Автор: Денис Аветисян
Исследователи предлагают эффективный метод обучения линейным, изменяющимся во времени стратегиям управления, обеспечивающим реалистичную анимацию персонажей и успешный перенос на реальные роботы.
В статье представлен линейный контроллер с использованием штрафа за якобиан действий, позволяющий создавать плавные траектории движения для физически достоверных симуляций и робототехники.
Обучение реалистичных стратегий управления для симуляций персонажей часто приводит к возникновению неестественных высокочастотных сигналов, не применимых к реальным системам. В работе, озаглавленной ‘Learning Smooth Time-Varying Linear Policies with an Action Jacobian Penalty’, предложен новый подход, основанный на использовании штрафа по якобиану действий, для эффективного обучения гладким, изменяющимся во времени линейным стратегиям управления. Предложенная архитектура Linear Policy Net (LPN) значительно снижает вычислительные затраты при расчете этого штрафа и демонстрирует более быструю сходимость обучения по сравнению с традиционными методами. Сможет ли данная комбинация LPN и штрафа по якобиану действий стать стандартом в разработке реалистичных и управляемых симуляций, а также способствовать успешному переносу стратегий на физических роботов?
Пророчество Движения: Вызовы Реалистичной Анимации
Создание убедительной физически-реалистичной анимации персонажей остается сложной задачей, обусловленной значительными вычислительными сложностями и трудностями в управлении. Моделирование взаимодействия персонажа с окружающей средой, включая столкновения, трение и динамические реакции, требует огромных ресурсов обработки данных, особенно при стремлении к высокой детализации и реализму. Контроль над движением персонажа, обеспечивающий не только правдоподобность, но и соответствие задуманным действиям, представляет собой отдельную проблему. Простые алгоритмы часто приводят к неестественным движениям, в то время как сложные методы требуют точной настройки множества параметров, что затрудняет процесс создания анимации и ограничивает возможности для импровизации и адаптации к изменяющимся условиям. Поиск баланса между вычислительной эффективностью и реалистичностью движений остается ключевой задачей для исследователей и разработчиков в области компьютерной графики.
Традиционные методы создания анимации персонажей, несмотря на свою зрелость, часто сталкиваются с ограничениями при генерации разнообразных и естественных движений. Их способность к адаптации к изменяющимся условиям окружающей среды, будь то неровная местность или неожиданные препятствия, остается недостаточной. Эти методы, как правило, требуют значительных усилий по ручной настройке каждого движения, что делает процесс трудоемким и ограничивает спонтанность и реалистичность. В результате, персонажи, созданные подобным образом, зачастую демонстрируют повторяющиеся паттерны поведения и не способны адекватно реагировать на динамично меняющийся мир, что снижает эффект погружения и достоверности.
Для достижения реалистичного движения персонажа необходимо глубокое понимание и точное манипулирование его «состоянием» — совокупностью всех внутренних параметров, определяющих текущее положение, скорость и другие характеристики. Именно состояние персонажа является отправной точкой для генерации желаемого «действия». Исследователи стремятся создать системы, способные эффективно отображать изменение состояния персонажа в ответ на внешние воздействия или внутренние решения, обеспечивая плавный и правдоподобный переход от одного действия к другому. Управление состоянием включает в себя не только контроль над ключевыми точками, но и учет динамики всего тела, а также предвидение возможных реакций на окружающую среду, что позволяет создавать сложные и убедительные последовательности движений. Эффективное управление состоянием — это ключ к созданию персонажей, способных реагировать на ситуации так, как это сделал бы человек, делая анимацию более живой и реалистичной.
Глубокое Обучение с Подкреплением: Путь к Управляемому Движению
Глубокое обучение с подкреплением (Deep Reinforcement Learning, DRL) представляет собой эффективный подход к обучению стратегий управления напрямую посредством взаимодействия с симулированной средой. В отличие от традиционных методов, требующих ручного проектирования контроллеров или предопределенных моделей динамики, DRL позволяет агенту самостоятельно осваивать оптимальное поведение путем проб и ошибок. Среды симуляции, такие как ‘Mujoco’, предоставляют реалистичную физическую модель и позволяют агенту безопасно исследовать различные стратегии управления, собирая данные для обучения. Этот процесс позволяет создавать контроллеры для сложных систем, где явное математическое моделирование затруднено или невозможно, и демонстрирует высокую эффективность в задачах управления движением, робототехнических приложениях и других областях.
Алгоритм Proximal Policy Optimization (PPO) является одним из наиболее эффективных методов обучения политик в обучении с подкреплением. PPO относится к классу алгоритмов policy gradient, и его ключевая особенность заключается в использовании “обрезанной” функции потерь, что позволяет совершать более крупные шаги в пространстве политик без риска значительного ухудшения производительности. Это достигается за счет ограничения изменения политики на каждой итерации, что обеспечивает стабильность обучения. Алгоритм оптимизирует политику, максимизируя ожидаемое накопленное вознаграждение, определяемое функцией вознаграждения (Reward Function), при этом минимизируя отклонение новой политики от старой. В результате PPO позволяет быстро и эффективно обучать агентов сложным задачам управления, таким как управление движением в симуляторе Mujoco.
Для обеспечения стабильности и надежности при обучении политик управления в глубоком обучении с подкреплением часто применяются методы регуляризации, такие как штраф за якобиан действий (Action Jacobian Penalty). Этот метод добавляет к функции потерь слагаемое, пропорциональное норме якобиана выходных действий политики. ||J(s)|| , где J(s) — якобиан, а s — состояние. Штраф за якобиан действий способствует сглаживанию траекторий движения, уменьшая резкие изменения в управляющих сигналах и предотвращая нереалистичные или неустойчивые действия. Это особенно важно в задачах управления, где требуется точное и плавное отслеживание траектории или поддержание заданного состояния.
Линейные Сети Управления: Новая Архитектура для Плавного Движения
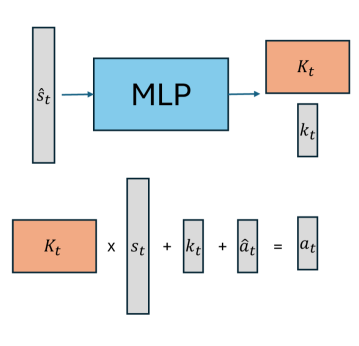
Линейная политика сети (Linear Policy Net) представляет собой новую архитектуру, которая напрямую выдает Временную Линейную Обратную Связь (Time-Varying Linear Feedback Policy), в отличие от традиционных подходов, где сеть напрямую генерирует управляющие воздействия. Вместо вычисления конкретного действия в каждый момент времени, сеть определяет матрицу усиления обратной связи K(t), которая преобразует текущее состояние системы в управляющее воздействие. Такой подход позволяет представить политику как функцию состояния и времени, что обеспечивает большую прозрачность и контроль над поведением агента, а также упрощает процесс обучения и повышает стабильность системы.
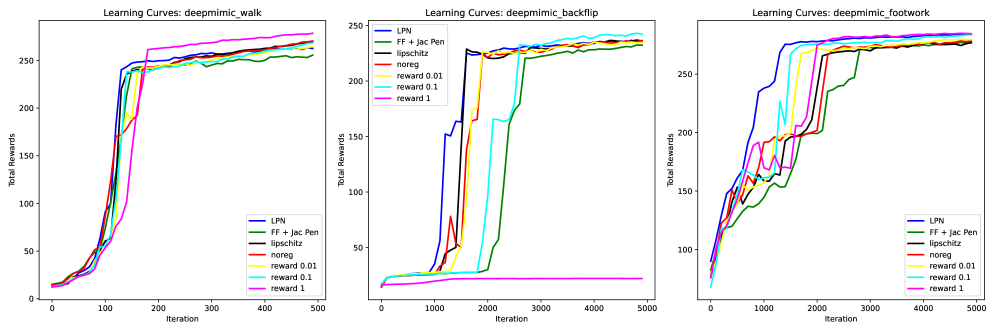
Архитектура линейных сетевых политик (LPN) обеспечивает повышенную интерпретируемость и управляемость политик, что упрощает процесс обучения и повышает стабильность. Экспериментальные данные показывают, что LPN демонстрирует самую быструю сходимость обучения по сравнению с полносвязными сетями, использующими штрафы Якобиана или изменения действий, в различных задачах. Это достигается за счет прямого вывода времени-варьирующей линейной обратной связи, а не непосредственного управляющего воздействия, что позволяет более эффективно оптимизировать параметры и избежать проблем, связанных с нелинейностью и сложностью полносвязных архитектур.
Применение сингулярного разложения (Singular Value Decomposition, SVD) к полученным политикам позволяет существенно снизить их размерность и улучшить обобщающую способность. SVD позволяет представить матрицу обратной связи, описывающую политику, в виде произведения трех матриц, что позволяет отбросить компоненты с наименьшим сингулярным числом, тем самым уменьшая количество параметров, необходимых для представления политики. В результате, политика может быть представлена матрицами пониженного ранга (например, ранг 20-22 для некоторых движений), сохраняя при этом достаточную производительность и улучшая способность к обобщению на новые, ранее не встречавшиеся ситуации. Это также способствует повышению вычислительной эффективности и снижению требований к памяти при реализации политики.
Применение разработанного подхода продемонстрировало успешные результаты в задачах переноса обучения из симуляции в реальный мир, что позволило развернуть политики управления на четвероногом роботе. Установлено, что полученные политики могут быть эффективно представлены в виде низкоранговых матриц обратной связи (ранга 20-22 для некоторых движений), при этом сохраняется высокая производительность и стабильность управления. Такое представление позволяет снизить вычислительную сложность и упростить процесс развертывания на реальном оборудовании.
К Надежному и Адаптируемому Управлению Движением: Пророчество о Будущем
Основой устойчивого управления движением является способность системы адаптироваться к внешним возмущениям и изменениям в окружающей среде. В данном подходе, так называемая “Линейная Сеть Управления” обучается посредством формирования матрицы обратной связи, что позволяет ей эффективно компенсировать непредсказуемые факторы. В отличие от традиционных методов, требующих постоянной перенастройки при малейших изменениях, эта архитектура автоматически корректирует траекторию движения, поддерживая стабильность и точность. Обученная матрица обратной связи, по сути, представляет собой внутренний механизм самокоррекции, позволяющий системе оставаться устойчивой даже в сложных и динамичных условиях. Это особенно важно для робототехники и анимации персонажей, где реалистичность и надежность управления являются ключевыми требованиями.
Полученные алгоритмы управления движением позволяют создавать более естественные и плавные движения, что было продемонстрировано на эталонных тестах, таких как ‘DeepMimic’. В ходе исследований, системы, использующие данный подход, успешно воспроизводили сложные акробатические трюки и человекоподобные движения с высокой точностью и реалистичностью. Особенностью является способность алгоритма адаптироваться к различным условиям и вариациям в окружающей среде, обеспечивая стабильное и грациозное выполнение движений даже при наличии помех или неточностей в моделировании. Такие результаты открывают новые возможности для создания реалистичных анимаций персонажей, управления роботами и разработки систем виртуальной реальности, где плавность и естественность движений играют ключевую роль в создании эффекта присутствия.
Для дальнейшей оптимизации планирования и выполнения движений, архитектура линейной сети управления может быть эффективно дополнена методами траекторной оптимизации и кинематического MPC (Model Predictive Control). Траекторная оптимизация позволяет находить оптимальные траектории движения, учитывая ограничения и цели, в то время как кинематический MPC обеспечивает точное отслеживание этих траекторий, динамически корректируя управление на основе предсказания будущего поведения системы. Интеграция этих методов позволяет не только повысить точность и плавность движений, но и адаптироваться к изменяющимся условиям среды и непредсказуемым возмущениям, создавая более сложные и реалистичные модели поведения для роботов и виртуальных персонажей. Такой подход обеспечивает существенное улучшение качества управления по сравнению с использованием только линейной сети управления, открывая возможности для создания более гибких и адаптивных систем.
Разработанная система управления, основанная на обученных политиках, демонстрирует впечатляющую скорость обновления — до 15 Гц. Это значительно снижает вычислительную нагрузку по сравнению с традиционными нейронными сетями, что делает возможным применение в реальном времени и на устройствах с ограниченными ресурсами. Такая скорость и эффективность открывают перспективы для создания более реалистичных и адаптивных движений в анимации персонажей и робототехнике, позволяя им взаимодействовать с окружающей средой более плавно и естественно. Улучшенная способность к адаптации к изменениям в динамике и окружении позволяет создавать роботов, способных к более сложным задачам и взаимодействиям, а также более живых и убедительных цифровых персонажей.
Наблюдения за развитием систем часто напоминают заботу о саде. Попытки привить немедленную стабильность — тщетны, ведь сама природа контроля — в постоянном движении. Данная работа, исследующая обучение временных линейных политик с использованием штрафа за якобиан действий, подтверждает эту истину. Стремление к гладким, меняющимся во времени решениям — это не статичная конструкция, а органический рост. Как заметил Джон Маккарти: «Всякий интеллект увеличивает возможности, но не гарантирует их мудрого использования.» Именно поэтому акцент на плавности и адаптивности, как это демонстрируется в исследовании переноса управления на четвероногого робота, является ключом к созданию действительно устойчивых и эффективных систем управления.
Что же дальше?
Представленная работа, как и многие другие, стремится обуздать движение — зафиксировать его в сетях линейных контроллеров. Однако, движение — это не структура, а компромисс, застывший во времени. Штраф по якобиану действий — лишь один из способов смягчить неизбежные рывки и колебания, но он не устраняет фундаментальной неопределенности, присущей взаимодействию физических систем с миром. Перенос на реального четвероногого робота — это, конечно, шаг вперед, но и лишь подтверждение старой истины: технологии сменяются, зависимости остаются.
Будущие исследования, вероятно, сосредоточатся не столько на совершенствовании алгоритмов, сколько на понимании границ применимости линейных моделей. Иллюзия гладкости, создаваемая штрафами, рано или поздно рассеется при столкновении с непредсказуемостью реального мира. Поиск инвариантных свойств движения, тех, что не зависят от конкретной реализации системы, представляется более перспективным направлением, чем бесконечная гонка за точностью.
Системы — это не инструменты, а экосистемы. Их нельзя построить, только вырастить. И в этой сложной, нелинейной динамике, линейные контроллеры, как и все прочее, обречены на постепенное, неизбежное изменение. Вопрос не в том, как создать идеальный контроллер, а в том, как сделать систему достаточно устойчивой, чтобы выжить в этом постоянном движении.
Оригинал статьи: https://arxiv.org/pdf/2602.18312.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
2026-02-23 08:53