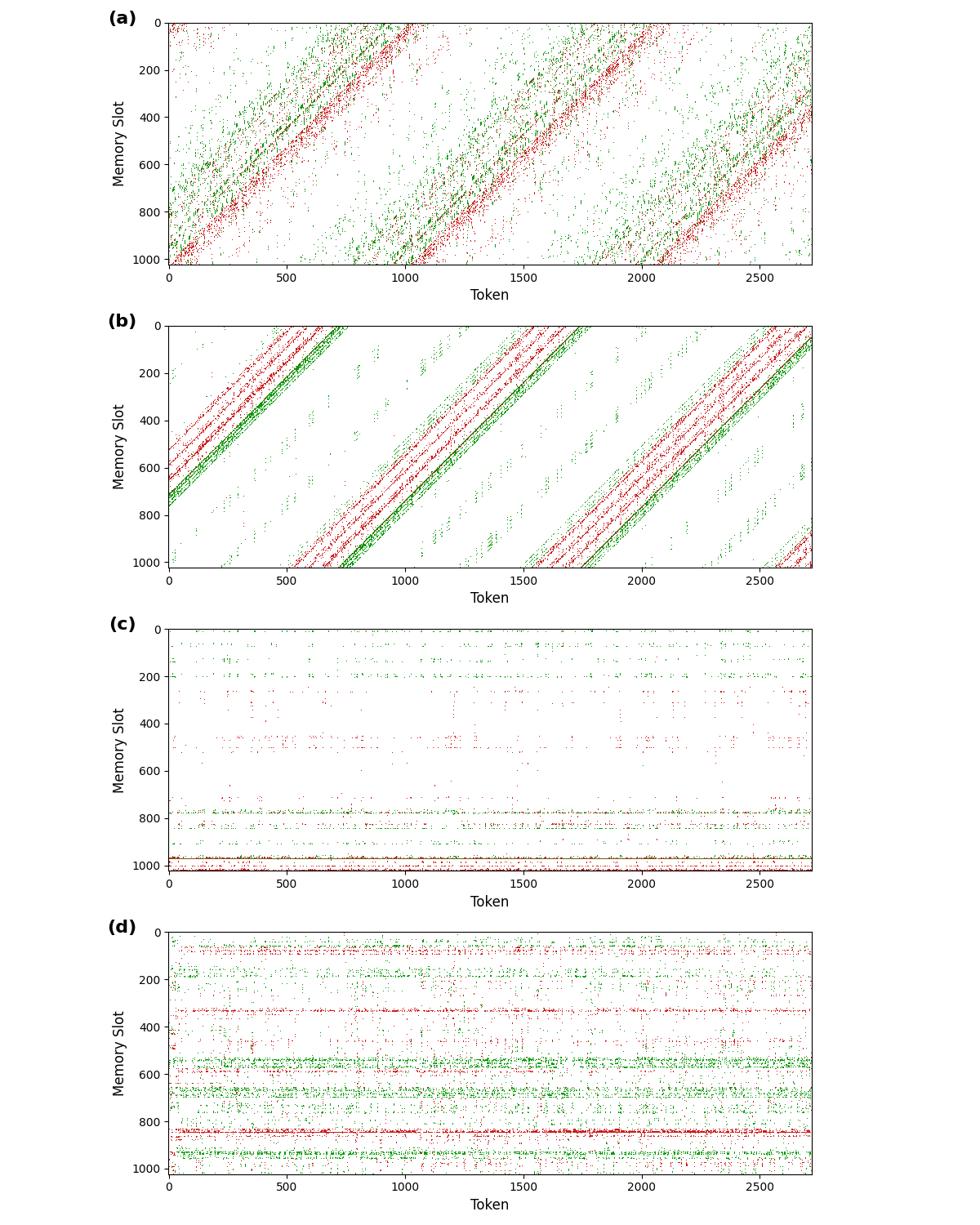
Динамическое управление памятью: PDMA и CAPE — детали реализации
В архитектуре RAM-Net, правило обновления Power Decay Moving Average (PDMA) обеспечивает раздельное управление скоростью забывания и интенсивностью записи информации в память. Традиционные методы, как правило, связывают эти два параметра, что приводит к неэффективному использованию ресурсов памяти. PDMA позволяет регулировать скорость затухания весов памяти независимо от объема записываемых данных. Это достигается путем использования степенной функции затухания w_{t+1} = \alpha w_t + (1 - \alpha) v_t, где α — коэффициент, определяющий скорость забывания, а v_t — вектор новых данных. Разделение этих параметров позволяет модели сохранять важную информацию на протяжении более длительного времени, не жертвуя при этом способностью адаптироваться к новым входным данным и обновлять существующие знания.
Механизм управления памятью RAM-Net позволяет модели сохранять важную информацию на протяжении более длительных периодов времени, не препятствуя при этом адаптации к новым входным данным. Это достигается за счет динамической настройки скорости «забывания» информации в зависимости от интенсивности записи, что позволяет избежать как быстрого устаревания ключевых данных, так и перегрузки памяти нерелевантной информацией. В результате, модель способна эффективно удерживать важные контекстные сведения, необходимые для выполнения задач, и одновременно оперативно реагировать на изменения во входном потоке, обеспечивая оптимальный баланс между стабильностью и гибкостью.
Для кодирования позиционной информации в RAM-Net используется Cyclic Address Positional Embedding (CAPE), основанный на циклическом операторе сдвига. CAPE преобразует адрес ячейки памяти в позиционный вектор, используя циклический сдвиг, что позволяет модели учитывать порядок следования данных в памяти. Этот метод обеспечивает эффективное кодирование позиции без добавления дополнительных параметров, сохраняя при этом информацию о последовательности в контексте ячеек памяти. Циклический сдвиг позволяет представлять позиции как периодические, что способствует обобщению и устойчивости модели к различным длинам последовательностей.
В RAM-Net, для оптимизации использования слотов памяти, применяется квантование векторов (Vector Quantization, VQ). Этот метод позволяет сжимать векторы представлений данных, снижая требования к объему памяти и повышая эффективность хранения информации в слотах памяти. VQ сопоставляет каждый входной вектор с ближайшим вектором из предопределенного кодового словаря, что приводит к уменьшению размерности данных и повышению скорости доступа к информации. Эффективность VQ напрямую влияет на плотность хранения данных в каждом слоте памяти и общую производительность модели.
RAM-Net: Результаты и перспективы — влияние на область
Архитектура RAM-Net продемонстрировала передовые результаты на различных эталонных задачах по моделированию последовательностей, что свидетельствует о её превосходной эффективности и точности. В ходе тестирования, RAM-Net стабильно превосходила существующие модели в задачах, требующих анализа и обработки длинных последовательностей данных. Эта способность к эффективной обработке информации достигается благодаря инновационному подходу к управлению памятью, позволяющему модели сохранять и использовать информацию на протяжении длительных периодов времени без существенного увеличения вычислительных затрат. Результаты подтверждают, что RAM-Net представляет собой значительный прогресс в области моделирования последовательностей и открывает новые возможности для решения сложных задач, требующих глубокого понимания контекста и долгосрочной памяти.
Архитектура RAM-Net демонстрирует значительное преимущество перед традиционными трансформерами в обработке длинных последовательностей данных. В отличие от трансформеров, потребность в памяти которых растет пропорционально длине входной последовательности, RAM-Net использует постоянный объем памяти, вне зависимости от размера обрабатываемых данных. Это достигается за счет использования внешней памяти, которая позволяет эффективно хранить и извлекать информацию, необходимую для обработки длинных контекстов. Такая особенность позволяет RAM-Net значительно превосходить традиционные модели при решении задач, требующих анализа и понимания больших объемов информации, например, при обработке длинных текстов, видео или аудиопотоков, открывая новые возможности для построения более эффективных и масштабируемых систем искусственного интеллекта.
В ходе экспериментов архитектура RAM-Net продемонстрировала превосходную точность в задаче MQAR (Multi-hop Question Answering over Reasoning), последовательно превосходя другие современные модели при различных размерах состояния, что наглядно подтверждается данными, представленными на рисунке 4. Эта способность эффективно обрабатывать сложные рассуждения и извлекать информацию из длинных контекстов делает RAM-Net особенно перспективной для приложений, требующих глубокого понимания и анализа больших объемов данных.
Архитектура RAM-Net открывает значительные перспективы для приложений, требующих сохранения и обработки информации на протяжении длительного времени. Её способность эффективно работать с длинными последовательностями делает её особенно ценной в задачах, связанных со сложным рассуждением, где необходим учёт большого контекста для принятия обоснованных решений. В диалоговых системах RAM-Net способна поддерживать более связные и осмысленные беседы, запоминая предыдущие реплики и адаптируясь к контексту разговора. Кроме того, в области обработки видео RAM-Net может использоваться для анализа и понимания временных зависимостей, позволяя эффективно отслеживать объекты, понимать действия и предсказывать будущие события, что значительно превосходит возможности традиционных моделей с ограниченной памятью.
Исследования показали, что архитектура RAM-Net демонстрирует сопоставимую эффективность в задачах языкового моделирования с передовыми методами, успешно проходя тесты на стандартных бенчмарках, таких как WikiText-103 и MMLU. Это означает, что, сохраняя при этом способность эффективно обрабатывать длинные последовательности, RAM-Net не уступает в качестве генерируемого текста и понимании языка другим современным моделям. Достижение подобного уровня производительности в сочетании с преимуществами в управлении памятью открывает широкие перспективы для применения данной архитектуры в разнообразных задачах обработки естественного языка, где важны как точность, так и способность к работе с большими объемами информации.
Архитектура RAM-Net демонстрирует впечатляющую способность эффективно улавливать долгосрочные зависимости в данных, что открывает новые перспективы для исследований в областях, требующих анализа сложных закономерностей. В отличие от традиционных моделей, испытывающих трудности при работе с длинными последовательностями, RAM-Net позволяет более точно извлекать и интерпретировать информацию, скрытую в удаленных частях данных. Это особенно важно для задач, связанных с тонким поиском информации, где даже небольшие детали могут иметь решающее значение, а также для понимания сложных структур в больших объемах данных, например, при анализе временных рядов, обработке естественного языка или изучении геномных данных. Подобная способность может существенно улучшить точность и эффективность систем, занимающихся извлечением знаний, прогнозированием и принятием решений на основе сложных данных.
Представленная работа демонстрирует стремление к компрессии сложности в архитектуре RAM-Net. Архитекторы модели, подобно скульпторам, отсекают всё лишнее, чтобы выявить суть последовательного моделирования. RAM-Net, отделяя ёмкость памяти от размера модели, достигает высокой точности и эффективности за счёт дифференцируемого декодера адресов и разреженного доступа к памяти. Как заметила Барбара Лисков: «Программы должны быть спроектированы так, чтобы изменения в одной части не приводили к неожиданным последствиям в других». Этот принцип находит отражение в архитектуре RAM-Net, где чёткое разделение памяти и модели обеспечивает предсказуемость и управляемость системы, избегая ненужной сложности и позволяя сконцентрироваться на главном — моделировании последовательностей.
Куда Далее?
Представленная архитектура RAM-Net, несомненно, представляет собой шаг к более элегантному управлению памятью в моделях последовательностей. Однако, упрощение — это не всегда решение. Вопрос не в том, чтобы увеличить ёмкость памяти любой ценой, а в том, чтобы понять, что действительно необходимо сохранить. Предлагаемый дифференцируемый декодер адресов — это лишь инструмент, и его эффективность напрямую зависит от качества данных и метрик, определяющих «важность» информации. Настоящая сложность заключается в определении того, что такое «релевантность» для модели, и как избежать увлечения тривиальными корреляциями.
Очевидным направлением для будущих исследований является исследование альтернативных механизмов разреженного доступа к памяти. Вместо полного отказа от части памяти, можно рассмотреть градиентные механизмы «забывания», позволяющие модели динамически адаптировать свою «запоминающую способность». Не менее важным представляется вопрос о масштабируемости. Увеличение размеров разреженной памяти может привести к новым узким местам, требующим разработки более эффективных алгоритмов доступа и обработки данных. В конечном итоге, цель — не просто построить большую память, а создать систему, способную извлекать истинное знание из хаоса информации.
И, пожалуй, самое важное: необходимо помнить, что каждая новая архитектура — это лишь приближение к идеалу. Стремление к совершенству — это бесконечный процесс. Истинное мастерство заключается не в создании сложной системы, а в умении её упростить до необходимого минимума. Совершенство — это исчезновение архитектора.
Оригинал статьи: https://arxiv.org/pdf/2602.11958.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Языковые модели и границы возможного: что делает язык человеческим?
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Таблицы оживают: Искусственный интеллект осваивает структурированные данные
- Понимание ориентации объектов: новый взгляд на 3D-пространство
- Гендерные стереотипы в найме: что скрывают языковые модели?
- Ожившие Пиксели: Создание Реалистичных Видео с Сохранением Личности
- Память на заказ: Как обучить агентов взаимодействовать эффективнее
- Квантовый разум: Новая эра языковых моделей
- Квантовые Игры и Цифровое Сотрудничество: Взгляд изнутри
- Разумные языковые модели: новый подход к логическому мышлению
2026-02-15 08:56